Banyak artikel ditulis tentang pemilihan kernel semantik, tetapi masih ada kesalahan. Cara Mengambil kernel semantik Dengan sejumlah besar kueri utama? Apakah saya perlu memperluas kernel semantik dari waktu ke waktu? Bagaimana cara mendistribusikan kata kunci pada halaman? Pertanyaan ini dan lainnya, baca di lembar curang kami.
Perhatian! 23 Oktober akan mengeluarkan edisi berikut "boks pengoptimal", topiknya - "CMS" .
Kirim pertanyaan Anda dan para ahli kami akan menjawab Anda!
Kernel semantik
1. Bagaimana cara membuat kernel semantik untuk toko online, apakah ada fitur tertentu?
Saat membuat kernel semantik untuk toko online, tidak hanya kueri frekuensi tinggi yang harus diambil, dan rangkaian produk memaksimalkan dan secara aktif mempromosikan kategori halaman dan kartu barang.
Oleh karena itu, untuk sumber daya seperti permintaan tampilan "membeli nokia Telepon N8 " akan lebih konversi dan efisien daripada kueri dengan frekuensi tipe yang lebih tinggi "Beli Telepon".
Untuk membuat kernel semantik, yang akan mengarahkan pengunjung ke situs, Anda dapat menggunakan dua cara: otomatis dan manual.
Pemilihan permintaan otomatis dapat dilakukan dengan menggunakan layanan dan program khusus. (Misalnya, layanan online seolib.ru, kolektor utama, slobel, dll.).
Metode manual baik karena Anda dapat memilih permintaan sekaligus pada halaman target - kartu dan kategori menggunakan skema pemilihan:
- "Produk + Kata Tambahan"
- "Beli + barang + kata-kata tambahan"
- "Penjualan + Produk + Kata Tambahan"
- "Harga + produk + kata-kata tambahan"
- "Karakteristik + Produk + Kata Tambahan"
- "Deskripsi + Produk + Kata Tambahan"
- "Foto + produk + kata-kata tambahan", dll.
Pada saat yang sama, dalam inti semantik, kami tidak akan menerima tidak hanya komersial, tetapi juga permintaan informasi yang akan membuat inti dan pelabuhan kami lebih alami.
Misalnya, untuk kategori barang "Smartphone Apple iPhone" di toko online ponsel Anda dapat menemukan permintaan menggunakan tabel sederhana di Excel:
Yaitu, berdasarkan data dalam tabel, kami mengambil 3 opsi untuk permintaan untuk satu halaman dari Apple iPhone smartphone Kategori:
- "membeli smartphone Apple. iPhone 3 4 GB Putih »
- "Sale Smartphone Apple iPhone 4 8 GB Hitam"
- "Deskripsi Smartphone Apple iPhone 5 16 GB Putih"
2. Bagaimana memilih kernel semantik untuk situs berita regional? Topik itu.
Pilih kernel semantik, dan kemudian tulis berita di bawahnya - pendekatan yang salah untuk situs berita apa pun, termasuk tema itu.
Tugas utama untuk situs berita adalah publikasi informasi operasional, menarik dan relevan tentang peristiwa terkini, informasi yang akan tertarik pada pembaca hari ini. Hanya dengan pendekatan ini, situs ini akan dapat menjadi populer, menaklukkan kepercayaan pengguna, dan, oleh karena itu, dan mesin pencari. Setelah prinsip ini, Anda secara alami akan membentuk inti semantik yang benar dari situs Anda. Lagi pula, topik utama (permintaan), satu atau lain cara, akan disebutkan dalam berita subjek Anda. Jika waktu luang Anda tetap ada, lebih baik membelanjakannya pada peningkatan jumlah dan peningkatan kualitas materi yang dipublikasikan daripada menyiapkan artikel berdasarkan permintaan tertentu.
3. Apakah layak menggunakan kueri frekuensi tinggi di inti semantik?
Kueri frekuensi baru dapat digunakan oleh situs baru, tetapi tergantung pada tingkat subjek dan persaingan. Semakin tinggi tingkat persaingan, semakin sulit (atau tidak mungkin) untuk mempromosikan situs, karena mesin pencari akan memberikan preferensi kepada sumber daya lama, kepercayaan.
Misalnya, mari kita lihat penerbitan dalam 10 atas permintaan "AC" (Mesin Pencari Yandex, Wilayah "Moskow"):

Untuk situs yang usianya kurang dari dua tahun, disarankan untuk pindah ke frekuensi menengah dan permintaan frekuensi rendah. Menggunakannya di kernel semantik, Anda tidak akan menghabiskan anggaran untuk promosi dan Anda dapat menarik audiens target ke situs. Tengah-aku. permintaan frekuensi rendah adalah konversi yang paling, yang mengarah ke situs pelanggan potensial.
4. Bagaimana cara membuat kernel semantik dengan sejumlah besar kunci? Apa yang dihentikannya, dan apa yang harus dibuang dalam situasi seperti itu? Jelas, tidak mungkin untuk bekerja dengan beberapa ribu kunci.
Beberapa rahasia tidak ada - pekerjaannya melelahkan dan, jika perlu, harus bekerja dengan beberapa ribu kunci.
Ada cara untuk memfasilitasi pekerjaan. Pada tahap pertama pemilihan permintaan, lebih mudah digunakan untuk menggunakan layanan pengumpulan statistik otomatis, mengkonfigurasi "Stop-Words" dan menentukan wilayah yang diperlukan. Layanan otomatis akan menyingkirkan kebutuhan untuk secara manual memasukkan kata-kata ke layanan WordStat.yandex.ru.
Daftar permintaan yang dihasilkan harus dibagi menjadi beberapa kelompok prioritas. Di sini, tentu saja, itu semua tergantung pada subjek spesifik Anda. Misalnya, jika Anda memiliki situs penjualan, pertama-tama perlu jenis transaksional jenis "membeli", "harga" dll.
5. Setelah jam berapa itu layak untuk menyelesaikan dan memperluas kernel semantik dan apakah itu layak dilakukan sama sekali?
Anda dapat memperluas kernel semantik dan kebutuhan. Ini optimal untuk melakukan ini dalam beberapa bulan promosi, ketika tahap utama telah berlalu dan situs telah mengambil posisi terdepan setidaknya 70% dari daftar pertama pertanyaan.
Saat memperluas kernel, pilih Permintaan sedemikian rupa sehingga mereka berpotongan dengan daftar asli. Jika tidak, jika Anda meningkatkan teks, header dan meta-tag setiap kali Anda dapat mengedit teks, mesin pencari, mesin pencari mungkin menganggapnya tidak wajar dan mencurigakan dan menurunkan situs dalam ekstradisi.
Saat memperluas kernel semantik, selain itu metode Standar Membuat daftar permintaan, disarankan untuk menggunakan data dari google.nalytics dan yandex.metrics.
Bagaimana layanan data dapat bermanfaat, kami akan menunjukkan pada contoh yandex.metrics - pergi ke yandex.metric, temukan tab "Sumber" - "frasa pencarian":

Dan Anda akan disajikan dengan daftar semua permintaan yang ada kunjungan ke situs, dengan jumlah pengunjung untuk setiap permintaan:

Dalam daftar ini, pilih Kueri yang ditargetkan untuk sumber daya Anda dan tidak termasuk dalam inti semantik awal. Kemudian periksa posisi situs sesuai dengan daftar yang diterima dan Anda dapat, pertama-tama, ambil pertanyaan-kueri yang tidak ada di 10 besar. Untuk permintaan yang tersisa, Anda dapat secara berkala melacak posisi dan mengencangkannya jika terjadi benih.
6. Seperti dalam pembentukan nukleus semantik, tentukan permintaan prioritas mana, apa yang opsional?
Untuk berbagi kueri untuk prioritas dan tambahan, Anda perlu mempertimbangkan jenis apa yang mereka hubungkan. Tiga jenis dibedakan: frekuensi tinggi (HF), frekuensi rendah (LF) dan frekuensi menengah. Kueri RF adalah permintaan paling populer, dan ada SCH dan LF yang kurang populer di sekitarnya. Oleh karena itu, prioritas akan menjadi HF, dan tambahan - SCH dan pendek. Misalnya, permintaan RF - "jendela plastik" Permintaan Utama di halaman, permintaan SC - "Jendela plastik di Moskow" dan permintaan LF - Permintaan tambahan.
7. Apa yang harus menjadi nomornya kata kunci. ke halaman? Secara khusus dalam jumlah - 3, 10, 15?
Itu secara unik dijawab sulit, karena Setiap situasi individu membutuhkan berbagai pendekatan. Paling benar mengoptimalkan halaman di bawah satu permintaan HF, 2-3 query SCH dan lebih lanjut - di bawah permintaan NF. Logikanya sederhana - satu halaman berjalan satu permintaan utama, di mana semuanya "berputar".
Sebagai contoh, "jendela plastik" - Permintaan RF; "Jendela plastik untuk dibeli", "Plastik Windows Moscow" - Permintaan SC; "Jendela plastik untuk dibeli di Moskow" - Kueri LF. Akan sulit untuk mempromosikan halaman jika Anda mengoptimalkannya untuk permintaan "Mencetak Logo" dan "film rumah kaca". Pengecualian hanya "rumah", karena Ini harus menggambarkan seluruh jajaran layanan situs.
Perhatikan bahwa untuk pertanyaan dengan kata-kata tambahan seperti "membeli", "Grosir", "harga" Tidak disarankan untuk mengoptimalkan halaman lain kecuali yang dimana kueri utama, frekuensi tinggi berada. Misalnya, program halaman dipromosikan "Plastik Windows.", Harus dipindahkan dan berdasarkan permintaan "Jendela plastik untuk dibeli".
8. Apakah layak menjual permintaan informasi ke inti semantik, ini cukup baik, atau masih tidak diperlukan permintaan seperti itu?
Pasti sepadan. Saat Anda menulis, itu adalah lalu lintas tambahan, yang juga dapat menyebabkan konversi. Saat membuat bagian informasi di situs komersial, penting untuk mematuhi beberapa prinsip:
- bahan informasi harus sangat berguna bagi pengguna untuk memberi tahu mereka informasi penting dan bermanfaat. Perlu untuk menyiapkan publikasi berkualitas tinggi, dan tidak hanya mengisi bagian bagian, "dipertajam" berdasarkan permintaan;
- jangan lupa bahwa situs Anda terutama komersial. Untuk sebagian besar mata pelajaran, situasi ketika jumlah artikel informasi melebihi jumlah kartu produk, itu akan terlihat aneh;
- cobalah untuk menempatkan tautan di tautan tubuh ke halaman penjualan situs. Ini akan meningkatkan efisiensi lalu lintas informasi.
9. Bagaimana cara lebih efisien menerapkan referensi di dalam konten frekuensi, I.E. Frekuensi mengikat satu tingkat atau memutarnya dengan frekuensi LF-HF yang berbeda?
Sejauh yang kita mengerti, pertanyaan itu menyangkut transfer dalam.
Strategi Peregonovka Ada sejumlah besar, tetapi kami tidak akan merekomendasikan untuk "melampirkan" pada konsep frekuensi permintaan. Penting bahwa transfer itu bermanfaat. Jika referensi di dalam konten menggunakan - itu akan membantu. Jika tautan "mati" dan jangan menggunakannya - rasa, kemungkinan besar tidak akan ada banyak. Dan tidak ada perbedaan, Anda merujuk pada permintaan LF dari halaman permintaan RF atau sebaliknya.
Tentu saja, efek dari transfer batin lebih terlihat untuk permintaan LF, karena mereka kurang "menuntut" daripada kueri frekuensi tinggi dengan persaingan besar. Tetapi sekali lagi kita akan mengulangi bahwa keinginan untuk "dilampirkan" pada algoritma overgrinking tertentu, tanpa memikirkan berapa banyak overclocking yang dibutuhkan oleh pengguna, tidak hanya tidak membantu, tetapi dapat membahayakan. Mesin pencari tidak suka spammer.
10. Saya membuat inti semantik, dengan fokus pada Yandex, meskipun saya memiliki situs Ukraina dan sebagian besar pengunjung berasal dari Google. Apakah inti ini cocok untuk Google (saya pikir, lakukan Yandex dan pengguna Google silakan praktikkan permintaan) atau perlu melakukan yang baru?
Perbedaan penting dalam permintaan dari Yandex dan pengguna Google biasanya tidak diamati. Jika seleksi memperhitungkan wilayah (dalam kasus Anda, Ukraina), maka seharusnya tidak ada masalah.
Untuk beberapa mata pelajaran, wilayah tersebut mungkin penting (dapat dipilih saat menganalisis permintaan di Yandex wordstat.). Perbedaan undang-undang atau popularitas produsen tertentu dapat mengakibatkan perbedaan. Dalam hal ini, Anda perlu melihat subjek Anda. Jika tidak ada perbedaan regional, maka Anda dapat dengan aman menggunakan inti yang dipilih sebagai dasar.
11. Situs saya bergerak sesuai permintaan "unta" dan pada kata ini ada di atas 3. Tetapi menurut kata "unta" itu bahkan tidak berada di urutan 30 besar. Mengapa begitu? Apakah penggunaan jamak atau satu-satunya di kata kunci mempengaruhi posisi situs?
Ya, dalam banyak kasus mempengaruhi, karena Yandex, mencari nomor ganda dan satu-satunya dapat berbeda secara signifikan, itu berarti memandang permintaan ini, sama berbeda. Selain itu, ada perbedaan yang signifikan dalam frekuensi permintaan. Misalnya, jika Anda melihat permintaan Yandex.WordStat.ru (Moskow) "! Jendela plastik" dan "! jendela plastik", maka frekuensi pertama akan 7650, dan yang kedua adalah 169315. Dengan demikian, penerbitannya akan sangat berbeda, karena Ini jelas permintaan yang berbeda. Perlakukan dengan hati-hati kata itu untuk mengoptimalkan halaman, karena Jika Anda memilih formulir yang salah - kehilangan lalu lintas.
12. Dalam penawaran komersial mereka, banyak perusahaan promosi membuat meja dengan inti semantik dan biaya per hari setiap frasa untuk menemukan 1-3, 4-6, 7-10 posisi di Yandex, Google. Bagaimana anggaran ini dipertimbangkan?
Pertanyaannya cukup rumit, karena masing-masing perusahaan dapat memiliki koefisien sendiri, dan tidak masuk akal untuk berbicara tentang semua perusahaan.
Biasanya, biaya kueri dihitung, berdasarkan kompleksitasnya (dengan kata lain, berapa banyak waktu yang akan diberikan karyawan untuk permintaan ini atau sekelompok permintaan) dan volume massa referensi yang diperlukan. Selain itu, Anda harus mempertimbangkan jumlah total permintaan yang dipromosikan (semakin banyak permintaan, masing-masing yang lebih murah, karena massa referensi umum situs akan lebih besar).
13. Pertanyaannya adalah sebagai berikut. Saya memiliki domain (ru), dibeli 1,5 tahun yang lalu. Ketika saya membuat situs di atasnya, saya tidak terlalu memikirkan persiapan nukleus semantik (tema medis, 40 halaman dalam indeks, tidak ada pengunjung). Saya ingin bertanya - jika saya mulai membuat situs baru di domain ini (topik lain), sudah dengan persiapan kernel semantik, dll., Dengan demikian langkah-langkah saya akan diobati dengan mesin pencari, bagaimana itu akan diindeks, Setelah periode berapa akan ada perubahan? Atau lebih baik membuat situs topik lain pada domain baru dan lupakan yang lama (ru)?
Jika situs saat ini tidak menerapkan filter dan domain cocok untuk subjek Anda yang lain (ingat bahwa itu harus menjadi pengguna yang tak terlupakan dan menampilkan aktivitas Anda) - seharusnya tidak ada masalah.
Namun, mesin pencari dapat "waspada" dengan perubahan total situs pemilik yang sama, karena perubahan tajam subjek terlihat tidak logis. Paling sering mengubah subyek situs yang dibuat berdasarkan penjualan referensi, dll.
Poin lain dari mana kita ingin memperingatkan adalah penciptaan situs di bawah inti semantik yang tersedia. Awalnya, perlu untuk mengembangkan konsep situs web, untuk memahami bahwa Anda dapat memberikan pengguna Anda yang berguna untuk menentukan penawaran unik Anda, dan sudah membuat situs web, pilih pertanyaan yang dapat diberikan oleh pengunjung target kepada Anda.
Periode pengindeksan ulang sulit, Anda dapat menavigasi sekitar satu setengah bulan.
Rilis Sebelumnya Optimizer Cheat Sheets:
DI saat ini Untuk promosi pencarian, faktor-faktor seperti konten dan struktur dimainkan sebagai penting sebagai peran penting. Namun, bagaimana memahami apa yang harus menulis teks bagian apa dan halaman buat di situs? Selain itu, Anda perlu mencari tahu persis apa sebenarnya pengunjung target sumber daya Anda yang tertarik. Untuk menjawab semua pertanyaan ini, Anda perlu merakit kernel semantik.
Kernel semantik - Daftar kata atau frasa yang sepenuhnya mencerminkan subjek situs Anda.
Dalam artikel itu, saya akan memberi tahu Anda cara mengambilnya, membersihkan dan membagi ke dalam struktur. Hasilnya akan menjadi struktur lengkap dengan kueri berkerumun melalui halaman.
Berikut adalah contoh inti dari permintaan yang dipecah ke dalam struktur:

Di bawah Clustering, saya mengerti rincian permintaan pencarian Anda untuk masing-masing halaman. Metode ini akan relevan untuk mempromosikan Yandex dan Google. Dalam artikel tersebut, saya akan menjelaskan cara yang sepenuhnya gratis untuk membuat inti semantik, tetapi saya akan menampilkan kedua opsi dengan berbagai layanan berbayar.
Setelah membaca artikel, Anda akan belajar
- Pilih permintaan yang tepat untuk subjek Anda
- Kumpulkan nukleus paling lengkap dari frasa
- Cleant dari permintaan yang tidak menarik
- Grup dan buat struktur
Kumpulkan inti semantik yang Anda bisa
- Buat struktur yang bermakna di situs
- Buat menu multi-level
- Isi halaman dengan teks dan tulis di atasnya dari MetaPET dan Judul
- Kumpulkan posisi situs Anda berdasarkan permintaan dari mesin pencari
Mengumpulkan dan mengelompokkan kernel semantik
Kompilasi yang tepat untuk Google dan Yandex dimulai dengan definisi frasa kunci utama subjek Anda. Misalnya, saya akan menunjukkan kompilasi pada toko pakaian online fiksi. Ada tiga cara untuk mengumpulkan kernel semantik:
- Manual. Menggunakan layanan Yandex WordStat, Anda memasukkan kata kunci dan tangan Anda memilih frasa yang Anda butuhkan. Metode ini cukup cepat jika Anda perlu merakit tombol ke satu halaman, namun, ada dua minus.
- Keakuratan metode "Chromas". Anda selalu dapat melewatkan kata-kata penting jika Anda menggunakan metode ini.
- Anda tidak akan dapat merakit kernel semantik di toko online besar, meskipun Anda dapat menggunakan plugin Yandex WordStat Asisten untuk menyederhanakan - masalahnya tidak menyelesaikannya.
- Setengah otomatis. Dalam metode ini, saya mengasumsikan penggunaan program untuk mengumpulkan nukleus dan pemecahan manual lebih lanjut pada bagian, subbagian, halaman, dll. Metode kompilasi ini dan mengelompokkan kernel semantik menurut saya adalah yang paling efektif. Ini memiliki sejumlah keunggulan:
- Cakupan maksimum semua tema.
- Gangguan kualitas
- Mobil. Saat ini, ada beberapa layanan yang menawarkan koleksi kernel sepenuhnya otomatis atau mengelompokkan permintaan Anda. Opsi sepenuhnya otomatis - saya tidak merekomendasikan untuk digunakan, karena Kualitas koleksi dan pengelompokan kernel semantik saat ini cukup rendah. Kueri otomatis Clustering - Mendapatkan popularitas dan berlangsung, tetapi Anda harus tetap menggabungkan beberapa halaman dengan tangan Anda, karena Sistem tidak memberikan solusi yang ideal. Dan menurut saya Anda hanya bingung dan Anda tidak akan dapat terjun ke proyek.
Untuk mengkompilasi dan mengelompokkan nukleus semantik yang lengkap pada proyek apa pun dalam 90% kasus, saya menggunakan metode semi-otomatis.
Jadi, sehingga kita perlu melakukan langkah-langkah berikut:
- Pemilihan permintaan untuk tema
- Memilih kernel berdasarkan permintaan
- Membersihkan dari kueri non-target
- Clustering (hancurkan frasa pada struktur)
Contoh kernel semantik menjahit dan pengelompokan pada struktur yang saya tunjukkan di atas. Saya mengingatkan Anda bahwa kami memiliki toko pakaian online, mulai paving 1 poin.
1. Pemilihan frasa untuk subjek Anda
Pada tahap ini, kita perlu alat Yandex Wordstat, pesaing dan logika Anda. Pada langkah ini, penting untuk merakit daftar frasa yang merupakan permintaan frekuensi tinggi tematik.
Cara Memilih Permintaan untuk Mengumpulkan Semantik dengan Yandex Wordstat
Ayo layanan, pilih kota yang Anda butuhkan (a) / wilayah, mendorong yang paling "lemak" dalam permintaan pendapat Anda dan lihat kolom kanan. Di sana Anda akan menemukan kata-kata tematik yang Anda butuhkan, baik di bagian lain dan frekuensi sinonim untuk frasa yang tertulis.

Cara Memilih Permintaan Sebelum Membuat Kernel Semantik Menggunakan Pesaing
Masukkan permintaan paling populer di mesin pencari dan pilih salah satu situs paling populer, banyak di antaranya kemungkinan besar Anda, dan Anda tahu.

Perhatikan bagian utama dan hemat frasa Anda yang Anda butuhkan.
Pada tahap ini, penting untuk dilakukan dengan benar: untuk memaksimalkan segala macam kata dari materi pelajaran Anda dan jangan lewatkan apa-apa, maka kernel semantik Anda akan menjadi yang paling lengkap.
Berlaku untuk contoh kami, kami perlu membuat daftar frasa / kata kunci berikut:
- pakaian
- Alas kaki
- Sepatu bot
- Gaun.
- T-shirt.
- Pakaian dalam
- Celana pendek
Frasa apa yang dimasukkan tidak berarti: Pakaian wanita, beli sepatu, gaun pada kelulusan, dll. Mengapa? - Frasa ini adalah "ekor" dari permintaan "pakaian", "sepatu", "gaun" dan akan ditambahkan ke kernel semantik secara otomatis pada tahap koleksi ke-2. Itu. Anda dapat menambahkannya, tetapi itu akan menjadi pekerjaan ganda yang tidak berarti.
Kunci apa yang harus Anda bugar? "Harfoots", "Boots" tidak sama dengan "Boots". Ini adalah bentuk kata yang penting, dan bukan kata atau tidak.
Seseorang memiliki daftar frasa kunci yang lama, dan siapa dia terdiri dari satu kata - jangan takut. Misalnya, toko online pintu untuk persiapan kernel semantik cukup mungkin cukup kata "pintu".
Jadi, pada akhir langkah ini, kita harus memiliki daftar yang sama.

2. Pengumpulan permintaan untuk kernel semantik
Untuk koleksi penuh yang lengkap, kami membutuhkan program. Saya akan menunjukkan contoh pada saat yang sama pada dua program:
- Pada bayar - keycollector. Bagi mereka yang memiliki, atau yang ingin membeli.
- Gratis - slovoeb. Program gratis bagi mereka yang belum siap untuk menghabiskan uang.
Buka programnya

Membuat proyek baru Dan mari kita sebut saja, misalnya, mysite

Sekarang, untuk mengumpulkan lebih lanjut kernel semantik, kita perlu melakukan beberapa hal:
Buat akun baru di Yandex Mail (lama tidak disarankan untuk digunakan karena fakta bahwa itu dapat dilarang untuk banyak permintaan). Jadi, Anda membuat akun, misalnya [Dilindungi Email] Dengan kata sandi super2018. Sekarang Anda perlu menentukan akun ini di pengaturan sebagai Ivan.ivanov: Super2018 dan tekan tombol "Simpan Perubahan" di bagian bawah. Baca lebih lanjut - pada tangkapan layar.

Kami memilih wilayah untuk mengkompilasi kernel semantik. Anda harus memilih hanya daerah di mana Anda akan pindah dan klik Simpan. Dari ini akan tergantung pada frekuensi permintaan dan apakah mereka akan jatuh ke dalam koleksi pada prinsipnya.

Semua pengaturan selesai, ia tetap menambahkan frasa jahat kami di langkah pertama dan klik tombol "Mulai Koleksi" dari kernel semantik.

Prosesnya sepenuhnya otomatis dan cukup panjang. Anda dapat melakukan kopi sambil membuat kopi, dan jika temanya lebar, misalnya, seperti yang kami kumpulkan - ini selama beberapa jam 😉
Setelah semua frasa mengumpulkan Anda untuk melihat sesuatu yang serupa:

Dan pada tahap ini selesai - lanjutkan ke langkah berikutnya
3. Membersihkan kernel semantik
Pertama, kita perlu menghapus permintaan yang tidak kita minati (neurozzi):
- Terkait dengan merek lain, misalnya, "Gloria Jeans", "Ecco"
- Permintaan informasi, misalnya, "saya memakai sepatu bot", "ukuran jeans"
- Serupa pada subjek, tetapi tidak terkait dengan bisnis Anda, misalnya, "B pakaian", "Grosir wanita"
- Permintaan, sama sekali tidak terkait dengan tema, misalnya, "Gaun Sims", "Cat in Boots" (permintaan semacam itu setelah pemilihan kernel semantik ada cukup banyak)
- Permintaan dari daerah lain, metro, kabupaten, jalan (tidak peduli wilayah apa yang Anda kumpulkan permintaan - wilayah lain masih muncul)
Pembersihan harus dilakukan secara manual sebagai berikut:

Kami memasukkan kata, tekan "Enter", jika di kernel semantik kami yang dibuat, itu adalah frasa yang kami butuhkan, kami mengalokasikan yang ditemukan dan klik Delete.
Saya sarankan memasukkan kata tidak sepenuhnya, tetapi menggunakan desain tanpa preposisi dan akhir, I.E. Jika kita menulis kata "kemuliaan", itu akan menemukan frasa "Beli di Gloria Jeans" dan "Beli di Gloria Jeans". Saat menulis "Gloria" - "Gloria" tidak akan ditemukan.
Dengan demikian, Anda harus melalui semua poin dan menghapus dari permintaan kernel semantik yang tidak perlu kepada Anda. Ini mungkin membutuhkan waktu yang cukup lama, dan mungkin akan berubah bahwa Anda menghapus sebagian besar kueri yang dikumpulkan, tetapi hasilnya akan menjadi daftar penuh yang penuh dan benar dari semua jenis permintaan yang dipromosikan untuk situs Anda.
Bongkar sekarang semua permintaan Anda ke Excel

Anda juga dapat menghapus query non-target secara besar-besaran dari semantik, asalkan Anda memiliki daftar. Anda dapat melakukan ini dengan stop-words dan mudah dilakukan untuk kelompok kata-kata khas dengan kota, metro, jalanan. Daftar kata-kata seperti yang saya gunakan dapat Anda unduh di bagian bawah halaman.
4. Clustering dari kernel semantik
Ini adalah bagian yang paling penting dan menarik - perlu untuk membagi peraturan kami pada halaman dan bagian yang secara agregat akan membuat struktur situs Anda. Sedikit teori - daripada dipandu oleh permintaan:
- Pesaing. Anda dapat memperhatikan bagaimana mengelompokkan kernel semantik dari pesaing Anda dari atas dan bertindak dengan cara yang sama, setidaknya dengan bagian utama. Dan juga untuk menonton halaman mana yang berada dalam ekstradisi permintaan frekuensi rendah. Misalnya, jika Anda tidak yakin untuk "melakukan atau tidak" bagian terpisah untuk permintaan "Red Leather Skirts", menggerakkan frasa ke mesin pencari dan melihat penerbitannya. Jika penerbitan berisi sumber daya di mana ada bagian seperti itu, itu berarti masuk akal untuk membuat halaman terpisah.
- Logika.. Buat seluruh pengelompokan kernel semantik menggunakan logika: struktur harus jelas dan mewakili halaman terstruktur halaman dengan kategori dan subkategori di kepala Anda.
Dan beberapa saran lagi:
- Tidak disarankan untuk menginstal kurang dari 3 permintaan ke halaman.
- Jangan membuat terlalu banyak level bersarang, cobalah untuk melakukannya sehingga mereka 3-4 (situs.ru / kategori / subkategori / sub-subkategori)
- Jangan melakukan URL yang panjang jika Anda memiliki banyak tingkat bersarang saat mengelompokkan kernel semantik, cobalah untuk mengurangi URL yang sangat pada kategori hierarki, I.E. Alih-alih "vash-site.ru/zhenskaya-odezhda/palto-dlya-zhenshin/krasnoe-palto", lakukan "vash-site.ru/zhenshinam/palto / krasnoe"
Sekarang untuk berlatih
Inti clustering pada contoh
Untuk memulai, kami akan membagikan semua permintaan untuk kategori utama. Melihat logika pesaing - kategori utama untuk toko pakaian akan: pakaian pria, pakaian wanita, pakaian anak-anak, serta sekelompok kategori lain yang tidak terikat ke lantai / usia, seperti hanya "sepatu" , pakaian luar.
Kami mengelompokkan kernel semantik bANTUAN UNXEL. Buka file dan tindakan kami:
- Kami membagi pada bagian utama
- Ambil satu bagian dan bagilah pada subbagian
Saya akan menunjukkan pada contoh satu bagian - pakaian pria dan ayatnya. Untuk memisahkan kunci dari orang lain, Anda perlu menyorot seluruh lembar dan klik Pemformatan Bersyarat-\u003e Aturan Pemilihan Kode-\u003e Teks berisi

Sekarang di jendela yang terbuka, kita menulis "suami" dan tekan Enter.

Sekarang semua kunci kami pada pakaian pria disorot. Cukup menggunakan filter untuk memisahkan kunci yang dipilih dari sisa kernel semantik kami yang dirakit.
Jadi nyalakan filter: Anda perlu menyorot kolom dengan permintaan dan tekan penyortiran dan filter-\u003e filter

Dan sekarang disortir

Buat lembar terpisah. Potong garis yang dipilih dan masukkan di sana. Dengan cara ini Anda perlu melanjutkan dan mematahkan kernel.
Ubah nama lembar ini menjadi "pakaian pria", selembar tempat lain adalah kernel semantik, beri nama "Semua permintaan". Kemudian buat lembar lain, beri nama "struktur" dan taruh dulu. Pada halaman struktur, buat pohon. Anda harus berhasil seperti ini:

Sekarang kita perlu membagi bagian besar pakaian pria pada subbagian dan sub-subseksi.
Untuk kenyamanan penggunaan dan transisi sesuai dengan kernel semantik Anda yang berkerumun, tempatkan referensi ke struktur ke lembar yang sesuai. Untuk melakukan ini, klik kanan pada item yang diinginkan dalam struktur dan lakukan seperti pada tangkapan layar.

Dan sekarang kita perlu memisahkan tangan Anda untuk berbagi permintaan, secara bersamaan menghilangkan apa yang mungkin tidak diperhatikan dan dihapus pada fase pembersih kernel. Pada akhirnya, berkat pengelompokan kernel semantik, Anda harus memiliki struktur yang mirip dengan ini:


Begitu. Apa yang kami pelajari untuk dilakukan:
- Pilih permintaan yang Anda butuhkan untuk mengumpulkan kernel semantik
- Kumpulkan semua frasa yang mungkin untuk permintaan ini
- Bersih
- Cluster dan buat struktur
Itu berkat menciptakan kernel semantik yang dikelompokkan, Anda dapat melakukannya:
- Buat struktur di situs
- Buat menu
- Menulis teks, Menauring, Taitla
- Kumpulkan posisi untuk melacak speaker berdasarkan permintaan
Sekarang sedikit tentang program dan layanan
Program untuk mengumpulkan kernel semantik
Di sini saya akan menjelaskan tidak hanya program, tetapi juga plugin dan layanan online yang saya gunakan
- Yandex Wordstat Assistant adalah plugin, terima kasih yang mana, lebih mudah untuk memilih permintaan dari Vordstat. Bagus untuk penyusunan cepat inti di situs kecil atau 1 halaman.
- Caicollector (slobel - versi gratis) - Program penuh untuk pengelompokan dan menciptakan kernel semantik. Evoids popularitas besar. Sejumlah besar fungsional selain arah utama: pemilihan kunci dari tumpukan sistem lain, kemungkinan autoklasi, mengumpulkan posisi di Yandex dan Google dan banyak lagi.
- Just-Magic - layanan online multifungsi untuk membuat inti, menulis, menguji kualitas teks dan fungsi lainnya. Layanan gratis secara kondisional, untuk pekerjaan penuh yang Anda butuhkan untuk membayar biaya berlangganan.
Terima kasih telah membaca artikel. Berkat manual langkah demi langkah ini, Anda dapat membuat kernel semantik situs Anda untuk dipromosikan di Yandex dan Google. Jika Anda memiliki pertanyaan yang tersisa - tanyakan di komentar. Di bawah ini adalah bonus.
Kernel semantik adalah tema taruhan yang cantik, bukan? Hari ini kami akan memperbaikinya dengan mengumpulkan semantik dalam pelajaran ini!
Tidak percaya? - Lihatlah diri Anda - itu cukup hanya untuk berkendara ke Yandex atau Google frase inti semantik situs. Saya pikir hari ini saya akan memperbaiki kesalahan yang mengganggu ini.
Tetapi pada kenyataannya, apa yang dia untuk Anda - semantik sempurna? Anda mungkin berpikir bahwa untuk pertanyaan bodoh, tetapi pada kenyataannya dia benar-benar Nehall, hanya sebagian besar Web-Masters dan pemilik situs web percaya bahwa mereka dapat membuat kernel semantik dan bahwa setiap anak sekolah akan mengatasi semua ini, ya, mereka sendiri berusaha mengajar orang lain ... Tetapi pada kenyataannya, semuanya jauh lebih sulit. Begitu saya bertanya kepada saya - apa yang harus saya lakukan di awal? - Situs dan konten atau sez kernel., dan bertanya kepada seseorang yang tidak menganggap dirinya pendatang baru di CEO. Sini masalah ini Dan izinkan saya memahami semua kesulitan dan ambiguitas masalah ini.
Kernel semantik adalah dasar dari fondasi - ruang pertama yang berdiri sebelum dan memulai apapun kampanye iklan di internet. Seiring dengan ini, semantik situs ini adalah proses paling kuat yang membutuhkan banyak waktu, tetapi dengan lebih banyak terima kasih dalam hal apapun.
Nah ... mari kita buat -nya bersama!
Kata pengantar kecil.
Untuk membuat bidang semantik situs, kami akan memerlukan program satu-satunya - Kolektor utama.. Pada contoh kolektor, saya akan mencari tahu contoh mengumpulkan kelompok kecil. Sebagai tambahannya program berbayar, Ada juga analog gratis seperti slobel dan lainnya.
Semantik dikumpulkan dalam beberapa tahap dasar, di antaranya harus dialokasikan:
- brainstorming - Analisis frasa dasar dan pelatihan parsing
- parsing - Perluasan Semantik Dasar Berdasarkan Vordstat dan Sumber Lain
- pembukaan - jatuh setelah parsing
- analisis - Analisis frekuensi, musiman, persaingan dan indikator penting lainnya
- penyempurnaan - Gruping, pemisahan nukleus frasa komersial dan informasi
Tentang yang paling tahap Penting Koleksi dan akan dibahas di bawah ini!
Video - Kompilasi kernel semantik pesaing
Brainstorming saat membuat kernel semantik - saringan otak
Pada tahap ini diperlukan dalam pikiran untuk membuat pilihaninti semantik situs dan menghasilkan sebanyak mungkin frasa di bawah subjek kita. Jadi, luncurkan kolektor kay dan pilih wordStat Parsing., seperti yang ditunjukkan pada tangkapan layar:

Kami memiliki jendela kecil, di mana Anda perlu memperkenalkan frasa maksimum pada subjek kami. Seperti yang sudah saya katakan, Dalam artikel ini kami akan membuat contoh set frasa untuk blog iniJadi frasa bisa sebagai berikut:
- sEO Blog.
- sEO Blog.
- blog tentang SEO.
- blog tentang SEO.
- promosi
- promosi proyek
- promosi
- promosi
- promosi blog.
- promosi blog
- promosi blog.
- promosi blog
- artikel Promosi
- promosi yang diaktifkan
- miralinks.
- bekerja di Sape.
- membeli tautan
- pembelian tautan
- optimasi
- pengoptimalan Halaman
- optimalisasi Internal.
- promosi independen
- cara mempromosikan sumber daya
- cara mempromosikan situs Anda
- cara mempromosikan situs sendiri
- cara mempromosikan situs sendiri
- promosi independen
- promosi gratis
- promosi gratis
- optimisasi Mesin Pencari
- cara mempromosikan situs di Yandex
- cara mempromosikan situs di Yandex
- promosi di bawah Yandex.
- promosi di Google.
- promosi di google.
- pengindeksan
- indeksasi akselerasi
- pilih Situs Donor
- checkout donor.
- promosi postov.
- menggunakan posting
- promosi blog.
- algoritma Yandex.
- perbarui Titz.
- cari Pembaruan Basis Data
- updiet yandex.
- tautan selamanya
- rEFERENSI ENAL
- rent Links.
- referensi Sewa
- tautan dengan pembayaran bulanan
- kompilasi nukleus semantik
- promosi rahasia
- promosi rahasia
- seo rahasia.
- rahasia Optimasi
Saya pikir itu cukup, dan daftar dari lantai halaman;) Secara umum, idenya adalah bahwa pada tahap pertama Anda perlu menganalisis industri kami untuk memaksimalkan dan memilih sebanyak mungkin frasa yang mencerminkan subjek situs. Meskipun jika Anda melewatkan sesuatu pada tahap ini - jangan putus asa - frasa umplifikasi tentu akan muncul pada tahap-tahap berikutHanya perlu melakukan banyak pekerjaan ekstra, tetapi tidak ada yang mengerikan. Kami mengambil daftar dan salin ke kolektor utama. Selanjutnya, klik tombol - Poule dengan yandex.wordstat.:
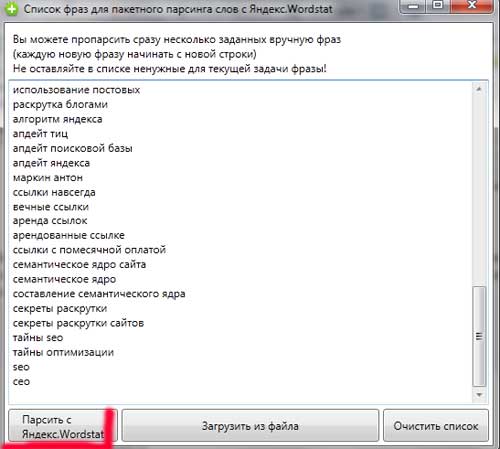
Parsing mungkin membutuhkan waktu yang cukup lama, jadi Anda harus bersabar. Kernel semantik biasanya berjalan selama 3-5 hari dan hari pertama Anda akan pergi ke persiapan kernel semantik dasar dan parsing.
Tentang Cara Bekerja dengan Sumber Daya, Cara Memilih Kata Kunci Saya menulis instruksi terperinci. Dan Anda dapat mempelajari tentang promosi situs pada permintaan NF.
Selain itu, saya akan mengatakan bahwa alih-alih brainstorming, kita dapat menggunakan semantik pesaing dengan salah satu layanan khusus, misalnya, Spypwords. Dalam antarmuka layanan ini, kami cukup memasukkan kata kunci yang Anda butuhkan dan melihat pesaing utama yang hadir pada frasa ini di bagian atas. Selain itu, semantik dari situs setiap pesaing dapat sepenuhnya diturunkan dengan layanan ini.

Selanjutnya, kita dapat memilih salah satu dari mereka dan mengeluarkan permintaannya yang akan ditinggalkan dari sampah dan digunakan sebagai semantik dasar untuk parsing lebih lanjut. Atau kita bisa melakukannya lebih mudah dan digunakan.
Membersihkan semantik
Segera setelah Wordstat Parsing Berhenti Berhenti - sudah waktunya untuk memotong kernel semantik. Tahap ini sangat penting, jadi kita harus menerimanya dengan perhatian.
Jadi, parsing saya berakhir, tetapi frasa ternyata BanyakDan oleh karena itu, kata-kata kata-kata dapat mengambil terlalu banyak dari kita. Oleh karena itu, sebelum melanjutkan ke definisi frekuensi, perlu untuk menghasilkan pembersihan kata-kata primer. Kami akan melakukannya dalam beberapa tahap:
1. Filter kueri dengan frekuensi yang sangat rendah
Untuk melakukan ini, didasarkan pada simbol penyortiran dalam frekuensi, dan mulai mengekstrak semua permintaan yang memiliki frekuensi di bawah 30:
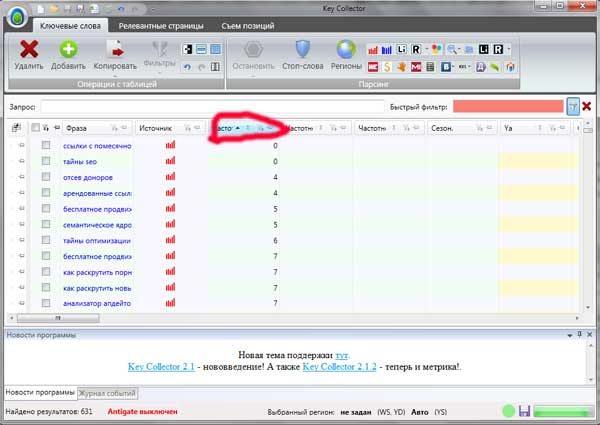
Saya pikir dengan item ini Anda dapat dengan mudah mengatasinya.
2. Hapus tidak cocok dalam permintaan makna
Ada pertanyaan yang memiliki frekuensi yang cukup dan persaingan rendah, tetapi mereka sama sekali tidak cocok untuk subjek kita. Tombol-tombol tersebut harus dihapus sebelum memeriksa tujuan yang tepat dari kunci, karena Periksa mungkin butuh banyak waktu. Kami akan menghapus kunci seperti itu kami akan secara manual. Jadi, untuk blog saya, mereka tidak perlu:
kursus Optimasi Mesin Pencari jual Situs Promosi
Analisis nukleus semantik
Pada tahap ini, kita perlu menentukan frekuensi kunci kita, yang perlu Anda klik pada simbol kaca pembesar, seperti yang ditunjukkan pada gambar:

Prosesnya cukup panjang, sehingga Anda bisa pergi dan membuat teh sendiri)
Ketika cek berhasil - perlu untuk terus membersihkan kernel kami.
Saya sarankan Anda menghapus semua tombol dengan frekuensi kurang dari 10 permintaan. Juga, untuk blog Anda, saya menghapus semua permintaan yang memiliki nilai di atas 1.000, karena saya masih tidak berencana untuk permintaan tersebut.
Ekspor dan pengelompokan kernel semantik
Jangan berpikir bahwa tahap ini akan menjadi yang terakhir. Tidak semuanya! Sekarang kita perlu mentransfer kelompok yang dihasilkan untuk mengeluarkan visibilitas maksimum. Selanjutnya, kita akan memilah-milah halaman dan kemudian kita akan melihat banyak kekurangan, koreksi yang dan kita akan berurusan dengan.
Semantik diekspor situs di Exel sepenuhnya mudah. Untuk melakukan ini, Anda hanya perlu mengklik karakter yang sesuai, seperti yang ditunjukkan pada gambar:
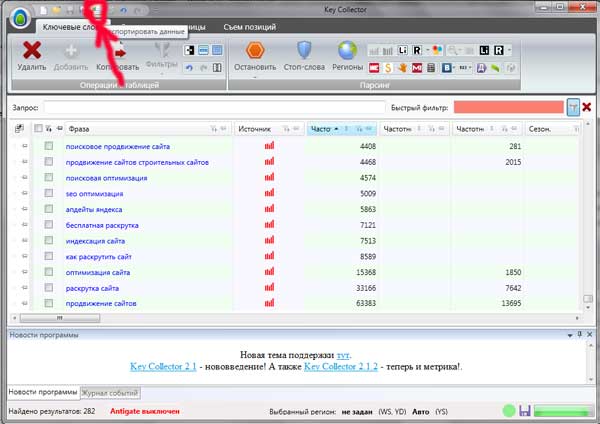
Setelah memasukkan ke Exel, kita akan melihat gambar berikut:

Kolom yang ditandai dengan warna merah harus dihapus. Kemudian buat tabel lain di Exel, di mana kernel semantik terakhir akan terkandung.
Tabel baru akan menjadi 3 kolom: URLhalaman, frasa kata kunci dan itu frekuensi. Sebagai URL, pilih atau sudah halaman atau halaman yang ada yang akan dirancang dalam perspektif. Untuk memulai, mari kita pilih tombol untuk halaman utama blog saya:

Setelah semua manipulasi, kami melihat gambar berikut. Dan segera menyarankan beberapa kesimpulan:
- kueri frekuensi seperti itu, sebagai perlu memiliki ekor yang jauh lebih besar dari frasa frekuensi yang lebih sedikit daripada yang kita lihat
- Berita SEO.
- kunci baru muncul, yang kami tidak ambil sebelumnya - artikel CEO. Perlu menganalisis kunci ini
Seperti yang saya katakan, tidak ada kunci dari kami bersembunyi. Langkah selanjutnya bagi kita akan menjadi brainstorming dari tiga frasa ini. Setelah brainstorming, kami ulangi semua langkah mulai dari item pertama untuk tombol-tombol ini. Anda semua bisa tampak terlalu lama dan membosankan bagi Anda, tetapi itu adalah - kompilasi nukleus semantik sangat bertanggung jawab dan pekerjaan yang melelahkan. Tetapi, sekte yang dikomposisikan secara kompeten akan sangat membantu dalam mempromosikan situs dan dapat sangat banyak untuk menghemat anggaran Anda.
Setelah semua hasil, kami dapat mendapatkan kunci baru untuk halaman utama blog ini:
- blog SEO terbaik.
- berita SEO.
- artikel SEO.
Dan beberapa lainnya. Saya pikir teknik ini bisa dipahami oleh Anda.
Setelah semua manipulasi ini, kita akan melihat halaman mana dari proyek kita perlu diubah (), dan halaman baru apa yang perlu ditambahkan. Sebagian besar kunci ditemukan oleh kami (dengan frekuensi hingga 100, dan terkadang jauh lebih tinggi) dapat dengan mudah dipromosikan sendiri.
Casting terakhir.
Pada prinsipnya, inti semantik hampir siap, tetapi ada yang lain poin pentingyang akan membantu kita dengan jelas meningkatkan kelompok keluarga kita. Untuk ini kita perlu segupel.
* Bahkan, Anda dapat menggunakan layanan serupa yang memungkinkan Anda untuk belajar persaingan dengan kata kunci, misalnya, Mutagen!
Jadi, kami membuat tabel lain di Exel dan menyalin hanya nama kunci di sana (kolom sedang). Untuk tidak menghabiskan banyak waktu, saya hanya akan menyalin tombol untuk halaman utama blog Anda:


Kemudian periksa biaya untuk mendapatkan satu transisi ke kata kunci kami:
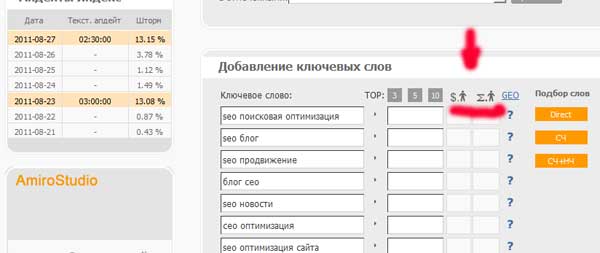
Biaya transisi ke beberapa frasa melebihi 5 rubel. Frasa seperti itu perlu dikecualikan dari kernel kita.

Mungkin preferensi Anda akan agak berbeda, maka Anda dapat mengecualikan frasa atau sebaliknya yang lebih murah. Dalam kasusnya, saya menghapus 7 frasa.
Informasi bermanfaat!
menurut persiapan kernel semantik, dengan fokus pada skrining kata kunci paling rendah kompetitif.
Jika Anda memiliki toko online Anda - baca baca , di mana dijelaskan bagaimana inti semantik dapat digunakan.
Clustering dari kernel semantik
Saya yakin sebelumnya Anda memilikinya untuk mendengar kata ini sebagaimana diterapkan pada promosi pencarian. Mari kita cari tahu seperti apa binatang buas begitu dan mengapa diperlukan saat mempromosikan situs.
Model promosi pencarian klasik terlihat seperti ini:
- Pemilihan dan Analisis Kueri Pencarian
- Mengelompokkan pertanyaan di halaman situs (halaman arahan)
- Mempersiapkan teks SEO untuk halaman arahan berdasarkan grup kueri untuk halaman ini
Untuk memfasilitasi dan meningkatkan tahap kedua dalam daftar di atas dan berfungsi sebagai pengelompokan. Intinya, clustering adalah metode perangkat lunak yang berfungsi untuk menyederhanakan tahap ini saat bekerja dengan semantik besar, tetapi semuanya tidak begitu sederhana karena kelihatannya pada pandangan pertama.
Untuk pemahaman yang lebih baik tentang teori clustering, Anda harus membuat tamasya kecil ke sejarah SEO:
Secara harfiah beberapa tahun yang lalu, ketika istilah clustering tidak melihat keluar untuk setiap sudut - Sienes, dalam mayoritas kasus, dikelompokkan oleh semantik dengan tangan mereka. Tetapi ketika mengelompokkan semantik besar dalam 1000, 10.000 dan bahkan 100.000 permintaan, prosedur ini berubah menjadi catguard nyata untuk orang biasa. Dan kemudian metodologi untuk kelompok semantik mulai digunakan di mana-mana (dan hari ini banyak menggunakan pendekatan ini). Teknik pengelompokan semantik melibatkan menggabungkan satu kelompok pertanyaan yang memiliki hubungan semantik. Sebagai contoh - Permintaan "Beli mesin cuci"Dan" Beli mesin cuci hingga 10.000 "digabungkan menjadi satu kelompok. Dan semuanya akan baik-baik saja, tetapi metode ini Berisi sejumlah masalah kritis dan untuk pemahaman mereka, perlu untuk memperkenalkan istilah baru dalam narasi kami, yaitu - " permintaan niat”.
Cara termudah untuk menggambarkan istilah ini dapat sebagai kebutuhan pengguna, keinginannya. Introven tidak lebih dari keinginan pengguna yang memasukkan permintaan pencarian.
Dasar pengelompokan semantik adalah untuk mengumpulkan dalam satu kelompok permintaan yang memiliki niat yang sama, atau sedekat mungkin intensitas, dan di sini 2 fitur menarik segera muncul, yaitu:
- Niat yang sama dapat memiliki beberapa permintaan yang tidak memiliki kedekatan semantik, misalnya - "layanan mobil" dan "mendaftar"
- Permintaan yang memiliki kedekatan semantik absolut dapat berisi intensis yang sangat berbeda, misalnya, situasi buku teks adalah "ponsel" dan "ponsel". Dalam satu kasus, pengguna ingin membeli telepon, dan di yang lain untuk menonton film
Jadi, pengelompokan semantik dalam korespondensi semantik tidak memperhitungkan intensitas permintaan. Dan kelompok-kelompok yang disusun dengan cara ini tidak akan memungkinkan Anda untuk menulis teks yang akan jatuh ke atas. Pada saat pengelompokan tangan untuk menghilangkan kesalahpahaman ini, para pria dengan profesi "Prudial Spesialis SEO.»Menganalisis penerbitan dengan tangan Anda.
Inti dari Clustering adalah perbandingan dari penerbitan mesin pencari yang terbentuk untuk mencari keteraturan. Dari definisi ini, Anda harus segera membuat catatan untuk diri saya sendiri bahwa pengelompokan itu sendiri bukanlah kebenaran pada contoh terakhir, karena penerbitan yang terbentuk mungkin tidak mengungkapkan maksud penuh (di basis Yandex mungkin hanya menjadi situs yang secara benar menggabungkan permintaan grup).
Mekanika clustering sederhana dan terlihat seperti ini:
- Sistem secara bergantian memasuki semua permintaan yang diserahkan ke dalamnya penerbitan pencarian dan ingat hasil dari atas
- Setelah input alternatif dari permintaan dan memelihara hasil, sistem mencari persimpangan dalam ekstradisi. Jika situs yang sama adalah dokumen yang sama (halaman situs) berada di bagian atas segera dalam beberapa permintaan, maka permintaan ini secara teoritis dapat digabungkan menjadi satu grup
- Itu menjadi relevan parameter seperti itu sebagai kelompok pengelompokan, yang berbicara sistem, berapa lama harus ada persimpangan yang diminta dapat ditambahkan ke satu grup. Misalnya, kekuatan pengelompokan 2 berarti bahwa setidaknya dua persimpangan harus ada dalam ekstradisi 2 menit. Juga lebih mudah - setidaknya dua halaman dari dua situs yang berbeda harus hadir secara bersamaan di bagian atas satu per satu dan permintaan lainnya. Contoh di bawah ini.
- Ketika mengelompokkan semantik besar, logika tautan antar permintaan relevan, berdasarkan yang ada 3 jenis dasar pengelompokan: lunak, tengah dan keras. Kami masih akan berbicara tentang jenis clustering dalam catatan buku harian berikut ini.
Cara membuat komponen informasi dari situs sehingga pelanggan dapat dengan cepat menemukannya
Jadi, Anda memutuskan untuk membuat portal di mana orang dapat menemukan informasi menarik, tetapi Anda tahu bahwa kami membutuhkan beberapa keterampilan untuk mempromosikan, yaitu, kompilasi kernel semantik. Tetapi semantik hanya menyarankan bahwa situs akan diisi dengan makna. Oleh karena itu, akan diberitahukan di sini bagaimana membunuh dua hares sekaligus - dan menarik audiens untuk informasi yang bermanfaat, dan tidak memaksa mesin pencari "bersumpah".Pendekatan lama dan baru untuk mengisi informasi situs dan kernel semantik
Membuat situs, pertama-tama, Anda perlu tahu apa yang menarik bagi pengguna dan bagaimana mereka mencari informasi - setelah semua, data yang sama dapat ditemukan secara berbeda. Dan juga perlu memperhitungkan kepentingan pengguna - karena karena semua informasi yang akan disajikan di situs Anda harus menarik bagi pembaca mana pun, maka orang perlu terlibat dalam membaca. Dan tanpa mesin pencari, tidak perlu dilakukan - Yandex dan Google tidak akan "menerima" portal untuk Anda sendiri jika sejumlah kondisi dijalankan.Secara khusus, penyebaran kata kunci, di mana frasa pencarian disusun pada seluruh portal. Oleh karena itu penting untuk mengisi teks beban semantik. Ini tidak lebih dari inti semantik (semantik) - kombinasi kata dan frasa yang mencerminkan orientasi tematik dan struktur sumber daya Internet. Secara umum, semantik adalah pembagian linguistik, yang mengeksplorasi konten semantik unit (elemen) bahasa. Semuanya, mungkin, melihat ekspresi seperti itu di situs sebagai "karakter utama membantu teman untuk menonton film online untuk tidak menjadi korban penjahat" (frasa perkiraan, esensi, dapat dimengerti). Di sini pengguna dengan jelas melihat bahwa ada kata kunci "menonton film online", tetapi itu tidak dilakukan untuknya, tetapi untuk mesin pencari. Akibatnya, ia mungkin merasa tertipu - tidak perlu berguling-guling seperti itu, tidak ada gunanya membawanya. Teks yang kompeten dengan diperkenalkannya kernel semantik akan dianggap jauh lebih baik.
Agar pengguna dapat menemukan sumber daya Internet, Anda dapat menggunakan dalam dua cara:
- Pertama, menganalisis permintaan pencarian pelanggan, mengikuti yang untuk membuat struktur portal (semantik, atau semantik, kernel, dalam hal ini melakukan nilai tegas dalam kerangka kerja dan struktur sumber daya);
- pertama-tama buat rencana tentang bagaimana struktur situs akan terlihat, sebelum beralih ke analisis apa yang diminati pengguna (kernel semantik didistribusikan sudah pada bingkai portal jadi).
Pendekatan pertama melibatkan adaptasi dengan kondisi saat ini - dan opsi ini benar-benar berfungsi. Dalam hal ini, struktur sumber daya dirangkum di bawah kata kunci dan tetap menjadi objek. Pilihan kedua seperti dalam lagu mesin waktu "Anda tidak boleh muak untuk dunia yang dapat diubah - suatu hari dia akan mengemudi di bawah kita." Dengan menggunakan pendekatan ini, pengusaha itu sendiri memilih bahwa ia ingin memberi tahu pengguna potensial. Pendekatan ini dapat disebut semacam proaktif - dan pengusaha dalam hal ini akan menjadi subjek.
Penting untuk dipahami bahwa tujuan utama pemasaran dan bisnis adalah fokus pada klien. Dan metode kedua hanya menyediakannya. Artinya, seorang wirausahawan atau pemasar memutuskan data apa yang harus diberikan kepada audiens menggunakan portalnya - dan, tentu saja, harus dimiliki oleh beberapa pengetahuan tentang apa yang akan diberitahu di situs webnya. Oleh karena itu, pertama-tama merencanakan desain sumber daya yang patut dicontoh, daftar halaman awal, dan kemudian menganalisis bagaimana pengguna mencari informasi yang Anda butuhkan. Dan dengan bantuan konten informasi sumber daya, bertanggung jawab atas pertanyaan yang menentukan pengguna mesin pencari.
Opsi pertama adalah metode "Celebular". Dia sudah lama memimpin, dan menerapkannya sekarang. Dengan metode ini, ada frasa kunci yang membuat pencipta situs hanya ingin mencapai bagian paling atas dari mesin pencari, dan kemudian struktur sumber daya dan tombol dibuat pada semua halaman. Konten informasi dioptimalkan dengan kata-kata dan frasa kunci.
Tetapi metode ini dalam praktik menunjukkan bahwa, mungkin mesin pencari tertipu, tetapi orang tidak. Nilai informasi dari penurunan sumber daya - orang tidak tertarik membaca teks-teks yang kata kunci mana dapat dilacak, ia berpikir di suatu tempat selingkuh. Tetapi pemasaran dibuat bukan demi hal ini - tren bentuk bisnis, dan pengusaha memilih apa yang harus dibicarakan dengan pengguna. Pemasaran tidak boleh "menari di bawah Dudka orang lain", jika tidak, audiens berhenti menghormatinya - ia harus membentuk lingkungan itu sendiri, tetapi pada saat yang sama berorientasi pada pelanggan. Tidak, atau yang lain, tidak ada pendekatan "semen", dan itulah sebabnya dia marah.
Sementara itu, beberapa prospektif kueri untuk mesin pencari, dan di sini juga dapat dipahami, karena ada persaingan besar di internet saat ini. Selain itu, situs diisi dengan tombol yang "suka" mesin pencari.
Hasil yang direncanakan dari pembangunan kernel semantik adalah daftar kueri utama yang tersebar di halaman portal. Ini termasuk URL halaman, permintaan yang menunjukkan frekuensi.
Desain situs
Struktur, atau desain, sumber daya internet adalah jenis hierarkis, atau peringkat, skema halaman web. Dengan membuatnya, tugas-tugas semacam itu diselesaikan sebagai:- Merencanakan strategi informasi dan struktur informasi kepada pengguna;
- Memastikan kepatuhan instruksi portal dari mesin pencari;
- Garansi sumber daya ergonomis untuk klien.
Untuk melakukan ini, Anda dapat menggunakan semua yang nyaman - bahkan MS Word atau Cat, Anda juga dapat menggambarnya dari tangan atau pada tablet dengan stylus. Saat merencanakan struktur, Anda perlu menjawab 2 pertanyaan:
- Informasi apa yang Anda sukai pengusaha yang ingin Anda sampaikan kepada pelanggan;
- Di mana mempublikasikan satu atau konten lain.
Jika Anda mengambil desain portal permen kecil sebagai contoh, itu akan mencakup halaman informasi (resep, riwayat kue), artikel dan katalog barang (showcase). Jika Anda mengirimkan ini dalam bentuk skema, mungkin terlihat seperti ini:
Skema situs hierarkis
Selanjutnya, desain disusun dalam bentuk tabel. Ini menunjukkan hierarki, halaman nama diindikasikan, kolom dengan kata kunci dan frekuensinya dihidupkan, serta menunjukkan URL dari halaman. Jika Anda mengirimkan tabel desain situs permen, mungkin berikutnya:

Ini adalah bagaimana struktur (desain) sumber daya Internet dapat diserahkan sebagai tabel
Untuk memulai, kita hanya tahu "judul halaman" dan " Legenda", Dan" URL "," kunci "dan" frekuensi "akan diisi nanti.
Kata kunci.
Penting untuk memahami kata kunci apa, dan kueri pencarian mana yang menerapkan klien - tanpa ini tidak akan ada pembuatan situs yang efektif dan menyajikan informasi kepada pengguna. Anda dapat menerapkan salah satu layanan untuk memilih kata kunci - tetapi penting untuk memahami bahwa kata-kata ini sesuai.Jadi, kunci tersebut adalah kata-kata atau frasa yang digunakan oleh pengguna untuk menemukan yang diinginkan dan informasi. Contoh sederhana adalah menyiapkan pai, ia memasuki sistem permintaan "resep Apple Charpeck dengan foto" di mesin pencari.
Tombol dapat dibagi menjadi beberapa kelompok:
Tergantung pada popularitasnya, mengalokasikan:
- Permintaan dengan frekuensi rendah (mereka ditampilkan 100-1.000 / bulan);
- Frekuensi menengah (1.000-5.000 tayangan);
- Frekuensi tinggi (permintaan untuk 5.000-10.000 tembakan per bulan).
Tergantung pada kebutuhan pelanggan bervariasi:
- Informasi (jika pengguna perlu menemukan informasi apa pun - misalnya, "Cara membersihkan pakaian dari Fuccin", "Vitamin mana yang meningkatkan kondisi kulit");
- Transaksional (kueri yang dikeluarkan untuk membuat kesepakatan, tetapi tanpa menentukan situs atau toko tertentu - "Beli sofa", "Unduh Game", "Buat aplikasi untuk kredit");
- Navigasi (jika klien ingin mencari informasi di situs tertentu - misalnya, "WebMoney untuk membuat kartu", "Lacak track-code Whitepoche", "Euroopt Diskon");
- Lainnya (jika sulit untuk menentukan apa yang diinginkan pengguna - misalnya, memperkenalkan frasa "otak", tidak jelas bahwa seseorang ingin tahu - struktur, organ, fakta Menarik Tentang dia, dan selain itu, tidak jelas otak seperti apa tentang dorsal atau kepala).
Sekarang untuk setiap item. Perbedaan dalam menilai popularitas tergantung pada bagaimana jelas dari konteks, pada apakah pengguna populer dengan popularitas satu atau tema lain. Keputusan Bersyarat, beberapa ahli menentukan jumlah hit yang lebih kecil untuk permintaan. Contohnya adalah kasus berikut: untuk situs yang berdagang dengan smartphone, permintaan "untuk membeli samsung Telepon"Frekuensinya menunjukkan 6.000 / bulan - frekuensi pertengahan. Pada saat yang sama, untuk klub olahraga, permintaan "Pelatihan Tinju Thailand" dengan frekuensi pandangan dalam 1.000 permintaan adalah frekuensi tinggi.
Semua ini harus diperhitungkan dan merancang kernel semantik yang sangat luas, dan harus diperkaya karena frasa frekuensi rendah, karena jika Anda percaya statistik, maka dari 60% menjadi 80% dari semua permintaan pengguna dapat dikaitkan dengan rendah frekuensi. Artinya, sebagai sumber daya utama yang memungkinkan Anda untuk menarik pelanggan potensial ke situs, tombol frekuensi rendah harus digunakan - ini adalah jenis kata kunci arah sempit. Anda perlu mencairkannya dengan permintaan frekuensi tinggi dan menengah.
Untuk secara efektif menggunakan grup kedua, menurut kata kunci mana yang dibedakan, itu perlu, pertama-tama, ketika mendistribusikan kunci pada halaman atau membuat rencana pengisian informasi untuk memperhitungkan kebutuhan pelanggan. Artinya, artikel di mana pengguna akan diberikan informasi, harus menjawab pertanyaan mereka. Ini adalah bagian besar dari frasa kunci tanpa niat tertentu - yaitu, dalam artikel artikel, Anda tidak boleh memasukkan kata-kata "Beli", "Unduh" dan sejenisnya. Bagian "Shop", "katalog" Katalog IL "Storefine" didorong untuk memenuhi permintaan transaksional pengguna.
Itu harus diingat bahwa sebagian besar permintaan transaksi komersial. Dan sesuai, memutuskan untuk menjual kue, Anda harus bersaing dengan "kue Moskow", "Dobryninsky dan Partners" dan "Wina Shop" - yang paling produsen besar permen Tetapi jika kita secara kompeten menggunakan rekomendasi di atas, semuanya menjadi jauh lebih mudah. Perluas kernel teks semantik sebanyak mungkin dan kurangi frekuensi kueri. Misalnya, frekuensi permintaan "untuk membeli kue rubel Amerika" dalam frekuensi akan lebih rendah dari "beli kue Amerika."
Membangun permintaan pencarian
Frasa itu konsep Umumyang termasuk pribadi. Jadi dengan frasa untuk pencarian - mereka termasuk tubuh, specifier dan ekornya. Misalnya, mengambil pertanyaan pencarian "Kue" sebagai dasar, kami tidak dapat memahami apa yang dibutuhkan pengguna untuk menentukan permen, membelinya atau hanya gambar. Permintaan itu sendiri frekuensi tinggi, dan ini berarti persaingan tinggi dalam memberikan hasil. Selain itu, pengenalan kueri akan membawa banyak panggilan ke situs web klien, sama sekali tidak tertarik untuk mendapatkan informasi yang Anda berikan, dan ini akan secara negatif mempengaruhi faktor perilaku. Dan semua karena permintaan seperti itu hanya berisi tubuh.Jika kita memasukkan add-on dalam bentuk kata "Beli", kita mendapatkan inklusi dan specifier - apa yang menentukan niat klien. Anda dapat mengganti kata "membeli" ke "resep", dan kemudian permintaan seperti itu akan menjadi informasi, dan jika Anda memasukkan "kue saya suka kue", maka pertanyaan seperti itu akan navigasi. Oleh karena itu, itu dari specifier bahwa kunci mempengaruhi kata kunci ke satu atau jenis kata kunci lainnya.
Kadang-kadang Anda dapat memenuhi itu, pengguna, ingin menjual hal tertentu, memperkenalkan permintaan untuk "membeli" untuk melihat di mana orang paling banyak membeli subjek ini.

Jika Anda memasukkan frasa "Beli kue di Moskow" atau "Beli kue untuk memesan", maka bagian terakhir dari permintaan pencarian adalah ekornya. Dia hanya mengklarifikasi beberapa detail tentang bagaimana atau di mana klien berniat untuk melakukan ini. Jadi, jika klien perlu tahu toko tertentu, permintaan akan menjadi navigasi.
Struktur bingkai untuk pencarian
Jika kita melihat contoh-contoh berikut: "Beli kue rumah di Alma-Ata", "Resep Kue Napoleon", "Beli Kue Pengiriman", kita akan melihat bahwa dalam setiap situasi ada tujuan tertentu dari pengguna, Dan ekornya hanya menentukan detailnya.Oleh karena itu, untuk kernel semantik, terminologi utama yang terkait dengan layanan dan barang akan disajikan pada portal, atau dengan kegiatan kewirausahaan dan kebutuhan pelanggan. Jadi, jika seseorang membutuhkan produk gula-gula, akan tertarik pada kue, marshmallow dan sampah, marshmallow, wafel, kue, meringue, cupcake, dll. Ini adalah tubuh kueri Utama. Dan kemudian menemukan spesifik dan ekor. Berkat frasa dengan "ekor" yang Anda miliki dan meningkatkan cakupan, dan pada saat yang sama menjadi kurang "pesaing pencarian".
Sumber daya internet untuk membuat kernel semantik (pemilihan nilai-nilai kunci)
Untuk mengumpulkan kata kunci untuk situs Anda, ada banyak asisten yang memfasilitasi kehidupan seorang pengusaha. Ada yang dibayar, yang diperlukan jika situsnya besar atau set, dan gratis, cocok untuk portal kecil, opsi.Dalam artikel tersebut, kami mempertimbangkan sumber daya berikut:
- Keycollector (dibayar);
- Slovoeb (gratis);
- Wordstat dari yandex'a (gratis);
- AdWords dari Google (GRATIS).
Kolektor utama.
Ini adalah alat berbayar dengan berbagai fungsi. Ini mengotomatiskan operasi yang dibutuhkan untuk membangun kernel semantik. Anda dapat, tentu saja, gunakan analog gratis dari program ini, tetapi untuk ini menggunakan beberapa sumber Internet sekaligus, karena program ini hampir tidak terbatas. Bahkan, layanan ini Ini sangat diperlukan jika Anda memiliki situs yang tidak ada, atau digunakan untuk memastikan bahwa semuanya cocok dalam satu program, agar tidak mencari sumber daya pihak ketiga, serta jika Anda memiliki beberapa situs atau dalam konten semantik membutuhkan besar situs.Ini menawarkan fitur-fitur berikut:

Di sini terlihat seperti keycollector
Slovoeb.
Layanan ini gratis. Pengembang adalah sama yang menciptakan program kolektor utama. Agar program menggunakan program, Anda perlu menentukan login dari akun tambahan langsung. Ini disebabkan oleh fakta bahwa Yandex dapat memblokir akun karena kueri otomatis, jadi jangan gunakan yang utama.Sumber daya menawarkan fitur-fitur berikut:
- Mengumpulkan kata kunci melalui WordStat;
- Filter permintaan untuk frekuensi tinggi;
- Analisis sintaks dari konfirmasi pencarian.

Antarmuka slovoeb.
Bagaimana program ini bekerja? Untuk memulai, membuat proyek baru. Pilih "Tambah frasa" - Berikut adalah frasa yang menggunakan pelanggan untuk mencari informasi tentang produk tertentu.

Menambahkan frasa pencarian ke program
Dalam menu "Mengumpulkan kata-kata dan statistik", pilih item yang diinginkan dan mulai layanan. Misalnya, jika Anda perlu mengumpulkan frasa kunci, lalu pilih opsi ini.

Penentuan frekuensi frasa kunci
WordStat (layanan Yandex)
Ini adalah sumber gratis untuk pemilihan dan analisis. frasa pencarian. Perlu jika Anda siap untuk menganalisis dan mengklasifikasikan pertanyaan secara manual. Layanan ini menawarkan opsi-opsi berikut:- Menampilkan informasi tentang pertunjukan dan permintaan untuk kata kunci, frasa pencarian, sambil menganalisis Anda dapat baik secara umum maupun data seluler (yaitu, Anda dapat melihat seberapa populer permintaan di perangkat seluler);
- Menunjukkan statistik berdasarkan wilayah;
- Tampilan data tentang popularitas permintaan tertentu untuk waktu ("Riwayat Kueri");
- Menampilkan frasa atau permintaan hanya dalam bentuk yang ditentukan (untuk ini perlu untuk menempatkan frasa dalam kutipan);
- Menunjukkan statistik tidak termasuk stop-words (sebelum kata ini Anda harus meletakkan minus sehingga tidak diperhitungkan);
- Mendemonstrasikan data dari penggunaan dalih yang dipilih (dalam hal ini, sebelum harus diletakkan "+");
- Menampilkan informasi tentang kategori Permintaan (untuk grup permintaan ini harus diberi label dalam tanda kurung, dan opsi-opsi utama - untuk memisahkan slash langsung "|": Yaitu, dalam waktu singkat untuk mendapatkan data berdasarkan permintaan "pesanan kue", "Beli a Kue "," Pesan Kappekyk "," Beli Cape "," Pite Pie "dan" Beli Pie ", ikuti instruksi, seperti yang ditunjukkan di bawah ini dalam gambar);
- Menampilkan data berdasarkan permintaan dengan mengacu pada area tertentu.

Permintaan "Kapkeyeys", Statistik Umum

Data pada kunci berdasarkan wilayah

Di sini Anda dapat melihat ketika permintaan adalah yang paling atau paling tidak populer.

Menampilkan frasa dalam bentuk yang ditentukan

Kata kunci tanpa Wordform.

Statistik tidak termasuk stop-words

Data pada enam permintaan segera - hal yang nyaman jika Anda perlu mendapatkan informasi dengan cepat

Jika Anda memilih wilayah tertentu, Anda dapat melihat apa yang populer di sana
Google Adwords (Scheduler Kata Kunci dari Google)
Jika di wilayah tertentu, Google memimpin secara signifikan, lebih baik menggunakan layanan ini. Ini dirancang hanya untuk menghitung kebutuhan pengguna mesin pencari ini. Layanan gratis, tetapi ada layanan berbayar (misalnya, untuk iklan).Alat ini menawarkan fitur-fitur berikut:
- Mengumpulkan informasi tentang permintaan pencarian;
- Pengembangan kombinasi baru permintaan dan perkiraan relevansi dan dinamika mereka.
Untuk mendapatkan statistik pada permintaan spesifik, Anda harus memilih opsi ini pada halaman Utama alat. Anda harus memasukkan frasa yang menarik dan mengunggah file dalam format CSV, kemudian memilih wilayah dengan statistik mana yang diperlukan, Anda juga dapat menentukan kata-kata Stop (seperti yang dijelaskan dalam WordStat). Semuanya siap - Anda dapat mengklik tombol "Cari tahu jumlah permintaan".

Informasi tentang Permintaan Google
Layanan Menawarkan Layanan Analytics
Anda juga dapat menggunakan analis atau metrik Google Analytics jika Anda perlu membangun kernel semantik untuk sumber daya yang ada. Alat-alat ini membantu menunjuk frasa mana yang mencari klien yang diperkenalkan.
Di sini Anda juga dapat menemukan inspirasi untuk pembentukan kata kunci.
Selain itu, data pada frasa umum untuk menemukan pelanggan dari ini atau bahwa informasi dapat diperiksa menggunakan kabinet untuk Yandex dan Google Webmaster. Data terakhir terletak di konsol pencarian, maka Anda harus pergi ke "Lalu Lintas Pencarian - Analisis Permintaan Pencarian".
Webmaster Yandex mengusulkan untuk menggunakan bagian "Kueri Pencarian - permintaan populer".
Alat untuk menganalisis situs pesaing
Situs yang bersaing adalah sumber daya lain di mana Anda dapat mencari inspirasi untuk mencari kata kunci. Untuk menunjuk mereka, masuk akal untuk membaca publikasi mereka atau memeriksa teks menggunakan tag HTML keywod menggunakan kode program halaman web. Atau advego dengan ISTIO untuk membantu Anda.
Antio Interface.
Jika Anda perlu menganalisis seluruh portal pesaing, Anda dapat menggunakan alat-alat berikut:
Sekarang lebih banyak untuk setiap item.
Untuk menentukan kunci utama, mereka perlu merekam, dimungkinkan untuk melakukan ini pada selembar kertas dan menggunakan program komputer. Anda akan memerlukan ide-ide semua kolega - mereka perlu merekam semuanya tanpa kecuali: masing-masing dapat berubah menjadi "mengambil Graveyla", yang akan menarik pelanggan kepada Anda.
Daftarnya mungkin terlihat seperti ini:

Daftar sampel frasa untuk pencarian
Dalam daftar ini, hampir semua tombol frekuensi tinggi, tanpa spesifisitas. Frasa dengan frekuensi menengah dan rendah akan memungkinkan hal yang sama untuk memperluas kernel. Jadi pergi ke tahap selanjutnya.
Di sini kesulitan ini diselesaikan dengan menggunakan alat untuk memilih kata kunci. Misalnya, Anda dapat memilih layanan Yandex - itu adalah salah satu yang paling nyaman, meskipun kompleksitas awal yang jelas. Di sini Anda dapat membuat pengikatan ke wilayah tertentu jika Anda menawarkan produk atau layanan dalam objek geografis tertentu.
Jadi pada tahap ini kita menganalisis semua tombol yang dikompilasi oleh kolega.

Analisis permintaan utama
Anda harus menyalin frasa dari kolom kiri layanan dan memasukkan ke dalam tabel. Sekarang Anda harus fokus pada kolom kanan asisten - di sini Yandex menawarkan frasa yang digunakan pengunjung bersama dengan frasa utama. Jadi di sini Anda memiliki kesempatan untuk memilih tombol yang cocok dan menyalinnya ke kolom kiri. Jangan khawatir jika ada sesuatu yang tidak cocok - frasa ini dikecualikan pada tahap akhir. Dan dia sudah dekat dengan musim dingin di "permainan takhta".
Hasil dari fase ini akan menjadi daftar frasa yang dikompilasi untuk mencari, yang akan dari setiap tombol utama. Pada tahap ini, ratusan dan bahkan ribuan permintaan yang berbeda dapat diperoleh.

Daftar frasa
Pergi ke tahap tutup. Tidak peduli seberapa mudah kelihatannya - tidak. Ini adalah pekerjaan yang paling memakan waktu dan menantang dengan inti. Perlu untuk mengecualikan secara manual dari nukleus semantik yang tidak cocok untuknya.
Tetapi Anda seharusnya tidak menghapus kunci frekuensi rendah - tanpa kasing. Pengoptimal "sekolah tua" membiarkan dan kemudian mempertimbangkan kunci ini untuk menjadi sampah, tetapi tidak perlu menemukan trik ini. Contoh: Mengambil kunci "kue diet" sebagai dasar, Anda dapat melihat bahwa layanan ini menunjukkan pada layar 3 dari pertunjukan per bulan di wilayah Cherepovets. Metode "Cash" melibatkan membuang kunci. Tetapi sekarang Anda akan mengerti mengapa Anda tidak melakukannya - dan saya berharap saran ini dan kemudian mendaftar dalam hidup.
Spesialis di bidang SEO, agar halaman mereka berada di bagian atas mesin pencari, mereka membeli untuk menyewa tautan. Pada saat yang sama, mereka perlu menggunakan tombol tertentu, metode ini diterapkan sekarang. Dan mereka dapat dipahami, karena frasa dengan frekuensi tampilan rendah, sebagai aturan, jangan membayar uang yang dihabiskan untuk tautan.
Tetapi jika Anda melihat "kue makanan" dengan mata pengerasan lama, dan pengusaha yang berorientasi pelanggan dapat ditemukan fitur tambahan. Lagi pula, beberapa pelanggan potensial benar-benar tertarik pada ini - dan tidak kalah pentingnya adalah gadis-gadis yang mengikuti sosok mereka. Jadi kami tahu persis apa permintaan ini Seseorang tertarik, dan oleh karena itu dengan hati nurani yang tenang dapat dimasukkan dalam inti semantik. Jika manisan di perusahaan Anda sedang mempersiapkan produk seperti itu, itu akan selalu berguna di mana barang akan dijelaskan. Dan jika tidak - konten informasi ini bisa membosankan untuk bagian informasi portal.

"Kue Diet", yang dapat dianggap sampah, sebenarnya ini bukan
Apa kemudian untuk mengecualikan? Mari kita cari tahu:
- Pertama, ini adalah frasa di mana merek lain hadir;
- Kedua, frasa berulang - misalnya, dari 3 kunci "kue untuk memesan tahun baru", "kue pesanan khusus", "Pesan Kue Tahun Baru," Akan ada kunci pertama;
- Ketiga, jika Anda tidak terlibat dalam hal seperti "dumping", maka, karenanya, kunci dengan pengenalan kata-kata "murah" dan "murah" tentu tidak akan berguna bagi Anda;
- Keempat, kunci dengan area yang tidak cocok - jika Anda berdagang hanya di Cherepovets, tetapi jangan memberikan di desa-desa terdekat atau tidak berdagang di daerah tertentu kota, data ini tidak diperlukan;
- Kelima, kunci dengan mengacu pada produk yang Anda tahu persis apa yang tidak akan dijual dan, sesuai, jangan menjual;
- Dan dalam enam, Anda tentu tidak akan menggunakan frasa yang ditulis secara tidak benar - tidak masalah, kesalahan tata bahasa atau kesalahan ketik - mesin pencari akan membantu pengunjung mencari "GBHJ;", bukan "kue", bukan "Cappoxy", bukan "Cappoxy" .
Voua-la ketika Anda telah mendeteksi semua kunci yang tidak cocok untuk Anda, Anda mendapat kunci "kue untuk memesan". Dengan semua yang lain, Anda perlu menghabiskan hal yang sama. Dan tahap selanjutnya akan menjadi klasifikasi frasa pada spesies.
Membangun peta kesesuaian (relevansi) dan klasifikasi frasa kunci
Frasa untuk pencarian yang akan digunakan oleh audiens target sebagai utama, dan akan menemukan data yang pengguna ke situs Anda akan diintegrasikan ke dalam T.N. "Clusters semantik (semantik)" adalah kategori permintaan yang mirip dengan konten semantik. Ini berarti bahwa "cluster kue" mencakup semua frasa yang secara langsung atau tidak langsung diartikulasikan dengan kata ini - dan dalam hal ini, unit bahasa ini naik sebagai "pribadi", dan semua frasa adalah "umum". Apa yang Anda miliki kesempatan untuk melihat pada gambar yang ditunjukkan di bawah ini.Harap dicatat bahwa cluster dari kategori kedua, ketiga, keempat hadir di sini. Semakin banyak tema, semakin besar level cluster. Meskipun de facto diperoleh sehingga cluster yang cukup dari kelompok kedua.

Level cluster.
Sebagian besar cluster didefinisikan pada tahap pertama membuat kata kunci. Secara alami, untuk ini Anda hanya perlu memahami topik yang dikirimkan, karena, tanpa mengetahui apa-apa tentang kue, Anda hampir tidak dapat membuat inti semantik yang kompeten. Asisten untuk membuat cluster juga akan berfungsi sebagai skema situs yang dikompilasi.
Clustering dari kategori kedua sangat penting. Ini harus menambah specifier yang akan menunjukkan tujuan pelanggan - ini, misalnya, membeli kue, "sejarah membuat kue Napoleon". Cluster terakhir ada di bagian informasi, dan yang pertama ke katalog.
Sekarang kita kembali ke diagram hierarkis dari halaman web dan dikembangkan atas dasarnya tabel. "Kue untuk memesan" didefinisikan dengan menggunakan layanan Yandex dan kemudian tidak dikecualikan dari daftar. Sekarang, kunci ini harus dibubarkan di antara halaman partisi yang sesuai.

Dengan demikian, Anda dapat menyebarkan frasa pencarian ke situs Anda.
Ambil contoh ini: Ada frasa di cluster untuk mencari "kue untuk memesan tema sepakbola".

Kue sepak bola, ternyata, pengguna bunga
Dan jika permen menghasilkan jenis produk ini, maka kita tahu bagian mana yang akan ditemukan halaman ini. Itu harus ditempatkan di "kue dari damar-momir", karena bahan ini digunakan untuk menciptakan produk gula-gula seperti itu. Jadi, di sini kita membuat halaman yang sesuai. Kami memperkenalkannya ke dalam desain sumber daya Internet, menunjukkan URL dan frasa pencarian dengan frekuensi.

Membuat halaman di bagian yang relevan
Anda dapat melihat dengan bantuan alat yang sama yang membantu memilih tombol yang tepat, yang masih meminta pengguna mengenai tema sepakbola. Frasa ini juga harus ditambahkan ke halaman ini.

Kami memahami apa lagi yang Anda minati pada pelanggan mengenai sepakbola dan kue
Kunci dicatat. Tersebar sisa tombol pencarian.
Skema yang ditarik pada awalnya mungkin dapat berubah bahkan beberapa kali tanpa batas - jika perlu, Anda dapat membuat kategori dan bagian baru. Jadi, jika itu tidak ada halaman "Kue anak-anak", kemudian, mengingat bahwa perusahaan dapat membuat kue dengan kartun "PiPpa" atau "patroli anak anjing", Anda dapat membuat perubahan dan membuat halaman. Pada saat itu, tombol-tombol ini dapat ditemukan di bagian "Kue dari damar wangi."

Menciptakan partisi baru dalam tabel hierarkis situs "Kue Anak-Anak"
Ada dua nuansa penting yang perlu diingat:
- Cluster mungkin tidak termasuk frasa yang sesuai untuk halaman yang ingin Anda buat. Penyebabnya bisa penggunaan yang salah Kata kunci, keberangkatan pemilihan frasa kunci atau hanya popularitas barang atau jasa yang rendah. Tetapi pada saat yang sama, ini bukan alasan untuk meninggalkan halaman dan menjual barang. Misalnya, jika dalam sistem pencarian Anda tidak menemukan permintaan pencarian "Kue Pig Pepper", tetapi perusahaan manisan memiliki fitur untuk membuat produk seperti itu, Anda dapat mengklarifikasi kebutuhan pelanggan menggunakan layanan lain. Dalam hal ini, permintaan seperti itu akan ditemukan, dan kebanyakan dari mereka berada;

Orang-orang juga mencari "Peppe Peppe"
- Nah, setelah mengecualikan kunci yang tidak perlu, mungkin ada permintaan yang tidak pantas. Nah, mereka dapat menghapusnya atau mendaftar di cluster lain. Misalkan perusahaan gula mengkhususkan diri dalam resep unik, dan kue yang diuji waktu seperti "Reruntuhan Kabupaten" atau "Napoleon" berpikir bahwa lebih baik untuk pergi di masa lalu - kunci seperti itu dapat diserahkan kepada bagian di mana pengguna akan diberikan Informasi Umum - Dalam hal ini, "Resep".
Frasa kunci dapat ditempatkan di bagian Informasi jika sangat populer di kalangan pengunjung.
Jadi, pada tahap akhir, menyebar pada halaman semua tombol, Anda akan mengajarkan daftar halaman web portal, di mana URL, permintaan, dan frekuensinya ditentukan. Kami melangkah lebih jauh, itu tidak semua.
Pengayaan tahap akhir dari inti semantik
Jadi, sekarang kita memiliki semua yang kita butuhkan. Kami memiliki meja dengan inti semantik, daftar halaman web pendahuluan dan frasa kunci yang menentukan kebutuhan pelanggan tertentu. Semua ini akan membantu dalam persiapan rencana pengisian informasi (rencana konten). Sekarang, memadapkannya, Anda harus menentukan nama halaman web atau artikel, dan menyertakan permintaan utama untuk mesin pencari. Tetapi harus diingat bahwa itu tidak selalu harus menjadi kunci yang paling umum dari sudut pandang Yandex atau Google. Dia harus mencerminkan apa yang ingin Anda sampaikan kepada pengguna dan fakta bahwa pelanggan ingin mendapatkan.Frasa kunci lain harus diterapkan sebagai jawaban atas pertanyaan - "Apa yang harus saya tulis?" Tentu saja, Anda seharusnya tidak segera "mendorong" semua frasa yang ditemukan menggunakan alat untuk pemilihan permintaan pencarian, ke bagian tertentu - apakah itu adalah halaman dari rencana informasi atau penawaran untuk membeli layanan atau produk tertentu. Ini harus diulangi pada akhirnya lagi: Perlu pertama-tama untuk memperhatikan kebutuhan informasi pengguna, dan bukan pada frasa kunci dan "isian" dari teks yang mereka suka pil. Pengguna selalu melihat ketika dia mencoba "hujan" - dengan kompilasi teks yang kompeten, dia bahkan tidak akan berpikir bahwa kata kunci digunakan di sini.
Akhirnya, apa yang masih belum dilakukan dengan inti semantik
Saya berharap pertanyaan tentang apa yang telah diberitahu, Anda tidak memiliki kiri, dan Anda sekarang dapat membuat selusin situs berdasarkan pengetahuan yang diperoleh. Tapi tetap saja, Anda harus menunjuk beberapa tindakan yang tidak dilakukan. Nanti Anda akan intuitif dalam hal ini, dan sekarang mereka harus dipelajari dengan hati. Berikut adalah beberapa tips untuk membantu menjadi profesional dalam kompilasi yang tepat dari sumber daya Internet:- Jangan menolak kunci yang memiliki kompetisi yang terlalu besar. Ya, Anda tidak memiliki banyak kebutuhan untuk masuk ke permintaan pencarian paling atas "Pesan Marshlow". Cukup gunakan frasa sebagai ide konten;
- Juga, itu tidak boleh dihilangkan dari frasa frekuensi rendah - ini adalah ide-ide konten, terima kasih yang kemungkinan besar dapat memuaskan mereka yang dapat menemukan layanan tersebut bahkan dari perusahaan terbesar;
- Jangan gunakan untuk mengevaluasi kata-kata kunci formula dan koefisien (seperti Kei, rasio popularitas kkonkurity). Mari kita lihat sekali lagi: semantik - bagian linguistik. Ini bukan ilmu yang akurat, seperti, misalnya, fisika atau matematika. Ini lebih dekat dengan seni daripada studi yang akurat, dan, mematuhi persyaratan formula atau koefisien, semantik kehilangan sorotannya. Jadi Anda kehilangan banyak ide untuk mengisi informasi, yang dapat dikecualikan oleh program - tetapi bukan program selanjutnya akan membaca teks;
- Jangan membuat halaman terpisah demi satu kunci. Semua tentu saja bertemu belanja online seperti itu, di mana ada halaman khusus "Beli kue" dan "memesan kue". Kernel semantik hilang di sini, karena pada dasarnya itu adalah tindakan yang sama. Atau "beli murah" dan "beli murah" - ini adalah kata-kata Sinonim, oleh karena itu tidak sebanding dengan halaman terpisah dari konten yang tidak berguna;
- Tidak perlu sepenuhnya mengotomatiskan desain kernel semantik. Tentu saja, Anda menggunakan alat khusus untuk mengumpulkan frasa kunci, dan untuk proyek-proyek besar, alat-alat tersebut hanya sangat diperlukan - terutama kolektor utama. Tetapi tanpa analisis, yang akan diproduksi oleh manusia, nilai kuncinya rendah. Ini bukan rahasia yang hebat - bahkan mereka yang menggunakan pengetahuan sekolah tua mengetahuinya. Layanan hanya membuatnya lebih mudah bagi kami, mengumpulkan informasi yang sebaliknya dibutuhkan untuk memfilter untuk waktu yang lama dan menyakitkan, tetapi teks itu sendiri tidak bisa. Lebih tepatnya, ada program-program semacam itu, tetapi nilai mereka untuk seseorang kecil, dan mereka dimaksudkan sepenuhnya untuk tujuan lain - bukan untuk membaca pengguna. Hanya orang yang memahami sesuatu di daerah ini sebenarnya dapat menentukan tingkat persaingan, menyusun rencana perusahaan informasi atau menganalisis situasi di bidang ini. Ketiga item secara tidak langsung diartikulasikan dengan desain struktur sumber daya web dan penyebaran kata kunci;
- Jangan menjadi mewah - tidak perlu fokus pada pengumpulan frasa kunci. Hanya memulai bisnis, tidak ada gunanya melakukan spionase yang cermat untuk pesaing, kumpulkan kata kunci maksimum dari semua mesin pencari yang tersedia hingga Hotbot dan jelajahi mesin pencari. Cukup untuk menggunakan satu - maksimal dua sumber daya, dan itu bisa Yandex atau Google. Nah, atau Rambler dengan Mail.ru paling buruk jika mesin pencari ini populer di wilayah Anda. Tut.by - Jika Anda tertarik dengan wilayah Belarusia tertentu, atau Uaportal.com - di Ukraina. Tetapi mereka hanya digunakan sebagai mengikat ke wilayah ini: Jika, misalnya, penduduk Belarus akan tertarik pada "kue dengan Ksenia Sitnik", penduduk Rusia tidak akan mengatakan apa-apa sama sekali. Dan oleh karena itu, itu juga tidak layak untuk overstat situs web Anda.
Perlu mengingat mengapa dan mengapa Anda membangun inti. Dan juga itu semantik.
Jadi, setelah semua, pemasaran atau SEO?
Tidak mungkin untuk mengatakan bahwa orang lain bertentangan. Pemasar bisa menjadi "ceeshnik" yang baik, dan sebaliknya. Hanya dari seseorang yang dapat membuat kernel semantik dengan benar untuk situsnya, dibutuhkan terutama logika pengusaha dan pemasar (orientasi kepada klien), dan selanjutnya - keterampilan seorang spesialis di bidang SEO (dikerahkan dengan benar kata kunci). Anda perlu memahami bahwa Anda sebagai pengusaha dapat menawarkan konsumen potensial. Setelah itu, harus dipahami bagaimana pelanggan mencari dan menemukan data yang diperlukan. Dan instrumen yang dijelaskan di atas akan membantu. Analisis, sadap tidak perlu, temukan kunci yang paling cocok, mengklasifikasikannya, dan tersebar secara ergonomis di seluruh struktur situs. Dan Vua-La, sekarang telah datang sebentar ketika Anda dapat memulai formasi paket konten. Perhatian!!!. Administrasi tidak bertanggung jawab atas isinya.Sering pemula webmaster, menghadapi kebutuhan untuk membuat inti semantik, tidak tahu harus mulai dari mana. Meskipun tidak ada yang rumit dalam proses ini. Sederhananya, Anda perlu merakit daftar frasa kunci untuk pengguna internet yang mencari informasi di situs Anda.
Semakin lengkap dan lebih tepatnya, akan lebih mudah untuk menulis salinan salinan yang baik, dan Anda mendapatkan posisi tinggi dalam mencari permintaan yang diinginkan. Cara membuat kernel semantik besar dan berkualitas tinggi dengan benar dan apa yang harus dilakukan dengan mereka selanjutnya bahwa situs pergi ke atas dan mengumpulkan banyak lalu lintas, dan itu akan menjadi pidato dalam materi ini.
Kernel semantik adalah serangkaian frasa kunci yang dipercayakan oleh makna, di mana setiap kelompok mencerminkan satu kebutuhan atau keinginan pengguna (niat). Artinya, apa yang dipikirkan seseorang, didorong oleh permintaannya ke string pencarian.
Seluruh proses membuat nukleus dapat diajukan dalam 4 langkah:
- Menemukan tugas atau masalah;
- Di kepala kita merumuskan bagaimana menemukan solusinya melalui pencarian;
- Mendorong permintaan ke Yandex atau Google. Selain kami, orang lain melakukan hal yang sama;
- Opsi panggilan yang paling sering jatuh ke dalam layanan analitik dan menjadi frasa utama yang kami kumpulkan dan grup untuk kebutuhan. Sebagai hasil dari semua manipulasi ini, kernel semantik diperoleh.
Apakah perlu untuk memilih frasa kunci atau dapat Anda lakukan tanpanya?
Sebelumnya, semantik untuk menemukan kata kunci frekuensi terbanyak pada topik, memasukkannya ke dalam teks dan mendapatkan visibilitas yang baik pada mereka dalam pencarian. 5 tahun terakhir, mesin pencari berusaha untuk pergi ke model di mana relevansi permintaan dokumen akan dinilai bukan dengan jumlah kata dan variasi variasi mereka dalam teks, tetapi sesuai dengan evaluasi pengungkapan maksud.
Google telah memulai pada tahun 2013 dengan Algoritma Hummingbird, Yandex pada tahun 2016 dan 2017 dengan teknologi Palee dan Ratu.
Teks yang ditulis tanpa Xia tidak akan dapat sepenuhnya mengungkapkan topik, yang berarti bersaing dengan bagian atas dalam permintaan frekuensi tinggi dan frekuensi pertengahan tidak akan berfungsi. Membuat taruhan pada permintaan frekuensi rendah tidak masuk akal - terlalu sedikit lalu lintas pada mereka.
Jika Anda mau dan di masa depan berhasil mempromosikan diri Anda atau produk Anda di Internet - Anda perlu belajar cara membuat semantik yang tepat, yang sepenuhnya mengungkapkan kebutuhan pengguna.
Klasifikasi permintaan pencarian
Kami akan memeriksa 3 jenis parameter yang kata kunci dievaluasi.
Dalam frekuensi:
- Frekuensi tinggi (HF) - frasa yang mendefinisikan topik. Terdiri dari 1-2 kata. Rata-rata, jumlah permintaan pencarian dimulai dari 1000-3000 per bulan dan dapat mencapai ratusan ribu tayangan tergantung pada materi pelajaran. Paling sering di bawah mereka adalah halaman utama situs.
- Medium-grade (SCK) - arahan terpisah dalam subjek. Lebih disukai mengandung 2-3 kata. Dengan frekuensi yang akurat dari 500 hingga 1000. Biasanya kategori situs komersial atau tema untuk artikel informasi besar.
- Frekuensi rendah (LF) - permintaan yang berkaitan dengan pencarian untuk jawaban spesifik untuk pertanyaan. Sebagai aturan, dari 3-4 kata. Ini bisa menjadi kartu produk atau topik artikel. Rata-rata, Anda mencari dari 50 hingga 500 orang per bulan.
- Saat menganalisis metrik atau data meter statistik, Anda dapat memenuhi jenis microch kuncinya. Ini adalah frasa yang sering bertanya sekali dalam pencarian. Tidak masuk akal untuk mempertajam di bawah mereka. Halaman tidak. Cukup di bagian atas LF, yang mencakupnya.
Untuk daya saing:
- Highborne (VC);
- Mediteranen (SC);
- Longcover (nk);
Untuk kebutuhan:
- Navigasi. Ekspresikan keinginan pengguna untuk menemukan sumber daya atau informasi tertentu di atasnya;
- Informasi. Ditandai dengan ketersediaan informasi dalam memperoleh informasi sebagai jawaban atas permintaan;
- Transaksi. Terkait langsung dengan keinginan untuk melakukan pembelian;
- Fuzzy atau umum. Mereka yang sulit menentukan niat secara akurat.
- Geo-bergantung dan bergantung pada Geon. Mencerminkan kebutuhan untuk mencari informasi atau melakukan transaksi di kotanya atau tanpa ikatan regional.

Tergantung pada jenis situs, rekomendasi berikut dapat diberikan ketika memilih frasa kunci untuk kernel semantik.
- Sumber informasi. Penekanan utama harus dilakukan pada pencarian artikel dalam bentuk permintaan LF SCH dan kompetisi rendah. Disarankan untuk mengungkapkan topik lebar dan dalam, menyeret halaman untuk sejumlah besar kunci LF.
- Toko online atau situs komersial. Kami mengumpulkan HF, SCH dan LF, yang paling jelas tersegmentasi sehingga semua frasa adalah tipe transaksional dan berhubungan dengan satu cluster. Penekanannya adalah pada pencarian kata kunci NC NK yang dikonversi dengan baik.
Cara membuat kernel semantik yang hebat - petunjuk langkah demi langkah
Kami beralih ke bagian utama artikel, di mana saya akan secara konsisten, membongkar tahapan utama yang Anda butuhkan untuk membangun kernel situs masa depan.
Agar proses menjadi lebih jelas, semua langkah diberikan dengan contoh.
Cari frasa dasar
Bekerja dengan kode dimulai dengan pilihan daftar utama kata-kata dan frasa dasar (HF), yang paling baik ditandai oleh tema dan digunakan dalam arti luas. Mereka juga disebut spidol.
Ini bisa seperti nama arah dan jenis produk, permintaan populer dari topik. Sebagai aturan, mereka terdiri dari 1-2 kata dan ada lusinan, dan kadang-kadang ratusan ribu pertunjukan per bulan. Kunci yang lebih baik lebih baik untuk tidak mengambil untuk tidak tenggelam dalam kata-kata minus pada tahap ekspansi.
Lebih nyaman untuk memilih frasa marker. Mencari permintaan untuk itu, di kolom kiri kita melihat frasa, yang dia isi sendiri, dalam hak - permintaan serupa yang sering Anda temukan cocok untuk memperluas tema. Juga, layanan menunjukkan frekuensi dasar frasa, yaitu, berapa kali mereka diminta sebulan dalam semua bentuk kata dan dengan penambahan kata-kata untuk itu.

Dengan sendirinya, frekuensi seperti itu tidak terlalu menarik, jadi perlu menggunakan operator untuk mendapatkan nilai yang lebih akurat. Kami akan menganalisis apa itu dan untuk apa.
Operator Yandex Wordstat:
1) "..." - Kutipan. Permintaan kutipan memungkinkan Anda untuk melacak berapa kali di Yandex sedang mencari frasa dengan semua bentuk kata-nya, tetapi tanpa menambahkan kata-kata lain (ekor).

2)! - tanda seru. Menggunakannya sebelum setiap kata dalam permintaan, kami memperbaikinya dengan bentuknya dan mendapatkan jumlah banding dalam pencarian dengan kata kunci hanya dalam bentuk kata yang ditentukan, tetapi dengan ekor.

3) "! ...! ...! ..." - tanda kutip dan tanda seru sebelum setiap kata. Operator paling penting untuk pengoptimal. Ini memungkinkan Anda untuk memahami berapa kali kata kunci diminta sebulan dengan ketat sesuai dengan frasa yang diberikan, seperti yang ditulis, tanpa menambahkan kata-kata.

4) +. Yandex Vordstat tidak memperhitungkan preposisi dan kata ganti saat diminta. Jika Anda membutuhkannya untuk menunjukkannya - letakkan tanda plus di depan mereka.

lima) -. Operator paling penting kedua. Dengan itu, kata-kata yang tidak cocok dihilangkan dengan cepat. Untuk menerapkannya setelah frasa yang dianalisis, kami menempatkan minus dan menghentikan kata. Jika mereka agak mengulangi prosedur.

6) (... | ...). Jika Anda perlu mendapatkan dari Yandex, data pada beberapa frasa secara bersamaan menyimpulkan mereka dalam tanda kurung dan berbagi budak langsung. Dalam praktiknya, metode ini jarang digunakan.

Untuk kenyamanan bekerja dengan layanan, saya sarankan meletakkan ekstensi khusus untuk browser Asisten WordStat. Itu ditempatkan di Mozil, Google Chrome, I.Baurazer dan memungkinkan Anda untuk menyalin frasa dan frekuensinya dengan satu klik "+" atau "tambahkan semua" ikon.

Misalkan kami memutuskan untuk membuat blog Anda di CEO. Pilih 7 frasa utama untuk itu:
- kernel semantik;
- optimasi;
- copywriting;
- promosi;
- monetisasi;
- Langsung
Cari sinonim.
Ketika diminta dengan mencari sistem, pengguna dapat menggunakan kata-kata yang berarti, tetapi berbeda dengan menulis.
Misalnya, "mobil" dan "mobil".
Penting untuk menemukan lebih banyak sinonim mungkin dengan kata-kata utama untuk meningkatkan cakupan nukleus semantik di masa depan. Jika ini tidak dilakukan, maka ketika parcing, kita akan melewatkan seluruh lapisan frasa kunci yang mengungkapkan kebutuhan pengguna.
Apa yang kami gunakan:
- Brainstorm;
- Kolom kanan yandex wordstat;
- Permintaan mencetak gol pada Cyrillic;
- Ketentuan khusus, singkatan, ekspresi slang dari subjek;
- Blok Yandex dan Google - bersama dengan "nama kueri" sedang mencari;
- Cuplikan pesaing.
Sebagai hasil dari semua tindakan untuk topik yang dipilih, kami memperoleh daftar frasa tersebut:

Memperluas permintaan utama
Kami akan mematahkan kata kunci ini untuk mengidentifikasi kebutuhan dasar orang-orang di bidang ini.
Lebih nyaman untuk melakukan ini dalam program pengumpul utama, tetapi jika sangat disayangkan untuk membayar 1800 rubel per lisensi, gunakan analog gratis. - Pedang.
Menurut fungsionalitasnya, tentu saja lebih lemah, tetapi untuk proyek kecil cocok.
Jika Anda tidak ingin mempelajari pekerjaan program, Anda dapat menggunakan layanan akademi dan analisis terburu-buru. Tapi tetap lebih baik menghabiskan sedikit waktu dan berurusan dengan perangkat lunak.
Saya akan menunjukkan prinsip bekerja di kolektor Kay, tetapi jika Anda bekerja dengan sebuah kata, maka semuanya akan dipahami juga. Antarmuka program serupa.
Prosedur:
1) Kami akan menambahkan daftar frasa dasar ke program dan menghapus frekuensi dasar dan akurat pada mereka. Jika kami berencana untuk mempromosikan di wilayah tertentu - kami menunjukkan regionalitas. Untuk situs informasi, ini paling sering tidak diperlukan.

2) Sparks kiri kolom Yandex Wordstat sesuai dengan kata-kata yang ditambahkan untuk mendapatkan semua permintaan dari topik kami.

3) Di pintu keluar, kami memutar 3374 frasa. Kami akan menghapus frekuensi yang tepat pada mereka, seperti pada titik 1.

4) Periksa apakah tidak ada kunci dalam daftar dengan nol frekuensi dasar.

Jika kita menghapus dan pergi ke langkah berikutnya.
Minus-kata.
Banyak yang mengabaikan prosedur untuk mengumpulkan kata-kata minus, menggantinya dengan menghilangkan frasa yang tidak cocok. Tetapi kemudian Anda akan menyadari bahwa itu nyaman dan benar-benar menghemat waktu.
Buka tab Data dalam Kolektor Kay -\u003e Analisis. Pilih jenis pengelompokan sesuai dengan kata-kata individu dan daftar kunci tombol. Jika Anda melihat frasa yang tidak cocok - tekan ikon biru dan tambahkan kata dengan semua wordware ke kata-kata berhenti.

Di slobel, bekerja dengan kata-kata stoppal diimplementasikan dalam versi yang lebih sederhana, tetapi Anda juga dapat membuat daftar frasa yang tidak sesuai dan menerapkannya pada daftar.
Jangan lupa menggunakan penyortiran frekuensi dasar dan jumlah frasa. Opsi ini membantu mengurangi daftar frasa sumber atau terpotong jarang ditemui.

Setelah kami menyusun daftar kata-kata stop, oleskan ke proyek kami dan lanjutkan ke koleksi promes.
Parsing Tips.
Saat memasukkan permintaan ke Yandex atau Google, mesin pencari menawarkan opsi mereka untuk melanjutkan dari frasa paling populer yang digerakkan oleh Internet. Kata kunci ini disebut tips pencarian.
Banyak dari mereka tidak jatuh ke dalam kata-kata, jadi ketika membangun semantik Anda perlu merakit permintaan tersebut.
Kolektor kay, dengan parsitis default mereka dengan bust dari akhir, sirilik dan alfabet latin dan dengan ruang setelah setiap frasa. Jika Anda bersedia mengorbankan jumlah untuk mempercepat proses, beri tanda centang pada titik "hanya kumpulkan ujung teratas tanpa rasa dan ruang setelah frasa".

Seringkali, di antara mesin pencari, Anda dapat menemukan frasa dengan frekuensi dan persaingan yang baik dalam waktu puluhan kali lebih rendah daripada di vordstat, sehingga di ceruk sempit saya sarankan mengumpulkan maksimal kata.
Tip parsing time langsung tergantung pada jumlah banding simultan ke server mesin pencari. Kolektor Kei maksimum mendukung 50 lalu lintas.
Tetapi untuk mengurai permintaan dalam mode ini, Anda akan memerlukan proxy dan akun sebanyak di Yandex.
Untuk proyek kami, setelah mengumpulkan petunjuk, ternyata 29595 frasa unik. Seiring waktu, seluruh proses membutuhkan waktu lebih dari 2 jam pada 10 utas. Artinya, jika ada 50, kita akan menempatkan dalam 25 menit.

Definisi frekuensi dasar dan akurat untuk semua frasa
Untuk pekerjaan lebih lanjut, penting untuk menentukan frekuensi dasar dan akurat dan memotong semua nol. Permintaan dengan sejumlah kecil pertunjukan dibiarkan jika mereka target.
Ini akan membantu untuk lebih memahami intrinsik dan menciptakan struktur artikel yang lebih lengkap daripada di bagian atas.
Untuk menghapus frekuensi, sear pertama yang tidak perlu:
- hents kata-kata
- kunci dengan simbol lain;
- frasa Belanda (melalui "Analisis Oak Implisit" Alat)

Untuk frasa yang tersisa, kami akan mendefinisikan frekuensi yang akurat dan mendasar.
tapi) untuk frasa hingga 7 kata:
- Kami memilih melalui filter "Frasa ini terdiri dari tidak lebih dari 7 kata"
- Buka jendela "Koleksi dengan Yandex.Direct" dengan mengklik ikon "D";
- Jika Anda menentukan wilayah;
- Pilih Mode Tampilan Dijamin;
- Kami menempatkan periode pengumpulan - 1 bulan dan centang di atas jenis frekuensi yang diinginkan;
- Klik "Dapatkan Data".

b) untuk frasa dari 8 kata:
- Kami menentukan untuk kolom "frase" filter - "terdiri dari minimal 8 kata";
- Jika Anda perlu pindah ke kota tertentu di bawah ini, kami menentukan wilayah tersebut;
- Klik pada Magnifier dan pilih "Kumpulkan semua jenis frekuensi".

Membersihkan kata kunci dari sampah
Setelah kami menerima informasi tentang jumlah tayangan untuk kunci kami, Anda dapat mulai menggunakan yang tidak sesuai.
Pertimbangkan prosedur untuk langkah-langkah:
1. Pergi ke "Analisis Grup" Kei Collector dan kami mengurutkan kunci dengan jumlah penggunaan kata. Tugas untuk menemukan yang tidak memadai dan sering dan menempatkannya dalam daftar kata-kata Stop.
Kami melakukan segalanya dan juga dalam "minus kata".

2. Berlaku untuk daftar frasa kami semua hentikan kata-kata yang ditemukan dan dijalankan di atasnya agar pasti tidak kehilangan target kueri. Setelah memeriksa, klik Hapus "frasa yang ditandai".

3. Sumber frasa Dumbers, yang jarang digunakan dalam entri yang akurat, tetapi memiliki frekuensi dasar yang tinggi. Untuk melakukan ini, dalam pengaturan program kolektor utama di kunci & SERP, masukkan rumus perhitungan: kunci 1 \u003d (yandexwordstatbaseefreq) / (yandexwordstatquotepointfreq) dan simpan perubahan.

4. Kami membuat perhitungan kunci 1 dan lepaskan frasa-frasa yang parameter ini ternyata dari 100 dan lebih.

Kunci yang tersisa harus dikelompokkan pada halaman asrama.
Kekelompokan
Distribusi kelompok dalam kelompok dimulai dengan frasa cluster di bagian atas program gratis. "Clusterizer Majento". Saya merekomendasikan bahwa analog dibayar dengan fungsi yang lebih luas dan kecepatan kerja yang cepat - keyassort, tetapi juga cukup bebas untuk kernel kecil. Satu-satunya nuansa bahwa untuk bekerja di salah satu dari mereka perlu membeli batasan XML. Harga rata-rata 5 p. Untuk 1000 permintaan. Artinya, pemrosesan inti tengah sebesar 20-30 ribu kunci akan dikenakan biaya 100-150 p. Alamat layanan yang digunakan, lihat di tangkapan layar di bawah ini.

Inti dari pengelompokan kunci metode ini adalah untuk menggabungkan ke dalam kelompok frasa-frasa yang ada pada 10 Yandex:
- uRL umum satu sama lain (keras)
- dengan kueri frekuensi terbanyak dalam grup (lunak).
Tergantung pada jumlah kebetulan tersebut untuk situs yang berbeda, ambang batas clustering dibedakan: 2, 3, 4 ... 10.
Keuntungan dari metode ini adalah pengelompokan frasa sesuai dengan kebutuhan orang, dan tidak hanya pada koneksi sinonim. Ini memungkinkan Anda untuk segera memahami kata kunci mana yang dapat digunakan pada satu halaman boarding.
Untuk informasi akan sesuai:
- Lembut dengan ambang batas 3-4 dan kemudian membersihkan dengan tangan;
- Keras pada 3-ke, dan kemudian menggabungkan cluster dalam arti.
Toko online dan situs komersial biasanya ditingkatkan dengan hard-y dengan ambang batas clustering tiga kali, jadi saya akan menaikkannya dalam artikel terpisah.
Untuk proyek kami setelah pengelompokan dengan metode sulit pada 3 ternyata 317 grup.

Periksa Persaingan
Tidak masuk akal untuk maju melalui permintaan yang sangat kompetitif. Sulit untuk masuk ke atas, dan tanpa itu tidak akan ada lalu lintas pada artikel. Untuk memahami topik apa yang menguntungkan untuk menulis menggunakan metode berikut:
Biasanya fokus pada frekuensi tepat dari kelompok frasa dimana artikel itu ditulis dan persaingan pada mutagen. Untuk situs informasi, saya sarankan, mengambil topik untuk bekerja, di mana frekuensi akurat 300 dan lebih tinggi, dan koefisien kompetitif dari 1 hingga 12 inklusif.
Dalam tema komersial, fokus pada marginalitas barang atau jasa dan bagaimana pesaing lakukan di 10. Bahkan 5-10 target kueri per bulan dapat menjadi alasan untuk membuat halaman terpisah di bawahnya.
Cara Memeriksa Bersaing berdasarkan permintaan:
a) Secara manual, didorong oleh frasa yang sesuai dalam layanan itu sendiri atau melalui tugas massa;

b) Dalam mode batch melalui program kolektor Kay.

Pemilihan topik dan pengelompokan
Pertimbangkan masing-masing kelompok yang dihasilkan untuk proyek kami setelah mengelompok dan memilih topik untuk situs tersebut.
Majento tidak seperti anggapan kunci tidak memungkinkan untuk mengunduh data pada jumlah pertunjukan untuk setiap frasa, sehingga Anda harus melepasnya melalui kolektor Kay.
Petunjuk:
1) Bongkar semua grup dari Majento dalam format CSV;
2) Kopling frasa di Excel pada topeng "Grup: Kunci";
3) Muat daftar yang dihasilkan dalam sollector kunci. Dalam pengaturan, itu harus menjadi tanda centang dalam mode impor "Grup: Kunci" dan bukan untuk memantau keberadaan frasa dalam kelompok lain;

4) Kami menghapus frekuensi dasar dan akurat untuk kata kunci dari grup yang baru dibuat. (Jika Anda menggunakan berbagai macam, itu tidak perlu dilakukan. Program ini memungkinkan Anda untuk bekerja dengan kolom tambahan)
5) Kami mencari cluster dengan intente unik, mengandung setidaknya 3 frasa dan jumlah hit pada semua permintaan dalam jumlah lebih dari 300. Selanjutnya, kami memeriksa 3-4 frekuensi paling banyak pada kompetisi Mutagen. Jika di antara frasa-frase ini ada kunci dengan persaingan kurang dari 12 - mulai bekerja;
6) Kami melihat seluruh kelompok. Jika frasa yang ditutup oleh makna ditemukan dan perlu dilihat dalam satu halaman - kita bergabung. Untuk kelompok yang berisi makna baru, kami melihat prospek untuk frasa total frasa, jika kurang dari 150 per bulan, kemudian meletakkannya sampai saat Anda melewati seluruh inti. Mungkin ternyata dikombinasikan dengan cluster lain dan mendapatkan 300 pertunjukan yang akurat - ini adalah minimum yang layak untuk diambil artikel. Untuk mempercepat grup manual, gunakan alat bantu: Filter cepat dan kamus frekuensi. Mereka akan membantu Anda dengan cepat menemukan frasa yang sesuai dari cluster lain;

Perhatian!!! Bagaimana cara memahami bahwa cluster dapat digabungkan? Kami mengambil 2 kunci frekuensi dari yang diambil dalam paragraf 5 untuk halaman arahan dan 1 permintaan dari grup baru.
Kami menambahkannya ke Alat Arsenkin "Bongkar Top 10", tunjukkan wilayah yang diinginkan jika perlu. Selanjutnya, kami melihat jumlah persimpangan warna untuk frasa ke-3 dengan sisanya. Kami menggabungkan kelompok jika berasal dari 3 atau lebih. Jika tidak ada kebetulan atau satu, tidak mungkin untuk menggabungkan - intensis yang berbeda, dalam kasus 2 persimpangan, lihat penerbitan dengan tangan Anda dan gunakan logika.
7) Setelah mengelompokkan kunci, kami menerima daftar topik yang menjanjikan untuk artikel dan semantik di bawahnya.

Menghapus permintaan untuk jenis konten lain
Dalam persiapan inti semantik Penting untuk dipahami bahwa untuk blog dan situs informasi, permintaan komersial tidak diperlukan. Sama seperti toko online tidak memerlukan informasi.
Kami menjalankan setiap kelompok dan membersihkan semuanya tidak perlu jika tidak mungkin untuk secara akurat menentukan niat kueri - membandingkan penerbitan atau menggunakan alat:
- Verifikasi untuk komersialisasi dari Pixel TULS (gratis, tetapi dengan batas hari pemeriksaan);
- layanan Just-Magic, Clustering dengan tanda centang Periksa kueri komersial (biaya, biaya tergantung pada tarif)
Setelah itu, pergi ke langkah terakhir.
Optimalisasi frasa
Kami mengoptimalkan kernel semantik sehingga nyaman untuk bekerja dengannya di spesialis SEO dan copywriter di masa depan. Untuk melakukan ini, kami akan meninggalkan frasa kunci di setiap kelompok yang sebagian besar mencerminkan kebutuhan orang dan mengandung sinonim sebanyak mungkin dengan frasa utama.
Algoritma tindakan:
- Sortir kata kunci di Excel atau Kay Collector secara alfabet dari A hingga Z;
- Pilih yang mengungkapkan topik dari berbagai sisi dan kata yang berbeda. Hal-hal lain yang sama meninggalkan frasa dengan frekuensi akurat yang lebih tinggi atau di mana kunci 1 indikator (rasio frekuensi dasar sesuai);
- Kami menghapus kata kunci dengan jumlah pertunjukan sebulan kurang dari 7, yang tidak menanggung makna baru dan tidak mengandung sinonim unik.
Contoh tentang bagaimana kernel semantik yang dikomposisikan secara kompeten terlihat -
Saya mencatat frasa yang tidak cocok untuk intensitas. Jika Anda mengabaikan rekomendasi saya pada pengelompokan manual dan tidak untuk memeriksa kompatibilitas, itu akan berubah bahwa halaman akan dioptimalkan untuk frasa kunci yang tidak kompatibel dan posisi tinggi pada permintaan progresif tidak lagi melihat.
Daftar Periksa Terakhir
- Kami memilih kueri frekuensi tinggi utama yang mengatur subjek;
- Kami mencari sinonim untuk mereka menggunakan WordStat kolom kiri dan kanan, situs-situs pesaing dan cuplikan mereka;
- Perluas permintaan pemulihan yang diterima ke wordstat kolom kiri;
- Kami menyiapkan daftar kata-kata stop dan berlaku untuk frasa yang dihasilkan;
- Parsim Tips Yandex dan Google;
- Hapus frekuensi dasar dan akurat;
- Perluas daftar kata-kata minus. Kami Bersihkan dari Permintaan Sampah dan Rahes
- Kami membuat klusterisasi melalui Majento atau Keyassort. Untuk situs informasi dalam mode lunak, ambang batas 3-4. Untuk sumber daya internet komersial menggunakan metode hard dengan ambang 3.
- Kami mengimpor data dalam kolektor Kay dan menentukan kompetisi 3-4 frasa untuk setiap cluster dengan intensitas unik;
- Kami memilih topik dan menentukan dengan halaman arahan untuk permintaan berdasarkan penilaian jumlah total pertunjukan yang akurat dalam semua frasa dari satu cluster (dari 300 untuk informasi) dan persaingan untuk sebagian besar frekuensi mereka pada mutagen (hingga 12) .
- Untuk setiap halaman yang sesuai, kami mencari cluster lain dengan kebutuhan pengguna yang serupa. Jika kita dapat mempertimbangkannya pada satu halaman - kita bergabung. Ketika kebutuhan tidak jelas atau ada kecurigaan yang sebagai jawaban untuk itu harus ada jenis konten atau halaman lain - periksa dengan mengeluarkan atau melalui alat Pixel Tuls atau Just-Magic. Untuk situs konten, kernel harus terdiri dari permintaan informasi, Komersial dari transaksional. Kami menghapus terlalu banyak.
- Kami mengurutkan kunci pada masing-masing kelompok dengan abjad dan meninggalkan mereka yang menggambarkan topik dari berbagai sisi dan kata yang berbeda. Hal-hal lain yang sama dengan prioritas permintaan tersebut yang kurang dari rasio frekuensi dasar pada jumlah yang tepat dan lebih tinggi dari pertunjukan yang akurat per bulan.
Apa yang harus dilakukan dengan seo-core setelah kreasinya
Sebagai daftar kunci, mereka memberi mereka kepada penulis dan dia menulis artikel yang sangat baik sepenuhnya, mengungkapkan semua makna. Eh, sesuatu yang saya terjebak ... Teks yang masuk akal hanya akan mungkin terjadi jika copywriter jelas memahami bahwa Anda ingin darinya dan bagaimana cara memeriksa diri sendiri.
Kami akan menganalisis 4 komponen, kerja dengan baik, yang Anda dijamin akan mendapatkan banyak target lalu lintas pada artikel:
Struktur yang baik. Kami menganalisis permintaan yang dipilih untuk halaman arahan dan mengungkapkan apa yang dibutuhkan orang dalam topik ini. Selanjutnya, tulis rencana untuk artikel yang sepenuhnya meresponsnya. Tugasnya adalah membuat orang pergi ke situs tersebut menerima respons volumetrik dan komprehensif pada semantik yang Anda buat. Ini akan memberikan perilaku yang baik dan relevansi tinggi dengan intensitas. Setelah Anda menyusun rencana, lihat situs pesaing dengan memiliki permintaan pencarian dasar yang dipromosikan. Anda perlu melakukan dalam urutan seperti itu. Artinya, pertama kita lakukan sendiri, maka kita melihat orang lain dan jika kita perlu disempurnakan.
Optimasi di bawah kunci. Artikel itu sendiri mengasah di bawah 1-2 sebagian besar kunci frekuensi dengan persaingan pada MutageN hingga 12. 2-3 frasa frekuensi lainnya dapat digunakan sebagai tajuk utama, tetapi dalam bentuk encer, yaitu, memasukkan tambahan non-tema ke dalamnya , menggunakan sinonim dan kata. Fokus utama yang kami buat pada frasa frekuensi rendah yang mengeluarkan bagian unik - ekor dan diterapkan secara merata ke dalam teks. Mesin pencari itu sendiri akan menemukan dan merekatkan.
Sinonim untuk permintaan dasar. Kami menuliskannya secara terpisah dari kernel semantik kami dan menempatkan tugas copywriter untuk menggunakannya secara merata dalam teks. Ini akan membantu mengurangi kepadatan kata-kata utama kami dan teks akan cukup dioptimalkan untuk masuk ke atas.
Frasa yang menentukan geas.Dengan sendirinya, LSI tidak mempromosikan halaman, tetapi kehadiran mereka menunjukkan bahwa kemungkinan besar teks tertulis milik Ahli Peru, dan ini sudah merupakan nilai tambah untuk kualitas konten. Untuk mencari frasa tematik, gunakan alat alat untuk copywriter dari Pixel Tuls.

Metode alternatif pemilihan frasa kunci menggunakan layanan analisis pesaing
Ada pendekatan cepat untuk membuat kernel semantik, yang berlaku untuk pendatang baru dan pengguna berpengalaman. Inti dari metode ini adalah bahwa kita awalnya memilih kunci bukan untuk seluruh situs atau kategori, tetapi secara khusus di bawah artikel, halaman tempat duduk.
Ini dapat diwujudkan dengan 2 cara yang berbeda dalam cara kami memilih tema untuk halaman dan seberapa banyak memperluas frasa kunci:
- menggunakan parsing kunci utama;
- berdasarkan analisis pesaing.
Masing-masing dapat diimplementasikan pada tingkat yang sederhana dan lebih kompleks. Kami akan menganalisis semua opsi.
Tanpa menggunakan program
Mesin fotokopi atau webmaster sering tidak ingin berurusan dengan antarmuka sejumlah besar program, tetapi Anda memerlukan tema dan frasa kunci yang baik di bawahnya.
Metode ini hanya untuk pemula dan mereka yang tidak mau repot. Semua tindakan dilakukan tanpa menggunakan perangkat lunak tambahan, menggunakan layanan yang sederhana dan mudah dimengerti.
Apa yang akan diambil:
- Kunci. Layanan untuk analisis pesaing - 1500 p. Di promosi "alblog" - diskon 15%;
- Mutagen. Periksa kompetisi permintaan - 30 kopecks, mengumpulkan frekuensi dasar dan akurat - 2 kopecks untuk 1 cek;
- Buvillers - versi gratis atau akun bisnis - 995 p. (Sekarang dengan diskon 695 P)
Opsi 1. Pilih topik melalui parsel frasa utama:
- Kami memilih kunci utama dari subjek dalam arti luas menggunakan brainstorming dan kolom kiri dan kanan Yandex WordStat;
- Selanjutnya, kami mencari sinonim untuk mereka, metode yang dikatakan awal;
- Kami mencetak semua permintaan penanda yang diterima ke bookvilk (perlu membayar untuk tarif berbayar) dalam mode lanjutan "Cari berdasarkan kata kunci";
- Kami menentukan dalam filter: "! Akurat! Frekuensi" dari 50, jumlah kata dari 3;
- Bongkar seluruh daftar di Excel;
- Kami mengalokasikan semua kata kunci dan mengirim ke pengelompokan ke layanan "Fists Crastier". Jika situs tersebut dipilih secara regional diperlukan kota. Ambang pengelompokan untuk situs informasi pergi pada 2, untuk 3-Ku komersial;
- Setelah pengelompokan, pilih tema untuk artikel dengan menelusuri cluster yang dihasilkan. Kami mengambil mereka di mana jumlah frasa dari 3 dan dengan intente unik. Lebih baik memahami kebutuhan orang-orang yang membantu analisis URL situs dari atas di kolom "pesaing" (di sebelah kanan di pelat layanan Kulakov). Kami juga tidak lupa memeriksa kompetisi untuk Mutagen. Kami menusuk 2-3 permintaan dari cluster. Jika lebih dari 12, maka Anda tidak boleh mengambil topik;
- Nama halaman arahan masa depan ditentukan, tetap memilih frasa kunci untuknya;
- Dari bidang "pesaing" menyalin 3 ullas dengan jenis halaman yang cocok (jika situs tersebut informasi - ambil referensi ke artikel, jika komersial, kemudian di toko);
- Masukkan mereka secara berurutan dalam tombol. Jadi dan bongkar semua frasa kunci pada mereka;
- Kami menggabungkannya di Excel dan menghapus duplikat;
- Layanan hanya data tidak cukup, jadi perlu untuk memperluasnya. Kami akan menggunakan buckvilical lagi;
- Daftar yang dihasilkan dikirim ke Clustering di tinju "Customerizer";
- Kami memilih grup permintaan yang cocok untuk halaman arahan, dengan fokus pada niat;
- Kami menghapus frekuensi dasar dan akurat melalui Mutagen dalam mode "Tugas Massa";
- Unggah daftar dengan data yang diperbarui dengan jumlah pertunjukan di Excel. Hapus nol untuk kedua jenis frekuensi;
- Juga di Excel, tambahkan rumus untuk hubungan frekuensi dasar untuk akurat dan hanya menyisakan kunci-kunci yang kurang dari 100;
- Kami menghapus permintaan jenis konten lain;
- Kami meninggalkan frasa bahwa kata-kata yang paling penuh dan berbeda mengungkapkan niat utama;
- Kami ulangi semua tindakan yang sama pada paragraf 8-19 untuk sisanya.
Opsi 2. Pilih topik melalui analisis pesaing:
1. Kami mencari situs teratas dalam subjek kami, didorong oleh permintaan RF dan melihat penerbitan melalui alat Arsenkin "10 besar". Cukup untuk menemukan 1-2 sumber daya yang cocok.
Jika kami mempromosikan situs di kota tertentu, kami menunjukkan regionalitas;
2. Buka layanan keys.so dan masukkan URL situs yang ditemukan dan lihat halaman pesaing seperti apa yang membawa lalu lintas terbanyak.
3. 3-5 dari permintaan frekuensi paling akurat dari mereka memeriksa daya saing. Jika di atas 12 di semua frasa, maka lebih baik mencari topik lain kurang kompetitif.
4. Jika Anda perlu menemukan lebih banyak situs analisis, buka tab "Pesaing" dan atur parameter: Mirip dengan 3, kolaborasi - 10. Kami menilai data tentang penurunan lalu lintas.
5. Setelah kami memilih topik, drive namanya untuk penerbitan dan salin 3 ullas dari atas.
6. Selanjutnya, ulangi item 10-19 dari opsi 1.
Menggunakan kolektor kei atau kata
Metode ini akan berbeda dari yang sebelumnya digunakan untuk digunakan untuk beberapa program pengumpul program operasi dan ekspansi utama yang lebih dalam.
Apa yang akan diambil:
- program Kolektor Utama - 1800 rubel;
- semua layanan yang sama seperti pada cara sebelumnya.
"Lanjutan - 1"
- Parsim kiri dan kolom kanan Yandex sepanjang daftar frasa;
- Hapus frekuensi yang tepat dan dasar melalui kolektor kay;
- Hitung tombol 1;
- Kami menghapus permintaan nol dan dengan kunci 1\u003e 100;
- Selanjutnya, kami melakukan segalanya serta dalam paragraf 18-19 opsi 1.
"Advanced - 2"
- Kami membuat langkah 1-5, seperti dalam perwujudan 2;
- Kami mengumpulkan pada masing-masing kunci URL di Keys.SO;
- Kami menghapus duplikat dalam kolektor kay;
- Kami mengulangi paragraf 1-4, seperti pada metode "Advanced -1".
Sekarang bandingkan jumlah tombol yang diperoleh dan frekuensi total akuratnya saat mengumpulkan dengan metode yang berbeda:
Seperti yang kita lihat dari tabel, hasil terbaik menunjukkan metode alternatif untuk membuat inti di bawah halaman - "Advanced 1.2". Dimungkinkan untuk mendapatkan 34% lebih banyak tombol target dan total lalu lintas pada cluster berusia 51% lebih banyak daripada dalam kasus metode klasik.
Di bawah pada tangkapan layar, dapat dilihat seperti inti jadi, di setiap kasus. Saya mengambil frasa dengan jumlah deposito yang tepat dari 7 per bulan sehingga kualitas kata kunci dapat diperkirakan. Untuk semantik lengkap, lihat tabel pada tautan "Lihat".
TAPI) 
B) 
DI) 
Sekarang Anda tahu bahwa cara yang paling umum tidak selalu dilakukan, seperti yang dilakukan semua orang, yang paling setia dan benar, tetapi tidak menolak metode lain. Banyak tergantung pada tema itu sendiri. Untuk situs komersial, di mana kunci tidak begitu banyak, cukup dan pilihan klasik. Pada situs informasi, Anda juga dapat memperoleh hasil yang sangat baik jika Anda mengkompilasi dengan benar TK dengan benar, membuat struktur yang baik dan optimasi SEO. Kami akan berbicara tentang semua ini secara rinci dalam artikel berikut.
3 kesalahan sering saat membuat kernel semantik
1. Kumpulkan frasa dengan atas. Itu tidak cukup untuk menggunakan kata-kata untuk mendapatkan hasil yang baik!
Lebih dari 70% permintaan yang jarang terjadi atau menstruasi, mereka tidak sampai di sana. Tetapi di antara mereka sering ada frasa kunci dengan konversi yang baik dan persaingan yang sangat rendah. Bagaimana tidak melewatkan mereka? Pastikan untuk mengumpulkan petunjuk pencarian dan menggabungkannya dengan data dari berbagai sumber (, penghitung di situs, statistik dan layanan basis data).
2. Mencampur informasi dan permintaan komersial pada satu halaman.Kami telah membongkar bahwa frasa kunci berbeda dalam jenis kebutuhan. Jika seorang pengunjung datang ke situs Anda, yang ingin melakukan pembelian, dan melihat sebagai jawaban untuk halaman permintaannya dengan artikel, bagaimana menurut Anda itu akan puas? Tidak! Sistem pencarian juga berpikir ketika halaman berada di peringkat, yang berarti tentang atasan di frasa tengah dan RF Anda dapat segera lupa. Oleh karena itu, jika Anda meragukan definisi jenis permintaan, lihat penerbitan atau gunakan alat Pixel Tuls, hanya keajaiban untuk menentukan komersialisme.
3. Seleksi untuk mempromosikan permintaan yang sangat kompetitif. Posisi untuk frasa RF VK adalah 60-70% tergantung pada faktor perilaku, dan membuatnya masuk ke atas. Semakin banyak pelamar, yang terpanjang dari mereka yang menginginkan dan di atas persyaratan situs. Segalanya, seperti dalam hidup atau olahraga. Jauh lebih sulit untuk menjadi juara dunia daripada mendapatkan gelar di kota Anda.
Karena itu, lebih baik memasuki niche yang tenang, dan tidak terlalu panas.
Sebelumnya, bahkan lebih rumit untuk berada di atas. Di atas berdiri pada prinsip yang berhasil, dia makan. Para pemimpin jatuh ke tempat pertama, dan mereka hanya bisa memindahkannya, menumpuk faktor perilaku. Dan bagaimana cara mendapatkannya jika Anda berada di halaman kedua atau ketiga ... Yandex merobek lingkaran tertutup ini pada musim panas 2015, memperkenalkan algoritma gangster berganda. Inti dari itu hanya secara acak meningkat dan menurunkan posisi situs untuk memahami apakah kandidat yang lebih layak muncul untuk menemukan di bagian atas.
Berapa banyak uang yang dibutuhkan untuk memulai?
Untuk menjawab pertanyaan ini, kami mempertimbangkan biaya persenjataan program dan layanan yang diperlukan untuk menyiapkan dan mengukur frasa kunci per 100 artikel.
Minimum (cocok untuk opsi klasik):
1. slobel - gratis
2. Majento Clrierterizer - Gratis
3. Untuk mengenali captch - 30 rubel.
4. Batas XML - 70 rubel.
5. Periksa persaingan permintaan Mutagen - 10 cek per hari secara gratis
6. Jika Anda tidak dirawat di mana saja dan siap untuk dibelanjakan pada parsing 20-30 jam yang dapat Anda lakukan tanpa proxy.
—————————
Hasilnya adalah 100 rubel. Jika Anda memasuki CAPTCHAS sendiri, dan xml membatasi mendapat imbalan untuk ditransfer dari situs Anda, maka benar-benar menyiapkan kernel secara umum secara umum. Hanya perlu untuk menghabiskan hari lain mengatur dan menguasai program dan 3-4 hari lagi untuk mengharapkan hasil parsing.
Set semantis standar (untuk metode canggih dan klasik):
1. Kolektor Kay - 1900 rubel
2. Aneka Kay - 1700 rubel
3. Bookwarix (Akun Bisnis) - 650 rubel.
4. Kunci. Layanan analisis pesaing - 1500 rubel.
5. 5 Proxy - 350 Rubel per Bulan
6. Antikapitch - sekitar 30 rubel.
7. Batas XML - sekitar 80 rubel.
8. Memeriksa persaingan oleh Mutagen (1 periksa \u003d 30 kopecks) - Buat 200 rubel.
———————-
Hasilnya adalah 6410 rubel. Tentu saja, dimungkinkan untuk melakukannya tanpa keyassort, menggantinya dengan clusterizer Majento dan bukan kolektor kay untuk menggunakan kata. Maka cukup dan 2810 rubel.
Haruskah saya mempercayai perkembangan kernel "profi" atau lebih baik untuk mengetahuinya dan melakukannya sendiri?
Jika seseorang secara teratur terlibat dalam hal favoritnya, memompa di dalamnya, maka mengikuti logika, hasilnya harus lebih baik daripada pendatang baru di daerah ini. Tetapi dengan pemilihan kunci, semuanya ternyata persis sebaliknya.
Mengapa dalam 90% kasus pendatang baru membuat profesional yang lebih baik?
Ini semua tentang jalan. Tugas semantis tidak mengumpulkan kernel terbaik untuk Anda, tetapi untuk memenuhi pekerjaan Anda untuk waktu minimum dan kualitasnya diatur untuk Anda.
Jika Anda melakukan semuanya sendiri untuk algoritma-algoritma yang mereka katakan lebih awal - hasilnya akan menjadi urutan besarnya lebih tinggi karena dua alasan:
- Anda mengerti topiknya. Jadi, Anda tahu kebutuhan pelanggan atau pengguna situs Anda dan Anda dapat pada tahap awal untuk memperluas permintaan marker untuk parsing, menggunakan sejumlah besar sinonim dan kata-kata tertentu.
- Tertarik melakukan semuanya secara kualitatif. Pemilik bisnis atau karyawan perusahaan tempat ia bekerja, tentu saja, datang ke pertanyaan lebih bertanggung jawab dan akan mencoba melakukan semuanya secara maksimal. Semakin lengkap kernel dan permintaan yang lebih rendah kompetitif di dalamnya, semakin mungkin untuk merakit lalu lintas target, dan karenanya laba dengan investasi yang sama dalam konten akan lebih tinggi.
Bagaimana menemukan 10% sisanya yang membuat kernel lebih baik dari Anda?
Cari perusahaan di mana pemilihan frasa kunci adalah kompetensi utama. Dan segera bahas apa hasil yang Anda inginkan, seperti orang lain atau maksimal. Dalam kasus kedua, itu akan 2-3 kali lebih mahal, tetapi dalam jangka panjang itu berulang kali terbayar. Bagi mereka yang ingin memesan layanan dengan saya, semua informasi dan ketentuan yang diperlukan. Jaminan Kualitas!
Mengapa sangat penting untuk menyelesaikan semantik sepenuhnya
Di sini, seperti dalam setiap bola, prinsip "pemilihan yang baik dan buruk" bekerja. Apa esensinya?
Setiap hari kami dihadapkan dengan kenyataan bahwa kami memilih:
- artinya dengan seseorang yang tampaknya bukan apa-apa, tetapi tidak melekat atau mengecewakan dengan sendirinya untuk membangun hubungan yang harmonis dengan mereka yang membutuhkan;
- pekerjaan yang tidak suka atau menemukan pekerjaan, lalu apa yang berbohong dan lakukan dengan profesi Anda;
- sewa kamar untuk toko di pos pemeriksaan non-posting atau masih menunggu sampai Anda bebas, opsi yang sesuai;
- buat tim tidak manajer terbaik. Penjualan, dan orang yang telah menunjukkan diri mereka lebih baik pada wawancara hari ini.
Tampaknya semuanya jelas. Dan jika Anda melihatnya di sisi lain, menyajikan setiap pilihan sebagai investasi di masa depan. Di sini itu dimulai yang paling menarik!
Disimpan dalam hal ini. kernel, 3-5 ribu. Puas seperti gajah! Tapi apa artinya:
a) Untuk situs informasi:
- Kerugian lalu lintas setidaknya 1,5 kali dengan investasi yang sama dalam konten. Perbandingan metode Lain-Lainnya Memperoleh frasa kunci, kami telah menemukan cara yang berpengalaman bahwa metode alternatif memungkinkan Anda untuk mengumpulkan 51% lebih;
- Proyek dengan cepat mengirimkan ekstradisi. Pesaing mudah untuk berkeliling kita, memberikan jawaban yang lebih lengkap pada intensitasnya.
b) Untuk proyek komersial:
- Kurang memimpin atau meningkatkan biaya mereka. Jika kita memiliki semantik, seperti orang lain, kita bergerak pada permintaan yang sama dengan pesaing. Sejumlah besar Saran dengan permintaan konstan mengurangi bagian dari masing-masing di pasar;
- Konversi rendah. Permintaan khusus Lebih baik dikonversi ke penjualan. Simpan ke tujuh. kernel, kami kehilangan kunci konversi yang paling;
- Lebih berat untuk maju. Banyak yang ingin berada di atas - di atas persyaratan untuk masing-masing kandidat.
Saya berharap Anda selalu melakukannya pilihan yang bagus Dan investasikan hanya di Plus!
P. Bonus "Cara menulis artikel yang bagus dengan semantik yang buruk", serta kehidupan dan penghasilan hidup-ke-pekerjaan lainnya di Internet, baca di grup saya





























 di Photoshop Cara Membuat Kotak Di Photoshop CS6")



