Mnogi su članci napisani o izboru semantičkog kernela, ali još uvijek postoje greške. Kako pokupiti semantički kernel Sa velikim brojem ključnih upita? Trebam li s vremenom proširiti semantički kernel? Kako distribuirati ključne riječi na stranici? Na ova i druga pitanja, pročitajte u našoj varalici.
Pažnja! 23. oktobra izaći će sljedeće izdanje "krevetića optimizatora", njegove teme - "CMS" .
Pošaljite svoja pitanja i naši stručnjaci će vam odgovoriti!
Semantički kernel
1. Kako napraviti semantički kernel za internetsku trgovinu, postoje li određene funkcije?
Prilikom izrade semantičkog kernela za internetsku trgovinu, ne treba uzimati samo visoke frekvencijske upite, a asortiman proizvoda maksimizira i aktivno promovira kategorije stranica i robe.
Stoga, za takve resurse zahtjev za prikaz "Kupiti nokia telefon N8 " bit će konverzija i efikasnija od upita s većom frekvencijom tipa "Kupite telefon".
Da biste napravili semantički kernel, koji će voditi posjetioce na web mjestu, možete koristiti dva načina: Automatski i ručni.
Automatski izbor zahtjeva može se izvesti pomoću posebnih usluga i programa. (Na primjer, internetska usluga Seolib.ru, ključni sakupljač, Slobel itd.).
Ručna metoda je dobra jer možete odabrati zahtjeve odjednom na ciljnim stranicama - kartice i kategorije pomoću shema izbora:
- "Proizvod + dodatne riječi"
- "Kupi + robu + dodatne riječi"
- "Prodaja + proizvod + dodatne riječi"
- "Cijena + proizvod + dodatne riječi"
- "Karakteristike + proizvod + dodatne riječi"
- "Opis + proizvod + dodatne reči"
- "Foto + proizvod + dodatne riječi", itd.
Istovremeno, u semantičkom jezgru dobit ćemo ne samo komercijalne, već i zahtjeve za informacijama koji će našoj jezgra i sidriti prirodnije.
Na primjer, za kategoriju robe "Smartphone Apple iPhone" u internetskoj trgovini mobilni telefoni Zahteve možete pronaći pomoću jednostavnog stola u Excelu:
Odnosno, na osnovu podataka u tablici, pokupili smo 3 opcije za upit za jednu stranicu Apple iPhone pametnih telefona Kategorija:
- "Kupiti smartphone Apple iPhone 3 4 GB bijela »
- "Prodaja Smartphone Apple iPhone 4 8 GB crni"
- "Opis pametni telefon Apple iPhone 5 16 GB bijeli"
2. Kako odabrati semantički kernel za regionalnu vesti? IT teme.
Odaberite semantički kernel, a zatim napišite vijesti pod IT - pogrešan pristup za bilo koju vesti, uključujući i IT teme.
Primarni zadatak vijesti je objavljivanje operativnih, zanimljivih i relevantnih informacija o trenutnim događajima, informacijama koje će danas biti zainteresirane za čitatelje. Samo s tim pristupom mjesto će moći postati popularno, osvojiti samopouzdanje korisnika, a samim tim i pretraživači. Nakon ovog principa prirodno ćete formirati ispravnu semantičku jezgru vaše web stranice. Uostalom, glavne teme (zahtjeve), na ovaj ili onaj način bit će spomenute u vijestima vašeg predmeta. Ako vam ostane slobodno vrijeme, bolje je potrošiti u porastu broja i poboljšanja kvalitete objavljenih materijala nego pripremiti članke pod određenim zahtjevima.
3. Da li vrijedi koristiti visoke frekvencijske upite u semantičkom jezgri?
New-frekventni upiti mogu se koristiti novim web lokacijama, ali ovisi o subjektu i nivou konkurencije. Što je veći nivo konkurencije, teže (ili nemoguće) promovirati lokaciju, jer će pretraživači dati prednost starim, pouzdanim resursima.
Na primjer, da vidimo izdavanje u Top-10 na upit "Klima uređaj" (Yandex pretraživač, regija "Moskva"):

Za mjesta čije je dob manje od dvije godine, preporučuje se prelazak na srednje frekvencije i niske frekvencije. Koristeći ih u semantičkom kernelu, nećete potrošiti budžet za promociju i možete privući ciljnu publiku na web mjesto. Srednji i. zahtevi sa niskim frekvencijama su najviše konverzije, što dovodi do mjesta potencijalnih kupaca.
4. Kako napraviti semantički kernel sa ogromnim brojem ključeva? Šta se zaustavlja i šta odbaciti u takvu situaciju? Očito je nemoguće raditi sa nekoliko hiljada ključeva.
Neka tajna ne postoji - rad je mukotrpljiv i, ako je potrebno, mora raditi sa nekoliko hiljada ključeva.
Postoje načini za olakšavanje rada. Pri prvoj fazi odabira zahtjeva, prikladno je koristiti automatske usluge prikupljanja statistike, konfiguriranjem "zaustavljanja" i određivanje potrebnih regija. Automatska usluga će se riješiti potrebe da ručno unese riječi na uslugu Wordstat.Yandex.ru.
Rezultirajući popis zahtjeva treba podijeliti u nekoliko prioritetnih grupa. Ovdje, naravno, sve ovisi o vašem specifičnom temu. Na primjer, ako imate prodajnu stranicu, prvo su potrebne transakcijske vrste tipa "Kupi", "Cijena" itd.
5. Nakon kojeg vremena vrijedi dovršiti i proširiti semantički kernel i vrijedi li uopće raditi?
Možete proširiti semantičko kernel i potrebe. Optimalno je to učiniti za nekoliko mjeseci promocije, kada je glavna faza već prošla, a web mjesto vodećim pozicijama preuzeo najmanje 70% prvog popisa upita.
Prilikom širenja kernela odaberite Zahtjeve na takav način da se presijecaju s originalnom listom. Inače, ako poboljšate tekst, zaglavlja i meta-oznake svaki put kada možete urediti tekst, pretraživače, pretraživači mogu pronaći neprirodno i sumnjivo i spustiti mjesto izručenja.
Prilikom širenja semantičkog kernela, pored toga standardne metode Izrada liste zahtjeva, preporučuje se korištenje podataka sa Google.nalytics i yandex.metrics.
Kako mogu biti korisničke usluge mogu biti korisne, pokazaćemo se na primjeru Yandex.Metrics - Idite u Yandex.Metric, pronađite kartice "Izvori" - "Rezultat": "

A bit ćete predstavljeni popisom svih zahtjeva za koje su bili posjeta web lokaciji, s brojem posjetitelja za svaki zahtjev:

Na ovom popisu odaberite upiti koja su ciljana za vaš resurs i nisu uključeni u početnu semantičku jezgru. Zatim provjerite položaje web mjesta prema primljenoj listi i prvo možete uzeti te upite za koje web mjesto nije u prvih 10. Za preostale zahtjeve možete povremeno pratiti položaje i zategnuti ih u slučaju sjemena.
6. Kao što je u formiranju semantičkog jezgara, odredite koji prioritetni zahtjevi, koji su neobavezni?
Da biste podijelili upite za prioritet i dodatne, morate razmotriti koji tip koji se odnose. Razlikuju se tri vrste: visoke frekvencije (HF), niskofrekventne (lf) i srednje frekvencije (i). RF upit je najpopularniji zahtjev, a manje je popularna sch i lf oko nje. Stoga će prioritet biti HF i dodatni - sch i kratak. Na primjer, RF zahtjev - "Plastični prozori" Glavni zahtjev na stranici, zapisnik SC - "Plastični prozori u Moskvi" i zahtjev za prijavu - Dodatni zahtjevi.
7. Što bi trebao biti broj ključne riječi na stranicu? Konkretno u brojevima - 3, 10, 15?
Jedinstveno je odgovoreno teško, jer Svaka pojedinačna situacija zahtijeva različite pristupe. Najpravednije optimiziraju stranicu pod jednim HF zahtjevom, 2-3 SCH upita i dalje - ispod NF zahtjeva. Logika je jednostavna - jedna stranica ide jedan glavni zahtjev, oko koje se sve "okreće".
Na primjer, "Plastični prozori" - RF zahtjev; "Plastični prozori za kupovinu", "Plastični prozori Moscow" - Zahtevi za SC; "Plastični prozori za kupovinu u Moskvi" - lf upit. Teško će promovirati stranicu ako ga optimizirate za zahtjeve "Štampanje logotipa" i "Greenhouse film". Izuzetak je samo "dom", jer Trebalo bi opisati čitav niz usluga web lokacije.
Imajte na umu da za upite s dodatnim riječima poput "Kupi", "Veleprodaja", "Cijena" Ne preporučuje se optimizacije drugih stranica osim onog u kojem se nalazi glavni, visokofrekventni upit. Na primjer, promoviran program stranice "Plastični prozori", Mora se premjestiti i na zahtjev "Plastični prozori za kupovinu".
8. Da li vrijedi prodavati informacije o zahtjevima za semantičko jezgro, ovo je prilično dobro ili još uvijek nisu potrebni takvi zahtjevi?
Definitivno vrijedi. Dok pišete, to je dodatni promet koji takođe može dovesti do konverzije. Prilikom kreiranja podataka o podacima na komercijalnoj lokaciji, važno je pridržavati se nekoliko principa:
- informativni materijali trebaju biti korisni korisnicima da ih obavijeste važne i korisne informacije. Potrebno je pripremiti visokokvalitetne publikacije, a ne samo popuniti članke odjeljka, "naoštrene" pod zahtevima;
- ne zaboravite da je vaša web lokacija prvenstveno komercijalna. Za većinu predmeta, situacija kada broj informativnih članaka premašuje broj proizvoda proizvoda, izgledat će čudno;
- pokušajte postaviti veze u linkove tijela na prodaju stranica stranica. To će povećati efikasnost informacijskog prometa.
9. Kako efikasnije implementirati reference unutar sadržaja frekvencija, I.E. Vezanje frekvencija jedne razine ili uvijajte ih različitim frekvencijama LF-HF-a?
Koliko razumijemo, pitanje se odnosi na unutrašnju prenosu.
Peregonovka Strategije Postoji veliki iznos, ali ne bismo preporučili "priložiti" konceptu frekvencije zahtjeva. Važno je da je transformator bio koristan. Ako se referenca unutar sadržaja koristi - pomoći će. Ako je veza "mrtva" i ne koristi ga - osjećaj za to, najvjerovatnije neće biti mnogo. I nema razlike, pozivate se na zahtjev LF sa stranice RF zahtjeva ili obrnuto.
Naravno, učinak unutrašnjeg transformacije primjetniji je za zahtjeve LF-a, jer su manje "zahtjevni" od visokofrekventnih upita s velikim konkurencijom. Ali još jednom ćemo ponoviti da željom da se "bude pričvrsti" na određeni algoritam prekogradnji, a da se ne razmišlja o tome koliko je overkloking potreban od strane korisnika, ne samo da ne samo ne pomaže, već ne samo da ne samo ne može pomoći. Traži motori ne vole neželjene pošte.
10. Napravio sam semantičku jezgru, fokusirajući se na Yandex, iako imam ukrajinsko mjesto i većina posjetitelja dolazi od Googlea. Da li je ovo jezgro pogodno za Google (mislim, da li Yandex i Google korisnici primjenjuju zahtjeve) ili trebaju učiniti novi?
Obično se ne primjećuju suštinske razlike u zahtjevima Yandex-a i Google korisnika. Ako je izbor uzeo u obzir regiju (u vašem slučaju, Ukrajini), tada ne bi trebalo biti problema.
Za neke subjekte region može biti važan (može se odabrati prilikom analize zahtjeva u Yandex Wordstat.). Razlika u zakonodavstvu ili popularnost određenih proizvođača može rezultirati razlikovanjem. U ovom slučaju morate pogledati svoj predmet. Ako nema regionalnih razlika, tada možete sigurno koristiti odabranu jezgru kao osnovnu.
11. Moja stranica se kreće na zahtjev "deva" i na ovoj riječi je u vrhu 3. ali prema riječi "deva" nije čak ni u prvih 30. Zašto može biti tako? Da li se upotreba množine ili jedinog u ključnoj riječi utječe na položaj web mjesta?
Da, u mnogim slučajevima utiče, jer Yandex, u potrazi za višestrukim i jedinim brojem može se značajno razlikovati, to znači da shvaća ove zahtjeve, kao različite. Pored toga, postoji značajna razlika u učestalosti zahtjeva. Na primjer, ako pogledate yandex.wordstat.ru (moskovsku) zahtjeve "! Plastični prozor" i "! Plastični prozori", tada će prva frekvencija biti 7650, a druga 169315. Prema tome, izdavanje će biti potpuno drugačije, jer To je očigledno različiti zahtjevi. Pobrinite pažljivo na tu riječ da optimizira stranicu, jer Ako odaberete pogrešan obrazac - izgubite promet.
12. U svojim komercijalnim ponudama, mnoge promotivne firme čine tablicu sa semantičkim jezgrama i troškovima po danu svake fraze za pronalaženje 1-3, 4-6, 7-10 u Yandexu, Googleu. Kako se razmatra ovaj budžet?
Pitanje je prilično komplicirano, jer svaka kompanija može imati vlastite koeficijente, a nerazumno je razgovarati o svim kompanijama.
Obično se trošak upita izračunava, na osnovu njegove složenosti (drugim riječima, koliko će zaposleni dati vrijeme na ovaj zahtjev ili grupu zahtjeva) i potrebnu količinu referentne mase. Pored toga, trebali biste razmotriti ukupan broj promoviranih zahtjeva (više zahtjeva, jeftiniji od njih, jer će opća referentna masa nalazišta biti veća).
13. Pitanje je sljedeće. Imam domenu (RU), kupio pre 1,5 godina. Kad sam stvorio stranicu na njemu, nisam previše razmišljao o pripremi semantičkog jezgra (medicinske teme, 40 stranica u indeksu, nema posjetitelja). Htio sam pitati - ako počnem kreirati novo mjesto na ovoj domeni (još jednu temu), već sa pripremom semantičkog kernela itd., Kao takve moje korake tretiraće se pretraživačima, kako će se indeksirati, Nakon kojeg perioda će biti promjena? Ili je bolje stvoriti web mjesto drugih tema na novom domenu i zaboraviti na staro (RU)?
Ako trenutna web lokacija ne primijeni filtere, a domena je pogodna za druge vaše objekte (zapamtite da morate biti pamtljivi korisnici i prikazuju vašu aktivnost) - ne bi trebalo biti problema.
Međutim, pretraživači mogu biti "oprezni" do potpune promjene mjesta istog vlasnika, jer oštra promjena subjekta izgleda nelogično. Najčešće mijenja subjekte lokacija napravljenih u prodaji referenci itd.
Još jedna stvar iz kojeg želimo upozoriti je stvaranje mjesta ispod dostupne semantičke jezgre. U početku je potrebno razviti koncept web stranice, kako bismo shvatili da korisnicima možete dati korisnicima da odredite svoju jedinstvenu ponudu i već kreirate web stranicu, odaberite te upite za koje ciljane posjetitelje mogu ići na vas.
Period ponovnog investiranja je težak, možete se kretati oko mjesec i pol.
Prethodna izdanja za optimizator varalice:
U ovaj trenutak Za promociju pretraživanja takve faktore kao sadržaj i strukturu igraju se kao važna uloga. Međutim, kako razumjeti šta da napišem tekst kojim se dijelovima i kreiraju stranice na web mjestu? Pored toga, morate saznati tačno šta je tačno ciljni posjetitelj vašeg resursa zainteresiran. Da biste odgovorili na sva ova pitanja, morate sastaviti semantički kernel.
Semantički kernel - Lista riječi ili izraza koji u potpunosti odražavaju predmet vaše web stranice.
U članku ću vam reći kako ga pokupiti, čistiti i podijeliti u strukturu. Rezultat će biti potpuna struktura sa upitama grupiranim putem stranica.
Evo primjera jezgre zahtjeva probijenih u strukturu:

Pod klasterom razumijem razgradnju vaših upita za pretragu za pojedinačne stranice. Ova metoda će biti relevantna kako promovirati Yandex i Google. U članku ću opisati potpuno slobodan način za stvaranje semantičkog jezgra, ali pokazat ću obje mogućnosti sa raznim plaćenim uslugama.
Nakon čitanja članka, naučit ćete
- Odaberite prave zahtjeve za svoj predmet
- Sakupite najpotpunije jezgro fraza
- Cleant od nezanimljiva zahtjeva
- Grupa i stvarajte strukturu
Sakupi semantički jezgro koji možete
- Na gradilištu stvorite smislenu strukturu
- Napravite meni na više nivoa
- Ispunite stranice tekstovima i pišite na njih od metapiranja i naslova
- Prikupite položaj svoje web stranice na zahtjevima pretraživača
Sakupljanje i grupiranje semantičkog kernela
Pravilna kompilacija za Google i Yandex započinje s definicijom glavnih ključnih fraza vašeg predmeta. Na primjer, pokazat ću njegovu kompilaciju na izmišljenoj internetskoj trgovini odjeće. Postoje tri načina za prikupljanje semantičkog kernela:
- Priručnik. Upotreba usluge Yandex Wordstat unosite svoje ključne riječi i ruke odaberite fraze koje su vam potrebne. Ova metoda je dovoljno brza ako trebate sastaviti tipke na jednu stranicu, međutim, postoje dva minuse.
- Tačnost metode "Chromasa". Uvijek možete propustiti sve važne riječi ako koristite ovu metodu.
- Nećete moći sastaviti semantički kernel na veliku internetsku trgovinu, iako možete koristiti Yandex Wordstat pomoćni dodatak za pojednostavljenje - problem je ne riješi.
- Poluautomatski. U ovoj metodi pretpostavljam upotrebu programa za prikupljanje jezgra i daljnji ručni kvar na odjeljcima, pododjeljkama, stranicama itd. Ova metoda sastavljanja i grupiranja semantičkog kernela po mom mišljenju je najefikasnija. Ima niz prednosti:
- Maksimalna pokrivenost svih tema.
- Kvar kvaliteta
- Automatski. Danas postoji nekoliko usluga koje nude potpuno automatsko kolekciju kernela ili klasteriranje vaših zahtjeva. Potpuno automatska opcija - ne preporučujem upotrebu, jer Kvaliteta prikupljanja i grupiranja semantičkog kernela trenutno je prilično niska. Automatska upita klasteriranje - dobivanje popularnosti i odvija se, ali morate još uvijek spajati neke stranice rukama, jer Sistem ne daje idealno spremno rješenje. I po mom mišljenju, samo se zbunite i nećete se moći spustiti u projekt.
Za sastavljanje i grupiranje pune ispravne semantičke jezgre na bilo kojem projektu u 90% slučajeva, koristim poluautomatska metoda.
Dakle, tako da moramo izvršiti sljedeće korake:
- Izbor zahtjeva za teme
- Odabir kernela na zahtjev
- Čišćenje iz ne-ciljnih upita
- Klasteriranje (razgradite fraze na strukturu)
Primjer šivanja semantičkog kernela i grupisanje na strukturu koju sam pokazao gore. Podsjećam vas da imamo internetsku trgovinu odjeće, započinju popločati 1 bod.
1. Izbor fraza za vaš predmet
U ovoj fazi potrebni su nam TOOL Yandex Wordstat, vaši konkurenti i logika. U ovom je koraku važno sastaviti popis fraza koji su tematski visoki frekvencijski zahtjevi.
Kako odabrati zahtjeve za prikupljanje semantike sa Yandex Wordstatom
Dođite na uslugu, odaberite grad koji vam je potreban (a) / regija (e), navode najviše "masti" po vašem mišljenju i pogledajte pravi stupac. Tamo ćete pronaći tematske riječi koje su vam potrebne, kako na drugim odjeljcima i frekvencijskim sinonimima za upisanu frazu.

Kako odabrati zahtjeve prije izrade semantičkog kernela koristeći konkurente
Unesite najpopularnije zahtjeve u pretraživaču i odaberite jednu od najpopularnijih mjesta, od kojih su mnogi od najvjerovatnije, i znate.

Obratite pažnju na glavne presjeke i uštedite sami izraze koje su vam potrebne.
U ovoj je fazi važno ispravno raditi: da maksimizirate sve vrste riječi iz vaše teme i ne propustite ništa, tada će vam se semantički kernel biti najophodniji.
Primjenjivo na naš primjer, moramo napraviti popis sljedećih fraza / ključnih riječi:
- odjeća
- Obuća
- Čizme
- Haljine
- Majice
- Donje rublje
- Šorc
Koje fraze ulaze bez značenja: Ženska odjeća, kupujte cipele, haljina na maturu itd. Zašto? - Ove fraze su "repovi" "odjeće" zahtjeva, "cipele", "haljine" i automatski će se dodati u semantički kernel u 2. fazi kolekcije. Oni. Možete ih dodati, ali bit će besmislen dvostruki rad.
Koje tastere trebate uklopiti? "Harfoots", "Čizme" nisu iste kao "čizme". To je riječ o riječima koji je važan, a ne tako pojedinačne riječi ili ne.
Neko ima listu ključnih fraza, a ko se sastoji od jedne riječi - ne bojte se. Na primjer, internetska trgovina vrata za pripremu semantičkog kernela sasvim je moguće dovoljno riječi "vrata".
I tako, na kraju ovog koraka trebali bismo imati sličnu listu.

2. Prikupljanje zahtjeva za semantičkim kernelom
Za pravilnu punu kolekciju potreban nam je program. Pokazaću primjer istovremeno na dva programa:
- Na plaćenoj - ključni bilektof. Za one koji imaju, ili ko želi kupiti.
- Besplatno - Slovoeb. Besplatan program za one koji nisu spremni potrošiti novac.
Otvorite program

Stvoriti novi projekat I nazovimo ga, na primjer, mysite

Sada, za daljnje prikupljanje semantičkog kernela, moramo napraviti nekoliko stvari:
Kreirajte novi račun na Yandex mail (stari se ne preporučuje koristiti zbog činjenice da se može zabranjeno za mnoge zahtjeve). Dakle, stvorili ste račun, na primjer [Zaštićen e-poštom] Sa lozinkom SUPER2018. Sada morate odrediti ovaj račun u postavkama kao Ivan.Ivanov: Super2018 i pritisnite tipku "Spremi promjene" na dnu. Pročitajte više - na ekranima.

Mi biramo regiju da sastavimo semantički kernel. Morate odabrati samo regije u kojima ćete se premjestiti i kliknite Sačuvaj. Iz ovoga ovisit će o učestalosti zahtjeva i da li će u principu pasti u prikupljanje.

Sve su postavke završene, ostaje da dodamo našu zlju u prvom koraku i kliknemo gumb "Start Collection" semantičkog kernela.

Proces je potpuno automatski i dovoljno je dovoljno. Možete raditi kafu dok pravite kafu, a ako je tema široka, na primjer, poput one koju prikupljamo - to je nekoliko sati 😉
Jednom kada sve fraze prikupe da vidite nešto slično:

A u ovoj fazi je završeno - pređite na sljedeći korak
3. Čišćenje semantičkog kernela
Prvo, moramo izbrisati zahtjeve koje nas ne zanima (neurozzi):
- Povezan s drugim markom, na primjer, "Gloria Jeans", "Ecco"
- Zahtjevi za informacije, na primjer, "nosim čizme", "Jeans veličina"
- Slično na temu, ali ne vezan za vaš posao, na primjer, "B odjeća", "Ženska veleprodaja"
- Zahtjevi, na primjer, ni na koji način odnose na temu, "Sims haljine", "mačka u čizmama" (takvi zahtjevi nakon izbora semantičkog kernela postoji prilično puno)
- Zahtjevi od ostalih regija, metroa, okruga, ulica (bez obzira na regiju prikupljali zahtjeve - još jedan region i dalje)
Čišćenje se mora izvršiti ručno na sljedeći način:

Ulazimo u reč, pritisnite "ENTER", ako ste u našem stvorenom semantičkom jezgru, to su one fraze koje su nam potrebne, dodelimo pronađenu i kliknemo izbriši.
Preporučujem da uđete u reč, ne u potpunosti, već korištenje dizajna bez prijedloga i završetaka, I.E. Ako napišemo riječ "slava", pronaći će fraze "Kupiti u Gloria Jeans" i "Kupi u Gloria Jeans". Pri pisanju "Gloria" - "Gloria" ne bi bila pronađena.
Dakle, morate proći kroz sve točke i ukloniti se iz semantičkog kernela nepotrebnih zahtjeva za vas. Ovo može potrajati dosta vremena, a možda će ispasti da uklonite većinu prikupljenih upita, ali rezultat će biti punopravni i tačan popis svih vrsta promoviranih zahtjeva za vašu web lokaciju.
Istovarite sada svi vaši zahtjevi za Excel

Također možete masovno ukloniti neciljne upite iz semantike, pod uslovom da imate listu. To možete učiniti sa stop-riječima i lako je učiniti za tipičnu grupu riječi sa gradovima, metroa, ulicama. Popis takvih riječi koje koristim možete preuzeti na dnu stranice.
4. Ključenje semantičkog kernela
Ovo je najvažniji i zanimljiviji dio - potrebno je podijeliti naše propise na stranicama i odjeljcima koji će u agregatu stvoriti strukturu vaše web stranice. Malo teorije - nego što se vodi zahtjevima:
- Konkurenti. Možete obratiti pažnju na to kako grupiranje semantičkog kernela od svojih konkurenata od vrha i djeluje na sličan način, barem sa glavnim odjeljcima. A i za gledanje kojih su stranice u izručivanju niskih frekvencijskih zahtjeva. Na primjer, ako niste sigurni da "radite ili ne" zaseban odjeljak za zahtjev "crvene kožne suknje", vozite frazu u pretraživač i pogledajte izdavanje. Ako izdavanje sadrži resurse u kojima postoje takvi odjeljci, to znači da ima smisla napraviti zasebnu stranicu.
- Logika. Učinite cjelokupnu grupiranje semantičkog kernela koristeći logiku: struktura mora biti jasna i predstavlja strukturiranu stranicu stranica s kategorijama i podkategorije u vašoj glavi.
I još par savjeta:
- Ne preporučuje se instalirati manje od 3 zahtjeva na stranicu.
- Ne pravite previše nivoa gniježđenja, pokušajte to učiniti da su bili 3-4 (site.ru / Kategorija / podkategorija / podkategorija)
- Nemojte praviti duge URL-ove ako imate mnogo nivoa gniježđenja prilikom grupiranja semantičkog kernela, pokušajte smanjiti URL-ove visoko na hijerarhiju kategorija, I.E. Umjesto "Vash-site.ru/Zhenskaya-odezhda/palto-dlya-zhenshin/krasnoe-palto", do "Vash-site.ru/zhenshinam/palto / krasnoe"
Sada vežbati
Na primjer, jezgra klasteriranje
Za početak, dijelimo sve zahtjeve za glavne kategorije. Gledajući logiku konkurenata - glavne kategorije za trgovinu odjeće bit će: muška odjeća, ženska odjeća, odjeća za djecu, kao i gomila drugih kategorija koje nisu vezane za pod / dob, poput jednostavno "cipele" , gornja odjeća.
Grupimo se semantički kernel kada je kada excel Help. Otvorite našu datoteku i akt:
- Podjelimo se na glavnim dijelovima
- Uzmite jedan odjeljak i podijelite ga na pododjeljke
Pokazat ću se na primjeru jednog odjeljka - muške odjeće i njenog pododjeljka. Da biste odvojili ključeve od drugih, morate istaknuti cijeli list i kliknite na uvjetno oblikovanje -\u003e Pravila odabira koda -\u003e Tekst sadrži

Sada u prozoru koji se otvara, pišemo "muž" i pritisnite Enter.

Sada su svi naši ključevi na muškoj odjeći istaknuti. Dovoljno je koristiti filtar za odvajanje odabranih tipki iz ostatka našeg montenog semantičkog kernela.
Zato uključite filter: Morate istaknuti stupac sa zahtjevima i pritisnite sortiranje i filter-\u003e filter

I sada je sortirano

Stvorite poseban list. Izrežite odabrane linije i umetnite ih tamo. Na ovaj način ćete morati nastaviti i slomiti kernel.
Promijenite naziv ovog lista na "Muška odjeća", list u kojem je sve ostalo semantičko jezgro, ime "Svi zahtjevi". Zatim stvorite drugi list, ime ga imenujte "strukturu" i prvo ga stavite. Na stranici strukture stvorite drvo. Trebali biste uspjeti ovako:

Sada moramo podijeliti veliki dio muške odjeće na pododjeljke i podsekcije.
Za praktičnost upotrebe i prijelaza prema vašem grupnom semantičkom jezgru postavite reference na strukturu na odgovarajuće listove. Da biste to učinili, desnom tipkom miša kliknite željenu stavku u strukturi i učinite kao u snimku zaslona.

A sada moramo razdvojiti vaše ruke za dijeljenje zahtjeva, istovremeno uklanjanje onoga što možda nije primijećeno i uklonjeno u fazi čišćenja kernela. U konačnici, zahvaljujući grupiranju semantičkog kernela, trebali biste imati strukturu sličnu ovoj:


Pa Ono što smo naučili da radimo:
- Odaberite zahtjeve koje trebate prikupiti semantičko kernel
- Prikupite sve moguće izraze za ove zahtjeve
- Čist
- Klaster i stvarajte strukturu
To zahvaljujući stvaranju takvog grupnog semantičkog kernela, možete:
- Napravite strukturu na sajtu
- Kreirajte meni
- Pisanje tekstova, metauring, taitla
- Prikupite pozicije za praćenje zvučnika na zahtjev
Sada malo o programima i uslugama
Programi za sakupljanje semantičkog kernela
Ovdje ću opisati ne samo programe, već i dodatke i mrežne usluge koje koristim
- Yandex Wordstat asistent je dodatak, zahvaljujući tome, prikladno je odabrati zahtjeve iz Vordstata. Izvrsno za brzu kompilaciju jezgre na maloj lokaciji ili 1 stranici.
- Caicollector (Slobel - besplatna verzija) - punopravni program za grupiranje i stvaranje semantičkog kernela. Evoide od velike popularnosti. Ogroman broj funkcionalnog uz glavni smjer: Odabir ključeva od gomile drugih sustava, mogućnost automatskog računala, prikupljanje položaja u Yandexu i Googleu i još mnogo toga.
- Just-Magic - multifunkcionalna internetska usluga za izradu jezgre, autoriranja, testiranja kvalitete teksta i drugih funkcija. Servis uvjetno besplatan, za punopravni posao morate platiti pretplatu.
Hvala vam što ste pročitali članak. Zahvaljujući ovom koraku priručnika, možete napraviti semantički kernel vaše web lokacije za promociju u Yandexu i Googleu. Ako imate bilo kakvih pitanja, postavite u komentare. Ispod su bonusi.
Semantički kernel je prilično klađenje tema, zar ne? Danas ćemo to popraviti zajedno sakupljanjem semantike u ovoj lekciji!
Ne vjerujem? - Pogledajte sebe - dovoljno je samo da se vozite u Yandex ili Google fraza semantičke jezgre stranice. Mislim da ću danas popraviti ovu dosadnu grešku.
Ali u stvari, šta je ona za vas - savršena semantika? Možda mislite da je za glupo pitanje, ali u stvari je potpuno Nehall, samo većina web-majstora i vlasnika web stranica smatra da mogu napraviti semantičke jezgre i da će se svaki školkati sa svim tim, da, oni sami pokušavaju naučiti druge ... Ali u stvari, sve je mnogo teže. Jednom me pitao - šta da radim na početku? - stranica i sadržaj ili sez kerneli pitao je osobu koja se ne smatra pridoškom generalnom direktoru. Ovdje ovo pitanje I javite mi da razumijem svu poteškoće i dvosmislenost ovog problema.
Semantički kernel je osnova temelja - vrlo prvo komore koje stoji prije i započinje bilo koji reklamna kampanja Na internetu. Uz to, semantika stranice je najotstavniji proces koji će zahtijevati puno vremena, ali s više hvala u bilo kojem slučaju.
Pa ... da stvorimo njegova Zajedno!
Mali predgovor
Da bismo stvorili semantičko polje stranice, trebat će nam jedan program samo - Kolektor ključa.. Na primjeru kolektora, shvatit ću primjer prikupljanja male grupe. Pored toga plaćeni program, Postoje i besplatni analozi poput Slobel-a i drugih.
Semantika prikupljena u nekoliko osnovnih faza, među kojima treba izdvojiti:
- brainstorming - analiza osnovnih izraza i obuke raščlanjivanja
- rang - proširenje osnovne semantike na osnovu Vordstata i drugih izvora
- otvaranje - spuštanje nakon raščlanjivanja
- analiza - analiza frekvencije, sezonalnosti, konkurencije i drugih važnih pokazatelja
- pOVREDE - GRUPPING, ODJELJENJE TRGOVINSKE I INFORMACIJSKE FRAZE NUCLEUS
O najviše važne faze Kolekcija i raspravljat će se u nastavku!
VIDEO - Kompilacija semantičkog jezgre konkurenata
Brainstorming pri stvaranju semantičkog kernela - naprezanje mozga
U ovoj je fazi potrebno imajući u vidu izborasemantička jezgra stranice i smislite što više fraza pod našim temom. Dakle, pokrenite kay kolektor i odaberite wordstat raščlanjivanje, kao što je prikazano na ekranu:

Imamo mali prozor, gdje trebate uvesti maksimum fraza na naš predmet. Kao što sam već rekao, U ovom ćemo članku stvoriti primjer skupa fraza za ovaj blogDakle, fraze mogu biti sljedeće:
- sEO blog
- sEO blog
- blog o SEO-u
- blog o SEO-u.
- promocija
- promocija projekat
- promocija
- promocija
- promocija blogova
- promocija bloga
- promocija blogova
- promocija bloga
- Članci promocije
- aktivirana promocija
- miralinks.
- radite u Sapeu.
- kupnja veza
- kupovina veza
- optimizacija
- optimizacija stranice
- interna optimizacija
- nezavisna promocija
- kako promovirati resurs
- kako promovirati vašu stranicu
- kako promovirati stranicu sami
- kako promovirati stranicu sami
- nezavisna promocija
- besplatna promocija
- besplatna promocija
- optimizacija pretraživača
- kako promovirati stranicu u Yandexu
- kako promovirati stranicu u Yandexu
- promocija pod Yandexom.
- promocija pod Googleom
- promocija u Googleu
- indeksiranje
- indeksacija ubrzanja
- odaberite mjesto donatora
- donatorska odjava
- promocija Postov
- korištenje postova
- promocija blogova
- algoritam Yandex
- ažuriraj Titz
- ažuriranje baze podataka za pretraživanje
- ažuritelj Yandex
- linkovi zauvijek
- vječne reference
- najam linkova
- reference za najam
- veze sa mesečnom uplatom
- kompilacija semantičkog jezgra
- promocija tajna
- promocija tajna
- tajne Seo.
- optimizacija tajna
Mislim da je dovoljan, pa popis sa poda stranice;) Općenito, ideja je da je u prvoj fazi potrebna analizirala našu industriju kako bi se maksimiziralo i biramo onoliko fraza koje odražavaju predmet web mjesta. Iako ako ste nešto propustili u ovoj fazi - ne očajavajte - umplifikovane fraze nužno će se pojaviti na sljedećim fazamaSamo moram raditi puno dodatnog posla, ali ništa strašno. Svoju listu uzimamo i kopiramo na kolektor ključa. Zatim kliknite na gumb - Poule sa yandex.wordstat.:
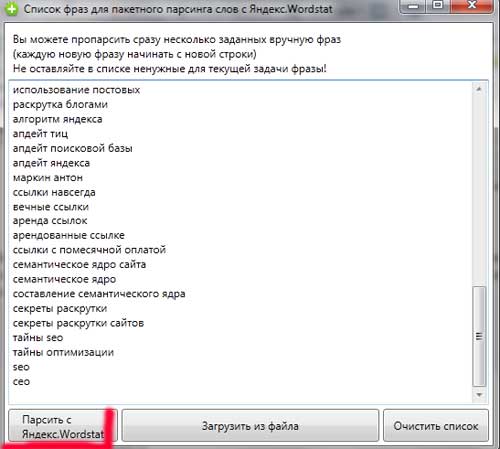
Rangsing može potrajati dosta vremena, pa biste trebali biti strpljivi. Semantički kernel obično ide 3-5 dana, a prvi dan ćete ići na pripremu osnovne semantičke kernela i raščlanjivanja.
O tome kako raditi sa resursom, kako odabrati ključne riječi napisao sam detaljno uputstvo. I možete naučiti o promociji web mjesta na zahtjevima NF-a.
Pored toga, reći ću da umjesto brainstorming možemo koristiti semantiku konkurenata s jednom od specijaliziranih usluga, na primjer, špijune. U sučelju ove usluge jednostavno unosemo ključnu riječ koja vam je potrebna i vidjeti glavne konkurente koji su prisutni na ovoj frazi na vrhu. Štaviše, semantika lokacije bilo kojeg takmičara može se u potpunosti istovariti ovom uslugom.

Dalje, možemo odabrati bilo koji od njih i izvući njegove zahtjeve koji će se ostaviti od smeća i koristiti kao osnovna semantika za daljnje raščlanjivanje. Ili to možemo učiniti još lakšim i koristiti.
Čišćenje semantike
Čim se reč ogleda u potpunosti - vrijeme je za odsezanje semantičkog kernela. Ova je faza veoma važna, pa bismo to trebali uzeti sa dužom pažnjom.
Dakle, moj raščlanjivanje je završio, ali izrazi su se ispostavile MnogoI zbog toga riječi riječi mogu oduzeti previše. Stoga je prije nego što nastavite s definiranjem frekvencije, potrebno je proizvesti primarno čišćenje riječi. Učinit ćemo to u nekoliko faza:
1. Filtrirajte upite s vrlo niskom frekvencijom
Da biste to učinili, zasnovan je na simbolu sortiranja u frekvenciji i počnite izvlačiti sve zahtjeve koji imaju frekvencije ispod 30:
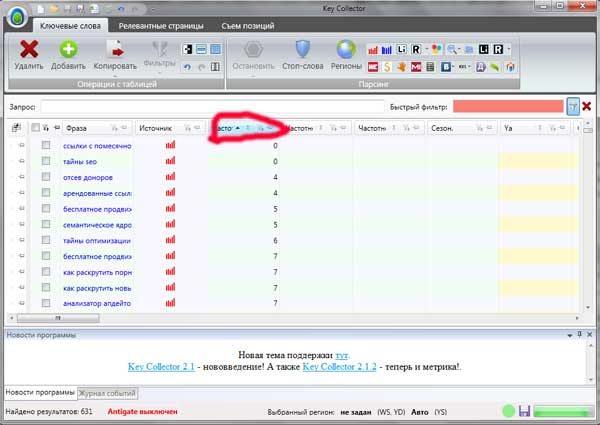
Mislim da s ovim stavkom možete lako nositi.
2. Uklonite nije prikladno u zahtjevima značenja
Postoje takvi upiti koji imaju dovoljnu frekvenciju i nisku konkurenciju, ali oni uopšte nisu prikladni za naš predmet. Takve tipke moraju biti uklonjene prije provjere tačnih ciljeva ključa, jer Provjerite može potrajati puno vremena. Izbrisat ćemo takve tipke koje ćemo ručno. Dakle, za moj blog su bili nepotrebni:
tečajevi za optimizaciju pretraživača prodaja stranica promocije
Analiza semantičkog jezgara
U ovoj fazi moramo odrediti tačnu frekvenciju naših ključeva, za koje trebate kliknuti na simbol uvećanja, kao što je prikazano na slici:

Proces je sasvim dug, tako da možete ići i napravite sebi čaj)
Kad je ček bio uspješan - potrebno je nastaviti čišćenje našeg kernela.
Predlažem vam da uklonite sve tipke frekvencije manje od 10 zahtjeva. Također, za vaš blog izbrišem sve zahtjeve koji imaju vrijednosti iznad 1.000, jer još uvijek ne planiram takve zahtjeve.
Izvoz i grupiranje semantičkog kernela
Nemojte misliti da će ova faza biti posljednja. Ne sve! Sada moramo prenijeti rezultirajuću grupu na exel za maksimalnu vidljivost. Zatim ćemo sortirati putem stranica i tada ćemo vidjeti mnoge nedostatke, korekciju sa čijom ćemo se baviti.
Izvezena semantika lokacije u Exel-u je potpuno jednostavna. Da biste to učinili, samo trebate kliknuti na odgovarajući znak, kao što je prikazano na slici:
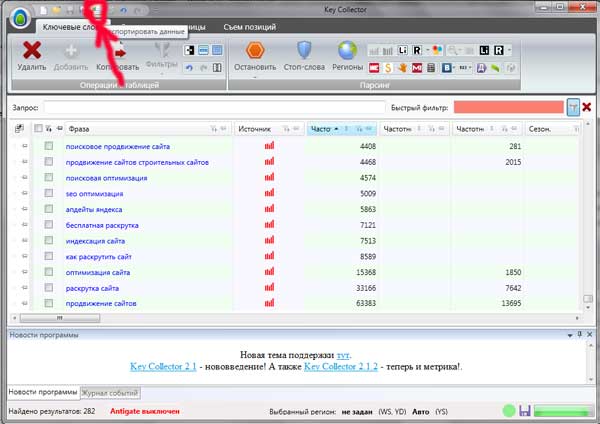
Nakon umetanja na Exel, vidjet ćemo sljedeću sliku:

Stupci označeni crvenom bojom moraju se ukloniti. Zatim stvorite još jedan stol u exel-u, gdje će se sadržavati konačni semantički kernel.
Nova tablica bit će 3 stupca: Urlstranice, ključna reč fraza i to učestalost. Kao URL, odaberite ili već postojeću stranicu ili stranicu koja će biti dizajnirana u perspektivi. Za početak, izaberimo ključeve za glavnu stranicu mog bloga:

Nakon svih manipulacija, vidimo sljedeću sliku. I odmah sugerira nekoliko zaključaka:
- takvi frekventni upiti, kao što treba imati mnogo veći rep od manje frekvencijskih izraza nego što vidimo
- Seo News
- novi ključ se pojavio, što nismo preuzeli ranije - Članci izvršnog direktora. Trebate analizirati ovaj ključ
Kao što rekoh, nema ključa od nas sakrivanje. Sljedeći korak za nas bit će mozak ove tri fraze. Nakon brainstorming-a ponavljamo sve korake počevši od prvog predmeta za ove tipke. Svi vam se možete činiti preduga i tezi, ali jeste, jeste - sastavljanje semantičkog jezgra je vrlo odgovoran i mukotrpan rad. Ali, kompetentno je sastavljena sekta u velikoj mjeri pomoći u promociji web mjesta i vrlo se može uštedjeti vašem proračunu.
Nakon svih prihoda uspjeli smo dobiti nove ključeve za glavnu stranicu ovog bloga:
- najbolji SEO blog
- seo News
- Članci SEO.
I neki drugi. Mislim da vam je tehnika razumljiva.
Nakon svih ovih manipulacija, vidjet ćemo koje stranice našeg projekta trebaju se mijenjati (), a koje nove stranice trebaju dodati. Većina tipki koje je pronašlo od nas (sa frekvencijom do 100, a ponekad i mnogo viši) mogu se lako promovirati sami.
Konačno livenje
U principu, semantička jezgra je gotovo spremna, ali postoji još jedna lijepa važna tačkašto će nam pomoći primebljivo poboljšati našu porodičnu grupu. Za to nam je potreban Seopult.
* U stvari, možete koristiti bilo koju od sličnih usluga koje omogućuju da naučite konkurenciju po ključnim riječima, na primjer, Mutagen!
Dakle, stvaramo još jedan stol u egzonu i kopiramo samo tasterna imena (srednji stupac). Da ne potrošite puno vremena, kopiram samo ključeve za glavnu stranicu vašeg bloga:


Zatim provjerite troškove pribavljanja jedne prijelaze na naše ključne riječi:
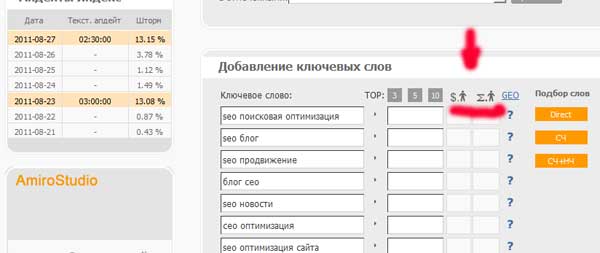
Troškovi tranzicije na neke fraze premašili su 5 rubalja. Takve fraze trebaju biti isključene iz našeg kernela.

Možda će vaše postavke biti nešto drugačije, onda možete isključiti manje skupe izraze ili obrnuto. U svom slučaju izbrisao sam 7 izraza.
Korisne informacije!
prema pripremi semantičkog kernela, sa fokusom na skrining najnižeg konkurentskih ključnih riječi.
Ako imate svoju internetsku trgovinu - pročitati , gdje je opisano kako se može koristiti semantička jezgra.
Klasteriranje semantičkog kernela
Siguran sam da ste ga prethodno imali čuti ovu riječ kako se primjenjuje na promociju pretraživanja. Radimo da to shvatimo kakva je zvijer tako i zašto je to potrebno prilikom promocije stranice.
Model klasičnog promocije pretraživanja izgleda ovako:
- Odabir i analiza upita za pretraživanje
- Grupiranje upita na stranicama na licu mjesta (slijetanje)
- Priprema SEO tekstova za stranice slijetanja na osnovu grupe upita za ove stranice
Da biste olakšali i poboljšali drugu fazu na popisu iznad i služi kao klasteriranje. U suštini je klastering softverska metoda koja služi za pojednostavljenje ove faze prilikom rada sa velikim semantikom, ali sve nije tako jednostavno kao što se možda čini na prvi pogled.
Za bolje razumijevanje teorije klasteriranja trebali biste napraviti mali izlet u povijest SEO-a:
Doslovno prije nekoliko godina, kada se pojam grupiranje nije pazio na svaki ugao - Peenes, u velikoj većini slučajeva grupisane semantikom rukama. Ali prilikom grupisanja ogromne semantike u 1000, 10 000, pa čak i 100.000 zahtjeva, ovaj se postupak pretvorio u stvarnu mačku za običnu osobu. A onda je metodologija za semantičku grupu počela koristiti svuda (a danas mnogi koriste ovaj pristup). Semantička tehnika grupiranja uključuje kombiniranje u jednu grupu upita koji imaju semantičke odnose. Kao primjer - zahteva "Kupi veš mašina"I" Kupite veš mašinu do 10.000 "u kombinaciji u jednu grupu. I sve bi bilo u redu, ali ova metoda Sadrži niz kritičnih problema i za njihovo razumijevanje potrebno je uvesti novi termin u našoj naraciji, naime - " namjeran zahtjev”.
Najlakši način za opisivanje ovog termina može biti kao potreba korisnika, njegova želja. Introvent nije ništa više od želje korisnika koji ulazi u upit za pretraživanje.
Osnova grupiranja semantike je prikupljanje u jednoj grupi zahtjeva koji imaju istu namjeru, ili što je bliže mogućem intenzitetu, a ovdje se dva zanimljiva karakteristika pojavljuju odmah, naime:
- Istoj namjeri može imati nekoliko zahtjeva koji nemaju nikakvu semantičku blizinu, na primjer - "Auto servis" i "Prijavi se za"
- Zahtjevi koji imaju apsolutnu semantičku blizinu mogu sadržavati radikalno različite intenzite, na primjer, situacija u udžbeniku je "mobilni telefon" i "Mobilni telefoni". U jednom slučaju, korisnik želi kupiti telefon, a u drugom za gledanje filma
Dakle, grupiranje semantike u semantičkom prepisku ne uzima u obzir intenzitet zahtjeva. I grupi na taj način neće vam dopustiti da napišete tekst koji će pasti u vrh. U vrijeme ručnog grupisanja za uklanjanje ovog nesporazuma, momci sa profesijom "Prfudial SEO specijalista»Analizirao je izdavanje rukama.
Suština klasteriranja je usporedba formirane izdavanja pretraživača u potrazi za pravila. Od ove definicije trebali biste odmah zabilježiti za sebe da sama klasteriranje nije istina, jer formirana izdavanja ne može otkriti potpuno namjeru (u Yandex bazi može biti jednostavno da je jednostavno postavljeno mjesto koje je pravilno kombinirao zahtjeve za grupa).
Mehanika klasteriranja su jednostavna i izgleda ovako:
- Sistem naizmjenično ulazi u sve zahtjeve koje su joj dostavljene izdavanje pretrage i pamti rezultate vrha
- Nakon alternativnog ulaza zahtjeva i održavanje rezultata, sustav traži raskrižje u izručenjem. Ako je ista stranica isti dokument (stranica stranice) nalazi se u vrhu odmah u nekoliko zahtjeva, tada se ti zahtjevi teoretski mogu kombinirati u jednu grupu u jednu grupu
- To postaje relevantan takav parametar kao grupa grupiranja, koja govori sistem, koliko dugo mora postojati raskrsnica da zahtjevi mogu dodati jednu grupu. Na primjer, snaga grupiranja 2 znači da u izrukunju 2 minute trebaju biti prisutne najmanje dvije raskrsnice. Također lakše - najmanje dvije stranice dvije različite lokacije trebaju biti prisutne istovremeno u gornjem dijelu jedan po jedan i drugi zahtjev. Primjer u nastavku.
- Pri grupiranju velikih semantike, logika veza između zahtjeva je relevantna na osnovu koje postoje 3 osnovne vrste grupiranja: meko, srednje i tvrdočno. I dalje ćemo razgovarati o vrstama klasteriranja u sljedećim zapisima ovog dnevnika.
Kako napraviti informativnu komponentu mjesta tako da ga kupci mogu brzo pronaći
Dakle, odlučili ste kreirati portal na kojem bi ljudi mogli pronaći zanimljive informacije, ali znate da su nam potrebne neke vještine za promociju, naime, sastavljanje semantičkog kernela. Ali semantika samo sugerira da će mjesto biti ispunjeno značenjem. Stoga će se reći ovdje kako ubiti dva zera odjednom - i privući publiku za korisne informacije, a ne prisiljavati pretraživače "zakleti se".Stari i novi pristup popunjavanju podataka o web mjestu i semantičkog kernela
Izrada stranice, prije svega, morate znati koji su korisnici zainteresirani i kako traže informacije - na kraju krajeva, isti podaci mogu se naći različito. A također je potrebno uzeti u obzir interese korisnika - jer otkako bi sve informacije koje bit će predstavljene na vašoj web lokaciji trebale biti zanimljive bilo kojem čitatelju, tada su ljudi trebaju biti uključeni u čitanje. I bez pretraživača, nije potrebno učiniti - Yandex, a Google jednostavno neće "prihvatiti" portal sami ako se pogubi niz uvjeta.Konkretno, rasipanje ključnih riječi, od kojih se izravna za pretraživanje čine na cijelom portalu. Stoga je važno ispuniti tekst semantičkog opterećenja. To nije ništa drugo nego semantičko (semantičko) jezgro - kombinacija riječi i fraza koje odražavaju tematsku orijentaciju i strukturu internetskog resursa. Općenito, semantic je podjela lingvistike koja istražuju semantički sadržaj jedinica (elemenata) jezika. Svi su vjerovatno vidjeli takve izraze na web lokacijama kao "glavni lik pomaže prijateljima da gledaju filmove putem interneta da ne postanu žrtve negativca" (frazu se približava, nadam se, razumljiva je. Ovdje korisnik jasno vidi da postoji ključna riječ "Gledajte filmove na mreži", ali to nije učinjeno za njega, već za pretraživač. Kao rezultat toga, on se može osjećati prevareno - nema potrebe da se prevrnete u takvo, ništa dobro neće donijeti. Nadležni tekst sa uvođenjem semantičkog kernela smatrat će se mnogo boljim.
Da bi korisnik mogao pronaći internet resurs, možete koristiti na dva načina:
- Prvo, analizirajte upite za pretraživanje kupaca, nakon što u ovom slučaju izvrši strukturu portala (semantičkog ili semantičkog, kernela, u ovom slučaju izvršava odlučujuću vrijednost u okviru i strukturu resursa);
- prvo napravite plan kako će izgledati struktura web lokacije, prije nego što se prebaci na analizu onoga što su korisnici zainteresirani za (semantički kernel distribuira se već na završenom okviru portala).
Prvi pristup uključuje adaptaciju trenutnim uvjetima - i ova opcija zaista djeluje. U tom se slučaju struktura resursa sažeta pod ključnim riječima i ostaje objekt. Druga opcija je kao u pjesmi vremenske mašine "Ne smijete se zasitila za promjenjivi svijet - jednog dana će voziti ispod nas." Koristeći ovaj pristup, sam biznismen odabire da želi reći potencijalnim korisnicima. Ovaj pristup se može nazvati svojevrsne proaktivne - a biznismen u ovom slučaju postat će predmet.
Važno je shvatiti da je glavni cilj marketinga i poslovanja fokus na klijenta. A druga metoda to jednostavno pruža. To jest, poduzetnik ili marketer odlučuje koji su podaci da ih treba dati publici koristeći svoj portal - i, naravno, trebaju biti u vlasništvu nekih znanja o onome što će se reći na njegovoj web stranici. Stoga prvo planira uzorni dizajn resursa, preliminarnu listu stranica, a zatim analizira kako korisnik traži informacije koje su vam potrebne. I uz pomoć Informativnog sadržaja resursa odgovoran je za pitanja koja korisnik određuje pretraživač.
Prva opcija je metoda "celebular". Bio je dugo vremena da vodi i primijeni ga sada. Ovom metodom su bile ključne fraze za koje je kreator stranice jednostavno želio doći do samog vrha pretraživača, a zatim su strukturu resursa i tipki kreirani na svim stranicama. Sadržaj informacija optimiziran je pod ključnim riječima i frazama.
Ali ova metoda u praksi pokazuje da, možda je pretraživač prevaren, ali ljudi ne. Informativna vrijednost padova resursa - ljudi ne zanimaju čitanje tekstova za koje se mogu pratiti ključne riječi, on misli negdje varanje. Ali marketing se kreira ne radi ovog - trendovi poslovnih oblika, a biznismen odluči šta razgovarati s korisnicima. Marketing ne bi trebao "plesati pod tuđom Dudkom", inače publika prestaje da ga poštuje - mora formirati sam okruženje, ali istovremeno biti orijentisan na kupca. Ni ni jedno drugo, ne postoji "seme" i zato je ogorčen.
U međuvremenu, neki od potencijalnih upita za pretraživač, i ovdje se ovdje mogu shvatiti, jer danas na Internetu postoji sjajna konkurencija. Pored toga, lokacije su ispunjene tipkama koje "love" traži motore.
Planirani rezultat izgradnje semantičkog kernela nalazi se popis ključnih upita koji se raspršuju na stranicama portala. Sadrži URL stranice, zahtjeve koji ukazuju na frekvenciju.
Dizajn stranice
Struktura ili dizajn, Internet resurs je vrsta hijerarhijskog, ili sheme web stranica. Stvaranjem toga, takvi se zadaci rješavaju kao:- Planiranje informatičke strategije i strukture informacija korisniku;
- Osiguravanje usklađenosti portala upute za pretraživanje;
- Garancija ergonomskog resursa za klijenta.
Da biste to učinili, možete koristiti sve što je zgodno - čak i MS Word ili Boja, možete ga izvući i od ruke ili na tabletu sa olovkom. Pri planiranju strukture morate odgovoriti na 2 pitanja:
- Koje informacije volite biznismen koji želite prenijeti kupcima;
- Gdje objaviti jedan ili drugi sadržaj.
Ako u obliku malog portala portala uzimate kao primjer, uključit će stranice s informacijama (recepti, povijest torte), članke i katalog robe (izlog). Ako to podnesete u obliku sheme, može izgledati ovako:
Hijerarhijska šema stranice
Zatim se dizajn izrađuje u obliku tablice. Ukazuje na hijerarhiju, naznačena je stranica naziva, stupci s ključnim riječima i njihovu frekvenciju su uključeni, kao i ukazivanje u URL-ove stranica. Ako predate tablicu dizajna slastičara, možda će biti sljedeća:

Ovako se struktura (dizajn) internetskog resursa može podnijeti kao tablica
Za početak, znamo samo "naslove stranica" i " Legenda"I" URL "," Ključevi "i" frekvencija "bit će popunjeni kasnije.
Ključne riječi
Važno je shvatiti koje su ključne riječi, a koje pretražuju upiti primjenjuju klijente - bez ovoga neće biti efikasne izrade web lokacije i prezentaciju informacija korisnicima. Možete primijeniti jednu od usluga za odabir ključnih riječi - ali važno je shvatiti da ove riječi budu prikladne.Dakle, ključevi su riječi ili fraze koje korisnici koriste kako bi pronašli željene i informacije. Jednostavan primjer je pripremiti pitu, ulazi u sistem zahtjeva "Apple Charpeck Recept sa fotografijom" u pretraživaču.
Ključevi se mogu podijeliti u nekoliko grupa:
Ovisno o popularnosti, dodijelite:
- Zahtjevi sa niskom frekvencijom (oni su prikazani 100-1000 / mjesec);
- Srednja frekvencija (1.000-5.000 utisaka);
- Velika frekvencija (zahtjevi za 5000-10.000 hitaca mjesečno).
Ovisno o potrebama kupaca variraju:
- Informacije (ako korisnik mora pronaći bilo kakve informacije - na primjer, "Kako očistiti odjeću iz fuccina", "koji vitamini poboljšavaju stanje kože");
- Transakcijski (upiti izdani za dogovor, ali bez navođenja određene stranice ili trgovine - "Kupi sofu", "Preuzmi igru", "Napravite aplikaciju za kredit");
- Navigacija (ako klijent želi pronaći informacije o određenoj web lokaciji - na primjer, "WebMoney za kreiranje kartice", "Pratite zapis-kod Whitepochea", "Euroopt popusti");
- Drugi (ako je teško odrediti šta korisnik želi - na primjer, uvođenjem fraze "Mozak", nije jasno da osoba želi znati - strukturu, orgulje, orgulje, orgulje, zanimljivosti O njemu, i osim toga, nije jasno kakav je mozak u vezi s dorzalnim ili glavom).
Sada za svaki predmet. Razlika u procjeni popularnosti ovisi o tome kako je iz konteksta jasno, o tome da li su korisnici popularni s popularnošću jedne ili druge teme. Odluka uvjetno, neki stručnjaci definiraju manji broj hitova za zahtjeve. Primjer je sljedeći slučaj: za web mjesto koje trguje sa pametnim telefonima, zahtjev "za kupovinu samsung telefon"Frekvencija je pokazala 6.000 / mesec - srednje frekvencije jedan. Istovremeno, za sportski klub, zahtjev "Thai Boxing trening" sa učestalošću mišljenja u 1.000 zahtjeva je visoka frekvencija.
Sve se to mora uzeti u obzir i dizajnirano široko rasprostranjeno semantičko kernel, a treba ga obogatiti zbog niskofrekventnih fraza, jer vjerujete u statistiku, tada se od 60% do 80% svih zahtjeva korisnika može pripisati niskom- Frekvencija. To je kao glavni resurs koji vam omogućava da privučete potencijalne kupce na web lokaciju, treba koristiti niskofrekventne tipke - ovo je vrsta uskih ključnih riječi. Morate ih razrijediti sa visokim i srednjim frekvencijskim zahtjevima.
Da bi se učinkovito koristila druga grupa, prema kojima se ključne riječi razlikuju, prije svega, prilikom distribucije ključeva na stranicama ili stvaranjem plana za punjenje informacija da bi se uzelo u obzir potrebe kupaca. To jest, članci u kojima će se korisnik pružiti informacije, moraju odgovoriti na njihova pitanja. Ovo je veliki dio ključnih fraza bez određene namjere - to je, u člancima članka, ne biste trebali umetnuti riječi "Kupiti", "Preuzmi" i slično. Odjeljci "Trgovina", "Katalog" Katalog kataloga Il "Storefine" ohrabruju se da udovolji korisničkim transakcijskim zahtjevima.
Treba imati na umu da su većina zahtjeva za transakciju komercijalna. I u skladu s tim, odlučujući se za prodaju kolača, morat ćete se natjecati sa "Torta Moskva", "Dobrynsky i partneri" i "Bečkoj radnji" - najviše veliki proizvođači Konditorski proizvodi. Ali ako kompetentno koristimo gore navedene preporuke, sve postaje mnogo lakše. Proširite semantički tekst kernel što je više moguće i smanjite frekvenciju upita. Na primjer, učestalost zahtjeva "za kupovinu američke rublje torte" u frekvenciji bit će niža od "Kupi američku tortu".
Zgrada upita za pretragu
Fraza je opći konceptšto uključuje privatno. Dakle, sa frazama za pretragu - oni uključuju telo, specifikator i rep. Na primjer, uzimajući upita za pretragu "Torta" kao osnova, ne možemo razumjeti šta je korisnik potrebno odrediti slastičarnu, kupovinu ili samo slike. Sam zahtjev je visoka frekvencija, a to znači visoku konkurenciju u pružanju rezultata. Pored toga, uvođenje upita donijet će puno poziva na web mjesto klijenta, a ne zanimljivo da dobijate informacije koje pružate, a to će negativno utjecati na faktor ponašanja u ponašanju. I sve zato što takav zahtjev sadrži samo tijelo.Ako unesemo dodatak u obliku riječi "Kupi", dobivamo inkluziju i specifikator - što određuje namjeru klijenta. Riječ možete zamijeniti "Kupiti" na "recept", a zatim će takav zahtjev postati podaci, a ako uđete u "kolače u ja volim tortu", tada će tačno pitanje biti navigacijsko. Stoga je iz precizirana da ključ utječe na ključne riječi na jednu ili drugu vrstu ključnih riječi.
Ponekad možete upoznati to, korisnik koji želi prodati određenu stvar, uvodi zahtjev za "kupiti" da vidimo gdje ljudi najviše kupuju ovu temu.

Ako unesete frazu "kupite tortu u Moskvi" ili "kupite tortu za narudžbu", tada je posljednji dio upita za pretraživanje rep. On samo pojašnjava neke detalje o tome kako ili gdje klijent namjerava to učiniti. Dakle, ako klijent mora znati određenu trgovinu, zahtjev će postati navigacijski.
Struktura okvira za pretragu
Ako pogledamo sljedeće primjere: "Kupite kućnu tortu u Alma-Ata", "Napoleon kolač za tortu", "kupite dostavnu tortu", vidjet ćemo da u svakoj situaciji postoji određena svrha korisnika, A rep samo određuje detalje.Stoga će za semantički kernel, glavna terminologija povezana s uslugama i robom bit će predstavljena na portalu ili sa poduzetničkim aktivnostima i potrebama kupaca. Dakle, ako je osobu potreban konditorski proizvod, bit će zainteresirani za kolače, marshmallows i smeće, marshmallow, vafle, kolačići, meringue, cupcakes itd. Ovo je tijelo key upit. A zatim pronađite specifičnosti i repove. Zahvaljujući frazama sa "repovima" imate i povećavate pokrivenost, a istovremeno postaje manje "pretraga konkurenti".
Internet resursi za izradu semantičkog kernela (izbor ključnih vrijednosti)
Da bismo prikupili ključne riječi za vašu web lokaciju, postoje mnogi asistenti koji olakšavaju život biznismena. Postoje plaćeni, koji su potrebni ako je mjesto ogroman ili njihov set, a besplatan, pogodan za mali portal, opcije.U članku razmatramo sljedeće resurse:
- KeyCollector (plaćen);
- Slovoeb (besplatno);
- WordStat iz Yandex'a (besplatno);
- AdWords iz Googlea (besplatno).
Kolektor ključa.
Ovo je plaćeni alat sa više funkcija. Automatizira operacije potrebne za izgradnju semantičkog kernela. Možete, naravno, koristiti besplatne analoge programa, ali za to koristite nekoliko internetskih resursa odjednom, jer ovaj program ima gotovo ništa ograničeno. Štaviše, ova usluga Jednostavno je neophodno ako posjedujete nijednu web lokaciju ili se koristi da se osigura da se sve uklopi u jedan program, kako ne bismo tražili resurse trećih strana, kao i ako imate nekoliko web lokacija ili u semantičkom sadržaju potrebna je velika stranica.Nudi sledeće karakteristike:

Ovdje liči na tipkolkorc
Slovoeb.
Ova usluga je besplatna. Programeri su isti koji su stvorili program ključnog kolektora. Da bi program koristio program, morate odrediti prijavu sa dodatnog računa direktne. To je zbog činjenice da Yandex može blokirati račun zbog automatskih upita, tako da ne koristite glavni.Resurs nudi sljedeće funkcije:
- Prikupljanje ključnih riječi putem Wordstata;
- Zahtevi za filtriranje za visoku frekvenciju;
- Sintaksa analiza upita pretraživanja.

Sučelje slovoeb.
Kako program radi? Za početak, kreiranje novog projekta. Odaberite "Dodaj fraze" - evo fraza koji koriste kupce za traženje informacija o određenom proizvodu.

Dodavanje fraze za pretraživanje na program
U meniju "Prikupljanje i statističko" odaberite željenu stavku i pokrenite uslugu. Na primjer, ako trebate prikupiti ključne fraze, odaberite ovu opciju.

Određivanje učestalosti ključnih fraza
Wordstat (Yandex servis)
Ovo je besplatan resurs za izbor i analizu. pretražite fraze. Potrebno je ako ste spremni ručno analizirati i klasificirati upite. Usluga nudi sljedeće opcije:- Prikazuje informacije o emisijama i zahtjevima za ključnu riječ, izraze pretraživanja, dok analizirate možete i opće i mobilne podatke (to jest, možete vidjeti koliko je popularan zahtjev za mobilne uređaje);
- Demonstriranje statistika po regionu;
- Prikaz podataka o popularnosti određenog zahtjeva za vrijeme ("Istorija upita");
- Prikazivanje fraze ili zatražite samo u navedenom obliku (za to potrebno je staviti frazu u navodnike);
- Prikazivanje statistika isključujući zaustavljanja (prije ove riječi trebate staviti minus tako da se ne uzima u obzir);
- Pokazivanje podataka iz upotrebe odabranog izgovora (u ovom slučaju, prije nego što ga treba staviti "+");
- Prikazivanje informacija o kategoriji zahtjeva (za ovu grupu zahtjeva treba označiti u zagradama i ključnim opcijama - za odvajanje izravne kosa "|": to je u kratkom vremenu za pribavljanje podataka na zahtjev "Order A", kupujte a Torta "," Naručite kappekyk "," kupite ogrtač "," naručite pitu "i" Kupite pitu ", slijedite upute, kao što je prikazano u slici);
- Prikazuje podatke na zahtjevima s obzirom na određena područja.

Zahtjev za "Capkeeys", opće statistike

Podaci o ključu po regiji

Ovdje možete vidjeti kada je zahtjev bio najpopularniji.

Prikazivanje fraza u navedenom obliku

Ključna reč bez reči

Statistika isključujući stanice

Podaci na šest zahtjeva odmah - ugodna stvar ako trebate brzo dobiti informacije

Ako odaberete određenu regiju, možete vidjeti šta je tamo popular
Google AdWords (Ključni planer sa Google-a)
Ako u određenoj regiji, Google značajno vodi, bolje je koristiti ovu uslugu. Dizajniran je samo za izračunavanje potreba korisnika ovog pretraživača. Usluga je besplatna, ali postoje plaćene usluge (na primjer, za oglase).Alat nudi sljedeće funkcije:
- Prikupljanje informacija o pitanjima za pretraživanje;
- Razvoj novih kombinacija zahtjeva i predviđanja njihove relevantnosti i dinamike.
Da biste dobili statistiku o posebnim zahtjevima, trebali biste odabrati ovu opciju glavna stranica Alat. Morat ćete unijeti fraze interesa i prenijeti datoteku u CSV formatu, a zatim odaberite regiju po kojoj su statistike potrebne, možete odrediti i zaustavljanje riječi (kao što je opisano u Wordstatu). Sve je spremno - možete kliknuti na tipku "Saznaj broj zahtjeva".

Informacije o Google zahtjevima
Usluge koje nude usluge analitike
Takođe možete koristiti analitičare Google Analytike ili metrike ako trebate izgraditi semantički kernel za postojeći resurs. Ovi alati pomažu u označavanju koje izraze za pretraživanje klijenata se uvode.
Ovdje možete pronaći i inspiraciju za formiranje ključnih riječi.
Pored toga, podaci o zajedničkim frazama za pronalaženje kupaca ove ili da se informacije mogu provjeriti pomoću ormara za Yandex i Google Webmastere. Posljednji podaci smješteni su u konzoli za pretraživanje, a zatim trebate ići na "Search promet - analiza zahtjeva za pretraživanje".
Webmaster Yandex predlaže korištenje odjeljka "Pretraživanje - popularni zahtjevi".
Alati za analizu web lokacija takmičara
Nadležna mjesta su još jedan resurs u kojem možete potražiti inspiraciju za traženje ključnih riječi. Da bismo ih označili, ima smisla čitati njihovu publikaciju ili provjeriti tekst pomoću tipke HTML oznake pomoću programa web stranice. Ili advego sa Istijom da vam pomogne.
Istio sučelje
Ako trebate analizirati cijeli konkurentski portal, možete koristiti sljedeće alate:
Sada više za svaku stavku.
Da bi se utvrdilo glavne tipke, trebat će ih zabilježiti, moguće je to učiniti na listu papira i pomoću računalnih programa. Trebat će vam ideje svih kolega - trebaju zabilježiti sve bez izuzetka: svaki se može pokazati kao "uzimanje grovela", što će vam privući kupce.
Lista može izgledati ovako:

Uzorak liste fraza za pretragu
Na ovoj listi gotovo svi ključevi su visoke frekvencije, bez ikakve specifičnosti. Izrazi sa srednjim i niskim frekvencijama omogućit će isto da proširi kernel. Pa idite na sljedeću fazu.
Ovdje se ova poteškoća riješi pomoću alata za odabir ključnih riječi. Na primjer, možete odabrati Yandex uslugu - jedna je od najudobnijih, uprkos prividnom početnom sloju. Ovdje možete uspostaviti obvezujući na određenu regiju ako ponudite proizvod ili uslugu u određenom geografskom objektu.
Dakle, u ovoj fazi analiziramo sve tipke koje su sastavljale kolege.

Analiza glavnog zahtjeva
Trebali biste kopirati fraze s lijevog stupca usluge i umetnite u tablicu. Sada biste se trebali fokusirati na desni stupac asistenta - ovdje Yandex nudi fraze koje su posjetitelji korišteni zajedno sa glavnom frazom. Dakle, ovdje imate priliku odabrati odgovarajuće tipke i kopirati ih u lijevu stupcu. Ne brinite ako nešto nije pogodno - ove fraze su isključene u završnoj fazi. A ona je već blizu zime u "igri prijestolja".
Rezultat ove faze bit će sastavljen popis izraza za pretraživanje, koji će biti iz svakog glavnog ključa. U ovoj fazi mogu se dobiti stotine i čak hiljade različitih zahtjeva.

Lista fraza
Idite u pozornicu za zatvaranje. Bez obzira koliko izgleda lako - nije. Ovo je najneočajniji i izazovni rad sa jezgrom. Potrebno je ručno isključiti iz semantičkog jezgara da mu ne odgovara u značenju.
Ali ne biste trebali uklanjati niskofrekventne tipke - ni u kojem slučaju. "Starica" \u200b\u200boptimizeri puštaju i tada smatraju da ovaj ključ bude smeće, ali nije potrebno naići na ovaj trik. Primjer: Uzimanje ključa "Prehrambene torte" kao osnova, možete vidjeti da servis prikazuje na ekranu 3 emisije mjesečno u regiji Cherepovets. Metoda "gotovine" uključuje izbacivanje svojih ključeva. Ali sada ćete shvatiti zašto to ne biste trebali učiniti - i nadam se da će ovaj savjet uključiti, a zatim se prijaviti u životu.
Specijalisti iz oblasti SEO-a, kako bi njihove stranice bili u vrhu pretraživača, kupili su ili iznajmljivanje veze. Istovremeno su trebali koristiti određene ključeve, metoda se sada primjenjuje. I mogu se razumjeti, jer izrazi s niskom frekvencijom ekrana, u pravilu ne plaćaju novac potrošen na linku.
Ali ako pogledate "dijetalne kolače" sa očima starog stvrdnjavanja, a može se otkriti biznismen orijentiran na kupca dodatne funkcije. Uostalom, neki od potencijalnih kupaca zaista zanimaju ovo - a ne najmanje bile su djevojke koje slijede svoju figuru. Tako da tačno znamo šta ovaj zahtjev Neko je zainteresiran, a samim tim i mirne savjesti može uključivati \u200b\u200bu semantičko jezgro. Ako slastičari u vašoj kompaniji pripremaju takav proizvod, nužno će se dobro doći tamo gdje će roba opisati. A ako ne - ovaj sadržaj podataka može biti dosadan za odjeljak Informacije o portalu.

"Dijetalna torta", koja se može smatrati smećem, zapravo to nije
Šta onda isključiti? Radimo se:
- Prvo, to su fraze u kojima su prisutni drugi brendovi;
- Drugo, ponavljajući fraze - na primjer, od 3 tipke "Torte za naručivanje nove godine", "Custor-narudžbenici", "Tortični nalog Nova godina", bit će prvi ključ;
- Treće, ako se ne bavite takvom stvari, tada, u skladu s tim, tasteri s uvođenjem riječi "jeftino" i "jeftino" za vas sigurno ne bi bilo korisno;
- Četvrti, ključevi sa neprikladnim područjima - ako se trgujete samo u herepovetcima, ali ne isporučujete u obližnjim selima ili ne trgujte određenim područjem grada, ovi podaci nisu potrebni;
- Peti, ključevi s obzirom na proizvode koje tačno znate šta neće prodati i, u skladu s tim, ne prodaje;
- I u šest, sigurno nećete koristiti fraze napisane - bez obzira, gramatičke greške ili pogreške - pretraživač će pomoći posjetitelju koji traži "kolače", umjesto "Capkequets", umjesto "kapkeky", umjesto "capkequets" .
VOUA-LA Kada ste otkrili sve ključeve koji vam ne odgovaraju, dobili ste potrebne tipke "kolači za naručivanje". Uz sve ostale morate potrošiti istu stvar. A sljedeća faza bit će klasifikacija fraza na vrstama.
Izgradnja karte sukladnosti (relevantnosti) i klasifikacija ključnih fraza
Fraze za pretres koji će se ciljna publika koristiti kao glavna, a podatke će pronaći da će korisnici na vašu web lokaciju biti integrirani u T.N. "Semantički (semantički) klasteri" su kategorije zahtjeva sličnih semantičkog sadržaja. To znači da "klaster za kolače" uključuje sve fraze koje su direktno ili indirektno artikulirane ovom riječi - i u ovom slučaju ova jedinica jezika raste kao "privatna", a sve fraze ". Što imate priliku vidjeti na slici prikazanom u nastavku.Imajte na umu da su klasteri drugog, trećeg, četvrtog kategorije prisutni ovdje. Što su opsežniji tema, veći nivo klastera. Iako se de facto dobiva tako da dovoljno klastera druge grupe.

Nivo klastera
Većina klastera definirana je u prvoj fazi kreiranja ključnih riječi. Prirodno, za to morate jednostavno razumjeti temu podnesenu, jer, bez da znate ništa o kolačima, teško možete napraviti kompetentnu semantičku jezgru. Pomoćnik za stvaranje klastera također će poslužiti kao sastavljena šema web mjesta.
Klasteriranje druge kategorije je vrlo važna. To bi trebalo dodati specifikacije koji će ukazivati \u200b\u200bna ciljeve kupaca - to je, na primjer, kupiti kolače ", historija stvaranja torte Napoleon." Posljednji klaster nalazi se u odjeljku Informacije, a prvi u katalogu.
Sada se vraćamo na hijerarhijski dijagram web stranice i razvijali se na osnovu tablice. "Torte za narudžbu" definirano je korištenjem Yandex usluge i nakon toga nije isključen sa liste. Ovaj ključ treba raštrkavati između stranica odgovarajuće particije.

Dakle, možete raskorati frazu za pretraživanje na svoju web lokaciju.
Uzmite ovaj primjer: postoje fraze u klasteru za traženje "kolača za naručivanje nogometnih tema".

Fudbalski kolači, ispostavilo se, kamatni korisnici
A ako slastičarstvo proizvodi ovu vrstu proizvoda, onda znamo koji će se odjeljak nalaziti ova stranica. Treba ga smjestiti u "kolače iz mastika", jer se ovaj materijal koristi za stvaranje takvog konditorskog proizvoda. Dakle, ovdje kreiramo odgovarajuću stranicu. Predstavljamo ga u dizajn internetskog resursa, što ukazuje na URL i pretraživanje frekvencije.

Izrada stranice u odgovarajućem odjeljku
Možete vidjeti uz pomoć istog alata koji pomaže u odabiru pravih tipki, koji i dalje zahtijeva korisnike u vezi s nogometnim temama. Te se izraze trebaju biti dodane i na ovu stranicu.

Razumijemo šta vas još zanimaju kupci u vezi s fudbalom i tortom
Tasteri primijećene. Raspravljao je preostale tipke za pretraživanje.
Shema koja je izvučena na samom početku može biti podložna promjenu čak i neograničenog broja vremena - ako je potrebno, možete kreirati nove kategorije i odjeljke. Dakle, ako ne postoji stranica "Dječji kolači", sjećajući se da firma može napraviti kolače crtanim filmovima "svinjska peppa" ili "štenad patrole", možete napraviti promjene i stvoriti stranicu. U vrijeme tih ključeva mogu se nalaziti u odjeljku "kolači iz mastike".

Stvaranje nove particije u hijerarhijskom stolu stranice "Dječji kolači"
Postoje dvije važne nijanse koje treba imati na umu:
- Klaster ne može sadržavati odgovarajuću frazu za stranicu koju želite stvoriti. Uzroci mogu biti nepravilna upotreba Ključna riječ, odlazak izbora ključnih fraza ili jednostavno slabe popularnosti robe ili usluge. Ali istovremeno, to nije razlog za odustajanje od stranice i prodaje robe. Na primjer, ako u sustavu pretraživanja niste pronašli upit za pretraživanje "Paprika za torte", ali konditorska firma ima značajke za izradu takvog proizvoda, možete razjasniti potrebe kupaca koji koriste drugu uslugu. U ovom slučaju takav će se takav zahtjev naći, a većina ih se nalazi;

Ljudi takođe traže "Peppe Peppe"
- Pa, nakon isključivanja nepotrebnih tipki, mogu postojati potpuno neprikladni zahtjevi. Pa, mogu ih ukloniti ili se prijaviti u drugom klasteru. Pretpostavimo da je konditorska kompanija specijalizirana za jedinstvene recepte, a vremenski testirani kolači poput "županijskih ruševina" ili "Napoleon" misle da je bolje odlaziti u prošlost - takve tastere mogu se prepustiti u odjeljku u kojem će se korisnik biti isporučen u odjeljku Opće informacije - u ovom slučaju "Recepti".
Ključna fraza može se staviti u odjeljak Informacije ako je vrlo popularan među posjetiteljima.
Dakle, u završnoj fazi, raspršivanje na stranicama sve tastere, učite listu web stranica portala, gdje su navedeni URL, zahtjevi i njihova frekvencija. Idemo dalje, nije sve.
Završna faza obogaćivanje semantičkog jezgara
Dakle, sada imamo sve što nam treba. Imamo stol sa semantičkim jezgrom, popisom preliminarnih web stranica i ključnih fraza koji određuju potrebe određenih kupaca. Sve će to pomoći u pripremi plana punjenja informacija (plan sadržaja). Sad, izmirići, morat ćete odrediti naziv web stranice ili članka i uključiti glavni upit za pretraživač. Ali treba imati na umu da ne mora uvijek biti najčešći ključ sa stanovišta Yandexa ili Googlea. Mora da odražava ono što želite prenijeti na korisnike i činjenicu da kupci žele dobiti.Ostale ključne fraze trebaju se primijeniti kao odgovor na pitanje - "Što treba pisati?" Naravno, ne biste trebali odmah "gurati" sve fraze koje su pronađene pomoću alata za izbor upita za pretraživanje, na određeni odjeljak - bilo da je to stranica informacijskog plana ili ponuda za kupovinu određene usluge ili proizvoda. Trebalo bi se ponovo ponoviti na samom kraju: potrebno je prvo obratiti pažnju na potrebe za informativnim potrebama korisnika, a ne na ključnim frazama i "nadjev" teksta koji vole tablete. Korisnik uvijek vidi kada pokušava "kišu" - sa kompetentnim kompilacijama teksta, on neće ni u mislima ovdje korištene ključne riječi.
Konačno, šta još uvek nema veze sa semantičkim jezgrom
Nadam se da su pitanja o onome što je već rečeno, nemate lijevo, i sada možete stvoriti desetak mjesta na osnovu stečenih znanja. Ali ipak, trebali biste odrediti neke akcije koje ne čine. Kasnije ćete u tome biti intuitivan, a sada ih treba naučiti srcem. Evo nekoliko savjeta koji će vam pomoći da postanu profesionalni u pravilnom sastavljanju internetskog resursa:- Ne odbijajte ključeve koji imaju preveliku konkurenciju. Da, nemate puno potrebe da uđete u najpopularnije upite za pretraživanje "Naručite Marshlow". Samo upotrijebite frazu kao sadržajnu ideju;
- Također, ne bi se ne smije eliminirati iz niskofrekventnih fraza - ovo su vrlo sadržajne ideje, zahvaljujući kojem ćete vjerojatno uspjeti udovoljiti onima koji su mogli pronaći takve usluge čak i od najvećih kompanija;
- Nemojte koristiti za ocjenu ključnih riječi formule i koeficijenata (poput KEI-ja, odnos popularnosti kKuckerity). Da vidimo još jednom: Semantic - lingvističarska odjeljka. Ovo nije tačna nauka, kao, na primjer, fiziku ili matematiku. Bliži se umjetnošću nego preciznim studijama i, pridržavajući se zahtjeva formule ili koeficijenta, semantika gubi isticavanje. Dakle, izgubite puno ideja za punjenje informacija, koje se program može isključiti - ali ne i program će naknadno pročitati tekst;
- Ne stvarajte zasebnu stranicu radi jedne tipke. Svakako se sastaju sa takvom kupovinom na mreži, gdje postoje posebne stranice "Kupite tortu" i "naručite tortu". Semantički jezner se ovdje gubi, jer je u suštini isto djelovanje. Ili "Kupite jeftino" i "Kupite jeftine" - to su reči sinonimi, pa ne vrijedi zasebnu stranicu sa beskorisnih sadržaja;
- Nema potrebe za potpuno automatizom dizajna semantičkog kernela. Naravno, koristili ste posebne alate za prikupljanje ključnih fraza, a za ogromne projekte takvi su alati jednostavno neophodni - posebno ključni sakupljač. Ali bez analize, koju će proizvoditi čovjek, vrijednost ključa je niska. Ovo nije sjajna tajna - čak ni oni koji koriste znanje stare škole znaju to. Usluge nam samo olakšavaju, prikupljajući informacije koje bi inače trebalo da se filtrira dugo i bolno, ali sam tekst ne može. Tačnije, takve programe postoje, ali njihova vrijednost za osobu je mala, a namijenjena su u potpunosti za drugu svrhu - ne čitati korisnika. Samo onaj koji razumije nešto u ovom području može zapravo odrediti stupanj konkurencije, izvucite plan informatičke kompanije ili analizirati situaciju u ovoj oblasti. Sve tri stavke su indirektno artikulirane dizajnom strukture web resursa i rasipanom ključnim riječima;
- Ne budite pliš - nema potrebe da se fokusirate na prikupljanje ključnih fraza. Samo pokretanje poslovanja, ne postoji sjajna poanta u vođenju pažljive špijunaže za konkurente, prikupite maksimalne ključne riječi iz svih dostupnih pretraživača do vrućeg i istraživanja pretraživača. Dovoljno je koristiti jedan - maksimalno dva resursa, a to može biti Yandex ili Google. Pa, ili Rambler sa Mail.ru je u najgorem slučaju ako je ovaj pretraživač popularan u vašoj regiji. Tut.by - ako vas zanima određena bjeloruska, ili uaboral.com - u Ukrajini. Ali oni se koriste samo kao obvezujući u regiju: Ako će, na primjer, stanovnici Bjelorusije biti zainteresirani za "kolače sa Ksenijom Sitnikom", stanovnik Rusije uopće neće reći ništa. I zato ne vrijedi i prekoračiti vašu web stranicu.
Trebate se sjetiti zašto i zašto gradite jezgru. A takođe i da je to semantički.
Pa nakon svega, marketinga ili SEO?
Nemoguće je reći da je još jedan drugačiji. Marketer može biti dobar "Ceeshnik" i obrnuto. Samo od osobe koja bi mogla pravilno napraviti semantički kernel za svoju web lokaciju, ona je prvenstveno potrebna logika biznismena i marketara (orijentacija na klijenta) i dalje - vještine specijalista za SEO polje (pravilno raspoređivanje Ključne riječi). Morate shvatiti da vi kao biznismen može ponuditi potencijalni potrošač. Nakon toga treba shvatiti kako kupci traže i pronalaze potrebne podatke. A gore opisani instrumenti pomoći će. Analizirajte, prosirajte nepotrebne, pronađite najprikladnije tastere, klasificirajte ih i ergonomski se raspršio po cijeloj strukturi web mjesta. I VUA-LA, sada je došao trenutak kada možete započeti formiranje plana sadržaja. Pažnja !!!. Uprava nije odgovorna za njen sadržaj.Često početni webmasteri, suočeni s potrebom za stvaranjem semantičkog jezgara, ne znaju odakle započeti. Iako u ovom procesu ništa nije komplicirano. Jednostavno rečeno, morate sastaviti popis ključnih fraza za koje korisnici interneta traže informacije na vašoj web lokaciji.
Što se više i tačnije, to će,, što je lakše napisati dobru kopiju kopije, a vi dobijete visoke pozicije u potrazi za željenim zahtjevima. Kako pravilno napraviti velike i visokokvalitetne semantičke jezgre i šta učiniti s njima sljedeći koji web mjesto odlazi na vrh i sakuplja puno prometa, a to će biti govor u ovom materijalu.
Semantički kernel je skup ključnih fraza kojima je povjereno značenje, gdje svaka grupa odražava jednu potrebu ili želju korisnika (namjera). To jest, ono što osoba misli, vozena po svom zahtjevu za tragove.
Čitav proces stvaranja jezgra može se podnijeti u 4 koraka:
- Naići na zadatak ili problem;
- U glavi formuliramo kako pronaći njegovo rješenje putem pretrage;
- Vozite zahtjev Yandexu ili Googleu. Pored nas, drugi ljudi to rade;
- Najčešće mogućnosti poziva spadaju u analitičke usluge i postaju ključne fraze koje prikupljamo i grupiramo za potrebe. Kao rezultat svih ovih manipulacija dobiva se semantički kernel.
Da li je potrebno odabrati ključne fraze ili možete bez njega?
Prije toga, semantika je bila da bi pronašli najčešće ključne riječi na temi, unesite ih u tekst i dobiti dobru vidljivost na njima u pretraživanju. Posljednjih 5 godina, pretraživači nastoje otići u model u kojem će se relevantnost zahtjeva za dokumentom procijeniti ne po broju riječi i raznolikosti njihovih varijacija u tekstu, već u skladu s ocjenom otkrivanja namjere.
Google je započeo u 2013. godini sa algoritmom hummingbird-a, Yandex u 2016. i 2017. sa Palee i Queen Technologies, respektivno.
Tekstovi napisani bez XIA neće moći u potpunosti otkriti temu, što znači da se takmiče s vrhom u srednjofsnim i srednjim frekvencijskim zahtjevima neće raditi. Izrada opklade na niskim frekvencijskim zahtjevima nema smisla - premalo prometa na njima.
Ako želite, a u budućnosti uspješno promovirajte sebe ili svoj proizvod na Internetu - morate naučiti kako napraviti pravu semantiku, što u potpunosti otkriva potrebe korisnika.
Klasifikacija upita za pretraživanje
Ispitaćemo 3 vrste parametara za koje se ocjenjuju ključne riječi.
U frekvenciji:
- Visoka frekvencija (HF) - izrazi koji definiraju temu. Sastoji se od 1-2 riječi. U prosjeku, broj upita za pretraživanje počinje sa 1000-3000 mjesečno i može doći do stotine hiljada utisaka ovisi o temi. Najčešće su pod njima glavne stranice web lokacija.
- Srednje klase (sch) - zasebne upute u temi. Poželjno sadrže 2-3 riječi. S preciznom frekvencijom od 500 do 1000. obično kategorije komercijalne web stranice ili teme za velike informativne članke.
- Niska frekvencija (LF) - Zahtjevi koji se odnose na potragu za specifičnom odgovoru na pitanje. Po pravilu, od 3-4 riječi. To može biti kartica ili tema članaka. U prosjeku tražite od 50 do 500 ljudi mjesečno.
- Prilikom analize metričkih ili podataka statističkih brojila možete upoznati drugu vrstu mikroka ključeva. Ovo su fraze koje se često pitaju jednom na pretraživanju. Nema smisla izoštriti ispod njih, stranica nije. Dovoljno je biti na vrhu LF-a, koji ih uključuje.
Za konkurentnost:
- Highborne (VC);
- Mediteran (SC);
- LongCover (NK);
Za potrebe:
- Navigacija. Izraziti želje korisnika da pronađe određeni internetski resurs ili informacije o njemu;
- Informacije. Karakterizira dostupnost informacija u dobivanju informacija kao odgovora na zahtjev;
- Transakcija. Direktno povezano sa željom za kupovinu;
- Nejasno ili uobičajeno. Oni na kojima je teško tačno odrediti namjeru.
- Geo-ovisan i ovisan o geonu. Odražavaju potrebu za traženjem informacija ili izvršite transakciju u svom gradu ili bez regionalnog obvezanja.

Ovisno o vrsti web lokacije, mogu se dati sljedeće preporuke prilikom odabira ključnih fraza za semantičko kernel.
- Informativni resurs. Glavni naglasak treba obaviti u potrazi za člancima u obliku zahtjeva LF i niskog takmičenja. Preporučuje se otkriti širinu temu i duboko, povlačenje stranice za veliki broj LF tipki.
- Internetska trgovina ili komercijalna stranica. Prikupljamo HF, SCH i LF, koji se najviše segmentira tako da su sve fraze transakcijske vrste i odnose se na jedan klaster. Naglasak je u potrazi za dobro konvertibilnim NC NK ključnim riječima.
Kako napraviti sjajnu semantičku kernel - korak po korak uputstva
Prešli smo na glavni dio članka, gdje ću dosljedno rastaviti glavne faze koje trebate ići na izgradnju kernela buduće stranice.
Da bi proces bio jasniji, svi koraci su dati sa primjerima.
Traži osnovne izraze
Rad sa kodom započinje izborom primarne liste osnovnih riječi i fraza (HF), koji su najbolje karakterizirani temama i koriste se u širokom smislu. Nazivaju se i markeri.
Može biti poput imena uputa i vrsta proizvoda, popularnih zahtjeva s teme. U pravilu se sastoje od 1-2 riječi i ima desetine, a ponekad stotine hiljada emisija mjesečno. Bolji tasteri su bolji da ne trebate ne utapati u minus riječi u fazi širenja.
Prikladnije za odabir markerskih izraza koji koriste. Gledajući u zahtjev, u lijevom stupcu vidimo izraze, koje on sadrži sam, u pravu - slični zahtjevi iz kojih često možete pronaći pogodno za širenje tema. Također, usluga pokazuje osnovnu frekvenciju fraze, odnosno koliko ih je puta traženo mjesec dana u svim riječima riječi i uz dodatak bilo koje riječi.

Samo po sebi, takva frekvencija nije baš zanimljiva, pa je potrebno koristiti operatere da biste dobili preciznije vrijednosti. Mi ćemo analizirati šta je to i za šta.
Operatori Yandex Wordstat:
1) "..." - citati. Zahtev citata omogućava vam da pratite koliko puta u Yandexu tražila je frazu sa svim njegovim rečima, ali bez dodavanja drugih reči (repovi).

2)! - Uzvičnik. Koristeći ga prije svake riječi u zahtjevu, mi ga popravljamo s njegovim oblikom i dobijamo broj žalbi u pretraživanju po ključnoj riječi samo u određenom obliku riječi, ali s repom.

3) "! ...! ...! ..." - citati i uskličnik prije svake riječi. Najvažniji operator za optimizator. Omogućuje vam da shvatite koliko se puta ključna riječ traži mjesečno u skladu s datom frazom, jer je napisana, a da ne dodaje nikakve riječi.

4) +. Yandex Vordstat ne uzima u obzir prijedloge i zamjenice prilikom traženja. Ako vam treba da im pokaže - stavite znak plus ispred njih.

pet) -. Drugi najvažniji operator. Uz njega, riječi koje nisu prikladne brzo se eliminiraju. Da biste ga primijenili nakon analizirane fraze, stavili smo minus i zaustavljamo riječ. Ako su pomalo ponovljeni postupak.

6) (... | ...). Ako trebate doći od Yandexa, podaci o nekoliko fraza istovremeno ih zaključuju u zagrade i dijele direktan rob. U praksi se metoda retko koristi.

Za pogodnost rada sa uslugom, preporučujem da postavljate posebno proširenje za pomoćnika za pomoćnika Wordstat. Postavlja se na Mozilu, Google Chrome, I.Baurazer i omogućava vam kopiranje fraza i njihovu frekvenciju jednim klikom "+" ili "Dodaj sve" ikonu.

Pretpostavimo da smo odlučili napraviti vaš blog na izvršnom direktoru. Odaberite 7 glavnih fraza za IT:
- semantički kernel;
- optimizacija;
- kopiranje;
- promocija;
- monetizacija;
- Direktan
Potražite sinonime
Na potaknuti sustavi pretraživanja, korisnici mogu koristiti riječi bliske značenja, ali različite pismenim putem.
Na primjer, "automobil" i "automobil".
Važno je pronaći kako je moguće sinonimi moguće povećati pokrivenost budućeg semantičkog jezgara. Ako se to ne učini, onda će vam pričati, propustit ćemo čitav sloj ključnih fraza koji otkrivaju potrebe korisnika.
Ono što koristimo:
- Brainstorm;
- Desni stupac Yandex Wordstat;
- Zahtjevi postignutim na ćirilici;
- Posebni uvjeti, skraćenice, sleng izraze iz teme;
- Blokira Yandex i Google - zajedno sa "nazivom upita" traže;
- Snippembe takmičara.
Kao rezultat svih akcija za odabranu temu, dobivamo takav popis fraza:

Proširenje glavnih zahtjeva
Prekršićemo ove ključne riječi da bismo identificirali osnovne potrebe ljudi u ovom području.
Prikladniji za to u programu ključnog kolektora, ali ako je šteta za plaćanje 1800 rubalja po licenci, koristite ga besplatan analogni - Mač.
Prema funkcionalnosti, naravno je slabiji, ali za male projekte je pogodan.
Ako ne želite da se obvedite u radu programa, možete koristiti pravednu uslugu i žurnu analitiku. Ali ipak je bolje provesti malo vremena i baviti se softverom.
Pokazat ću princip rada u kolektoru Kay-a, ali ako radite s riječi, i sve će se i sve razumjeti. Programsko sučelje je slično.
Postupak:
1) Dodat ćemo popis osnovnih fraza u program i ukloniti osnovnu i preciznoj frekvenciji na njima. Ako planiramo promovirati u određenoj regiji - ukazujemo na regionalnost. Za informativne stranice najčešće nije potrebno.

2) Iskrivi lijevi stupac Yandex WordStat prema dodanim riječima kako bi se dobili svi zahtjevi iz naše teme.

3) Na izlazu smo navršili 3374 izraza. Uklonit ćemo tačnu frekvenciju na njima, kao u 1. točki.

4) Proverite da li nema tastera na listi sa nulte osnovnom frekvencijom.

Ako uklonimo i pređemo na sljedeći korak.
Minus-reči
Mnogi zanemaruju postupak prikupljanja minus riječi, zamjenjujući ga uklanjanjem fraza koji nisu prikladni. Ali kasnije ćete shvatiti da je to zgodno i stvarno štedi vrijeme.
Otvorite karticu Podaci u kaj kolektoru -\u003e Analiza. Odaberite vrstu grupiranja prema pojedinim riječima i listovima navodite tipke. Ako vidite frazu koja se ne uklapa - pritisnite plavu ikonu i umjesto toga dodajte riječ sa svim svojim riječima.

U Slobelu, rad sa čepnim rečima se provodi u pojednostavljenoj verziji, ali možete napraviti i svoju listu fraza koji se ne uklapaju i primenjuju ih na popis.
Ne zaboravite koristiti sortiranje osnovne frekvencije i broja izraza. Ova opcija pomaže u brzom smanjenju liste izvornih fraza ili odsjeći retko susret.

Nakon što smo sastavili popis zaustavljanja, primijenite ih na naš projekt i prijeđite na prikupljanje pretrage MPS.
Savjeti za raščlanjivanje
Kada unosite zahtjev za Yandex ili Google, pretraživači nude svoje mogućnosti za nastavak iz najpopularnijih fraza koje pokreću Internet. Ove ključne riječi nazivaju se savjeti za pretraživanje.
Mnogi od njih ne spadaju u Wordstat, pa kada se izgradi semantic, morate sastaviti takve zahtjeve.
Kay Collector, prema zadanim parazitisom s poprsjem krajnjeg, ćirilice i latino abecede i sa prostorom nakon svake fraze. Ako ste spremni da žrtvujete iznos da biste značajno ubrzali proces, stavite krpelj na točku "Sakupite samo vrhunske savjete bez probijanja i razmaka nakon fraze".

Često, među pretraživačima možete pronaći izraze s dobrom frekvencijom i konkurencijom u desetinama vremena niža nego u Vordstatu, tako da u uskim nišama preporučujem prikupljanje maksimuma riječi.
Vrijeme raščlanjivanja vrhova direktno ovisi o broju istodobnih žalbi na servere pretraživača. Maksimalni kolekcionar KEI podržava 50 prometa.
Ali da biste za donete zahtjeve u ovom režimu trebate toliko punomoćnika i računa u Yandexu.
Za naš projekt, nakon prikupljanja uputa, ispostavilo je 29595 jedinstvenih fraza. Po vremenu, čitav proces trajao je nešto više od 2 sata na 10 niti. To jest, ako ima 50, stavićemo za 25 minuta.

Definicija osnovne i precizne frekvencije za sve fraze
Za daljnji rad važno je odrediti osnovnu i tačnu frekvenciju i prekinuti sve nule. Zahtjevi s malim brojem emisija ostaju ako su meta.
To će pomoći da bolje razumete intrinzicu i stvori potpuniju strukturu članka nego na vrhu.
Da biste uklonili frekvenciju, prvo zasjepite sve nepotrebne:
- drhti od riječi
- ključevi s drugim simbolima;
- holandski fraze (kroz "analizu implicitnog hrasta" alata)

Za preostale izraze definirat ćemo tačnu i osnovnu frekvenciju.
ali) za izraze do 7 riječi:
- Mi biramo kroz filter "fraza se ne sastoji od 7 riječi"
- Otvorite prozor "Kolekcija sa Yandex.direct" klikom na ikonu "D";
- Ako odredite regiju;
- Odaberite zagarantovani režim prikaza;
- Stavili smo period prikupljanja - 1 mjesec i označite iznad željenih vrsta frekvencije;
- Kliknite "Dobivanje podataka".

b) za fraze sa 8 riječi:
- Sperificiramo za kolonu "FRASE" Filter - "sastoji se od najmanje 8 riječi";
- Ako se trebate premjestiti u određenom gradu u nastavku, određujemo regiju;
- Kliknite na luk i odaberite "Prikupite sve vrste frekvencija".

Ključne riječi čišćenja od smeća
Nakon što smo dobili informacije o broju utisaka za naše tastere, možete početi koristiti neprikladni.
Razmotrite postupak za korake:
1. Idite na "Analiza grupa" KEI sakupljača i sortiramo ključeve po količini upotrebe riječi. Zadatak da se pronađe neadekvatno i česte i stavite ih na popis zaustavljanja riječi.
Radimo sve kao i u "minusnim riječi".

2. Primjenite na popis naših fraza sve su se riječi pronađene i pokrenute na njemu da definitivno ne izgube ciljane upite. Nakon provjere kliknite Izbriši "označene fraze".

3. Izvor Izrazi kratkih sredstava, koji se rijetko koriste u preciznoj unosu, ali imaju visoku osnovnu frekvenciju. Da biste to učinili, u postavkama programa ključnog kolektora u ključu i SERP-u ubacite formulu izračuna: tipku 1 \u003d (YandexwordStatBaseFreq) / (YandexwordStatQuotePreqreq) i spremite promjene.

4. Napravimo ključ 1 izračun i uklanjamo te fraze da se ovaj parametar pokazao iz 100 i više.

Preostali tasteri trebaju biti grupirani na stranicama ukrcavanja.
Grupiranje
Raspodjela grupa u grupama počinje sa grupim frazama duž vrha besplatni program "MAJENTO CLUSTERSER". Preporučujem da se plaćeni analog sa širim funkcionalnošću i bržem brzinom rada - Keyassort, ali i dovoljno slobodno za malu kernel. Jedina nijansa koja za rad u bilo kojem od njih trebat će kupiti XML ograničenja. Prosječna cijena je 5 str. Za 1000 zahtjeva. Odnosno, prerada srednje jezgre do 20-30 hiljada ključeva koštat će 100-150 str. Adresa usluge koja koristi, gleda na snimku zaslona u nastavku.

Suština grupiranja ključeva Ova metoda je kombinirati se u grupe tih fraza koje imaju na top 10 Yandex:
- uobičajeni URL-ovi jedno s drugim (tvrdim)
- s najčešćeg upita u grupi (meka).
Ovisno o broju takvih slučajnosti za različite web lokacije, pragovi za klasteriranje se razlikuju: 2, 3, 4 ... 10.
Prednost metode je grupiranje fraza prema potrebama ljudi, a ne samo na sinonimnim vezama. To vam omogućuje da odmah shvatite koje se ključne riječi mogu koristiti na jednoj stranici za ukrcaj.
Za informaciju će odgovarati:
- Meko sa pragom 3-4, a zatim čišćenje rukama;
- Teško na 3-KE, a zatim kombiniranjem klastera u značenju.
Internet trgovine i komercijalne stranice obično su napredovale tvrdom Y sa trostrukim pragom klasteriranja, pa ću ga podići u zasebnom članku.
Za naš projekt nakon grupisanja tvrdom metodom na 3. mjestu, ispostavilo se 317 grupa.

Konkurencija
Nema smisla napredovati kroz visoko konkurentne zahtjeve. Teško je ući u vrh, a bez njega neće biti prometa na članku. Da biste shvatili koje teme je povoljno za pisanje pomoću sljedeće metode:
Svi su se fokusira na točnu frekvenciju fraze grupi po kojoj je članak napisan i konkurencija na Mutagen. Za informativne stranice, preporučujem, preuzme temu za rad u kojoj je ukupna tačna frekvencija od 300 i veća, te konkurentni koeficijent od 1 do 12 inkluzivni.
U komercijalnim temama fokusirajte se na marginalnost robe ili usluga i kako konkurenti rade u prvom 10. Čak 5-10 metalnih upita mjesečno može biti razlog za izradu zasebne stranice pod njom.
Kako provjeriti Natjecati na zahtjev:
a) ručno, vođen odgovarajućom frazom u samoj službi ili kroz masovne zadatke;

b) U serijskom režimu kroz program kolektora KAY-a.

Izbor tema i grupiranja
Razmislite o svaku od rezultata grupa za naš projekt nakon grupiranja i odaberite temu za web mjesto.
Majdento Za razliku od ključnih asortija ne omogućava preuzimanje podataka o broju emisija za svaku frazu, pa ćete ih morati dodatno ukloniti putem kolektora Kay.
Uputstvo:
1) istovariti sve grupe iz MAJENTO-a u CSV formatu;
2) kvačilo fraze u Excelu na masku "Grupa: ključ";
3) učitajte rezultirajuće liste u ključnom sollectoru. U postavkama, mora biti ček oznaka u uvozniku "Grupa: tipka", a ne nadzirati prisustvo fraza u drugim grupama;

4) Uklanjamo osnovnu i tačnu frekvenciju za ključne riječi od novostvorenih grupa. (Ako koristite ključnu asortiju, nije potrebno učiniti. Program vam omogućava rad sa dodatnim stupovima)
5) Tražimo klastere sa jedinstvenom namjerom, sa najmanje 3 fraze i broj pogodaka na svim zahtjevima u iznosu od više od 300. Dalje, provjeravamo 3-4 najčešće njih na natjecanju Mutagen. Ako među tim frazama postoje ključevi s takmičenjem manjim od 12 - uzimaju u posao;
6) Mi gledamo ostale grupe. Ako se pronađu fraze u blizini značenja i vrijedi gledati unutar jedne stranice - kombiniramo se. Za grupe koje sadrže nova značenja, gledamo izglede za ukupnu frekvenciju fraza, ako je manja od 150 mjesečno, a zatim ga položite do trenutka kada prođete kroz cijelu jezgru. Može se pokazati da se kombinira s drugim klasterom i dobiva 300 preciznih emisija - ovo je minimum od kojih vrijedi uzeti članak za rad. Da biste ubrzali ručnu grupu, koristite pomoćni alat: brzi filter i frekvencijski rječnik. Oni će vam pomoći da brzo pronađete odgovarajuće fraze iz drugih klastera;

Pažnja !!! Kako shvatiti da se klasteri mogu kombinirati? Uzimamo 2 frekvencijske tipke od onih koji se pokupe u paragrafu 5 za slijetanje i 1 zahtjev iz nove grupe.
Dodajemo ih u Atton Alat "Istovar top 10", ukazuju na željenu regiju ako je potrebno. Nadalje, gledamo broj raskrižja u boji za treću frazu s ostalim. Kombinujemo grupe ako su od 3 ili više. Ako nema slučajnosti ili jedan, nemoguće je kombinirati - različite intenzite, u slučaju 2 raskrsnice, pogledajte izdavanje rukama i koristite logiku.
7) Nakon grupirajućih ključeva, dobivamo popis perspektivnih tema za članke i semantiku ispod njih.

Uklanjanje zahtjeva za drugi tip sadržaja
U pripremi semantičkog jezgra važno je razumjeti da za blogove i informativne stranice, komercijalni zahtjevi nisu potrebni. Baš kao što interneta ne trebaju informacije.
Prolazimo kroz svaku grupu i čistimo sve nepotrebno ako je nemoguće precizno odrediti namjeru upita - uspoređujući izdavanje ili upotrebu alata:
- Provjera komercijalizacije od piksela TULS-a (besplatno, ali sa dnevnim granicama čekova);
- servis Just-Magic, Klasteriranje s ček oznake Provjerite komercijalno upita (punjenje, trošak ovisi o tarifi)
Nakon toga idite na zadnji korak.
Optimizacija fraza
Optimiziramo semantički kernel tako da je prikladno raditi s tim u budućem SEO specijalistiku i kopiranju. Da bismo to učinili, ostavićemo ključne fraze u svakoj grupi koja uglavnom odražava potrebe ljudi i sadrže što više sinonimima u glavnim frazama.
Algoritam akcija:
- Poredajte ključne riječi u kolektoru Excel ili Kay abecedno iz A do Z;
- Odaberite one koji otkrivaju temu s različitih strana i različite riječi. Ostale stvari koje su jednake lijevo izraz s većom tačnom frekvencijom ili u kojoj je ključni 1 indikator (omjer osnovne frekvencije tačno);
- Uklanjamo ključnu riječ s brojem emisija mjesečno manje od 7, koji ne nose nova značenja i ne sadrže jedinstvene sinonime.
Primjer kako izgleda kompetentno sastavljeno semantički kernel -
Napomenuo sam da fraze nisu prikladne za intenzitet. Ako zanemarite moje preporuke o ručnom grupiranju, a ne provjerite kompatibilnost. Isključit će se da će stranica biti optimizirana za nekompatibilne ključne fraze i velike položaje na progresivnim zahtjevima više ne vidite.
Konačna lista za provjeru
- Mi odabiremo glavne visokofrekventne upite koje postavljaju subjekte;
- Tražimo sinonime za njih koristeći lijevu i desnu repumnu, web stranice takmičara i njihovih isječka;
- Proširite primljene zahtjeve za oporavak u Wordstat Lijevi stupac;
- Pripremamo listu zaustavljanja i primjenjuju se na rezultirajuće izraze;
- Parsim savjeti Yandex i Google;
- Uklonite osnovnu i preciznoj frekvenciji;
- Proširite listu minuti reči. Čistimo iz smeća i Rahes zahtjeva
- Mi pravimo klasterizaciju putem Majentona ili Keyassort-a. Za web lokacije u mekom režimu, prag 3-4. Za komercijalne internetske resurse koristeći tvrdu metodu s pragom 3.
- Uvozimo podatke u kay kolektoru i određuju konkurenciju 3-4 fraze za svaki klaster jedinstvenim intenzitetom;
- Odabralimo teme i određujemo sa stranama slijetanja na upite na temelju procjene ukupnog broja tačnih emisija u svim klasterima (od 300 za informaciju) i konkurenciju za najčešće njih na Mutagen (do 12) .
- Za svaku prikladnu stranicu tražimo druge klastere sa sličnim potrebama korisnika. Ako ih možemo razmotriti na jednoj stranici - kombiniramo se. Kada potreba nije jasna ili postoje sumnje da bi kao odgovor na njega trebao postojati druga vrsta sadržaja ili stranica - provjeriti izdavanjem ili kroz alate piksela tkuls ili samo-magiju. Za web stranice sadržaja treba se sastojati od kernela zahtevi za informacije, Komercijalni iz transakcije. Previše izbrišemo.
- Ključevi u svakoj grupi sortiramo po abecedno i ostavljamo ih onima koji opisuju temu sa različitih strana i različitih riječi. Ostale stvari su jednake prioritetu tih zahtjeva koji su manje od omjera osnovne frekvencije tačnog i većeg broja tačnih emisija mjesečno.
Što učiniti sa SEO-jezmom nakon njegovog stvaranja
Kao popis ključeva dali su ih autoru i napisao je potpuno odličan članak u potpunosti, otkrivajući sva značenja. Eh, nešto što sam zaglavio ... razborni tekst bit će moguć samo ako kopiraj jasno razumije da želite od njega i kako da se provjerite.
Analizirat ćemo 4 komponente, dobro radno, za koje ste zagarantovani da biste dobili puno ciljanog prometa na članku:
Dobra struktura. Analiziramo zahtjeve odabrane za stranicu slijetanja i otkrivaju šta trebaju ljudi u ovoj temi. Zatim napišite plan za član koji im u potpunosti odgovori. Zadatak je učiniti da ljudi odlaze na stranicu primili su volumetrijski i sveobuhvatan odgovor na semantiku koju ste izvršili. Dat će dobro ponašanje i visok relevantnost intenziteta. Nakon što ste sastavili plan, pogledajte web lokacije natjecatelja tako što ćete imati osnovni zahtjev za pretragu. Morate učiniti u takvom nizu. To je, prvo radimo sebe, onda gledamo druge i ako trebamo biti rafinirani.
Optimizacija pod ključevima. Sam članak ošiša se ispod 1-2 najfrekventnih tipki sa takmičenjem na Mutagenu do 12. Još 2-3 srednje frekvencijske fraze mogu se koristiti kao naslovi, ali u razblaženom obliku, umeštajući dodatnu ne-temu u njih , koristeći sinonime i reč. Glavni fokus koji obavljamo na niskofrekventnim frazama od kojih se izvlači jedinstveni dio - rep i ravnomjerno implementira u tekst. Sami pretraživači će naći i ljepilo.
Sinonimi za osnovne zahtjeve. Napisujemo ih odvojeno od našeg semantičkog kernela i stavljaju zadatak kopije da ih ravnomjerno koristi u tekstu. Ovo će pomoći u smanjenju gustoće naših glavnih riječi i tekst će biti dovoljno optimiziran da uđe u vrh.
Izreze za preciziranje u tkaninu.Sami, LSI ne promovira stranicu, ali njihovo prisustvo ukazuje da najvjerovatnije pisani tekst pripada stručnjaku Perua, a ovo je već plus kvalitetu sadržaja. Da biste pretražili tematske fraze, koristite alat za alat za kopiranje od piksela TULS-a.

Alternativna metoda odabira ključnih fraza pomoću usluga analize takmičara
Postoji brz pristup stvaranju semantičkog kernela, koji se primjenjuje i na pridošljene i iskusne korisnike. Suština metode je da u početku odaberemo ključeve koji nisu za cijelu web mjesto ili kategoriju, ali posebno prema članku, stranica za sjedenje.
Može se realizirati na dva načina koja se razlikuju na način koji odaberemo teme za stranicu i koliko duboko proširite ključne fraze:
- koristeći glavni ključni raščlanjivanje;
- na osnovu analize konkurenata.
Svaki od njih može se implementirati na jednostavan i složeniji nivo. Analiziraćemo sve opcije.
Bez upotrebe programa
Kopir ili webmaster često ne žele da se bave sučeljem velikog broja programa, ali su vam potrebne dobre teme i ključne fraze ispod njih.
Ova metoda je samo za početnike i one koji se ne žele gnjaviti. Sve akcije se vrše bez upotrebe dodatnog softvera, koristeći jednostavne i razumljive usluge.
Šta će potrajati:
- Ključevi.so Služba za analizu konkurenata - 1500 str. U promociji "Altblog" - 15% popusta;
- Mutagen. Provjerite za upita konkurenciju - 30 kopeksa, prikupljanje osnovne i precizne frekvencije - 2 Kopecks za 1 ček;
- Buvillers - besplatna verzija ili poslovni račun - 995 str. (sada sa popustom 695 p)
Opcija 1. Odaberite temu kroz glavnu frazu:
- Mi odabiremo glavne tipke iz objekta u širokom smislu koristeći brainstorming i lijevi i desni stup Yandex Wordstat;
- Nadalje, tražimo sinonime za njih, čiji su metode rekli rano;
- SVIM SVIMBILJSKIH zahtjeva markera postižemo bookvilku (treba platiti uplaćenu stopu) u naprednom režimu "Traži po popisu ključnih riječi";
- Navedimo u filteru: "! Precizno! Frekvencija" iz 50, broj riječi iz 3;
- Istovarite cijeli popis u Excelu;
- Izdvajamo sve ključne riječi i pošaljemo u grupi na uslugu "Klastier Fists". Ako je web mjesto regionalno odabrano potreban grad. Prag klasteriranja za informativne stranice odlaze na 2, za komercijalni 3-ku;
- Nakon grupisanja, odaberite teme za članke pregledavanjem nastalih klastera. Uzimamo one gdje je iznos izraza iz 3 i sa jedinstvenom namjerom. Bolje je razumjeti potrebe ljudi koji pomažu analizi URL-ova web lokacija od vrha u koloni "Konkurenti" (s desne strane na uslužnoj ploči Kulakov). Takođe ne zaboravljamo provjeriti takmičenje za Mutagen. Probijamo 2-3 zahtjeva od klastera. Ako više od 12, onda ne biste trebali preuzeti temu;
- Određena je ime buduće stranice za slijetanje, ostaje da odabere ključne fraze za nju;
- Sa polja "Natjecatelji" kopiraju 3 Ullas sa odgovarajućim vrstom stranica (ako je web lokacija informacija - uzimajte reference na članke, ako komercijalne, tada u trgovinama);
- Umetnite ih uzastopno u tipke. Pa i istovarite sve ključne fraze na njih;
- Kombinujemo ih u Excelu i uklanjamo duplikat;
- Usluga samo podataka nije dovoljna, pa je potrebno proširiti. Ponovo ćemo koristiti Buckolicl;
- Rezultirajuća lista šalje se klasteriranju u pesnici "Korisnik";
- Mi odabiremo grupe zahtjeva koje su pogodne za slijetanje, fokusirajući se na namjeru;
- Uklanjanje osnovne i precizne frekvencije kroz mutagen u režimu "Masovne zadatke";
- Pošaljite listu sa ažuriranim podacima po broju emisija u Excelu. Uklonite nulu za obje vrste frekvencija;
- Također u Excelu dodajte formulu za odnos osnovne frekvencije da biste tačni i ostavili samo one ključeve u kojima je manje od 100;
- Izbrišemo zahtjeve druge vrste sadržaja;
- Izrasima ostavljamo da najteže i različite riječi otkrivaju glavnu namjeru;
- Ponavljamo sve iste akcije na paragrafima 8-19 za ostalo.
Opcija 2. Odaberite temu kroz analizu konkurenata:
1. Tražimo gornja dijela u našem subjektu, vođenu RF zahtjevima i gledanje izdavanja putem alata Arsenkin "Top 10". Dovoljno je pronaći 1-2 odgovarajuće resurse.
Ako promoviramo stranicu u određenom gradu, ukazujemo u regionalnost;
2. Idite na ključeve.so servis i unesite URL adrese web lokacija koja su pronađena i pogledajte koje vrste takmičarskih stranica donose najviše prometa.
3. 3-5 najtačnijeh frekvencijskih zahtjeva od njih provjeri konkurentnost. Ako je iznad 12 u svim frazama, onda je bolje potražiti drugu temu manje konkurentne.
4. Ako trebate pronaći više web lokacija za analizu, otvorite karticu "Takmičari" i postavite parametre: slično 3, saradnju - 10. Mi zagovaramo podatke o smanjenju prometa.
5. Nakon što smo odabrali temu, vozite njegovo ime u izdavanje i kopirajte 3 Ullas sa vrha.
6. Zatim ponovite stavke 10-19 iz 1. opcije.
Pomoću kolektora Kei ili Word
Ova metoda će se razlikovati od prethodno korištenog za korištenje za neki kolektor ključa operacija i dublje ključno širenje.
Šta će potrajati:
- ključni kolekcionarski program - 1800 rubalja;
- sve iste usluge kao i prethodni način.
"Napredno - 1"
- Parsim lijevi i desni stupac Yandex-a tokom liste izraza;
- Uklonite tačnu i osnovnu frekvenciju putem kolektora KAY;
- Izračunati ključ 1;
- Izbrišemo nulte zahtjeve i s ključem 1\u003e 100;
- Dalje, radimo sve kao i izloži 18-19 od 1.
"Napredno - 2"
- Izrađujemo korake 1-5, kao u utjelovljenju 2;
- Prikupljamo na svakom ključevima za URL-u tipkama.
- Uklanjamo duplikat u kolektoru Kay;
- Ponavljamo paragrafe 1-4, kao u metodi "Advanced -1".
Sada uporedite broj dobivenih tipki i njihovu tačnu ukupnu frekvenciju prilikom prikupljanja s različitim metodama:
Kao što vidimo iz tablice, najbolji rezultat je pokazao alternativnu metodu za stvaranje jezgre ispod stranice - "Napredno 1.2". Bilo je moguće dobiti 34% više ciljnih ključeva i ukupni promet na klasteru iznosio je 51% više nego u slučaju klasične metode.
Ispod snimke zaslona, \u200b\u200bmože se vidjeti kako izgleda gotov jezgra, u svakom od slučajeva. Uzeo sam izraze s preciznim brojem depozita iz 7 mjesečno, tako da se može procijeniti kvaliteta ključne riječi. Za potpunu semantiku pogledajte tablicu na vezu "View".
Ali) 
B) 
U) 
Sada znate da najčešći način ne radi uvijek, jer svi rade, najvjernija i tačna, ali ne da odbiju druge metode. Mnogo ovisi o samoj temi. Za komercijalne lokalitete, gdje ključevi nisu toliko, sasvim dovoljno i klasična opcija. Na informativnim mjestima možete dobiti i odlične rezultate ako pravilno sastavite koprikon TK ispravno, napravite dobru strukturu i SEO optimizaciju. O svim tim ćemo detaljno govoriti u sljedećim člancima.
3 česte greške prilikom stvaranja semantičkog kernela
1. Prikupite fraze po vrhu. Nije dovoljno da se pribjegavate riječi za redakciju da biste dobili dobar rezultat!
Više od 70% zahtjeva koje se dovode rijetko ili razdoblja, oni ne stignu tamo. Ali među njima često postoje ključne fraze s dobrim konverzijom i stvarno niskom konkurencijom. Kako ih ne nedostajati? Obavezno prikupite pretraživanje upita i kombinirajte ih s podacima iz različitih izvora (, šaltera na web lokacijama, statističkim i bazama podataka).
2. Mešanje informacija i komercijalnih zahtjeva na jednoj stranici.Već smo rastavljali da se ključne fraze razlikuju u vrsti potreba. Ako posjetitelj dođe na vašu web lokaciju, koji želi kupovinu iznijeti, a kao odgovor na svoju stranicu zatraže u članku, kako mislite da će biti zadovoljan? Ne! Sustavi za pretraživanje razmišljaju i kada je stranica rangirana, što znači o vrhu u srednjim i RF frazama koje možete odmah zaboraviti. Stoga, ako sumnjate u definiciju vrste zahtjeva, pogledajte izdavanje ili koristite alate piksela TULS, samo-magistriranje za određivanje komercijalizma.
3. Izbor za promociju vrlo konkurentskih zahtjeva. Položaji za RF VK fraze su 60-70% ovise o faktorima ponašanja i da ih uđu u vrh. Što je više podnositelja zahtjeva, najduži red od onih koji žele i iznad zahtjeva za web lokacije. Sve, kao u životu ili sportu. Mnogo je teže postati svjetski prvak nego dobijanje naslova u vašem gradu.
Stoga je bolje unijeti mirnu, a ne pregrijanu nišu.
Prije toga, bilo je još komplikovanije biti na vrhu. U vrhu je stajao na principu koji je upravljao, jeo. Vođe su pali na prva mesta i mogli su ih samo pomerati, akumulišući faktori bihevioralnog ponašanja. I kako da ih nabavite ako ste na drugoj ili trećoj stranici ... Yandex je umanjio ovaj zatvoreni krug u ljeto 2015. godine, uvođenjem višestrukih algoritma gangstera. Suština toga je samo onaj nasumično povećanje i spuštanje stavova web lokacija da bi razumjeli da li se pojavilo više vrijednih kandidata na vrhu.
Koliko je novca potrebno za početak?
Da biste odgovorili na ovo pitanje, razmatramo troškove potrebnog arsenala programa i usluga za pripremu i nepoznavanje ključnih fraza na 100 članaka.
Minimum (pogodan za klasičnu opciju):
1. Slobel - besplatno
2. MAJENTO CLASTERSER - besplatno
3. Prepoznati CAPTCH - 30 rubalja.
4. XML granice - 70 rubalja.
5. Provjerite za konkurenciju zahtjeva Mutagen - 10 čekova dnevno besplatno
6. Ako se ne tretirate nigdje i spremni ste provesti na raščlanjivanju 20-30 sati, možete bez proxyja.
—————————
Rezultat je 100 rubalja. Ako sami unesete CAPTCHA, a XML ograničenja dobijaju u zamjenu za prenošenje sa vaše web lokacije, a zatim stvarno pripremite kernel uopšte. Potrebno je samo provesti dan još jedan na uspostavljanju i savladavanju programa i još 3-4 dana za očekivati \u200b\u200brezultate raščlanjivanja.
Standardni semantistički set (za naprednu i klasičnu metodu):
1. Kolekcionar Kay - 1900 rubalja
2. KAY ASSORT - 1700 rubalja
3. Bookwarix (poslovni račun) - 650 rubalja.
4. Ključevi.so Služba za analizu takmičara - 1500 rubalja.
5. 5 Proxy - 350 rubalja mesečno
6. Antikapiča - otprilike 30 rubalja.
7. XML granice - oko 80 rubalja.
8. Provjera konkurencije Mutagen (1 ček \u003d 30 Kopecks) - napravite 200 rubalja.
———————-
Rezultat je 6410 rubalja. Naravno, moguće je učiniti bez keyasort-a, zamijenići ga sa Mjestonskim klasteražom i umjesto kolektorom Kay da koristi riječ. Tada dovoljno i 2810 rubalja.
Trebam li vjerovati razvoju "Profi" kernela ili bolje da to shvatim i učinim sami?
Ako se osoba redovno bavi svojim omiljenim stvarima, ispumpavajući u njemu, a zatim slijedeći logiku, njegovi rezultati trebaju biti potpuno bolji od novorođenčeta u ovom području. Ali s izborom ključa, sve se ispada upravo suprotno.
Zašto u 90% slučajeva novajlija čini bolji profesionalac?
Sve je u pitanju. Zadatak semantika ne sakuplja najbolji kernel za vas, već da ispunimo svoj rad na minimalno vrijeme i da je njegov kvalitet dogovorio za vas.
Ako sve radite sami za te algoritme o kojima su rekli rano - rezultat će biti reda veličine veća iz dva razloga:
- Razumijete temu. Dakle, znate potrebe svojih kupaca ili korisnika web lokacije i možete u početnoj fazi proširiti zahtjeve markera za raščlanjivanje, koristeći veliki broj sinonimi i specifičnih riječi.
- Zainteresovani da sve bude kvalitativno. Vlasnik poslovanja ili zaposleni u kompaniji u kojoj funkcionira, naravno, to je odgovorno pitanje i pokušavat će učiniti sve do maksimuma. Što više kompletira kernel i više konkurentskih zahtjeva u njemu, to će više biti moguće sastaviti ciljni promet, a samim tim i profit s istim ulaganjima u sadržaj bit će veći.
Kako pronaći preostalih 10% koji je kernel bolji od vas?
Potražite kompanije u kojima je odabir ključnih fraza ključna kompetencija. I odmah razgovarajte o tome koji rezultat želite, kao i svi drugi ili maksimum. U drugom slučaju, to će biti 2-3 puta skuplje, ali dugoročno se više puta isplati. Za one koji žele naručiti uslugu sa mnom, svim potrebnim informacijama i uvjetima. Garancija kvaliteta!
Zašto je tako važno u potpunosti izvesti semantiku
Ovdje, kao u bilo kojoj sferi, princip "dobrih i loših selekcija" djeluje. Koja je njegova suština?
Svakog dana smo suočeni sa činjenicom da odaberemo:
- značenje sa osobom koja izgleda da nije ništa, ali se ne drži ili razočara sama po sebi da izgradi skladne odnose sa onima koji su potrebne;
- posao koji ne voli ili ne nalazi posao, onda ono što duša laže i to radi sa vašom profesijom;
- iznajmite sobu za trgovinu na ne-kontrolnom punktu ili još uvijek pričekajte dok ne budete slobodni, odgovarajuća opcija;
- uzmi tim ne najbolji menadžer Prodaja i onaj koji se u današnjem intervjuu pokazao bolje.
Čini se da je sve jasno. A ako ga pogledate s druge strane, predstavljajući svaki izbor kao ulaganje u budućnost. Ovdje započinje najzanimljivije!
Spremljeno na ovo. Kernel, 3-5 hiljada. Zadovoljni poput slonova! Ali ono što vodi:
a) Za informativne stranice:
- Gubici na saobraćaju najmanje 1,5 puta s istim ulaganjima u sadržaj. U poređenju ostale metode Dobivanje ključnih fraza, već smo saznali iskusni način da alternativna metoda omogućuje prikupljanje 51% više;
- Projekt brzo šalje izručenje. Takmičari su lako zaobići oko nas, dajući potpuni odgovor na intenzitet.
b) za komercijalne projekte:
- Manje vodi ili povećava troškove. Ako imamo semantiku, kao i svi drugi, krećemo se na isti zahtjevi kao natjecatelji. Veliki broj Prijedlozi sa stalnom potražnjom smanjuju udio svakog od njih na tržištu;
- Niska konverzija. Specifični zahtjevi Bolje pretvoreno u prodaju. Uštedite do sedam. kernel, gubimo najviše ključeve za konverziju;
- Teži za napredovanje. Mnogi žele da budu u vrhu - iznad zahtjeva za svakog od kandidata.
Volio bih da uvijek radiš dobar izbor I ulagati samo u plus!
P.S. Bonus "Kako napisati dobar članak sa lošom semantikom", kao i drugi život i zaradu za život i zaradu na Internetu, čitanje u mojoj grupi





























 u Photoshopu kako napraviti rešetku u Photoshopu CS6")



