Jak vyhledávat pomocí google.com
Každý asi umí používat vyhledávač jako je Google =) Ne každý ale ví, že pokud správně poskládáte vyhledávací dotaz pomocí speciálních struktur, můžete mnohem efektivněji a rychleji dosáhnout výsledků toho, co hledáte =) V tomto článku Pokusím se to ukázat a jak to musíte udělat, abyste správně hledali
Google podporuje několik operátorů pokročilého vyhledávání, které mají zvláštní význam při vyhledávání na google.com. Tito operátoři obvykle upravují vyhledávání nebo dokonce Googlu říkají, aby prováděl úplně jiné typy vyhledávání. Například konstrukce odkaz: je speciální operátor a dotaz odkaz: www.google.com vám neumožní normální vyhledávání, ale místo toho najde všechny webové stránky, které mají odkazy na google.com.
alternativní typy požadavků
mezipaměti: Pokud do dotazu zahrnete další slova, Google tato zahrnutá slova v dokumentu uloženém v mezipaměti zvýrazní.
Například, cache: www.webové stránky zobrazí obsah uložený v mezipaměti se zvýrazněným slovem „web“.
odkaz: výše uvedený vyhledávací dotaz zobrazí webové stránky, které obsahují odkazy na zadaný dotaz.
Například: odkaz: www.webové stránky zobrazí všechny stránky, které mají odkaz na http://www.site
příbuzný: Zobrazuje webové stránky, které „souvisejí“ se zadanou webovou stránkou.
Například, související: www.google.com zobrazí seznam webových stránek, které jsou podobné domovské stránce Google.
info: Vyžádat informace: poskytne některé informace, které má Google o požadované webové stránce.
Například, info: webové stránky zobrazí informace o našem fóru =) (Armada - Fórum dospělých webmasterů).
Další žádosti o informace
definovat: Dotaz define: poskytne definici slov, která zadáte poté, sestavenou z různých online zdrojů. Definice bude pro celou zadanou frázi (to znamená, že bude zahrnovat všechna slova v přesném dotazu).
zásoby: Začnete-li dotaz s akciemi: Google bude se zbytkem dotazu zacházet jako se symboly burzy a odkáže na stránku s připravenými informacemi pro tyto symboly.
Například, akcie: intel yahoo zobrazí informace o Intel a Yahoo. (Všimněte si, že musíte vytisknout znaky pro nejnovější zprávy, nikoli název společnosti)
Modifikátory požadavků
místo: Pokud do dotazu zahrnete site:, Google omezí výsledky na weby, které najde v dané doméně.
Můžete také hledat jednotlivé zóny, jako je ru, org, com atd ( site:com site:ru)
allintitle: Pokud spustíte dotaz s allintitle:, Google omezí výsledky na všechna slova dotazu v názvu.
Například, allintitle: vyhledávání google vrátí všechny stránky vyhledávání Google, jako jsou obrázky, blog atd
titul: Pokud ve svém dotazu zahrnete intitle:, Google omezí výsledky na dokumenty obsahující toto slovo v názvu.
Například, název:Obchod
allinurl: Pokud spustíte dotaz s allinurl: Google omezí výsledky na všechna slova dotazu v URL.
Například, allinurl: vyhledávání google vrátí dokumenty pomocí google a vyhledá v názvu. Také můžete volitelně oddělit slova lomítkem (/), poté budou slova na obou stranách lomítka prohledána na stejné stránce: Příklad allinurl: foo/bar
inurl: Pokud ve svém dotazu zahrnete inurl:, omezí Google výsledky na dokumenty obsahující toto slovo v adrese URL.
Například, Animace inurl:web
intext: hledá zadané slovo pouze v textu stránky, ignoruje nadpis a texty odkazů a další věci nesouvisející s. Existuje také odvozenina tohoto modifikátoru - allintext: ty. dále budou všechna slova v dotazu vyhledána pouze v textu, což je také důležité, ignoruje se často používaná slova v odkazech
Například, intext: fórum
časové období: hledá v časových rámcích (daterange:2452389-2452389), data pro čas jsou specifikována v juliánském formátu.
No a všemožné zajímavé příklady žádostí
Příklady sestavování dotazů pro Google. Pro spammery
inurl:control.guest?a=sign
Site:books.dreambook.com „Adresa URL domovské stránky“ „Podepsat“ inurl:sign
Web: www.freegb.net Domovská stránka
Inurl:sign.asp "Počet postav"
"Zpráva:" inurl:sign.cfm "Odesilatel:"
inurl:register.php “Registrace uživatele” “Webové stránky”
Inurl:edu/guestbook „Zapište se do knihy návštěv“
Inurl:post "Přidat komentář" "URL"
Inurl:/archives/ “Komentáře:” “Pamatujete si informace?”
“Skript a návštěvní kniha vytvořil:” “URL:” “Komentáře:”
inurl:?action=add “phpBook” “URL”
Intitle:"Odeslat nový příběh"
Časopisy
inurl:www.livejournal.com/users/mode=reply
inurl největší žurnál.com/mode=reply
Inurl:fastbb.ru/re.pl?
inurl:fastbb.ru /re.pl? "Kniha hostů"
blogy
Inurl:blogger.com/comment.g?"postID""anonymní"
Inurl:typepad.com/ “Přidejte komentář” “Pamatujete si osobní údaje?”
Inurl:greatestjournal.com/community/ “Přidat komentář” “adresy anonymních plakátů”
"Přidat komentář" "adresy anonymních plakátů" -
Intitle: "Přidat komentář"
Inurl:pirillo.com “Přidat komentář”
Fóra
Inurl:gate.html?”name=Forums” “mode=reply”
inurl:”forum/posting.php?mode=reply”
inurl:"mes.php?"
inurl:”members.html”
inurl:forum/memberlist.php?"
Přijímání soukromých dat nemusí vždy znamenat hackování – někdy jsou zveřejněna ve veřejné doméně. Znalost nastavení Google a trocha vynalézavosti vám umožní najít spoustu zajímavých věcí – od čísel kreditních karet až po dokumenty FBI.
VAROVÁNÍ
Veškeré informace jsou poskytovány pouze pro informační účely. Redakce ani autor nenesou odpovědnost za případné škody způsobené materiály tohoto článku.Všechno je dnes připojeno k internetu, málo se starají o omezení přístupu. Mnoho soukromých dat se proto stává kořistí vyhledávačů. Spider roboti se již neomezují pouze na webové stránky, ale indexují veškerý obsah dostupný na webu a neustále přidávají důvěrné informace do svých databází. Naučit se tato tajemství je snadné – stačí vědět, jak se na ně zeptat.
Hledání souborů
Ve schopných rukou Google rychle najde vše, co je na webu špatné, jako jsou osobní údaje a soubory pro oficiální použití. Často jsou schované jako klíč pod kobercem: neexistují žádná skutečná omezení přístupu, data jen leží v zadní části webu, kam nevedou odkazy. Standardní webové rozhraní Google poskytuje pouze základní pokročilá nastavení vyhledávání, ale i ty budou stačit.
Existují dva operátory, které můžete použít k omezení vyhledávání Google na soubory určitého typu: filetype a ext . První nastavuje formát, který vyhledávač určí podle záhlaví souboru, druhý - příponu souboru, bez ohledu na jeho vnitřní obsah. Při vyhledávání v obou případech je třeba zadat pouze příponu. Zpočátku bylo vhodné použít operátor ext v případech, kdy pro soubor nebyly žádné specifické formátové charakteristiky (například pro hledání konfiguračních souborů ini a cfg, uvnitř kterých může být cokoli). Nyní se algoritmy Google změnily a mezi operátory není žádný viditelný rozdíl – výsledky jsou ve většině případů stejné.

Filtrování výstupu
Ve výchozím nastavení Google vyhledává ve všech souborech na indexovaných stránkách slova a obecně jakékoli zadané znaky. Rozsah vyhledávání můžete omezit doménou nejvyšší úrovně, konkrétním webem nebo umístěním požadované sekvence v samotných souborech. Pro první dvě možnosti se používá výpis webu, za kterým následuje název domény nebo vybraného webu. Ve třetím případě vám celá sada operátorů umožňuje vyhledávat informace v polích služeb a metadatech. Například allinurl najde specifikované v těle samotných odkazů, allinanchor - v textu poskytnutém značkou , allintitle - v záhlaví stránek, allintext - v těle stránek.
Pro každého operátora existuje odlehčená verze s kratším názvem (bez předpony all). Rozdíl je v tom, že allinurl najde odkazy se všemi slovy, zatímco inurl najde pouze odkazy s prvním z nich. Druhé a následující slova z dotazu se mohou objevit kdekoli na webových stránkách. Operátor inurl se také liší od jiného podobného operátoru ve významu - site. První z nich také umožňuje najít libovolnou sekvenci znaků v odkazu na požadovaný dokument (například /cgi-bin/), což je široce používáno pro hledání komponent se známými zranitelnostmi.
Pojďme si to vyzkoušet v praxi. Vezmeme allintextový filtr a přimějeme, aby dotaz vrátil seznam čísel kreditních karet a ověřovacích kódů, jejichž platnost vyprší až po dvou letech (nebo když jejich majitele omrzí krmit všechny v řadě).
Allintext: číslo karty datum vypršení platnosti /2017 cvv 
Když si ve zprávách přečtete, že se mladý hacker „naboural do serverů“ Pentagonu nebo NASA a ukradl utajované informace, pak jde ve většině případů právě o tuto elementární techniku používání Google. Předpokládejme, že nás zajímá seznam zaměstnanců NASA a jejich kontaktní údaje. Určitě takový seznam je v elektronické podobě. Pro pohodlí nebo z důvodu nedopatření může ležet i na samotném webu organizace. Je logické, že v tomto případě na něj nebudou žádné odkazy, protože je určen pro interní použití. Jaká slova mohou být v takovém souboru? Alespoň - pole "adresa". Je snadné otestovat všechny tyto předpoklady.

inurl:nasa.gov filetype:xlsx "adresa"

Používáme byrokracii
Takové nálezy jsou příjemnou maličkostí. Opravdu solidní úlovek pochází z podrobnější znalosti Google Webmaster Operators, samotného webu a struktury toho, co hledáte. Když znáte podrobnosti, můžete snadno filtrovat výstup a upřesňovat vlastnosti souborů, které potřebujete, abyste ve zbytku získali opravdu cenná data. Je legrační, že byrokracie zde přichází na pomoc. Vytváří typické formulace, které usnadňují vyhledávání tajných informací, které náhodně unikly na web.
Například prohlášení o distribuci, které je povinné v kanceláři ministerstva obrany USA, znamená standardizovaná omezení distribuce dokumentu. Písmeno A označuje veřejná vydání, ve kterých není nic tajného; B - určeno pouze pro interní použití, C - přísně důvěrné atd. až po F. Samostatně je zde písmeno X, které označuje zvláště cenné informace, které představují státní tajemství nejvyšší úrovně. Takové dokumenty nechť vyhledávají ti, kteří to mají dělat ve službě, a my se omezíme na soubory s písmenem C. Podle DoDI 5230.24 je toto označení přiděleno dokumentům obsahujícím popis kritických technologií, které spadají pod exportní kontrolu. Takto pečlivě střežené informace můžete najít na stránkách v doméně nejvyšší úrovně .mil přidělené americké armádě.
"PROHLÁŠENÍ O DISTRIBUCI C" inurl:navy.mil 
Je velmi výhodné, že v doméně .mil jsou shromažďovány pouze stránky Ministerstva obrany USA a jeho smluvních organizací. Výsledky vyhledávání omezené na doménu jsou výjimečně čisté a názvy mluví samy za sebe. Je prakticky zbytečné pátrat po ruských tajemstvích tímto způsobem: v doménách .ru a .rf vládne chaos a názvy mnoha zbraňových systémů znějí botanické (PP „Kiparis“, samohybná děla „Acacia“) či dokonce báječný (TOS "Pinocchio").

Pečlivým prozkoumáním jakéhokoli dokumentu z webu v doméně .mil můžete zobrazit další značky pro upřesnění vyhledávání. Například odkaz na exportní omezení „Sec 2751“, což je také pohodlné pro vyhledávání zajímavých technických informací. Čas od času je odstraněn z oficiálních stránek, kde se kdysi objevil, takže pokud nemůžete sledovat zajímavý odkaz ve výsledcích vyhledávání, použijte mezipaměť Google (operátor mezipaměti) nebo webovou stránku Internet Archive.
Stoupáme do mraků
Kromě náhodně odtajněných dokumentů z vládních ministerstev občas v mezipaměti Google vyskakují odkazy na osobní soubory z Dropboxu a dalších služeb pro ukládání dat, které vytvářejí „soukromé“ odkazy na veřejně publikovaná data. S alternativními a vlastnoručně vyrobenými službami je to ještě horší. Například následující dotaz najde data všech klientů Verizon, kteří mají nainstalovaný server FTP a aktivně používají směrovač na svém směrovači.
Allinurl:ftp://verizon.net
Takových chytrých lidí je nyní více než čtyřicet tisíc a na jaře 2015 jich bylo řádově více. Místo Verizon.net můžete nahradit jméno jakéhokoli známého poskytovatele a čím slavnější je, tím větší může být úlovek. Prostřednictvím vestavěného FTP serveru můžete vidět soubory na externím disku připojeném k routeru. Obvykle se jedná o NAS pro vzdálenou práci, osobní cloud nebo nějaký druh stahování souborů typu peer-to-peer. Veškerý obsah takových médií je indexován Googlem a dalšími vyhledávači, takže k souborům uloženým na externích discích se dostanete přes přímý odkaz.

Nahlížející konfigurace
Před velkoobchodní migrací do cloudu vládly jako vzdálená úložiště jednoduché FTP servery, které rovněž postrádaly zranitelnost. Mnohé z nich jsou aktuální i dnes. Například oblíbený program WS_FTP Professional ukládá konfigurační data, uživatelské účty a hesla do souboru ws_ftp.ini. Je snadné jej najít a přečíst, protože všechny položky jsou uloženy v prostém textu a hesla jsou šifrována pomocí algoritmu Triple DES s minimálním zmatkem. Ve většině verzí stačí zahodit první bajt.

Dešifrování takových hesel je snadné pomocí nástroje WS_FTP Password Decryptor nebo bezplatné webové služby.

Když mluvíme o hacknutí libovolného webu, obvykle to znamená získání hesla z protokolů a záloh konfiguračních souborů CMS nebo e-commerce aplikací. Pokud znáte jejich typickou strukturu, můžete klíčová slova snadno označit. Řádky jako ty nalezené v ws_ftp.ini jsou extrémně běžné. Například Drupal a PrestaShop mají vždy uživatelské ID (UID) a odpovídající heslo (pwd) a všechny informace jsou uloženy v souborech s příponou .inc. Můžete je hledat takto:
"pwd=" "UID=" ext:inc
Odhalujeme hesla z DBMS
V konfiguračních souborech SQL serverů jsou uživatelská jména a e-mailové adresy uloženy jako prostý text a místo hesel jsou zaznamenány jejich MD5 hash. Jejich dešifrování, přísně vzato, je nemožné, ale můžete najít shodu mezi známými páry hash-heslo.

Až dosud existují DBMS, které ani nepoužívají hash hesel. Konfigurační soubory kteréhokoli z nich lze jednoduše zobrazit v prohlížeči.
Intext:DB_PASSWORD filetype:env 
S příchodem Windows serverů místo konfiguračních souborů částečně zabral registr. V jeho větvích můžete prohledávat úplně stejným způsobem s použitím reg jako typu souboru. Například takto:
Filetype:reg HKEY_CURRENT_USER "Heslo"= 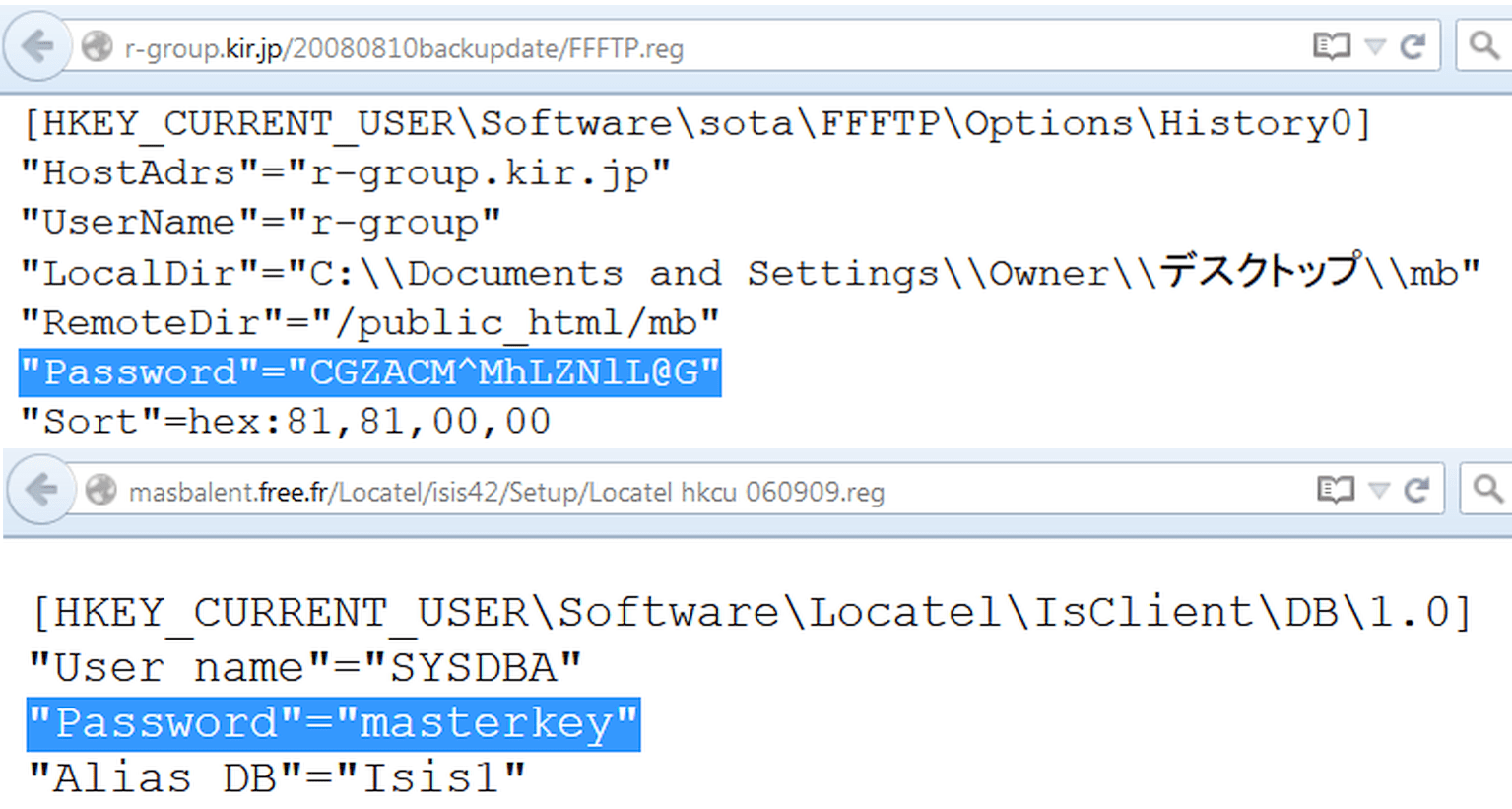
Nezapomeňte na Obvious
Někdy je možné se k utajovaným informacím dostat pomocí dat náhodně otevřených a zachycených Googlem. Ideální možností je najít seznam hesel v nějakém běžném formátu. Ukládat informace o účtu do textového souboru, wordovského dokumentu nebo excelové tabulky mohou jen zoufalci, ale těch je vždy dost.
Filetype:xls inurl:password 
Na jedné straně existuje mnoho prostředků, jak takovým incidentům předejít. Je nutné specifikovat adekvátní přístupová práva v htaccess, záplatovat CMS, nepoužívat levé skripty a uzavírat ostatní díry. Existuje také soubor se seznamem vyloučení robots.txt, který vyhledávačům zakazuje indexovat soubory a adresáře v něm uvedené. Na druhou stranu, pokud se struktura robots.txt na některém serveru liší od standardní, pak je okamžitě jasné, co se na něm snaží skrýt.

Seznamu adresářů a souborů na libovolném webu předchází standardní index indexu. Protože se musí objevit v názvu pro servisní účely, má smysl omezit jeho vyhledávání na operátora intitle. Zajímavé věci lze nalézt v adresářích /admin/, /personal/, /etc/ a dokonce i /secret/.

Sledujte aktualizace
Relevance je zde nesmírně důležitá: staré zranitelnosti se uzavírají velmi pomalu, ale Google a jeho výsledky vyhledávání se neustále mění. Je dokonce rozdíl mezi filtrem „poslední vteřiny“ (&tbs=qdr:s na konci adresy URL požadavku) a filtrem „v reálném čase“ (&tbs=qdr:1).
Implicitně je také uveden časový interval poslední aktualizace souboru od společnosti Google. Prostřednictvím grafického webového rozhraní můžete vybrat jedno z typických období (hodinu, den, týden atd.) nebo nastavit časové období, ale tento způsob není vhodný pro automatizaci.
Podle vzhledu adresního řádku lze pouze hádat o způsobu, jak omezit výstup výsledků pomocí konstrukce &tbs=qdr:. Písmeno y za ním určuje limit jednoho roku (&tbs=qdr:y), m ukazuje výsledky za poslední měsíc, w za týden, d za poslední den, h za poslední hodinu, n za minutu, a s pro dej mi sekundu. Nejnovější výsledky, které Google právě oznámil, lze nalézt pomocí filtru &tbs=qdr:1.
Pokud potřebujete napsat ošemetný skript, bude užitečné vědět, že časové období se v Googlu nastavuje v juliánském formátu přes operátor daterange. Takto můžete například najít seznam dokumentů PDF se slovem důvěrné nahraných mezi 1. lednem a 1. červencem 2015.
Důvěrný typ souboru: pdf rozsah dat: 2457024-2457205
Rozsah je uveden v juliánském formátu data bez desetinných míst. Překládat je ručně z gregoriánského kalendáře je nepohodlné. Je jednodušší použít převodník data.
Opět cílení a filtrování
Kromě zadání dalších operátorů ve vyhledávacím dotazu je lze odeslat přímo v těle odkazu. Například vlastnost filetype:pdf odpovídá konstruktu as_filetype=pdf. Je tedy vhodné nastavit jakákoli upřesnění. Řekněme, že výstup výsledků pouze z Honduraské republiky se nastaví přidáním konstrukce cr=countryHN do URL vyhledávání, ale pouze z města Bobruisk - gcs=Bobruisk . Úplný seznam naleznete v sekci pro vývojáře.
Automatizační nástroje Google jsou navrženy tak, aby usnadňovaly život, ale často ještě více komplikují práci. Například město uživatele je určeno IP adresou uživatele prostřednictvím WHOIS. Na základě těchto informací Google nejen vyrovnává zatížení mezi servery, ale také mění výsledky vyhledávání. V závislosti na regionu se pro stejný dotaz dostanou na první stránku různé výsledky a některé z nich se mohou ukázat jako zcela skryté. Cítit se jako kosmopolita a vyhledávat informace z jakékoli země pomůže jeho dvoupísmenný kód za direktivou gl=country . Například kód pro Nizozemsko je NL, zatímco Vatikán a Severní Korea svůj vlastní kód v Googlu nemají.
Výsledky vyhledávání jsou často plné i po použití několika pokročilých filtrů. V tomto případě je snadné dotaz upřesnit přidáním několika výjimečných slov (každému z nich předchází znaménko mínus). Například bankovnictví , jména a výukový program se často používají se slovem Osobní. V čistších výsledcích vyhledávání se tedy nezobrazí učebnicový příklad dotazu, ale upřesněný:
Intitle:"Index /Osobní/" -jména -náuka -bankovnictví
Poslední příklad
Sofistikovaný hacker se vyznačuje tím, že si vše potřebné zajišťuje sám. Například VPN je pohodlná věc, ale buď drahá, nebo dočasná a s omezeními. Zaregistrovat se sám pro sebe je příliš drahé. Je dobře, že existují skupinové odběry a s pomocí Google je snadné se stát součástí skupiny. K tomu stačí najít konfigurační soubor Cisco VPN, který má poněkud nestandardní příponu PCF a rozpoznatelnou cestu: Program Files\Cisco Systems\VPN Client\Profiles . Jedna žádost a připojíte se například k přátelskému personálu univerzity v Bonnu.
Typ souboru: pcf vpn NEBO Skupina 
INFO
Google najde konfigurační soubory s hesly, ale mnoho z nich je zašifrováno nebo nahrazeno hashe. Pokud vidíte řetězce pevné délky, okamžitě vyhledejte službu dešifrování.Hesla jsou uložena v zašifrované podobě, ale Maurice Massard již napsal program na jejich dešifrování a poskytuje jej zdarma prostřednictvím thecampusgeeks.com.
S pomocí Google se provádějí stovky různých typů útoků a penetračních testů. Existuje mnoho možností, které ovlivňují oblíbené programy, hlavní databázové formáty, četné zranitelnosti PHP, cloudy a tak dále. Pokud přesně víte, co hledáte, mnohem snáze získáte informace, které potřebujete (zejména informace, které jste nechtěli zveřejnit). Nejen Shodan krmí zajímavé nápady, ale jakákoli databáze indexovaných síťových zdrojů!
Hackování s Googlem
Alexandr Antipov
Vyhledávač Google (www.google.com) nabízí mnoho možností vyhledávání. Všechny tyto funkce jsou neocenitelným vyhledávacím nástrojem pro začínajícího uživatele internetu a zároveň ještě mocnější zbraní invaze a ničení v rukou lidí se zlými úmysly, mezi které patří nejen hackeři, ale i nepočítačové zločince. a dokonce i teroristé.
(9475 zobrazení za 1 týden)
Denis Batrankov
denisNOSPAMixi.ru
Pozornost:Tento článek není návodem k akci. Tento článek je napsán pro vás, správce WEB serveru, abyste ztratili falešný pocit, že jste v bezpečí, a konečně pochopili záludnost tohoto způsobu získávání informací a pustili se do ochrany vašeho webu.
Úvod
Například jsem našel 1670 stránek za 0,14 sekundy!
2. Zadáme další řádek, například:
inurl:"auth_user_file.txt"o něco méně, ale to už stačí pro bezplatné stažení a pro hádání hesel (pomocí stejného John The Ripper). Níže uvedu několik dalších příkladů.
Musíte si tedy uvědomit, že vyhledávač Google navštívil většinu internetových stránek a uložil informace na nich obsažené do mezipaměti. Tyto informace uložené v mezipaměti vám umožňují získat informace o webu a obsahu webu bez přímého spojení s webem, stačí se ponořit do informací, které jsou interně uloženy společností Google. Kromě toho, pokud informace na webu již nejsou dostupné, mohou být informace v mezipaměti stále zachovány. Vše, co tato metoda vyžaduje, je znát některá klíčová slova Google. Tato technika se nazývá Google Hacking.
Poprvé se informace o Google Hacking objevily na mailing listu Bugtruck před 3 lety. V roce 2001 toto téma nastolil francouzský student. Zde je odkaz na tento dopis http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html. Uvádí první příklady takových žádostí:
1) Index /admin
2) Index /hesla
3) Index /mail
4) Index / +banques +filetype:xls (pro Francii...)
5) Index / +passwd
6) Index souboru/password.txt
Toto téma vyvolalo velký hluk v anglické části internetu poměrně nedávno: po článku Johnnyho Longa zveřejněném 7. května 2004. Pro úplnější studium Google Hacking vám doporučuji přejít na stránky tohoto autora http://johnny.ihackstuff.com. V tomto článku vás chci jen informovat.
Kdo to může použít:
- Novináři, špióni a všichni lidé, kteří rádi strkají nos do cizích věcí, toho mohou využít k hledání kompromitujících důkazů.
- Hackeři hledající vhodné cíle pro hackování.
Jak Google funguje.
Chcete-li pokračovat v konverzaci, dovolte mi připomenout některá klíčová slova používaná v dotazech Google.
Hledejte pomocí znaménka +
Google podle něj nedůležitá slova z vyhledávání vyloučí. Například tázací slova, předložky a členy v angličtině: například are, of, where. Zdá se, že v ruštině Google považuje všechna slova za důležitá. Pokud je slovo z vyhledávání vyloučeno, pak o něm Google píše. Aby Google mohl začít vyhledávat stránky s těmito slovy, musíte před ně přidat znaménko + bez mezery před slovo. Například:
eso + základny
Hledat podle znamení -
Pokud Google najde velké množství stránek, ze kterých je nutné vyloučit stránky s určitými tématy, můžete Google donutit hledat pouze stránky, které neobsahují určitá slova. Chcete-li to provést, musíte tato slova označit tak, že před každé dáte znak - bez mezery před slovem. Například:
rybaření - vodka
Hledejte pomocí znaku ~
Možná budete chtít vyhledat nejen zadané slovo, ale také jeho synonyma. Chcete-li to provést, uveďte před slovo symbol ~.
Nalezení přesné fráze pomocí dvojitých uvozovek
Google na každé stránce vyhledává všechny výskyty slov, která jste zapsali do řetězce dotazu, a nezáleží mu na relativní pozici slov, hlavní je, že všechna zadaná slova jsou na stránce ve stejnou dobu ( toto je výchozí akce). Chcete-li najít přesnou frázi, musíte ji dát do uvozovek. Například:
"knižní zarážka"
Chcete-li mít alespoň jedno ze zadaných slov, musíte explicitně zadat logickou operaci: NEBO. Například:
bezpečnost knihy NEBO ochrana
Kromě toho můžete použít znak * ve vyhledávacím řetězci k označení libovolného slova a. reprezentovat jakoukoli postavu.
Hledání slov pomocí dalších operátorů
Existují vyhledávací operátory, které jsou uvedeny ve vyhledávacím řetězci ve formátu:
operátor:hledaný_term
Mezery vedle dvojtečky nejsou potřeba. Pokud za dvojtečku vložíte mezeru, zobrazí se chybová zpráva a před ní je Google použije jako běžný vyhledávací řetězec.
Existují skupiny dalších operátorů vyhledávání: jazyky - uveďte, v jakém jazyce chcete vidět výsledek, datum - omezte výsledky za poslední tři, šest nebo 12 měsíců, výskyty - uveďte, kde v dokumentu je třeba hledat řetězec: všude, v nadpisu, v URL, domény - prohledejte zadaný web nebo naopak vyřaďte jej z vyhledávání, bezpečné vyhledávání - zablokujte weby obsahující zadaný typ informací a odstraňte je ze stránek s výsledky vyhledávání.
Některé operátory však nepotřebují další parametr, například dotaz " cache: www.google.com" lze volat jako úplný vyhledávací řetězec a některá klíčová slova naopak vyžadují hledané slovo, například " site:www.google.com nápověda". Ve světle našeho tématu se podívejme na následující operátory:
Operátor |
Popis |
Vyžaduje další parametr? |
hledat pouze stránky uvedené v hledaném výrazu |
||
hledat pouze v dokumentech typu search_term |
||
najít stránky obsahující hledaný výraz v názvu |
||
najít stránky obsahující všechna slova search_term v názvu |
||
najít stránky obsahující ve své adrese slovo search_term |
||
najít stránky obsahující všechna slova search_term v jejich adrese |
Operátor místo: omezuje vyhledávání pouze na zadané stránce a můžete zadat nejen název domény, ale také IP adresu. Zadejte například:
Operátor typ souboru: omezuje vyhledávání na soubory určitého typu. Například:
K datu tohoto článku může Google vyhledávat ve 13 různých formátech souborů:
- Adobe Portable Document Format (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (týden 1, týden 2, týden 3, týden 4, týden 5, týden, týden, týden)
- Lotus Word Pro (lwp)
- MacWrite (mw)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word (doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Formát RTF (rtf)
- Shockwave Flash (swf)
- Text (ans, txt)
Operátor odkaz: zobrazí všechny stránky, které ukazují na zadanou stránku.
Vždy musí být zajímavé vidět, kolik míst na internetu o vás ví. Zkoušíme:
Operátor mezipaměti: zobrazuje verzi webu uloženou v mezipaměti Google tak, jak vypadala, když Google stránku naposledy navštívil. Vezmeme všechny často se měnící stránky a podíváme se:
Operátor titul: hledá zadané slovo v názvu stránky. Operátor allintitle: je rozšíření - hledá všech zadaných pár slov v názvu stránky. Porovnat:
intitle:let na mars
intitle:flight intitle:on intitle:mars
allintitle:let na mars
Operátor inurl: způsobí, že Google zobrazí všechny stránky obsahující zadaný řetězec v adrese URL. allinurl: hledá všechna slova v URL. Například:
allinurl:acid_stat_alerts.php
Tento příkaz je užitečný zejména pro ty, kteří nemají SNORT – alespoň vidí, jak to funguje na reálném systému.
Metody hackování Google
Zjistili jsme tedy, že pomocí kombinace výše uvedených operátorů a klíčových slov může kdokoli shromáždit potřebné informace a vyhledat zranitelnosti. Tyto techniky jsou často označovány jako Google Hacking.
mapa stránek
Pomocí příkazu site: můžete zobrazit všechny odkazy, které Google na webu našel. Stránky, které jsou dynamicky vytvářeny skripty, se obvykle neindexují pomocí parametrů, takže některé weby používají filtry ISAPI, takže odkazy nejsou ve tvaru /článek.asp?num=10&dst=5, ale s lomítky /článek/abc/num/10/dst/5. To se provádí, aby bylo zajištěno, že web je obecně indexován vyhledávači.
Zkusme to:
stránky: www.whitehouse.gov whitehouse
Google si myslí, že každá stránka na webu obsahuje slovo whitehouse. To je to, co používáme k získání všech stránek.
Existuje také zjednodušená verze:
web: whitehouse.gov
A nejlepší na tom je, že soudruzi z whitehouse.gov ani nevěděli, že jsme se podívali na strukturu jejich webu a dokonce se podívali i do stránek uložených v mezipaměti, které si Google pro sebe stáhl. Toho lze využít ke studiu struktury webů a prohlížení obsahu, aniž by si toho člověk všiml.
Výpis souborů v adresářích
WEB servery mohou zobrazovat výpisy adresářů serveru namísto běžných HTML stránek. To se obvykle provádí, aby uživatelé museli vybrat a stáhnout konkrétní soubory. V mnoha případech však správci nemají v úmyslu zobrazovat obsah adresáře. To je způsobeno nesprávnou konfigurací serveru nebo nepřítomností hlavní stránky v adresáři. Díky tomu má hacker šanci najít v adresáři něco zajímavého a použít to pro své účely. K nalezení všech takových stránek si stačí všimnout, že všechny obsahují v názvu slova: index of. Protože ale index slov neobsahuje pouze takové stránky, musíme dotaz upřesnit a vzít v úvahu klíčová slova na samotné stránce, takže dotazy jako:
intitle:index.nadřazeného adresáře
intitle:index.of name size
Vzhledem k tomu, že většina výpisů v adresáři je záměrných, můžete mít potíže s hledáním nesprávně umístěných výpisů napoprvé. Ale alespoň budete moci pomocí výpisů určit verzi WEB serveru, jak je popsáno níže.
Získání verze WEB serveru.
Znalost verze WEB serveru je vždy užitečná před zahájením jakéhokoli hackerského útoku. Opět díky Google je možné získat tyto informace bez připojení k serveru. Pokud se pozorně podíváte na výpis adresáře, uvidíte, že je tam zobrazen název WEB serveru a jeho verze.
Apache1.3.29 – ProXad Server na trf296.free.fr Port 80
Zkušený správce může tyto informace změnit, ale zpravidla je to pravda. K získání těchto informací tedy stačí odeslat žádost:
intitle:index.of serveru.at
Abychom získali informace pro konkrétní server, upřesníme požadavek:
intitle:index.of server.at site:ibm.com
Nebo naopak hledáme servery běžící na konkrétní verzi serveru:
intitle:index.of Apache/2.0.40 Server at
Tuto techniku může hacker použít k nalezení oběti. Pokud má například exploit pro určitou verzi WEB serveru, může jej najít a vyzkoušet stávající exploit.
Verzi serveru můžete získat také tak, že se podíváte na stránky, které jsou standardně nainstalovány při instalaci nové verze WEB serveru. Chcete-li například zobrazit testovací stránku Apache 1.2.6, stačí napsat
intitle:Test.stránky.pro.Apache to.fungovalo!
Některé operační systémy navíc okamžitě nainstalují a spustí WEB server během instalace. Někteří uživatelé si to však ani neuvědomují. Samozřejmě, pokud vidíte, že někdo neodstranil výchozí stránku, je logické předpokládat, že počítač nebyl podroben žádné konfiguraci a je pravděpodobně zranitelný vůči útokům.
Zkuste hledat stránky IIS 5.0
allintitle:Vítejte ve Windows 2000 Internet Services
V případě IIS můžete určit nejen verzi serveru, ale také verzi Windows a Service Pack.
Dalším způsobem, jak zjistit verzi WEB serveru, je vyhledat manuály (stránky nápovědy) a příklady, které lze standardně nainstalovat na web. Hackeři našli poměrně dost způsobů, jak tyto komponenty využít k získání privilegovaného přístupu na web. To je důvod, proč musíte tyto součásti odstranit na místě výroby. Nemluvě o tom, že přítomností těchto komponent můžete získat informace o typu serveru a jeho verzi. Najdeme například příručku Apache:
inurl:manuální moduly direktiv Apache
Použití Google jako CGI skeneru.
CGI skener nebo WEB skener je nástroj pro vyhledávání zranitelných skriptů a programů na serveru oběti. Tyto nástroje potřebují vědět, co mají hledat, k tomu mají celý seznam zranitelných souborů, například:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Každý z těchto souborů můžeme najít pomocí Google, navíc pomocí slov index of nebo inurl s názvem souboru ve vyhledávací liště: můžeme najít stránky se zranitelnými skripty, například:
allinurl:/random_banner/index.cgi
S dodatečnými znalostmi by hacker mohl zneužít zranitelnost skriptu a využít tuto zranitelnost k tomu, aby skript obsluhoval jakýkoli soubor uložený na serveru. Například soubor s hesly.
Jak se chránit před hackery přes Google.
1. Nenahrávejte důležitá data na WEB server.
I když jste data dočasně zveřejnili, můžete na ně zapomenout nebo někdo bude mít čas tato data najít a vzít, než je vymažete. Nedělej to. Existuje mnoho dalších způsobů přenosu dat, které je chrání před krádeží.
2. Zkontrolujte svůj web.
Použijte popsané metody k průzkumu vašeho webu. Pravidelně na svém webu kontrolujte nové metody, které se objevují na webu http://johnny.ihackstuff.com. Pamatujte, že pokud chcete své akce automatizovat, musíte získat zvláštní povolení od společnosti Google. Pokud si pozorně přečtete http://www.google.com/terms_of_service.html, pak se zobrazí fráze: Bez předchozího výslovného souhlasu od společnosti Google nesmíte odesílat automatizované dotazy jakéhokoli druhu do systému Google.
3. Možná nebudete potřebovat Google k indexování vašeho webu nebo jeho části.
Google vám umožňuje odstranit odkaz na váš web nebo jeho část z jeho databáze a také odstranit stránky z mezipaměti. Kromě toho můžete zakázat vyhledávání obrázků na vašem webu, zakázat zobrazování krátkých fragmentů stránek ve výsledcích vyhledávání Všechny možnosti pro smazání webu jsou popsány na stránce http://www.google.com/remove.html. K tomu musíte potvrdit, že jste skutečně vlastníkem tohoto webu nebo vložit na stránku tagy resp
4. Použijte soubor robots.txt
Je známo, že vyhledávače nahlížejí do souboru robots.txt v kořenovém adresáři webu a neindexují ty části, které jsou označeny slovem Zakázat. Pomocí toho můžete zabránit indexování části webu. Chcete-li se například vyhnout indexování celého webu, vytvořte soubor robots.txt obsahující dva řádky:
User-agent: *
zakázat: /
Co se ještě stane
Aby se vám život nezdál jako med, na závěr řeknu, že existují stránky, které sledují ty lidi, kteří pomocí výše uvedených metod hledají díry ve skriptech a WEB serverech. Příkladem takové stránky je
Slepé střevo.
Trochu sladké. Vyzkoušejte sami jednu z následujících možností:
1. #mysql dump filetype:sql – vyhledá výpisy mySQL databáze
2. Souhrnná zpráva o zranitelnosti hostitele – ukáže vám, jaké zranitelnosti našli jiní lidé
3. phpMyAdmin běžící na inurl:main.php – toto vynutí zavřít ovládání pomocí panelu phpmyadmin
4. Není určeno k důvěrné distribuci
5. Podrobnosti požadavku na serverové proměnné řídicího stromu
6. Běh v dětském režimu
7. Tuto zprávu vytvořil WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs - možná někdo potřebuje konfigurační soubory firewallu? :)
10. intitle:index.of finance.xls - hmm....
11. intitle:Index chatů dbconvert.exe - icq chat logs
12. intext:Tobias Oetiker dopravní analýza
13. intitle:Statistiky použití pro Generated by Webalizer
14. intitle:statistika pokročilé webové statistiky
15. intitle:index.of ws_ftp.ini - konfigurace ws ftp
16. inurl:ipsec.secrets uchovává sdílená tajemství - tajný klíč - dobrý nález
17. inurl:main.php Vítejte v phpMyAdmin
18. inurl:server-info Informace o serveru Apache
19. site:edu admin známky
20. ORA-00921: neočekávaný konec SQL příkazu - získat cesty
21. intitle:index.of trillian.ini
22. intitle:Index of pwd.db
23. intitle:index.lid.lst
24. intitle:index.of master.passwd
25.inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.správců.pwd
29. intitle:Index.of etc stínu
30. intitle:index.secring.pgp
31. inurl:config.php název_dbu dbpass
32. inurl:provést typ souboru:ini
Školicí středisko "Informzaschita" http://www.itsecurity.ru - přední specializované středisko v oblasti školení v oblasti informační bezpečnosti (Licence Moskevského výboru pro vzdělávání č. 015470, státní akreditace č. 004251). Jediné autorizované školicí středisko Internet Security Systems a Clearswift v Rusku a zemích SNS. Autorizované školicí středisko společnosti Microsoft (specializace zabezpečení). Školicí programy jsou koordinovány se Státní technickou komisí Ruska, FSB (FAPSI). Certifikáty o školení a státní doklady o dalším školení.
SoftKey je jedinečná služba pro kupující, vývojáře, prodejce a affiliate partnery. Navíc se jedná o jeden z nejlepších online obchodů se softwarem v Rusku, na Ukrajině, v Kazachstánu, který zákazníkům nabízí široký sortiment, mnoho platebních metod, rychlé (často okamžité) vyřízení objednávky, sledování procesu plnění objednávky v osobní sekci, různé slevy z obchodu a výrobců ON.
Funkce Stories neboli „Příběhy“ v ruské lokalizaci umožňuje vytvářet fotografie a 10sekundová videa s překryvným textem, emotikony a ručně psanými poznámkami. Klíčovou vlastností takových příspěvků je, že na rozdíl od běžných příspěvků ve vašem feedu nežijí věčně a jsou smazány přesně po 24 hodinách.
Proč potřebuješ
Oficiální popis Instagramu říká, že nová funkce je potřeba pro sdílení nepříliš důležitých informací o běžném životě.
Jak to použít
Ve svém jádru je inovace velmi podobná a funguje v podstatě stejným způsobem, ale s malými rozdíly. Přestože Instagram Stories nemá tolik možností a všechny jsou velmi jednoduché, ne všichni uživatelé si s nimi poradí na cestách.
Zobrazit příběhy
Všechny dostupné příběhy se zobrazují v horní části zdroje jako kruhy s uživatelskými avatary a jsou při posouvání skryté. Nové příběhy se objevují, jak jsou publikovány, a o den později beze stopy zmizí. Příběhy jsou přitom řazeny nikoli chronologicky, ale podle počtu cyklů přehrávání a komentářů.

Pro zobrazení stačí klepnout na hrnek. Fotografie nebo video se otevře a zobrazí na 10 sekund. Klepnutím a podržením pozastavíte video.
Nahoře vedle uživatelského jména je zobrazen čas odeslání. Pokud lidé, které sledujete, mají jiné příběhy, další se zobrazí hned po prvním. Mezi nimi můžete přepínat přejetím doleva a doprava.


Příběhy, které jste si již prohlédli, z nabídky nemizí, ale jsou označeny šedou barvou. Mohou být znovu otevřeny, dokud nebudou po jednom dni odstraněny.
Příběhy můžete komentovat pouze pomocí zpráv, které se odesílají na Direct a jsou viditelné pouze pro autora, nikoli pro všechny odběratele. Jestli je to chyba nebo funkce, nevím.
Vytváření příběhů
Kliknutím na znaménko plus v horní části zdroje a přejetím od okraje obrazovky doprava se otevře nabídka pro záznam nového příběhu. Všechno je zde jednoduché: klepneme na tlačítko záznamu - získáme fotku, podržíme ji - natočíme video.
Natáčení nebo nahrávání


Můžete přepínat přední a zadní fotoaparát nebo zapnout blesk. Je také snadné vybrat mediální soubor z těch, které byly natočeny za posledních 24 hodin: to se provádí přejetím dolů. Dostanou se sem všechny fotky z galerie, včetně časosběrů a značkových bumerangů.
Léčba
Když jsou fotografie nebo videa připraveny, lze je po zpracování publikovat. Pro fotografie i videa jsou nástroje stejné: filtry, text a emotikony, kresby.


Filtry se přepínají v kruhu jednoduchým přejetím od okraje obrazovky. Je jich celkem šest, včetně duhového gradientu jako na ikoně Instagramu.
Přidaný text lze zvětšit nebo zmenšit, posouvat po fotografii. Ale zanechat více než jeden komentář, bohužel, je nemožné. Emoji se vkládají i přes text, takže pokud si chcete zakrýt obličej emotikonem, musíte si vybrat.


Kreslení má trochu více možností. Máme k dispozici paletku a hned tři štětce: běžné, fixové a s „neonovým“ tahem. Můžete kreslit všechny najednou, přičemž neúspěšný tah lze zrušit.
Jste s výsledkem spokojeni? Klikněte na tlačítko zaškrtnutí a vaše video bude dostupné odběratelům. Lze jej uložit do galerie před i po.
Nastavení soukromí, statistiky


Obrazovku nastavení a statistiky vyvoláte přejetím prstem nahoru při prohlížení příběhu. Odtud lze příběh uložit do galerie, smazat nebo publikovat do hlavního kanálu, čímž se z něj stane běžný příspěvek. Seznam diváků je zobrazen níže. Příběh před kterýmkoli z nich můžete skrýt kliknutím na křížek vedle názvu.


Nastavení skrytá za ikonou ozubeného kola vám umožňuje vybrat, kdo může odpovídat na vaše příběhy, a skrýt příběh před určitými odběrateli. Zároveň se zapamatují nastavení ochrany osobních údajů a použijí se na všechny následující publikace.
Jak s tím žít
Pokuta. Ano, mnozí brali Stories nepřátelsky kvůli podobnosti se Snapchatem a nevyřešeným problémům Instagramu, na které by se vývojáři měli zaměřit. Ale myslím, že inovace je užitečná.
Problém nepřehledného feedu, kdy se musíte odhlásit od přátel, kteří doslova vyskládají každý jejich krok, existuje již dlouho a nebylo vynalezeno jeho jasné řešení. Příběhy lze považovat za první krok k tomu. Lidé by si časem měli zvyknout na nabízenou kulturu chování a začít do feedu zveřejňovat jen opravdu důležitý a pozoruhodný obsah. Vše ostatní by mělo jít do Stories. To je pravda?
Na konci listopadu 2016 představil vývojový tým telegram messenger novou službu pro online publikace. Telegrafovat je speciální nástroj, který vám umožňuje vytvářet objemné texty založené na odlehčeném jazyku markdown webu. Pomocí této platformy můžete publikovat články na internetu s fotografiemi, videi a dalšími vloženými prvky. Zároveň není vyžadována žádná registrace s osobními údaji, což umožňuje zachování naprosté anonymity.
Jaké příležitosti nabízí nová platforma blogerům?
Podle vývojářů služby má uživatel možnost prezentovat informace stejně, jako to dělají klasická média. K tomu má Telegraph vše, co potřebujete:
 Aby vývojáři demonstrovali všestrannost produktu, zveřejnili API na doméně telegra.ph
Aby vývojáři demonstrovali všestrannost produktu, zveřejnili API na doméně telegra.ph
Navenek se obsah Telegraph neliší od materiálů zveřejněných na webových zdrojích konvenčních médií, nicméně anonymita autorství a prohlížení článků přímo v messengeru otevírá moderním blogerům jedinečné příležitosti. Nejzajímavější publikace vytvořené pomocí nové služby jsou prezentovány ve vynikající .
Jak pracovat s telegrafem
Abyste mohli tento nástroj používat, musíte navštívit www.telegra.ph. Při přechodu na tuto adresu uživatel narazí na téměř prázdnou stránku se třemi jednoduchými řádky: Název, Vaše jméno, Váš příběh.
- Řádek Titulek je určen pro psaní nadpisu článku, který spolu s datem publikace tvoří odkaz na obsah. Například článek „Jak propagovat svůj web mezi top 10“ publikovaný 5. dubna bude mít odkaz: „http://telegra.ph/Kak-prodvinut-sajt-v-top-10-04-05“ .
 Rozhraní nástroje pro vytváření článků telegra.ph je velmi jednoduché
Rozhraní nástroje pro vytváření článků telegra.ph je velmi jednoduché - Položka Vaše jméno je volitelná. Autor může uvést své skutečné jméno, pseudonym, přezdívku nebo dokonce nechat řádek prázdný, aby nikdo nemohl určit jeho identitu. Možnost publikovat materiál a přitom zůstat inkognito je docela zajímavá. Ale většina spisovatelů ráda uvede své autorství.
- Váš příběh je polem pro vytvoření hlavního obsahu. Otevírá také možnosti pro formátování textu, které byly zmíněny výše. Algoritmus pro vytvoření článku je velmi jednoduchý a intuitivní, takže uživatelé by neměli mít s jeho psaním žádné potíže.
Jedinečný odkaz vám umožňuje používat publikovaný materiál nejen v Telegramu, ale také na jiných stránkách. Tvůrce přitom může obsah kdykoliv měnit. Je pravda, že tato funkce funguje pouze v případě, že jsou soubory cookie uloženy.
 Pro snadnou správu všech článků použijte robota
Pro snadnou správu všech článků použijte robota K vytvoření článku vyžaduje uživatel minimum akcí. Tato snadnost má však nevýhodu. Další úpravy lze provádět pouze na stejném zařízení a ve stejném prohlížeči, ve kterém byl text poprvé publikován. Vývojáři tuto situaci předvídali a vytvořili speciálního robota pro správu publikací. Pojďme si vyjmenovat jeho funkčnost:
- Autorizace v Telegraph z vašeho účtu Telegram. Vytvořením příspěvku tímto způsobem se budete moci přihlásit na jakémkoli jiném zařízení a budete mít přístup k úpravám. Při první autorizaci na každém zařízení vám robot nabídne přidání všech dříve vytvořených příspěvků na váš účet.
- Zobrazit statistiky pro jakýkoli telegrafní příspěvek. Bere v úvahu všechny přechody do článku, nejen z telegramu, ale také z jakýchkoli externích zdrojů. Můžete analyzovat nejen své vlastní publikace, stačí poslat odkaz, který vás zajímá, robotovi.
- Můžete nastavit trvalý alias a odkaz na profil, abyste je nemuseli pokaždé zadávat.
Telegraf – skutečná hrozba pro tradiční média?
Messengery, které svou povahou patří do mediální sféry, se vyvíjejí rychlým tempem a mění se v pohodlné platformy pro zveřejňování užitečných informací. Vznik takové služby, jako je Telegraph, ještě více usnadnil vytvoření plnohodnotné obchodní platformy, která přiláká koncového uživatele. Mnoho značek již začíná chápat, že tento typ komunikace je stále aktuálnější.
Stále je však předčasné tvrdit, že instant messenger obecně a Telegraph zvláště vytvářejí přímou konkurenci tradičním médiím. Takové služby jsou odborníky definovány jako doplňkový nástroj pro generování internetového obsahu, který může být pro média dobrým pomocníkem, ale v této fázi vývoje je není schopen zcela absorbovat.
 Internetová média jsou vůči konkurenční platformě obezřetná
Internetová média jsou vůči konkurenční platformě obezřetná

































