Multe articole sunt scrise despre selecția kernel-ului semantic, dar există încă greșeli. Cum să ridici kernel semantic. Cu un număr mare de interogări cheie? Trebuie să mă extind kernelul semantic în timp? Cum să distribuiți cuvintele cheie pe o pagină? La aceste și alte întrebări, citiți în foaia noastră de înșelătorie.
Atenţie! 23 octombrie va ieși în următoarea ediție a "paturilor de optimizare", subiectul său - "CMS" .
Trimiteți-vă întrebările și experții noștri vă vor răspunde!
Kernel semantic.
1. Cum să faceți un kernel semantic pentru un magazin online, există anumite caracteristici?
Atunci când efectuați un kernel semantic pentru un magazin online, trebuie luate nu numai interogări de înaltă frecvență, iar gama de produse maximizează și promovează în mod activ categoriile și cărțile de bunuri de pagină.
Prin urmare, pentru astfel de resurse o cerere de vizualizare "Cumpără telefon Nokia. N8 " va fi mai multă conversie și eficientă decât o interogare cu o frecvență mai mare de tip "Cumpărați telefonul".
Pentru a face un kernel semantic, care va conduce vizitatorii site-ului, puteți utiliza două moduri: automată și manuală.
Selectarea automată a cererilor poate fi efectuată utilizând servicii și programe speciale. (De exemplu, service online seolib.ru, colector cheie, slobel etc.).
Metoda manuală este bună deoarece puteți alege solicitări simultan pe paginile țintă - cartele și categoriile utilizând schemele de selecție:
- "Produs + cuvinte suplimentare"
- "Cumpărați + bunuri + cuvinte suplimentare"
- "Vanzare + produs + cuvinte suplimentare"
- "Preț + produs + cuvinte suplimentare"
- "Caracteristici + produs + cuvinte suplimentare"
- "Descriere + produs + cuvinte suplimentare"
- "Foto + produs + cuvinte suplimentare", etc.
În același timp, în miezul semantic, vom primi nu numai cereri comerciale, ci și informații care vor face ca miezul și ancorarea noastră să fie mai naturale.
De exemplu, pentru categoria de bunuri "smartphone Apple iPhone" în magazinul online telefoane mobile Puteți găsi solicitări utilizând o masă simplă în Excel:
Adică, pe baza datelor din tabel, am preluat 3 opțiuni pentru o interogare pentru o pagină a Categoria Smartphone-urilor Apple iPhone:
- "Cumpără smartphone Apple. iPhone 3 4 GB alb »
- "Vanzare Smartphone Apple iPhone 4 8 GB Negru"
- "Descriere smartphone Apple iPhone 5 16 GB White"
2. Cum de a alege un kernel semantic pentru un site de știri regionale? Subiecte.
Selectați kernelul semantic, apoi scrieți știrile sub ea - abordarea greșită pentru orice site de știri, inclusiv teme IT.
Sarcina primară pentru site-ul de știri este publicarea informațiilor operaționale, interesante și relevante privind evenimentele curente, informații care vor fi interesate astăzi de cititori. Numai cu această abordare, site-ul va putea deveni popular, cucerirea încrederii utilizatorilor și, prin urmare, și motoarele de căutare. În urma acestui principiu, veți forma în mod natural nucleul semantic corect al site-ului dvs. La urma urmei, principalele subiecte (cereri), într-un fel sau altul, vor fi menționate în știrile subiectului dvs. Dacă rămâne timpul liber, este mai bine să-l cheltuiți cu privire la creșterea numărului și îmbunătățirii calității materialelor publicate decât pentru pregătirea articolelor în anumite solicitări.
3. Merită să utilizați interogări de înaltă frecvență în miezul semantic?
Interogările de frecvențe noi pot fi utilizate de noi site-uri, dar depinde de nivel de subiect și de concurență. Cu cât este mai mare nivelul de concurență, cu atât mai dificilă (sau imposibilă) pentru a promova site-ul, deoarece motoarele de căutare vor da preferință resurselor vechi, de încredere.
De exemplu, să vedem emiterea în top-10 la cerere "Aer condiționat" (motorul de căutare Yandex, regiunea "Moscova"):

Pentru site-urile a căror vârstă este mai mică de doi ani, se recomandă să se deplaseze la cererile de frecvență și frecvență redusă. Folosindu-le în kernelul semantic, nu veți cheltui bugetul pentru promovare și puteți atrage publicul țintă pe site. Middle-i. cereri de frecvență joasă sunt cea mai conversie, ceea ce duce la locul clienților potențiali.
4. Cum să faci un kernel semantic cu un număr mare de chei? Ce se oprește și ce să arunce într-o astfel de situație? Evident, este imposibil să lucrăm cu câteva mii de chei.
Unele secrete nu există - lucrarea este dureroasă și, dacă este necesar, trebuie să lucreze cu câteva mii de chei.
Există modalități de a facilita munca. În prima etapă a selecției cererilor, este convenabil să se utilizeze serviciile de colectare automată a statisticilor, configurarea "cuvintelor de oprire" și specificarea regiunilor necesare. Serviciul automat va scăpa de nevoia de a introduce manual cuvintele la serviciul WordStat.yandex.ru.
Lista de solicitări rezultate ar trebui împărțită în mai multe grupuri prioritare. Aici, desigur, totul depinde de subiectul dvs. specific. De exemplu, dacă aveți un site de vânzare, mai întâi necesită tipuri de tipuri de tranzacționare de tip "Cumpără", "Preț" etc.
5. După ce timpul merită să completați și să extindeți kernelul semantic și merită să faceți totul?
Puteți extinde kernelul semantic și nevoia. Este optim să faceți acest lucru în câteva luni de promovare, când etapa principală a trecut deja și site-ul a luat pozițiile de lider cel puțin 70% din prima listă de interogări.
La extinderea kernelului, selectați solicitări astfel încât acestea să intersecteze cu lista originală. În caz contrar, dacă îmbunătățiți textul, anteturile și meta-etichetele de fiecare dată când puteți edita textul, motoarele de căutare, motoarele de căutare pot să o găsească nefiresc și suspecte și să scadă site-ul în extrădare.
La extinderea kernel-ului semantic, în plus metode standard Crearea unei liste de solicitări, se recomandă utilizarea datelor de la Google.Nalytics și Yandex.metrics.
Cum pot fi utile serviciile de date, vom arăta despre exemplul lui Yandex.MEtrics - mergeți la yandex.metric, găsiți filele "Surse" - "Fraze de căutare":

Și veți fi prezentat cu o listă cu toate solicitările pentru care au fost vizite pe site, numărul de vizitatori pentru fiecare solicitare:

În această listă, selectați interogări care sunt vizate pentru resursa dvs. și nu sunt incluse în miezul semantic inițial. Apoi, verificați pozițiile site-ului în conformitate cu lista primită și puteți, mai întâi, să luați aceste interogări pentru care site-ul nu este în top 10. Pentru solicitările rămase, puteți urmări periodic pozițiile și le puteți strânge în caz de semințe.
6. Ca și în formarea nucleului semantic, determinați ce cereri prioritare, care sunt opțional?
Pentru a împărtăși interogări pentru prioritate și suplimentar, trebuie să luați în considerare ce tip se referă. Se disting trei tipuri: frecvență înaltă (HF), frecvență redusă (LF) și la jumătatea frecvenței (s). Interogarea RF este cea mai populară solicitare și există mai puțin populare SCH și LF în jurul ei. Prin urmare, prioritatea va fi HF și suplimentară - SCH și scurt. De exemplu, cererea RF - "Windows din plastic" Solicitare principală la pagină, SC Solicitare - "Ferestre din plastic din Moscova" și solicitarea LF - Cereri suplimentare.
7. Care ar trebui să fie numărul cuvinte cheie la pagină? În mod specific în numere - 3, 10, 15?
Este răspunsă în mod unic dificilă, pentru că Fiecare situație individuală necesită diverse abordări. Cele mai corecte optimizează pagina sub o solicitare HF, 2-3 interogare Sch și în continuare - sub cererile NF. Logica este simplă - o pagină merge o cerere principală, în jurul căreia totul "rotirea".
De exemplu, "Windows din plastic" - cererea RF; "Ferestre din plastic pentru a cumpăra", "Windows din plastic Moscova" - cereri SC; "Ferestre din plastic pentru a cumpăra în Moscova" - Interogare LF. Va fi dificil să promovați pagina dacă o optimizați pentru solicitări "Imprimarea logo-urilor" și "film de seră". Excepția este doar "acasă", pentru că Ar trebui să descrie întreaga gamă de servicii de site-uri.
Rețineți că pentru interogări cu cuvinte suplimentare cum ar fi "Cumpără", "angro", "Preț" Nu este recomandat să optimizați alte pagini, cu excepția celei în care se află interogarea principală, de înaltă frecvență. De exemplu, un program de pagină promovat "Ferestre din plastic", Trebuie să fie mutat și la cerere "Ferestre din plastic pentru a cumpăra".
8. Merită să vindeți cererile de informații către miezul semantic, acest lucru este destul de bun sau încă nu este nevoie de astfel de solicitări?
Cu siguranta merita. După cum scrieți, este un trafic suplimentar, care poate duce și la conversie. La crearea de secțiuni de informare pe un site comercial, este important să adere la mai multe principii:
- materialele informaționale ar trebui să fie foarte utile utilizatorilor de informare a informațiilor importante și utile. Este necesar să se pregătească publicații de înaltă calitate și nu doar să completeze articolele din secțiunea, "ascuțit" sub cereri;
- nu uitați că site-ul dvs. este în primul rând comercial. Pentru majoritatea subiecților, situația în care numărul de articole de informare depășește numărul de carduri de produse, acesta va arăta ciudat;
- Încercați să plasați link-uri în legăturile corpului către vânzarea paginilor site-ului. Acest lucru va spori eficiența traficului de informații.
9. Cum să implementați mai eficient referințele din conținutul frecvențelor, adică frecvențe de legare a unui nivel sau le răsuciți cu frecvențe diferite ale LF-HF?
În ceea ce înțelegem, întrebarea se referă la transfina interioară.
Strategii Peregonovka Există o sumă mare, dar nu am recomanda să "atașați" conceptului de frecvență de solicitare. Este important ca transfina să fie utilă. Dacă referința din interiorul conținutului utilizează - va ajuta. Dacă link-ul "mort" și nu îl folosiți - un sentiment al acesteia, cel mai probabil nu va fi prea mult. Și nu există nicio diferență, vă referiți la solicitarea LF din pagina de solicitare RF sau invers.
Desigur, efectul transfinei interioare este mai vizibil pentru solicitările LF, deoarece acestea sunt mai puțin "exigente" decât interogările de înaltă frecvență, cu o mare concurență. Dar, încă o dată, vom repeta că dorința de a "fi atașat" unui algoritm specific de supragrat, fără a gândi cât de mult este nevoie de overclocking de către utilizator, nu numai că nu ajută, dar poate dăuna. Motoarele de căutare nu-i plac spam-urile.
10. Am făcut un miez semantic, concentrându-mă pe Yandex, deși am un site ucrainean și majoritatea vizitatorilor provin de la Google. Acest nucleu este potrivit pentru Google (cred, fac Yandex și utilizatorii Google vă rugăm să practicați cererile) sau trebuie să faceți una nouă?
Diferențele esențiale în cererile de la Yandex și utilizatorii Google nu sunt de obicei observate. Dacă selecția a luat în considerare regiunea (în cazul dvs., Ucraina), atunci nu ar trebui să existe probleme.
Pentru unele subiecte, regiunea poate contează (poate fi selectată atunci când analizează cererile din Yandex wordstat.). Diferența în legislație sau popularitatea anumitor producători poate duce la distincție. În acest caz, trebuie să vă uitați la subiectul dvs. Dacă nu există diferențe regionale, atunci puteți utiliza în siguranță un nucleu selectat ca de bază.
11. Site-ul meu se mișcă la cererea de "cămile" și pe acest cuvânt este în top 3. Dar, conform cuvântului "Camel", nu este nici măcar în topul 30. De ce poate fi așa? Utilizarea pluralului sau a singurii din cuvântul cheie afectează poziția site-ului?
Da, în multe cazuri afectează, pentru că Yandex, căutând un număr multiplu și numai poate diferi semnificativ, înseamnă că percepe aceste cereri, la fel de diferite. În plus, există o diferență semnificativă în frecvența cererilor. De exemplu, dacă te uiți la cererile Yandex.wordstat.ru (Moscova) "Fereastra de plastic" și "Windows din plastic", atunci prima frecvență va fi de 7650, iar al doilea este 169315. În consecință, emiterea va fi complet diferită, pentru că Aceasta este în mod clar diferite cereri. Tratați cu atenție cuvântul respectiv pentru a optimiza pagina, pentru că Dacă alegeți formularul greșit - pierde traficul.
12. În ofertele lor comerciale, multe firme de promovare fac o masă cu un miez semantic și un cost pe zi a fiecărei fraze pentru găsirea de poziții 1-3, 4-6, 7-10 în Yandex, Google. Cum se ia în considerare acest buget?
Întrebarea este destul de complicată, deoarece fiecare companie poate avea coeficienți proprii și este nerezonabil să vorbim despre toate companiile.
În mod tipic, costul de interogare este calculat, pe baza complexității sale (cu alte cuvinte, cât de mult timp angajatul va da timp acestei cereri sau unui grup de solicitări) și volumul necesar de masă de referință. În plus, ar trebui să luați în considerare numărul total de solicitări promovate (cu atât mai multe cereri, cele mai ieftine fiecare dintre ele, deoarece masa generală de referință a site-ului va fi mai mare).
13. Întrebarea este după cum urmează. Am un domeniu (RU), cumpărat acum 1,5 ani. Când am creat un site pe el, nu m-am gândit prea mult la pregătirea nucleului semantic (teme medicale, 40 de pagini în index, nu există vizitatori). Am vrut să întreb - dacă încep să creez un nou site pe acest domeniu (un alt subiect), deja cu pregătirea kernel-ului semantic etc., deoarece pașii mei vor fi tratați de motoarele de căutare, cum va fi indexată, După ce perioadă vor exista schimbări? Sau este mai bine să creați un site de alte subiecte pe un domeniu nou și să uitați de vechiul (RU)?
Dacă site-ul actual nu se aplică filtre și domeniu sunt potrivite pentru ceilalți subiecți (amintiți-vă că trebuie să fie utilizatori memorabili și să afișeze activitatea) - nu ar trebui să existe probleme.
Cu toate acestea, motoarele de căutare pot fi "atente" la schimbarea completă a site-ului același proprietar, deoarece schimbarea bruscă a subiectului pare ilogică. Cel mai adesea schimba subiectele de site-uri realizate sub vânzarea de referințe etc.
Un alt punct din care dorim să avertizăm este crearea unui site sub miezul semantic disponibil. Inițial, este necesar să se dezvolte un concept de site-uri web, să înțelegeți că puteți oferi utilizatorilor dvs. să vă determine oferta unică și să creați deja un site web, să selectați aceste interogări pentru care vizitatorii țintă pot merge la dvs.
Perioada de re-indexare este dificilă, puteți naviga aproximativ o lună și jumătate.
Comunicate anterioare de foi de trișor optimizator:
ÎN acest moment Pentru promovarea căutării, astfel de factori, deoarece conținutul și structura sunt jucate la fel de importante ca un rol important. Cu toate acestea, cum să înțelegeți ce să scrieți text în ce secțiuni și crearea de pagini de pe site? În plus, trebuie să aflați exact ce este interesat exact vizitatorul țintă al resurselor dvs.. Pentru a răspunde la toate aceste întrebări, trebuie să asamblați kernelul semantic.
Kernel semantic. - Lista cuvintelor sau frazelor care reflectă pe deplin subiectul site-ului dvs.
În articol, vă voi spune cum să o luați, curățați și împărțiți în structură. Rezultatul va fi o structură completă cu interogările grupate prin pagini.
Iată un exemplu de nucleu de solicitări rupte în structură:

Sub clustering, înțeleg defalcarea interogărilor de căutare pentru pagini individuale. Această metodă va fi relevantă atât pentru a promova Yandex și Google. În articol, voi descrie o modalitate complet gratuită de a crea un nucleu semantic, dar voi afișa ambele opțiuni cu diferite servicii plătite.
După ce ați citit articolul, veți învăța
- Selectați cererile corecte pentru subiectul dvs.
- Colectați cel mai complet nucleu de fraze
- Cleant de la cererile neinteresante
- Grupul și creați structura
Colectați miezul semantic pe care îl puteți
- Creați o structură semnificativă pe site
- Creați un meniu multi-nivel
- Umpleți paginile cu texte și scrieți-le de la Metapping și Titlu
- Colectați poziția site-ului dvs. la cererile motoarelor de căutare
Colectarea și gruparea kernel-ului semantic
Compilația adecvată pentru Google și Yandex începe cu definiția principalelor fraze cheie ale subiectului dvs. De exemplu, voi demonstra compilația pe un magazin de îmbrăcăminte online fictiv. Există trei modalități de a colecta kernelul semantic:
- Manual. Folosind serviciul Yandex Wordstat, introduceți cuvintele dvs. cheie și mâinile dvs. alegeți frazele de care aveți nevoie. Această metodă este suficient de rapidă dacă trebuie să asamblați cheile la o pagină, cu toate acestea, există două minusuri.
- Acuratețea metodei "cromas". Puteți pierde întotdeauna cuvinte importante dacă utilizați această metodă.
- Nu veți putea asambla kernelul semantic pe un magazin online mare, deși puteți utiliza pluginul asistent Yandex Wordstat pentru a simplifica - problema nu o rezolvă.
- Semiautomat. În această metodă, presupun utilizarea programului de colectare a nucleului și defalcarea manuală suplimentară asupra secțiunilor, subsecțiilor, paginilor etc. Această metodă de compilare și grupare a kernelului semantic în opinia mea este cea mai eficientă. Are o serie de avantaje:
- Acoperirea maximă a tuturor temelor.
- Defalcare de calitate
- Auto. În zilele noastre, există mai multe servicii care oferă o colecție de kernel complet automată sau clustering solicitările dvs. Opțiunea complet automată - nu recomand să utilizați, deoarece Calitatea colectării și a clusteringului kernel-ului semantic este în prezent destul de scăzută. Întrerupătoare automată Clustering - câștigând popularitate și are loc, dar trebuie să îmbinați încă câteva pagini cu mâinile, pentru că Sistemul nu oferă o soluție ideală gata. Și în opinia mea, vă confundați și nu veți putea să vă plimbați în proiect.
Pentru compilarea și gruparea unui nucleu semantic adecvat pe orice proiect în 90% din cazuri, folosesc o metodă semi-automată.
Deci, pentru a trebui să îndeplinim următorii pași:
- Selectarea cererilor de teme
- Alegerea kernelului la cereri
- Curățarea de la interogările non-țintă
- Clustering (întrerupeți frazele pe structură)
Un exemplu de coasere a kernelului semantic și gruparea pe structura pe care am arătat-o \u200b\u200bmai sus. Vă reamintesc că avem un magazin de îmbrăcăminte online, începem paving 1 punct.
1. Selectarea frazelor pentru subiectul dvs.
În acest stadiu, avem nevoie de Instrumentul Yandex Wordstat, concurenții și logica dvs. În acest pas, este important să se asambleze o listă de fraze care sunt solicitări tematice de înaltă frecvență.
Cum se selectează cererile de colectare a semanticii cu Yandex Wordstat
Vino pe serviciu, alegeți orașul de care aveți nevoie (a) / regiuni, conduceți cele mai "grăsimi" în cererile dvs. de opinie și uitați-vă la coloana din dreapta. Acolo veți găsi cuvinte tematice de care aveți nevoie, atât pe alte secțiuni, cât și sinonime de frecvență pentru fraza inscripționată.

Cum se selectează cererile înainte de a face un kernel semantic folosind concurenți
Introduceți cele mai populare solicitări din motorul de căutare și selectați unul dintre cele mai populare site-uri, multe dintre care sunteți cel mai probabil și știți.

Acordați atenție secțiunilor principale și salvați frazele de care aveți nevoie.
În acest stadiu, este important să faceți corect: să maximizați tot felul de cuvinte din subiectul dvs. și să nu pierdeți nimic, atunci kernelul dvs. semantic va fi cel mai complet posibil.
Aplicabil la exemplul nostru, trebuie să facem o listă cu următoarele fraze / cuvinte cheie:
- îmbrăcăminte
- Încălţăminte
- Cizme
- Rochii
- Tricouri
- Lenjerie
- Pantaloni scurti
Ce fraze intră în sens fără sens: Îmbrăcăminte pentru femei, cumpărați pantofi, rochie la absolvire etc. De ce? - Aceste fraze sunt "cozile" de "îmbrăcăminte" cereri, "pantofi", "rochii" și vor fi adăugate la kernelul semantic automat în stadiul 2 al colecției. Acestea. Le puteți adăuga, dar va fi dublă fără sens.
Ce chei trebuie să se potrivească? "Harfoots", "Boots" nu sunt aceleași ca "cizme". Este forma cuvântului care este importantă și nu acel cuvinte unice sau nu.
Cineva are o listă de fraze cheie lungi și cine este format dintr-un singur cuvânt - nu-ți fie frică. De exemplu, magazinul online al ușilor pentru pregătirea kernel-ului semantic este destul de posibil "ușile".
Și așa, la sfârșitul acestui pas, ar trebui să avem o listă similară.

2. Colectarea cererilor de kernel semantic
Pentru o colecție adecvată, avem nevoie de un program. Voi afișa un exemplu în același timp pe două programe:
- Pe KeyCollectorul plătit. Pentru cei care au sau care dorește să cumpere.
- Gratuit - Slovoeeb. Program gratuit pentru cei care nu sunt pregătiți să cheltuiască bani.
Deschideți programul

Crea proiect nou Și să-l numim, de exemplu, MySite

Acum, pentru colectarea în continuare a kernel-ului semantic, trebuie să facem câteva lucruri:
Creați un cont nou pe Yandex Mail (vechi nu este recomandat să se utilizeze datorită faptului că acesta poate fi interzis pentru multe cereri). Deci, ați creat un cont, de exemplu [E-mail protejat] Cu parola Super2018. Acum trebuie să specificați acest cont în setări ca Ivan.IVANOV: Super2018 și apăsați butonul "Salvați modificările" din partea de jos. Citiți mai multe - pe capturi de ecran.

Alegem regiunea pentru a compila kernelul semantic. Trebuie să alegeți numai regiunile în care vă veți deplasa și faceți clic pe Salvați. Din acest lucru va depinde de frecvența cererilor și dacă vor cădea în principiu în colecție.

Toate setările sunt finalizate, rămâne să adăugați fraza noastră reală în primul pas și să faceți clic pe butonul "Start Collection" al kernel-ului semantic.

Procesul este complet automat și suficient de lung. Puteți face cafea în timp ce faceți cafea și dacă tema este largă, de exemplu, ca cea pe care o colectăm - este de câteva ore 😉
Odată ce toate frazele se adună pentru a vedea ceva similar:

Și pe această etapă este finalizată - treceți la următorul pas
3. Curățarea kernel-ului semantic
În primul rând, trebuie să ștergem cererile pe care nu le interesează (Neurozzi):
- Asociate cu o altă marcă, de exemplu, "blugi Gloria", "ecco"
- Cereri de informații, de exemplu, "am purta cizme", "dimensiunea blugi"
- Similar pe subiect, dar nu este legat de afacerea dvs., de exemplu, "îmbrăcămintea B", "en-gros de femei"
- Solicitări, în nici un caz legate de temă, de exemplu, "Rochii Sims", "Cat în Boots" (astfel de solicitări după selecția kernelului semantic sunt destul de multe)
- Cereri din alte regiuni, metrou, districte, străzi (indiferent de regiunea colectată solicitări - o altă regiune încă mai vine)
Curățarea trebuie efectuată manual după cum urmează:

Introducem cuvântul, apăsați pe "Enter", dacă în kernelul nostru semantic creat este acele fraze pe care avem nevoie, alocăm ștergerea găsită și faceți clic pe Ștergere.
Vă recomandăm să introduceți cuvântul care nu este în întregime, dar folosind designul fără propoziții și terminații, adică. Dacă scriem cuvântul "glorie", va găsi fraze "cumpăra în gloriul blugi" și "cumpăra în blugi Gloria". Când scrieți "Gloria" - "Gloria" nu ar fi fost găsită.
Astfel, trebuie să treceți prin toate punctele și să vă eliminați din cererile inutile de kernel semantic. Acest lucru poate dura un timp considerabil și poate se va dovedi că eliminați cele mai multe dintre interogările colectate, dar rezultatul va fi o listă curată și corectă de toate tipurile de solicitări promovate pentru site-ul dvs.
Descărcați acum toate solicitările dvs. de a excela

De asemenea, puteți elimina în mod masiv interogările non-țintă din semantică, cu condiția să aveți o listă. Puteți face acest lucru cu cuvinte stop și este ușor de făcut pentru un grup tipic de cuvinte cu orașe, metro, străzi. O listă cu astfel de cuvinte pe care le folosesc puteți descărca în partea de jos a paginii.
4. Gruparea kernelului semantic
Aceasta este partea cea mai importantă și interesantă - este necesară împărțirea reglementărilor noastre asupra paginilor și secțiunilor care, în agregat, va crea structura site-ului dvs. Un pic de teorie - decât ghidat de cereri:
- Concurenți. Puteți acorda atenție la modul în care gruparea semanticului de la concurenții dvs. din partea de sus și acționează într-un mod similar, cel puțin cu secțiunile principale. Și, de asemenea, să se uite la ce pagini sunt în extrădarea cererilor de frecvență redusă. De exemplu, dacă nu sunteți sigur că "faceți sau nu" o secțiune separată pentru solicitarea "fuste din piele roșie", conduceți fraza în motorul de căutare și vedeți emiterea. Dacă emiterea conține resurse în cazul în care există astfel de secțiuni, înseamnă că are sens să faceți o pagină separată.
- Logică. Faceți întreaga grupare a kernelului semantic folosind LOGIC: Structura trebuie să fie clară și să reprezinte pagina structurată a paginilor cu categorii și subcategorii din cap.
Și un cuplu mai mult:
- Nu este recomandat să instalați mai puțin de 3 cereri către pagină.
- Nu faceți prea multe niveluri de cuibărit, încercați să faceți acest lucru, încât au fost 3-4 (site.ru / Categorie / Subcategorie / Subcategorie)
- Nu efectuați URL-uri lungi Dacă aveți multe nivele de cuibărit atunci când clustering kernelul semantic, încercați să reduceți adresele URL ale ierarhiei de foarte mult pe categorii, adică În loc de "vash-site.ru/zhenskaya-odezhda/palto-dlya-zhenshin/krasnoe-palto", nu "vash-site.ru/zhenshinam/palto / krasnoe"
Acum pentru a practica
Clustering de bază pe exemplu
Pentru a începe, vom împărtăși toate cererile pentru principalele categorii. Privind logica concurenților - principalele categorii pentru magazinul de îmbrăcăminte vor fi: îmbrăcăminte pentru bărbați, îmbrăcăminte pentru femei, îmbrăcăminte pentru copii, precum și o grămadă de alte categorii care nu sunt legate de podea / vârstă, cum ar fi pur și simplu "pantofi" , îmbrăcăminte de îmbrăcăminte.
Noi grupăm kernelul semantic ajutor Excel.. Deschideți fișierul și acționarea:
- Împărțim pe secțiunile principale
- Luați o secțiune și împărțiți-o la subsecțiunile
Voi arăta exemplul unei secțiuni - îmbrăcămintea bărbaților și subsecțiunea sa. Pentru a separa cheile de la ceilalți, trebuie să evidențieți întreaga foaie și să faceți clic pe Formatare condiționată-\u003e Reguli de selecție a codului-\u003e Textul conține

Acum, în fereastra care se deschide, scriem "soț" și apăsați pe Enter.

Acum toate cheile noastre de îmbrăcăminte pentru bărbați sunt evidențiate. Este suficient să utilizați filtrul pentru a separa cheile selectate de la restul kernelului semantic asamblat.
Deci, porniți filtrul: trebuie să evidențiați o coloană cu solicitări și apăsați filtrul de sortare și filtru-\u003e

Și acum sortate

Creați o foaie separată. Tăiați liniile selectate și introduceți-le acolo. În acest fel, va trebui să continuați și să întrerupeți kernelul.
Schimbați numele acestei foi la "Îmbrăcăminte pentru bărbați", o foaie în care totul este kernelul semantic, numele "Toate cererile". Apoi creați o altă foaie, numiți "structură" și puneți-o mai întâi. Pe pagina structurii, creați un copac. Ar trebui să reușești așa:

Acum trebuie să împărțim secțiunea mare a îmbrăcămintei bărbaților la subsecțiuni și sub-subsecțiuni.
Pentru confortul de utilizare și tranziții în funcție de kernelul semantic cluster, plasați referințele la structură la foile corespunzătoare. Pentru a face acest lucru, faceți clic dreapta pe elementul dorit din structură și faceți ca în ecranul de ecran.

Și acum trebuie să vă separam mâinile pentru a împărtăși solicitările, îndepărtând simultan ceea ce nu a fost observat și eliminat în faza de curățare a kernelului. În cele din urmă, datorită clusteringului kernel-ului semantic, ar trebui să aveți o structură similară cu aceasta:


Asa de. Ce am învățat să facem:
- Alegeți cererile de care aveți nevoie pentru a colecta kernelul semantic
- Colectați toate frazele posibile pentru aceste solicitări
- Curat
- Cluster și crea structură
Acest lucru datorită creării unui astfel de kernel semantic cluster, puteți face pe:
- Creați o structură pe site
- Creați un meniu
- Scrierea textelor, metaling, taitla
- Colectați poziții pentru a urmări difuzoarele la cereri
Acum puțin despre programe și servicii
Programe de colectare a kernel-ului semantic
Aici voi descrie nu numai programele, ci și plugin-urile și serviciile online pe care le folosesc
- Asistentul Yandex Wordstat este un plugin, datorită căruia, este convenabil să selectați cererile de la Vordstat. Mare pentru compilarea rapidă a miezului pe un site mic sau o pagină.
- Caicollectorul (Slobel - versiune gratuită.) - Un program cu drepturi depline pentru clustering și crearea unui kernel semantic. Eșidează o mare popularitate. Un număr mare de funcțional în plus față de direcția principală: selectarea cheilor dintr-o grămadă de alte sisteme, posibilitatea de autoclasterare, colectarea de poziții în Yandex și Google și multe altele.
- Just-Magic - Serviciu online multifuncțional pentru realizarea de nucleu, de creație, de testare a calității textului și alte funcții. Serviciul gratuit, pentru muncă cu drepturi depline, trebuie să plătiți o taxă de abonament.
Vă mulțumim că ați citit articolul. Datorită acestui manual pas cu pas, puteți face un kernel semantic al site-ului dvs. pentru a promova în Yandex și Google. Dacă aveți întrebări la stânga - întrebați în comentarii. Mai jos sunt bonusuri.
Kernelul semantic este o temă drăguță, nu? Astăzi o vom rezolva împreună prin colectarea semanticii în această lecție!
Nu crede? - Uită-te la tine - este suficient doar să conduci în Yandex sau la Fraza Google nucleul semantic al site-ului. Cred că astăzi voi rezolva această greșeală enervantă.
Dar de fapt, ce este pentru tine - semantica perfectă? S-ar putea să credeți că pentru o întrebare stupidă, dar, de fapt, el este complet nehall, cel mai mult de maeștri web și proprietarii de site-uri consideră că pot face kerneluri semantice și că orice școală va face față tuturor acestor lucruri, da, ei înșiși încearcă să-i învețe pe ceilalți ... Dar, de fapt, totul este mult mai dificil. Odată ce m-am întrebat - ce ar trebui să fac la început? - site-ul și conținutul sau sEZ Kernel., și a cerut unei persoane care nu se consideră un nou venit în CEO. Aici această întrebare Și lasă-mă să înțeleg toată dificultatea și ambiguitatea acestei probleme.
Kernelul semantic este baza fundației - prima cameră care stă înainte și începe campanie publicitara în internet. Împreună cu aceasta, semantica site-ului este cel mai viguros proces care va necesita o mulțime de timp, dar cu mai mult vă mulțumesc în orice caz.
Ei bine ... Să creăm a lui împreună!
Prefață mică
Pentru a crea un câmp semantic al site-ului, vom avea nevoie de un singur program - Colector cheie.. Pe exemplul colectorului, voi da seama de un exemplu de colectare a unui grup mic. Pe lângă program plătit, Există, de asemenea, analogi complementați precum Slobel și alții.
Semanticile colectate în mai multe etape de bază, printre care ar trebui alocate:
- brainstorming - Analiza frazelor de bază și instruirea parsului
- parsing - Extinderea semanticii de bază bazată pe Vordstat și alte surse
- deschiderea - scăparea după parsare
- analiza - Analiza frecvenței, sezonalității, concurenței și altor indicatori importanți
- rafinarea - gruparea, separarea frazelor comerciale și informative nucleului
Despre cea mai mare etape importante Colecția și va fi discutată mai jos!
Video - Compilarea kernelului semantic al concurenților
Brainstorming Când creați un kernel semantic - creier de tulpină
În această etapă este necesar în minte pentru a face o selecțiemiezul semantic al site-ului și vine cu cât mai multe fraze posibil sub subiectul nostru. Deci, lansați colectorul Kay și alegeți wordstat parsare, așa cum se arată în Screenshot:

Avem o fereastră mică, unde trebuie să introduceți un maxim de fraze pe subiectul nostru. Așa cum am spus deja, În acest articol vom crea un exemplu de set de fraze pentru acest blogAstfel, frazele pot fi după cum urmează:
- blogul SEO.
- blogul SEO.
- blog despre SEO.
- blog despre SEO.
- promovare
- promovare proiect
- promovare
- promovare
- promovarea blogurilor
- promovarea blogului
- promovarea blogului
- promovarea blogului
- articole de promovare
- promovarea activată
- miralinks.
- lucrează în SAP.
- cumpărați link-uri
- achiziționarea de link-uri
- optimizare
- optimizarea paginii
- optimizarea internă
- promovare independentă
- cum de a promova o resursă
- cum să vă promovați site-ul
- cum să promovați singur site-ul
- cum să promovați singur site-ul
- promovare independentă
- promovare gratuită
- promovare gratuită
- optimizare motor de căutare
- cum de a promova site-ul în Yandex
- cum de a promova site-ul în Yandex
- promovarea sub Yandex.
- promovarea sub Google.
- promovarea în Google
- indexare
- indexarea accelerației
- selectați site-ul donatorului
- donator checkout.
- promovarea Postov.
- utilizarea mesajelor
- promovarea blogului
- algoritmul Yandex.
- actualizați Titz.
- căutați actualizarea bazei de date
- updiet Yandex.
- legături pentru totdeauna
- referințe eterne
- Închiriați legături
- referință de închiriere
- legături cu plată lunară
- compilarea nucleului semantic
- promovarea secretelor
- promovarea secretelor
- secretele SEO.
- optimizarea secretelor
Cred că este suficient, deci o listă de pe podeaua paginii;) În general, ideea este că, în prima etapă, trebuie să analizați industria noastră pentru a maximiza și a alege cât mai multe fraze care reflectă subiectul site-ului. Deși dacă ați ratat ceva în această etapă - nu disperați - expresii artificiale vor apărea în mod necesar în următoarele etapeTrebuie doar să faceți o mulțime de muncă suplimentară, dar nimic teribil. Luăm lista și copiam la colectorul cheie. Apoi, faceți clic pe buton - Poule cu yandex.wordstat.:
Parsingul poate dura mult timp, așa că ar trebui să fii răbdător. Kernel-ul semantic este de obicei de 3-5 zile, iar prima zi veți merge la pregătirea kernelului semantic de bază și parsarea.
Despre cum să lucrați cu o resursă, cum să alegeți cuvintele cheie Am scris o instrucțiune detaliată. Și puteți afla despre promovarea site-ului pe cererile NF.
În plus, voi spune că în loc de brainstorming, putem folosi semantica concurenților cu unul dintre serviciile specializate, de exemplu, Spywords. În interfața acestui serviciu, pur și simplu introducem cuvântul cheie de care aveți nevoie și vedeți principalii concurenți care sunt prezenți pe această expresie în partea de sus. În plus, semantica site-ului oricărui concurent poate fi complet descărcată cu acest serviciu.

Apoi, putem alege oricare dintre ele și să-i scoatem cererile care vor fi lăsate de la gunoi și să folosească ca semantică de bază pentru parsare ulterioară. Sau putem face acest lucru chiar mai ușor și mai folosit.
Curățarea semanticii
De îndată ce parsarea Wordstat se oprește complet - este timpul să tăiați kernelul semantic. Această etapă este foarte importantă, așa că ar trebui să o luăm cu atenție.
Deci, parsingul meu sa încheiat, dar frazele s-au dovedit MulteȘi, prin urmare, cuvintele cuvintelor pot să ne ia prea mult. Prin urmare, înainte de a continua definiția frecvenței, este necesar să se producă curățenia primară a cuvintelor. O vom face în mai multe etape:
1. Interogările filtrate cu frecvență foarte scăzută
Pentru a face acest lucru, se bazează pe simbolul de sortare în frecvență și începe să extragă toate cererile care au frecvențe sub 30:
Cred că cu acest element puteți face cu ușurință.
2. Îndepărtați nu este adecvată în sensul sensului
Există astfel de interogări care au o frecvență suficientă și o concurență scăzută, dar ei deloc nu sunt potrivite pentru subiectul nostru. Astfel de taste trebuie îndepărtate înainte de a verifica obiectivele exacte ale cheii, deoarece Verificarea poate dura mult timp. Vom șterge astfel de chei pe care le vom face manual. Deci, pentru blogul meu, nu au fost inutile:
cursuri de optimizare a motoarelor de căutare vânzarea site-ului de promovare
Analiza nucleului semantic
În această etapă, trebuie să determinăm frecvența exactă a cheilor noastre, pentru care trebuie să faceți clic pe simbolul de lupă, după cum se arată în imagine:

Procesul este destul de lung, astfel încât să puteți merge și să vă faceți ceai)
Când cecul a avut succes - este necesar să continuați să curățați kernelul nostru.
Vă sugerez să eliminați toate cheile cu frecvență mai mică de 10 cereri. De asemenea, pentru blogul dvs., șterg toate solicitările care au valori peste 1.000, deoarece încă nu planific pe astfel de solicitări.
Exportul și gruparea kernel-ului semantic
Nu credeți că această etapă va fi ultima. Deloc! Acum trebuie să transferăm grupul rezultat la exel pentru o vizibilitate maximă. Apoi, vom sorta paginile și apoi vom vedea multe deficiențe, corectarea și vom face față.
Semantica exportată a site-ului în Exel este complet ușoară. Pentru a face acest lucru, trebuie doar să faceți clic pe caracterul corespunzător, după cum se arată în imagine:
După introducerea la Exel, vom vedea următoarea imagine:

Coloanele marcate cu roșu trebuie îndepărtate. Apoi creați o altă masă în exel, unde va fi conținut kernelul final semantic.
Noul tabel va fi 3 coloane: URL.pagini, fraza de cuvinte cheie si el frecvență. Ca o adresă URL, selectați sau deja o pagină sau o pagină existentă care va fi proiectată în perspectivă. Pentru a începe, să alegem cheile pentru pagina principală a blogului meu:

După toate manipulările, vedem următoarea imagine. Și sugerează imediat câteva concluzii:
- astfel de interogări de frecvență, ca trebuie să aibă o coadă mult mai mare din fraze mai mici de frecvență decât vedem
- Știri SEO
- noua cheie a apărut, pe care nu am luat-o mai devreme - articole din CEO.. Trebuie să analizeze această cheie
Așa cum am spus, nici o cheie de la noi ascunde. Următorul pas pentru noi va fi brainstormingul acestor trei fraze. După brainstorming, repetăm \u200b\u200btoți pașii pornind de la primul element pentru aceste chei. Puteți să vă par prea mult timp și să vă plictisiți, dar este, este - compilarea nucleului semantic este o lucrare foarte responsabilă și minuțioasă. Dar, secta compusă competent va ajuta foarte mult la promovarea site-ului și poate fi foarte mult pentru a vă salva bugetul.
După toate încasările, am reușit să obținem cheile noi pentru pagina principală a acestui blog:
- cel mai bun blog SEO.
- Știri SEO
- articole SEO.
Și alții. Cred că tehnica este de înțeles pentru tine.
După toate aceste manipulări, vom vedea ce pagini ale proiectului nostru trebuie modificate () și ce pagini noi trebuie să adauge. Cele mai multe chei găsite de noi (cu frecvență de până la 100 și uneori mult mai mari) pot fi promovate cu ușurință singure.
Turnarea finală
În principiu, miezul semantic este aproape gata, dar există un alt frumos un punct importantCare ne va ajuta să îmbunătățim considerabil grupul nostru de familie. Pentru asta avem nevoie de Seopult.
* De fapt, puteți utiliza oricare dintre serviciile similare care vă permit să învățați concurența cu cuvinte cheie, de exemplu, Mutagen!
Deci, creăm o altă masă în Exel și copiați numai numele cheie acolo (coloana medie). Pentru a nu petrece mult timp, voi copia doar cheile pentru pagina principală a blogului dvs.:


Apoi verificați costul obținerii unei tranziții la cuvintele noastre cheie:
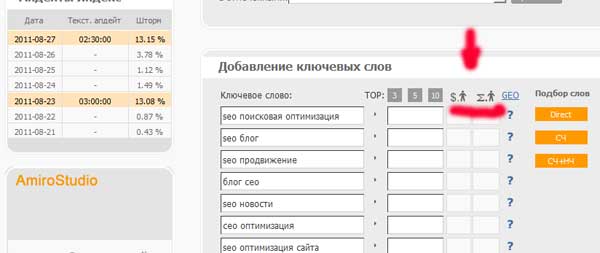
Costul tranziției la unele fraze a depășit 5 ruble. Astfel de fraze trebuie excluse de la kernelul nostru.

Poate că preferințele dvs. vor fi oarecum diferite, atunci puteți exclude fraze mai puțin costisitoare sau viceversa. În cazul său, am șters 7 fraze.
Informații utile!
În funcție de pregătirea kernel-ului semantic, cu accent pe screening-ul celor mai scăzute cuvinte cheie competitive.
Dacă aveți magazinul dvs. online - citit , unde este descris modul în care poate fi utilizat miezul semantic.
Clustering de kernel semantic
Sunt sigur că ați avut anterior acest lucru pentru a auzi acest cuvânt ca fiind aplicat promoției de căutare. Să ne dăm seama ce fel de fiară este așa și de ce este necesar atunci când promovați site-ul.
Modelul de promovare a căutării clasice arată astfel:
- Selectarea și analiza interogărilor de căutare
- Gruparea interogărilor pe paginile site-ului (pagini de aterizare)
- Pregătirea textelor SEO pentru paginile de destinație bazate pe un grup de interogări pentru aceste pagini
Pentru a facilita și a îmbunătăți a doua etapă din lista de mai sus și servește drept clustering. În esență, grupul este o metodă software care servește la simplificarea acestei etape atunci când lucrați cu semantica mare, dar totul nu este atât de simplu încât poate părea la prima vedere.
Pentru o mai bună înțelegere a teoriei clusteringului, ar trebui să faceți o excursie mică în istoria SEO:
În mod literal cu câțiva ani în urmă, când termenul de grupare nu a privit pentru fiecare colț - Sienes, în majoritatea covârșitoare a cazurilor, grupate de semantica cu mâinile lor. Dar când grupați o mare semantică în 1000, 10 000 și chiar 100.000 de cereri, această procedură sa transformat într-o relație reală pentru o persoană obișnuită. Și apoi metodologia pentru grupul de semantică a început să utilizeze peste tot (și astăzi mulți folosesc această abordare). Tehnica de grupare semantic implică combinarea într-un grup de interogări care au relații semantice. Ca exemplu - cererile "Cumpărați mașină de spălat"Și" cumpărați o mașină de spălat la 10.000 "combinată într-un singur grup. Și totul ar fi bine, dar aceasta metoda conține o serie de probleme critice și pentru înțelegerea lor este necesar să se introducă un nou termen în narațiunea noastră, și anume - " cererea de intenție”.
Cea mai ușoară modalitate de a descrie acest termen poate fi ca nevoie de utilizator, dorința lui. Introvent nu este altceva decât dorința utilizatorului care intră în interogarea de căutare.
Baza grupării semanticii este aceea de a colecta într-un grup de cereri care au aceeași intenție sau cât mai aproape posibilă intensitate, iar aici 2 trăsături interesante apar imediat, și anume:
- Aceeași intenție poate avea mai multe cereri care nu au nici o proximitate semantică, de exemplu - "Service auto" și "Înscrieți-vă"
- Cererile care au o proximitate semantică absolută pot conține Intensis diferit radical, de exemplu, situația manualelor este "telefonul mobil" și "telefoanele mobile". Într-un caz, utilizatorul dorește să cumpere un telefon, iar în altul pentru a viziona un film
Deci, gruparea semanticii în corespondența semantică nu ia în considerare intensitățile solicitărilor. Și grupurile întocmite în acest mod nu vă vor permite să scrieți textul care va cădea în partea de sus. În timpul grupului de mână pentru a elimina această neînțelegere, băieții cu profesia "prudială Specialist SEO»A analizat emiterea cu mâinile.
Esența clusteringului este o comparație a emiterii formate a motorului de căutare în căutarea regulațiilor. Din această definiție, trebuie să luați imediat o notă că gruparea însăși nu este adevărul în ultima instanță, deoarece emiterea formată nu poate dezvălui intenția pe deplin (în baza Yandex poate fi pur și simplu un site care combinat corect cererile grupul).
Mecanica de clustering sunt simplă și arată astfel:
- Sistemul intră alternativ în toate cererile depuse la acesta eliberarea de căutare și își amintește rezultatele topului
- După o contribuție alternativă de solicitări și mențineți rezultatele, sistemul caută o intersecție în extrădare. Dacă același site este același document (pagina site-ului) se află în top imediat în mai multe cereri, atunci aceste solicitări teoretic pot fi combinate într-un singur grup
- Acesta devine relevant un astfel de parametru ca un grup de grupare, care vorbește sistemul, cât timp trebuie să existe intersecții pe care cererile le pot adăuga la un grup. De exemplu, puterea grupului 2 înseamnă că cel puțin două intersecții ar trebui să fie prezente în extrădarea a 2 minute. De asemenea, mai ușor - cel puțin două pagini din două site-uri diferite ar trebui să fie prezente simultan în partea de sus unul câte unul și o altă cerere. Exemplu de mai jos.
- La gruparea semanticii mari, logica legăturilor dintre cereri este relevantă, pe baza căreia există 3 tipuri de bază de grupare: moale, mijlocie și greu. Vom vorbi în continuare despre tipurile de clustering în următoarele înregistrări ale acestui jurnal.
Cum se face o componentă de informații a site-ului, astfel încât clienții să poată găsi rapid
Deci, ați decis să creați un portal pe care oamenii ar putea găsi informații interesante, dar știți că avem nevoie de anumite abilități pentru a promova, și anume, compilarea kernel-ului semantic. Dar semantica sugerează doar că site-ul va fi umplut cu semnificație. Prin urmare, va fi spus aici cum să ucizi două iepuri la o dată - și să atrageți publicul pentru informații utile și să nu forțați motoarele de căutare "jura".Abordarea veche și nouă a completării informațiilor despre site și a kernel-ului semantic
Crearea unui site, în primul rând, trebuie să știți ce sunt interesați de utilizatori și cum caută informații - la urma urmei, aceleași date pot fi găsite în mod diferit. Și este, de asemenea, necesar să se țină seama de interesele utilizatorului - deoarece, deoarece toate informațiile care vor fi prezentate în site-ul dvs. ar trebui să fie interesante pentru orice cititor, atunci oamenii trebuie să fie implicați în lectură. Și fără motoarele de căutare, nu este necesar să faceți - Yandex și Google pur și simplu nu vor "accepta" portalul pentru dvs. dacă o serie de condiții sunt executate.În special, dispersarea cuvintelor cheie, a cărei fraza de căutare este compusă pe întregul portal. Prin urmare, este important să umpleți textul încărcăturii semantice. Nu este nimic mai mult decât un miez semantic (semantic) - o combinație de cuvinte și fraze care reflectă orientarea tematică și structura resurselor Internet. În general, semantica este o diviziune a lingvistică, care explorează conținutul semantic al unităților (elementelor) limbii. Toată lumea, probabil, au văzut astfel de expresii pe site-uri ca "personajul principal îi ajută pe prieteni să vizioneze filme online pentru a nu deveni victime ale ticălosului" (expresia aproximativă, esența, sper, este de înțeles). Aici, utilizatorul vede clar că există un cuvânt cheie "vizionați filme online", dar nu este făcut pentru el, ci pentru motorul de căutare. Ca rezultat, el se poate simți înșelat - nu este nevoie să se rostogolească la așa, nimic bun îl va aduce. Textul competent cu introducerea kernel-ului semantic va fi perceput mult mai bine.
Pentru ca utilizatorul să poată găsi o resursă pe Internet, puteți utiliza în două moduri:
- În primul rând, analizați interogările de căutare ale clienților, care urmează să facă ca structura portalului (semantic sau semantic, kernelul, în acest caz îndeplinește valoarea decisivă în cadrul și structura resurselor);
- mai întâi, efectuați un plan cu privire la modul în care va arăta structura site-ului, înainte de a trece la analiza a ceea ce sunt interesați de utilizatorii (kernelul semantic este distribuit deja pe cadrul portalului finit).
Prima abordare implică adaptarea la condițiile actuale - și această opțiune funcționează cu adevărat. În acest caz, structura resurselor este rezumată sub cuvintele cheie și rămâne obiectul. A doua opțiune este ca și în melodia mașinii de timp "Nu trebuie să fiți hrăniți pentru o lume schimbătoare - într-o zi el va conduce sub noi". Folosind această abordare, omul de afaceri însuși alege că dorește să spună potențialilor utilizatori. Această abordare poate fi numită un fel de proactivă - și omul de afaceri în acest caz va deveni subiectul.
Este important să înțelegem că obiectivul principal al marketingului și al afacerilor este accentul pe client. Iar a doua metodă o oferă doar. Adică, un antreprenor sau un comerciant decide ce date ar trebui să fie dat publicului folosind portalul său - și, bineînțeles, ar trebui să fie deținute de unele cunoștințe despre ceea ce va fi spus pe site-ul său. Prin urmare, mai întâi planifică un design exemplar al resurselor, o listă preliminară de pagini și apoi analizează modul în care utilizatorul caută informațiile de care aveți nevoie. Și cu ajutorul conținutului de informații al resursei, este responsabil pentru întrebările pe care utilizatorul le specifică motorul de căutare.
Prima opțiune este metoda "celebrul". Avea mult timp să conducă și să o aplice acum. Cu această metodă, au existat fraze cheie pentru care creatorul site-ului a vrut pur și simplu să ajungă la vârful motorului de căutare, iar apoi structura resurselor și cheile au fost create pe toate paginile. Conținutul de informații a fost optimizat sub cuvinte și fraze cheie.
Dar această metodă în practică arată că, poate motorul de căutare este înșelat, dar oamenii nu. Valoarea informațională a resurselor Falls - Oamenii nu sunt interesați să citească textele pentru care pot fi urmărite cuvintele cheie, el crede undeva înșeală. Dar marketingul nu este creat nu de dragul acestei tendințe de afaceri, iar omul de afaceri alege ce să vorbească cu utilizatorii. Marketingul nu ar trebui să "danseze sub Dudka altcuiva", altfel audiența încetează să-l respecte - trebuie să formeze mediul în sine, dar în același timp să fie orientat spre client. Nici, nici altceva, nu există o abordare "spermă" și de aceea este indignat.
Între timp, unele dintre întrebările potențiale pentru motorul de căutare și aici, de asemenea, pot fi înțelese, pentru că există o mare competiție pe internet astăzi. În plus, site-urile sunt umplute cu tastele care "iubesc" motoarele de căutare.
Rezultatul planificat al construirii kernel-ului semantic este o listă a interogărilor cheie care sunt dispersate pe paginile portalului. Acesta include adresa URL a paginilor, solicită indicarea frecvenței.
Designul site-ului
Structura sau designul, Resursa Internet este un fel de schemă ierarhică sau rang, pagină web. Prin crearea acesteia, aceste sarcini sunt rezolvate ca:- Planificarea unei strategii de informare și a unei structuri de informare către utilizator;
- Asigurarea conformității instrucțiunilor de portal ale motoarelor de căutare;
- Garanția resurselor ergonomice pentru client.
Pentru a face acest lucru, puteți folosi tot ceea ce este convenabil - chiar și MS Word sau vopsea, îl puteți desena de la mână sau pe o tabletă cu un stilou. La planificarea structurii, trebuie să răspundeți pentru 2 întrebări:
- Ce informații vă place un om de afaceri pe care doriți să îl transmiteți clienților;
- Unde să publice unul sau alt conținut.
Dacă luați un mic design portal de cofetărie ca exemplu, acesta va include pagini de informație (rețete, istoric de tort), articole și catalogul de bunuri (Showcase). Dacă trimiteți acest lucru sub formă de schemă, poate arăta astfel:
Schema ierarhică a site-ului
Apoi, designul este întocmit sub forma unei mese. Aceasta indică ierarhia, pagina de nume este indicată, coloanele cu cuvinte cheie și frecvența acestora sunt activate, precum și indicând adresele adreselor adreselor paginilor. Dacă trimiteți un tabel de proiectare a site-ului de cofetărie, acesta poate fi următorul:

Acesta este modul în care structura (proiectarea) resurselor Internet poate fi trimisă ca tabel
Pentru a începe cu, știm doar "titlurile de pagină" și " Legendă", Și" URL "," chei "și" frecvență "vor fi completate mai târziu.
Cuvinte cheie
Este important să înțelegeți ce cuvinte cheie sunt și care interogări de căutare se aplică clienților - fără aceasta, nu vor exista o creare eficientă a site-ului și prezentarea informațiilor utilizatorilor. Puteți aplica unul dintre serviciile pentru a selecta cuvintele cheie - dar este important să înțelegeți că aceste cuvinte sunt adecvate.Deci, cheile sunt cuvinte sau fraze folosite de utilizatori pentru a găsi informațiile dorite și de informare. Un exemplu simplu este de a pregăti o plăcintă, intră într-un sistem de solicitare "Apple Charpeck Rețetă cu o fotografie" în motorul de căutare.
Cheile pot fi împărțite în mai multe grupuri:
În funcție de popularitate, alocați:
- Cererile cu frecvență joasă (sunt prezentate 100-1000 / lună);
- Frecvența medie (impresiile de 1.000-5.000);
- Frecvență înaltă (cereri de 5.000-10.000 de fotografii pe lună).
În funcție de nevoile clienților variază:
- Informații (dacă utilizatorul trebuie să găsească orice informație - de exemplu, "Cum să curățați hainele din Fuccină", \u200b\u200b"care vitamine îmbunătățesc starea pielii");
- Tranzacțional (interogări emise pentru a face o înțelegere, dar fără a specifica un anumit site sau magazin - "Cumpărați o canapea", "descărcare joc", "face o cerere de credit");
- Navigare (dacă clientul dorește să găsească informații despre un anumit site - de exemplu, "WebMoney pentru a crea o carte", urmăriți codul de cale al Whitepoche "," reduceri Euroopt ");
- Altele (dacă este dificil să se determine ceea ce dorește utilizatorul - de exemplu, introducerea expresiei "creier", nu este clar că o persoană vrea să știe - structura, organul, fapte interesante Despre el, și în plus, nu este clar ce fel de creier este despre dorsal sau cap).
Acum pentru fiecare element. Diferența de evaluare a popularității depinde de modul în care este clar din context, dacă utilizatorii sunt populari cu popularitatea uneia sau a unei alte teme. Decizia condiționată, unii experți definesc un număr mai mic de hit-uri pentru solicitări. Un exemplu este următorul caz: pentru site-ul care tranzacționează cu smartphone-uri, cererea "de a cumpăra telefonul Samsung."Frecvența a arătat 6000 / lună - cea de frecvență medie. În același timp, pentru clubul sportiv, cererea "Thai Boxing Training" cu o frecvență de opinii în 1.000 de solicitări este de înaltă frecvență.
Toate acestea trebuie luate în considerare și proiectarea unui kernel semantic extrem de răspândit și ar trebui îmbogățit din cauza frazelor de frecvență redusă, deoarece, dacă credeți că statisticile, atunci de la 60% la 80% din toate solicitările utilizatorului pot fi atribuite low- frecvență. Adică, deoarece resursele principale care vă permite să atrageți clienți potențiali la site, ar trebui să se utilizeze tastele de frecvență redusă - acesta este un fel de cuvinte cheie înguste-direcționale. Trebuie să le diluați cu cereri de înaltă și la jumătatea frecvenței.
Pentru a utiliza în mod eficient cel de-al doilea grup, conform căruia se disting cuvintele cheie, este necesar, în primul rând, atunci când distribuie cheile pe pagini sau la crearea unui plan de umplere a informațiilor pentru a ține seama de nevoile clienților. Adică articole în care utilizatorul va fi furnizat cu informații, trebuie să răspundă la întrebările lor. Aceasta este o mare parte din frazele cheie fără o anumită intenție - adică în articolele cu articol, nu trebuie să introduceți cuvintele "cumpăra", "descărcare" și altele asemenea. Secțiunile "Magazin", "Catalog" Catalog IL "Storefine" sunt încurajate să satisfacă cererile de tranzacționare ale utilizatorilor.
Ar trebui să se țină cont de faptul că majoritatea cererilor de tranzacție sunt comerciale. În consecință, hotărând să vândă prăjituri, va trebui să concureze cu "tort Moscova", "Dobryninsky și parteneri" și "Viennese Shop" - cel mai mult producători mari cofetărie. Dar dacă folosim cu competent recomandările de mai sus, totul devine mult mai ușor. Extindeți cât mai mult posibil kernelul de text semantic și reduceți frecvența interogării. De exemplu, frecvența cererii "de a cumpăra un tort american de ruble" în frecvență va fi mai mică decât "cumpăra tort american".
Clădirea interogărilor de căutare
Fraza este conceptul general.care include privat. Deci, cu frazele pentru căutare - includ corpul, specificatorul și coada. De exemplu, luând o interogare de căutare "tort" ca bază, nu putem înțelege ce are nevoie de utilizator este de a determina produsele de cofetărie, cumpărând-o sau doar imagini. Cererea însăși este o frecvență ridicată, ceea ce înseamnă o concurență ridicată în furnizarea de rezultate. În plus, introducerea interogării va aduce o mulțime de apeluri către site-ul clientului, care nu este interesat de obținerea informațiilor pe care le furnizați și acest lucru va afecta negativ factorul comportamental. Și toate pentru că o astfel de cerere conține numai corpul.Dacă introducem un add-on sub forma cuvântului "cumpăra", obținem includerea și specificatorul - ceea ce determină intenția clientului. Puteți înlocui cuvântul "cumpăra" la "rețetă", iar apoi o astfel de solicitare va deveni informație și dacă introduceți "prăjituri în tort I Love", atunci o astfel de întrebare va fi navigație. Prin urmare, este de la specificator că cheia afectează cuvintele cheie la unul sau la alt tip de cuvinte cheie.
Uneori puteți întâlni acest lucru, utilizatorul, dorind să vândă un anumit lucru, introduce cererea de a "cumpăra" pentru a vedea unde oamenii cumpără acest subiect cel mai mult.

Dacă introduceți fraza "Cumpărați un tort în Moscova" sau "cumpărați un tort la comandă", atunci ultima parte a interogării de căutare este coada. El clarifică doar câteva detalii cu privire la modul în care clientul intenționează să facă acest lucru. Deci, dacă clientul trebuie să cunoască un anumit magazin, cererea va deveni navigație.
Structura cadrului pentru căutare
Dacă aruncăm o privire la următoarele exemple: "Cumpărați un tort de acasă în Alma-Ata", "Rețeta Cake Napoleon", "Cumpărați o tort de livrare", vom vedea că în fiecare situație există un anumit scop al utilizatorului, iar coada specifică doar detaliile.Prin urmare, pentru kernelul semantic, principala terminologie asociată cu serviciile și bunurile va fi prezentată pe portal sau cu activități antreprenoriale și nevoile clienților. Deci, dacă o persoană are nevoie de un produs de cofetărie, acesta va fi interesat de prăjituri, marshmallows și un gunoi, marshmallow, vafe, cookie-uri, meringue, cupcakes etc. Acesta este corpul interogare cheie. Și apoi găsiți specifice și cozi. Datorită frazelor cu "cozi", aveți și creșteți acoperirea și, în același timp, devine mai puțin "concurenți de căutare".
Resurse pe Internet pentru a face un kernel semantic (selectarea valorilor cheie)
Pentru a colecta cuvinte cheie pentru site-ul dvs., există mulți asistenți care facilitează viața unui om de afaceri. Sunt plătite, care sunt necesare dacă site-ul este uriaș sau setat, și gratuit, potrivit pentru un portal mic, opțiuni.În articol, luăm în considerare următoarele resurse:
- Keycollectorul (plătit);
- Slovoeb (gratuit);
- Wordstat de la Yandex'a (gratuit);
- AdWords de la Google (gratuit).
Colector cheie.
Acesta este un instrument plătit cu mai multe funcții. Acesta automatizează operațiunile necesare pentru a construi kernelul semantic. Puteți, bineînțeles, să utilizați analogii liberi ai programului, dar pentru acest lucru utilizează mai multe resurse de Internet simultan, deoarece acest program nu are aproape nimic limitat. În plus, acest serviciu Este pur și simplu indispensabilă dacă dețineți un site sau nu este folosit pentru a vă asigura că totul se potrivește într-un singur program, pentru a nu căuta resurse terțe, precum și dacă aveți mai multe site-uri sau în conținutul semantic are nevoie de un mare site-ul.Acesta oferă următoarele caracteristici:

Aici arată ca keycollectorul
Slovoeeb.
Acest serviciu este gratuit. Dezvoltatorii sunt aceiași care au creat programul Colector cheie. Pentru ca programul să utilizeze programul, trebuie să specificați autentificarea din contul suplimentar al direcției. Acest lucru se datorează faptului că Yandex poate bloca contul datorită interogărilor automate, deci nu utilizați cea principală.Resursele oferă următoarele caracteristici:
- Colectarea cuvintelor cheie prin Wordstat;
- Solicitări de filtrare pentru o frecvență ridicată;
- Analiza sintaxă a solicitărilor de căutare.

Interfața Slovoveeb.
Cum funcționează programul? Pentru a începe, creând un nou proiect. Selectați "Adăugați fraze" - aici sunt frazele care utilizează clienții pentru a căuta informații despre un anumit produs.

Adăugarea unei fraze de căutare la program
În meniul "Colectarea cuvintelor și statistici", selectați elementul dorit și porniți serviciul. De exemplu, dacă aveți nevoie să colectați fraze cheie, alegeți această opțiune.

Determinarea frecvenței frazei cheie
Wordstat (Serviciul Yandex)
Aceasta este o resursă gratuită pentru selecție și analiză. fraze de căutare. Este necesar ca dacă sunteți gata să analizați și să clasificați manual interogările. Serviciul oferă următoarele opțiuni:- Afișează informații despre spectacole și solicitări pentru cuvinte cheie, expresii de căutare, în timp ce analizează atât datele generale, cât și cele mobile (adică puteți vedea cât de popular este cererea pe dispozitivele mobile);
- Demonstrarea statisticilor pe regiune;
- Afișarea datelor privind popularitatea unei cereri specifice de timp ("Istoricul interogării");
- Afișarea expresiei sau a cererii numai în formularul specificat (pentru aceasta este necesar să puneți fraza în citate);
- Se afișează statistici exclusiv cuvintele de oprire (înainte de acest cuvânt trebuie să puneți minus astfel încât să nu fie luată în considerare);
- Demonstrarea datelor din utilizarea pretextului selectat (în acest caz, înainte de a fi pusă "+");
- Afișarea informațiilor la categoria de solicitare (pentru acest grup de solicitări trebuie să fie etichetate în paranteze, și opțiuni cheie - pentru a separa slash direct "|": adică într-un timp scurt pentru a obține date la cerere "Tort de comandă", "Cumpărați a Tort "," comanda un kappekyk "," cumpăra cape "," comenzi plăcintă "și" cumpărați plăcintă ", urmați instrucțiunile, după cum se arată mai jos în imagine);
- Afișează date despre solicitări cu referire la anumite zone.

Cerere de "capcheeys", statistici generale

Datele despre cheie pe regiune

Aici puteți vedea când cererea a fost cea mai sau mai puțin populară.

Care prezintă fraze în forma specificată

Cuvânt cheie fără cuvânt de cuvinte

Statistici, excluzând cuvintele de oprire

Datele privind șase cereri imediat - un lucru confortabil dacă aveți nevoie să obțineți rapid informații

Dacă alegeți o anumită regiune, puteți vedea ce este popular acolo
Google AdWords (programator de cuvinte cheie de la Google)
Dacă într-o anumită regiune, Google conduce semnificativ, este mai bine să utilizați acest serviciu. Este proiectat doar pentru a calcula nevoile utilizatorilor acestui motor de căutare. Serviciul este gratuit, dar există servicii plătite (de exemplu, pentru anunțuri).Instrumentul oferă următoarele caracteristici:
- Colectarea informațiilor despre interogările de căutare;
- Dezvoltarea de noi combinații de solicitări și prognoza relevanței și dinamicii acestora.
Pentru a obține statistici privind solicitările specifice, trebuie să alegeți această opțiune pe pagina principală instrument. Va trebui să introduceți frazele de interes și să încărcați un fișier în format CSV, apoi selectați regiunea prin care sunt necesare statistici, puteți specifica, de asemenea, cuvinte de oprire (așa cum este descris în Wordstat). Totul este gata - puteți face clic pe tasta "Aflați numărul de solicitări".

Informații despre solicitările Google
Servicii care oferă servicii de analiză
De asemenea, puteți utiliza analiștii Google Analytics sau metrici dacă aveți nevoie să construiți un kernel semantic pentru o resursă existentă. Aceste instrumente ajută la desemnarea frazelor pentru căutarea clienților.
Aici puteți găsi, de asemenea, inspirație pentru formarea cuvintelor cheie.
În plus, datele privind frazele comune pentru găsirea de clienți în acest sens sau că informațiile pot fi verificate utilizând cabinetul pentru Yandex și Webmasterii Google. Ultimele date sunt situate în consola de căutare, atunci trebuie să mergeți la analiza "Căutați traficul de căutare".
Webmaster Yandex propune utilizarea secțiunii "Cercetări de căutare - Cereri populare".
Instrumente pentru analiza site-urilor concurenților
Site-urile concurente sunt o altă resursă în care puteți căuta inspirație pentru a căuta cuvinte cheie. Pentru a le desemna, este logic să le citiți publicația sau să verificați textul utilizând eticheta HTML Keywod utilizând codul programului Web Page. Sau advego cu ISTIO pentru a vă ajuta.
Interfața ISTIO.
Dacă aveți nevoie să analizați întregul portal concurent, puteți utiliza următoarele instrumente:
Acum mai mult pentru fiecare element.
Pentru a determina tastele principale, vor trebui să înregistreze, este posibil să faceți acest lucru pe o foaie de hârtie și să utilizați programe de calculator. Veți avea nevoie de ideile tuturor colegilor - trebuie să înregistreze totul fără excepție: fiecare se poate dovedi a fi "Graveyla", care vă va atrage clienți.
Lista poate arăta astfel:

Exemplu lista de fraze pentru căutare
În această listă, aproape toate cheile sunt de înaltă frecvență, fără specificitate. Frazele cu frecvențe medii și joase vor permite același lucru pentru a extinde kernelul. Așa că du-te la următoarea etapă.
Aici această dificultate este rezolvată utilizând un instrument pentru selectarea cuvintelor cheie. De exemplu, puteți alege serviciul Yandex - este unul dintre cele mai confortabile, în ciuda complexității inițiale aparente. Aici puteți face o legare la o anumită regiune dacă oferiți un produs sau un serviciu într-un anumit obiect geografic.
Deci, în acest stadiu, analizăm toate cheile compilate de colegi.

Analiza cererii principale
Ar trebui să copiați frazele din coloana din stânga a serviciului și să introduceți în tabel. Acum, trebuie să vă concentrați pe coloana dreaptă a asistentului - aici Yandex oferă fraze pe care vizitatorii le-au folosit împreună cu fraza principală. Deci, aici aveți ocazia să alegeți tastele potrivite și să le copiați în coloana din stânga. Nu vă faceți griji dacă ceva nu este potrivit - aceste fraze sunt excluse la etapa finală. Și ea este deja aproape ca iarnă în "Jocul Tronurilor".
Rezultatul acestei faze va fi o listă compilată de fraze pentru căutarea, care va fi din fiecare cheie principală. În acest stadiu, pot fi obținute sute și chiar mii de solicitări diferite.

Lista frazelor
Du-te la stadiul de închidere. Indiferent cât de ușor pare - nu este. Aceasta este cea mai consumatoare de timp și provocatoare cu miezul. Este necesar să excludem manual din nucleul semantic că nu îl potrivește în sens.
Dar nu trebuie să eliminați cheile de frecvență redusă - în nici un caz. Optimizatorii "veche școală" lasă și apoi consideră că această cheie este de gunoi, dar nu este necesar să se întâlnească cu acest truc. Exemplu: luarea tastei "tort dietetic" ca bază, puteți vedea că serviciul afișează pe ecranul 3 al spectacolului pe lună în regiunea Cherepovets. Metoda "numerar" implică aruncarea cheilor sale. Dar acum veți înțelege de ce nu ar trebui să faceți acest lucru - și sper acest sfat și apoi aplicați în viață.
Specialiști în domeniul SEO, pentru ca paginile lor să fie în partea de sus a motoarelor de căutare, au cumpărat fie pentru a închiria un link. În același timp, au trebuit să utilizeze anumite chei, metoda este aplicată acum. Și pot fi înțelese, deoarece fraze cu o frecvență scăzută a afișării, de regulă, nu plătesc pentru bani cheltuiți pe link.
Dar dacă te uiți la "prăjiturile dietetice" cu ochii vechii întărire, iar omul de afaceri orientat spre client poate fi descoperit caracteristici suplimentare. La urma urmei, unii dintre clienții potențiali sunt cu adevărat interesați de acest lucru - și nu în ultimul rând, sunt fete care își urmează figura. Așa că știm exact ce aceasta cerere Cineva este interesat și, prin urmare, cu o conștiință calmă poate include în miezul semantic. Dacă cofetarii din compania dvs. pregătesc un astfel de produs, acesta va veni în mod necesar la îndemâna în care vor fi descrise mărfurile. Și dacă nu - acest conținut de informații poate fi plictisitor pentru secțiunea Informații despre portal.

"Tort dietetic", care poate fi considerat gunoi, este de fapt acest lucru nu este
Ce apoi excludeți? Să ne dăm seama:
- În primul rând, sunt prezente în care sunt prezente alte mărci;
- În al doilea rând, repetarea frazelor - de exemplu, de la 3 chei "prăjituri pentru a ordona Anul Nou", "Torturi personalizate", "Tort Ordine Anul Nou", va fi o primă cheie;
- În al treilea rând, dacă nu sunteți angajat într-un astfel de lucru ca "dumping", atunci, în consecință, cheile cu introducerea cuvintelor "ieftine" și "ieftine" nu vor fi utile pentru dvs.
- În al patrulea rând, cheile cu zone nepotrivite - dacă tranzacționați numai în Cherepovets, dar nu livrați în satele din apropiere sau nu tranzacționați într-o anumită zonă a orașului, aceste date nu sunt necesare;
- Cinci, cheile cu referire la produsele pe care le știi exact ce nu va vinde și, în consecință, nu vinde;
- Și în șase, cu siguranță veți folosi fraze scrise incorect - indiferent, erori gramaticale sau greșeli - motorul de căutare va ajuta vizitatorul căutând "gbhj; yst" în loc de "prăjituri", "capketuri" în loc de "cappoxi" .
Voua-la atunci când ați detectat toate cheile care nu vă potrivesc, ați primit cheile necesare "Torturi la comandă". Cu toate celelalte trebuie să petreceți același lucru. Iar următoarea etapă va fi clasificarea frazelor pe specii.
Construirea unei hărți a conformității (relevanței) și a clasificării frazelor-cheie
Expresii pentru căutarea pe care publicul țintă va fi utilizată ca principal și va găsi datele pe care utilizatorii de pe site-ul dvs. vor fi integrate în T.N. "Clustere semantice (semantice) sunt categorii de solicitări similare conținutului semantic. Aceasta înseamnă că "clusterul de tort" include toate frazele care sunt articulate direct sau indirect cu acest cuvânt - și în acest caz, această unitate a limbii se ridică ca fiind "privată", iar toate frazele sunt "generale". Ce aveți posibilitatea de a vedea în imaginea prezentată mai jos.Vă rugăm să rețineți că clusterele celei de-a doua, a treia, a patra categorie sunt prezente aici. Temele mai extinse, cu atât mai mari nivelurile clusterului. Deși de facto este obținut astfel încât suficiente grupuri ale celui de-al doilea grup.

Niveluri de cluster.
Majoritatea clusterelor au fost definite în prima etapă a creării cuvintelor cheie. Firește, pentru că trebuie să înțelegeți pur și simplu subiectul trimis, deoarece, fără să știți nimic despre prăjituri, cu greu puteți face un nucleu semantic competent. Asistentul de a crea un cluster va servi, de asemenea, ca o schemă compilată a sitului.
Glusteringul celei de-a doua categorii este foarte important. Acest lucru ar trebui să adauge specificatori care vor indica obiectivele clienților - acest lucru este, de exemplu, cumpărați prăjituri, "Istoria creării unui tort Napoleon". Ultimul cluster este în secțiunea Informații și primul la catalog.
Acum ne întoarcem la diagrama ierarhică a paginii web și dezvoltat pe baza tabelului. "Torturile la comandă" a fost definită utilizând serviciul Yandex și ulterior nu a fost exclus din listă. Acum, această cheie ar trebui să fie dispersată între paginile partiției corespunzătoare.

Astfel, puteți dispersa fraza de căutare pe site-ul dvs.
Luați acest exemplu: există fraze în cluster pentru a căuta "prăjituri pentru a comanda temele de fotbal".

Torturi de fotbal, se dovedește, utilizatorii de interes
Și dacă produsele de cofetărie produce acest tip de produs, atunci știm ce secțiune va fi localizată această pagină. Ar trebui să fie plasat în "prăjituri din mastic", deoarece acest material este utilizat pentru a crea un astfel de produs de cofetărie. Deci, aici creăm pagina potrivită. Introducem-l în proiectarea resurselor Internet, indicând adresa URL și a frazelor de căutare cu frecvență.

Crearea unei pagini în secțiunea relevantă
Puteți vedea cu ajutorul aceluiași instrument care ajută la alegerea tastelor potrivite, care încă solicită utilizatorilor cu privire la teme de fotbal. Aceste fraze ar trebui, de asemenea, adăugate la această pagină.

Înțelegem ce altceva sunteți interesat de clienți cu privire la fotbal și tort
Cheile au observat. Dispersați tastele de căutare rămase.
Schema care a fost trasă la început poate fi supusă schimbării chiar și a numărului nelimitat de ori - dacă este necesar, puteți crea noi categorii și secțiuni. Deci, dacă nu exista pagina "Torturile pentru copii", amintindu-vă că firma poate face prăjiturile cu desene animate "PigPa Peppa" sau o "patrulare de catelus", puteți efectua modificări și puteți crea o pagină. În acel moment, aceste taste pot fi amplasate în secțiunea "Torturi din mastic".

Crearea unei noi partiții în tabelul ierarhic al site-ului "Torturi pentru copii"
Există două nuanțe importante care trebuie să fie luate în considerare:
- Este posibil ca grupul să nu includă o expresie adecvată pentru pagina pe care doriți să o creați. Cauzele pot fi utilizare incorectă Cuvânt cheie, plecarea selecției fraze-cheie sau de popularitate simplă scăzută a bunurilor sau a serviciilor. Dar, în același timp, acest lucru nu este un motiv să abandoneze pagina și să vândă bunuri. De exemplu, dacă în sistemul de căutare nu ați găsit interogarea de căutare "piper de porc tort", dar firma de cofetărie are caracteristici pentru a face un astfel de produs, puteți clarifica nevoile clienților care utilizează un alt serviciu. În acest caz, o astfel de solicitare va fi găsită și majoritatea sunt situate;

Oamenii caută, de asemenea, "Peppe Peppe"
- Ei bine, după excluderea cheilor inutile, pot exista cereri complet inadecvate. Ei bine, ei pot să le elimine sau pot aplica într-un alt cluster. Să presupunem că o companie de cofetărie este specializată în rețete unice, iar prăjiturile testate în timp precum "ruinele județene" sau "Napoleon" crede că este mai bine să plecați în trecut - astfel de chei pot fi lăsate la secțiunea în care utilizatorul va fi furnizat Informații generale - în acest caz, "rețete".
Fraza cheie poate fi plasată în secțiunea de informații dacă este foarte populară printre vizitatori.
Deci, la etapa finală, dispersând pe pagini toate cheile, veți preda lista de pagini web ale portalului, unde sunt specificate adresa URL, cererile și frecvența acestora. Mergem mai departe, nu este totul.
Echilibrarea finală a nucleului semantic
Deci, acum avem tot ce avem nevoie. Avem o masă cu un miez semantic, o listă de pagini web preliminare și fraze cheie care determină nevoile anumitor clienți. Toate acestea vor ajuta la pregătirea unui plan de completare a informațiilor (plan de conținut). Acum, făcându-l, va trebui să specificați numele paginii web sau al articolului și să includeți interogarea principală pentru motorul de căutare. Dar ar trebui să se țină cont de faptul că nu trebuie întotdeauna să fie cea mai comună cheie din punctul de vedere al Yandex sau Google. El trebuie să reflecte ceea ce doriți să transmiteți utilizatorilor și faptul că clienții doresc să obțină.Alte fraze cheie ar trebui să fie aplicate ca răspuns la întrebare - "Ce ar trebui să scriu?" Desigur, nu ar trebui să împingeți imediat toate frazele care au fost găsite utilizând instrumentul pentru selectarea interogărilor de căutare, într-o anumită secțiune - fie că este o pagină a planului de informații sau oferirea de a cumpăra un anumit serviciu sau un produs. Ar trebui să se repete din nou la sfârșitul anului: este necesar, în primul rând, să acorde o atenție la nevoile de informare ale utilizatorilor și nu pe frazele cheie și "umplutura" textului pe care le plac pastilele. Utilizatorul vede întotdeauna când încearcă să "ploaie" - cu compilarea competentă a textului, el nu va fi nici măcar în gânduri că au fost folosite cuvintele cheie aici.
În cele din urmă, ceea ce este încă de a face cu miezul semantic
Sper că întrebările despre ceea ce sa spus deja, nu aveți stânga și acum puteți crea o duzină de site-uri bazate pe cunoștințele dobândite. Dar totuși, ar trebui să desemnați câteva acțiuni care nu fac. Mai târziu veți fi intuitiv în acest lucru și acum ar trebui să fie învățați de inimă. Iată câteva sfaturi pentru a ajuta la devenirea unui profesionist în compilarea corectă a resurselor Internet:- Nu refuză cheile care au o competiție prea mare. Da, nu aveți prea multă nevoie de a intra în cele mai importante interogări de căutare "Ordin Marshlow". Folosiți doar fraza ca o idee de conținut;
- De asemenea, nu ar trebui eliminat din fraze cu frecvență redusă - acestea sunt ideile de conținut, datorită cărora sunteți posibil să satisfaceți pe cei care au reușit să găsească astfel de servicii chiar de la cele mai mari companii;
- Nu utilizați pentru evaluarea cuvintelor cheie cu formula și coeficienții (cum ar fi Kei, raportul dintre popularitatea kkonkurity). Să vedem din nou: Secțiunea Semantică - Lingvistică. Aceasta nu este o știință exactă, cum ar fi, de exemplu, fizică sau matematică. Este mai aproape de artă decât de studii exacte și, respectând cerințele formulei sau coeficientului, semantica își pierde punctul culminant. Deci, pierdeți o mulțime de idei pentru completarea informațiilor, care poate fi exclusă de program - dar nu și programul va citi ulterior textul;
- Nu creați o pagină separată de dragul unei taste. Cu siguranță au întâlnit astfel de cumpărături on-line, unde există pagini speciale "cumpăra o prăjitură" și "comandă un tort". Kernelul semantic este pierdut aici, deoarece, în esență, este aceeași acțiune. Sau "cumpăra ieftin" și "cumpăra ieftin" - acestea sunt cuvinte sinonime, prin urmare nu merită o pagină separată de conținutul inutil;
- Nu este nevoie să automatizați pe deplin designul kernel-ului semantic. Desigur, ați folosit unelte speciale pentru colectarea frazelor cheie, iar pentru proiecte imense, astfel de instrumente sunt pur și simplu indispensabile - în special colectorul cheie. Dar fără o analiză, care va fi produsă de om, valoarea cheii este scăzută. Acesta nu este un mare secret - chiar și cei care folosesc cunoașterea vechii școli știu. Serviciile fac doar mai ușor pentru noi, colectând informații care altfel ar fi nevoie pentru a filtra pentru o perioadă lungă de timp și dureroasă, dar textul în sine nu poate. Mai precis, există astfel de programe, dar valoarea lor pentru o persoană este mică și sunt destinate complet unui alt scop - nu pentru a citi utilizatorul. Numai unul care înțelege ceva în acest domeniu poate determina de fapt gradul de concurență, elaborează un plan de companie informativă sau poate analiza situația din acest domeniu. Toate cele trei elemente sunt articulate indirect cu proiectarea structurii resurselor web și a dispersiei cuvintelor cheie;
- Nu fiți o pluș - nu este nevoie să vă concentrați asupra colectării frazelor cheie. Numai afacerea de afaceri, nu există un punct excelent în realizarea spionajului atenți pentru concurenți, colectați cuvinte cheie maxime de la toate motoarele de căutare disponibile până la Hotbot și explorați motoarele de căutare. Este suficient să folosiți unul - maximum două resurse și poate fi Yandex sau Google. Ei bine, sau Rambler cu Mail.ru este în cel mai rău caz dacă acest motor de căutare este popular în regiunea dvs. Tut.by - Dacă sunteți interesat de o anumită regiune din Belarus, sau UAPORTAL.com - în Ucraina. Dar ele sunt folosite doar ca fiind obligatorii în regiune: dacă, de exemplu, locuitorii din Belarus vor fi interesați de "prăjituri cu Ksenia Sitnik", rezidentul Rusiei nu va spune nimic deloc. Și, prin urmare, nu merită să depășiți site-ul dvs. web.
Trebuie să vă amintiți de ce și de ce construiți miezul. Și, de asemenea, că este semantic.
Deci, la urma urmei, Marketing sau SEO?
Este imposibil să spunem că altcineva contrazice. Marketerul poate fi un bun "Ceeshnik" și viceversa. Doar de la o persoană care ar putea să facă în mod corect un kernel semantic pentru site-ul său, este nevoie în primul rând logica unui om de afaceri și a unui comerciant (orientare către client) și, în continuare - abilitățile unui specialist în domeniul SEO (implementarea corespunzătoare Cuvinte cheie). Trebuie să înțelegeți că dumneavoastră ca un om de afaceri poate oferi un potențial consumator. După aceasta, ar trebui să se înțeleagă modul în care clienții caută și găsesc datele necesare. Iar instrumentele descrise mai sus vor ajuta. Analizați, inutil, găsiți cele mai potrivite taste, clasificați-le și dispersate ergonomic pe întreaga structură a site-ului. Și Vua-La, acum a venit un moment când puteți începe formarea planului de conținut. Atenţie!!!. Administrația nu este responsabilă pentru conținutul său.Frecvent Webmasterii pentru începători, cu care se confruntă nevoia de a crea un nucleu semantic, nu știu unde să înceapă. Deși nimic nu este complicat în acest proces. Pur și simplu, trebuie să asamblați o listă de fraze cheie pentru care utilizatorii de Internet caută informații pe site-ul dvs.
Cu cât este mai complet și mai precis, cu atât este mai ușor să scrieți o copie bună a copiei și obțineți poziții înalte în căutarea cererilor dorite. Cum se face corect kerneluri semantice mari și de înaltă calitate și ce să facă cu ei în continuare că site-ul merge în vârf și colectează o mulțime de trafic și va fi vorbire în acest material.
Kernelul semantic este un set de fraze cheie încredințate în sensul, în cazul în care fiecare grup reflectă o nevoie sau dorința utilizatorului (intenția). Adică, ceea ce gândește o persoană, condusă de cererea sa la șirul de căutare.
Întregul proces de creare a unui nucleu poate fi trimis în 4 pași:
- Întâlniți o sarcină sau o problemă;
- În cap, formulam cum să găsim soluția prin căutare;
- Conduceți o cerere către Yandex sau Google. În plus față de noi, alți oameni fac același lucru;
- Cele mai frecvente opțiuni de apel intră în serviciile de analiză și devin fraze cheie pe care le colectăm și grup de nevoi. Ca urmare a acestor manipulări, se obține kernelul semantic.
Este necesar să selectați fraze cheie sau puteți face fără ea?
Anterior, semantica au fost pentru a găsi cele mai frecvențe cuvinte cheie pe această temă, le introduce în text și pentru a obține o vizibilitate bună în căutarea. În ultimii 5 ani, motoarele de căutare încearcă să meargă la modelul în care relevanța cererii de documente va fi evaluată nu de numărul de cuvinte și de varietatea variațiilor lor în text, dar în funcție de evaluarea dezvăluirii intenției.
Google a început în 2013 cu algoritmul Handingbird, Yandex în 2016 și 2017, cu Tehnologii Palee și Regina, respectiv.
Textele scrise fără XIA nu vor putea să dezvăluie pe deplin subiectul, ceea ce înseamnă concura cu vârful în ceea ce privește cererile de înaltă frecvență și la jumătatea frecvenței nu va funcționa. Efectuarea unui pariu pe cererile de frecvență redusă nu are sens - prea puțin trafic asupra lor.
Dacă doriți și în viitor să vă promovați cu succes sau produsul dvs. pe Internet - trebuie să învățați cum să faceți semantica potrivită, care dezvăluie pe deplin nevoile utilizatorilor.
Clasificarea interogărilor de căutare
Vom examina 3 tipuri de parametri pentru care sunt evaluate cuvintele cheie.
În frecvență:
- Fraze de înaltă frecvență (HF) Definirea subiectului. Constau din 1-2 cuvinte. În medie, numărul interogărilor de căutare începe de la 1000-3000 pe lună și poate ajunge la sute de mii de impresii depinde de subiect. Cel mai adesea sub ele sunt principalele pagini ale site-urilor.
- Gradul mediu (SCH) - Direcții separate în subiect. De preferință conțin 2-3 cuvinte. Cu o frecvență exactă de la 500 la 1000. De obicei, categoriile de un site comercial sau temă pentru articole de informare mare.
- Frecvență redusă (LF) - Solicitări referitoare la căutarea unui răspuns specific la întrebare. De regulă, de la 3-4 cuvinte. Acesta poate fi un card de produs sau un subiect de articol. În medie, căutați de la 50 la 500 de persoane pe lună.
- Când se analizează metricul sau datele de metri statistice, puteți întâlni un alt tip de microchere a cheilor. Acestea sunt fraze care se întreabă adesea o dată pe căutare. Nu are sens să ascuți sub ele pagina nu este. Este suficient să fii în partea de sus a LF, care le include.
Pentru competitivitate:
- Highborne (VC);
- Mediterranent (SC);
- LongCover (NK);
Pentru nevoi:
- Navigare. Exprimă dorința utilizatorului de a găsi o resursă specifică de Internet sau informații despre aceasta;
- Informație. Caracterizată de disponibilitatea informațiilor în obținerea informațiilor ca răspuns la cerere;
- Tranzacţie. Direct asociate cu dorința de a face o achiziție;
- Fuzzy sau comună. Cele pe care este dificil să determine cu precizie intenția.
- Geo-dependent și dependent de Geon. Reflectă necesitatea de a căuta informații sau de a face o tranzacție în orașul lor sau fără obligație regională.

În funcție de tipul site-ului, pot fi date următoarele recomandări la selectarea frazelor cheie pentru kernelul semantic.
- Resurse de informare. Principalul accent ar trebui să se facă în căutarea articolelor sub formă de solicitări LF SCH și de concurență redusă. Se recomandă dezvăluirea subiectului larg și adânc, tragând pagina pentru un număr mare de taste LF.
- Magazin online sau site-ul comercial. Colectăm HF, SCH și LF, care este foarte clar segmentată, astfel încât toate frazele să fie de tip tranzacțional și să se refere la un cluster. Accentul se pune pe căutarea cuvintelor cheie NC NC NC.
Cum să faceți un mare kernel semantic - instrucțiuni pas cu pas
Am trecut la partea principală a articolului, unde voi fi în mod consecvent, dezasamblați principalele etape pe care trebuie să le faceți pentru a construi un kernel al site-ului viitor.
Pentru ca procesul să fie mai clar, toate etapele sunt date cu exemple.
Căutați fraze de bază
Lucrul cu codul începe cu alegerea listei primare de cuvinte și fraze de bază (HF), care sunt cel mai bine caracterizate prin teme și sunt folosite într-un sens larg. Ele sunt, de asemenea, numite markeri.
Poate fi ca numele instrucțiunilor și tipurilor de produse, cereri populare din subiect. De regulă, ele constau din 1-2 cuvinte și există zeci și, uneori, sute de mii de spectacole pe lună. Cheile mai bune sunt mai bune să nu ia în picioare în cuvinte minus la etapa de expansiune.
Mai convenabil pentru a selecta fraze de marker utilizând. Privind într-o cerere, în coloana din stânga vedem frazele, pe care le conține în sine, în dreapta - cereri similare din care puteți găsi adesea potrivite pentru extinderea temei. De asemenea, serviciul arată frecvența de bază a frazei, adică de câte ori li sa cerut o lună în toate formele de cuvinte și cu adăugarea de cuvinte la el.

Prin ea însăși, o astfel de frecvență nu este foarte interesantă, deci este necesar să se utilizeze operatorii pentru a obține valori mai precise. Vom analiza ceea ce este și pentru ce.
Operatori Yandex Wordstat:
1) "..." - Citate. Cererea de citate vă permite să urmăriți de câte ori în Yandex căuta o frază cu toate formele de cuvinte, dar fără a adăuga alte cuvinte (cozi).

2)! - Semn de exclamare. Folosind-o înainte de fiecare cuvânt în cerere, îl rezolvăm cu forma sa și obținem numărul de apeluri în căutarea după cuvântul cheie numai în formularul cuvânt specificat, dar cu coada.

3) "! ...!! ...! ..." - Citate și un semn de exclamare înainte de fiecare cuvânt. Cel mai important operator pentru optimizator. Acesta vă permite să înțelegeți de câte ori cuvântul cheie este solicitat cu o lună strict conform unei fraze date, deoarece este scrisă, fără a adăuga niciun cuvânt.

4) +. Yandex Vordstat nu ia în considerare prepozițiile și pronumele atunci când solicită. Dacă aveți nevoie să le arătați - puneți un semn plus în fața lor.

cinci) -. Cel de-al doilea cel mai important operator. Cu aceasta, cuvintele care nu sunt potrivite sunt rapid eliminate. Pentru ao aplica după fraza analizată, am pus minus și opresc cuvântul. Dacă acestea sunt oarecum repetate procedura.

6) (... | ...). Dacă trebuie să obțineți de la Yandex, datele de pe mai multe fraze se încheie simultan în paranteze și împărtășesc sclavul direct. În practică, metoda este rar utilizată.

Pentru confortul de a lucra cu serviciul, vă recomand să puneți o extensie specială pentru browserul asistent Wordstat. Acesta este plasat pe Mozil, Google Chrome, I.BAURAZER și vă permite să copiați fraze și frecvența acestora cu un singur clic sau "Adăugați toate" pictograma.

Să presupunem că am decis să vă facem blogul pe CEO. Selectați 7 fraze principale pentru aceasta:
- kernel semantic;
- optimizare;
- copywriting;
- promovare;
- monetizare;
- Direct
Căutați sinonime
Când vi se solicită să căutați sisteme, utilizatorii pot folosi cuvintele apropiate, dar diferite prin scriere.
De exemplu, "mașina" și "mașina".
Este important să găsiți cât mai multe sinonime ale cuvintelor principale pentru a crește acoperirea viitorului nucleu semantic. Dacă acest lucru nu este făcut, atunci când parcați, vom pierde un întreg strat de fraze cheie care dezvăluie nevoile utilizatorilor.
Ceea ce folosim:
- Brainstorm;
- Coloana dreapta yandex wordstat;
- Solicitări înregistrate pe chirilice;
- Termeni speciali, abrevieri, expresii de slang de la subiect;
- Blochează Yandex și Google - împreună cu "Nume de interogare" caută;
- Fragmente de concurenți.
Ca urmare a tuturor acțiunilor pentru subiectul ales, obținem o astfel de listă de fraze:

Extinderea cererilor principale
Vom sparge aceste cuvinte cheie pentru a identifica nevoile de bază ale oamenilor din acest domeniu.
Mai convenabil pentru a face acest lucru în programul cheie colector, dar dacă este milă de a plăti 1800 de ruble pe licență, utilizați-l analogul gratuit - Sword.
Conform funcționalității, este, desigur, mai slabă, dar pentru proiecte mici sunt potrivite.
Dacă nu doriți să vă deplasați în activitatea programelor, puteți utiliza serviciul Just-Magings și Analytics Rush. Dar totuși este mai bine să petreceți puțin timp și să vă ocupați de software.
Voi arăta principiul de a lucra în Kay Collector, dar dacă lucrați cu un cuvânt, atunci totul va fi înțeles. Interfața programului este similară.
Procedură:
1) Vom adăuga o listă de fraze de bază la program și vom elimina frecvența de bază și exactă asupra acestora. Dacă intenționăm să promovăm într-o anumită regiune - indicăm regionalitatea. Pentru site-urile de informații, cel mai adesea nu este necesar.

2) Sparks coloana din stânga Yandex Wordstat conform cuvintelor adăugate pentru a obține toate solicitările din subiectul nostru.

3) La ieșire am transformat 3374 fraze. Vom elimina frecvența exactă asupra lor, ca în primul punct.

4) Verificați dacă nu există chei din listă cu frecvența de bază zero.

Dacă eliminăm și mergem la pasul următor.
Minus-cuvinte.
Mulți neglijează procedura de colectare a cuvintelor minus, înlocuindu-l cu eliminarea frazelor care nu sunt potrivite. Dar mai târziu veți realiza că este convenabil și cu adevărat economisește timp.
Deschideți fila Date din Kay Collector -\u003e Analiză. Selectați tipul de grup în funcție de cuvintele individuale și LIDE Lista tastelor. Dacă vedeți o frază care nu se potrivește - apăsați pictograma albastră și adăugați un cuvânt în loc de tot cuvântul dvs. în cuvintele de oprire.

În Slobel, lucrul cu cuvintele de oprire este implementat într-o versiune mai simplificată, dar puteți face, de asemenea, lista de fraze care nu se potrivesc și le aplică în listă.
Nu uitați să utilizați sortarea frecvenței de bază și a numărului de fraze. Această opțiune ajută la reducerea rapidă a listei frazelor sursă sau tăiate rareori întâlnite.

După ce am compilat o listă de cuvinte stop, să le aplicați la proiectul nostru și să mergem la colecția de prompsuri de căutare.
Sfaturi de parsare
La introducerea unei cereri către Yandex sau Google, motoarele de căutare oferă opțiunile lor de a continua de cele mai populare fraze care sunt conduse de Internet. Aceste cuvinte cheie sunt numite sfaturi de căutare.
Mulți dintre ei nu se încadrează în Wordstat, așa că atunci când construiește semantic trebuie să adune astfel de solicitări.
Kay Collector, prin parsita implicită, cu un bust al capătului, alfabetului chirilic și latin și cu un spațiu după fiecare expresie. Dacă sunteți dispus să vă angajați să sacrificați suma pentru a accelera în mod semnificativ procesul, puneți o bifă la punctul "Colectați doar sfaturi de top fără o busting și un spațiu după fraza".

Adesea, printre motoarele de căutare, puteți găsi fraze cu o frecvență bună și o concurență în zeci de ori mai mici decât în \u200b\u200bVordstat, așa că în nișe îngustă vă recomand să colectați un maxim de cuvinte.
Timpul de parsare a vârfului depinde în mod direct de numărul de apeluri simultane la serverele motorului de căutare. Maximul colector Kei acceptă 50 de trafic.
Dar pentru a analiza cereri în acest mod, veți avea nevoie de prea multe proxy și conturi în Yandex.
Pentru proiectul nostru, după colectarea de solicitări, sa dovedit 29595 fraze unice. De-a lungul timpului, întregul proces a durat puțin mai mult de 2 ore pe 10 fire. Asta este, dacă există 50, vom pune în 25 de minute.

Definiția frecvenței de bază și exacte pentru toate frazele
Pentru lucrări ulterioare, este important să se determine frecvența de bază și exactă și să întrerupeți toate zero. Solicitările cu un număr mic de spectacole sunt lăsate dacă sunt țintă.
Acest lucru va contribui la înțelegerea mai bună a intrinsecului și de a crea o structură mai completă a articolului decât în \u200b\u200bpartea de sus.
Pentru a elimina frecvența, în primul rând, toate inutile:
- drumuri de cuvinte
- cheile cu alte simboluri;
- fraze olandeze (prin instrumentul "Analiza de stejar implicit")

Pentru frazele rămase, vom defini frecvența exactă și de bază.
dar) pentru fraze de până la 7 cuvinte:
- Alegem prin filtru "fraza nu constă mai mult de 7 cuvinte"
- Deschideți fereastra "Colecția cu Yandex.Direct" făcând clic pe pictograma "D";
- Dacă specificați regiunea;
- Selectați modul de afișare garantat;
- Am pus perioada de colectare - 1 lună și bifați peste tipurile de frecvență dorite;
- Faceți clic pe "Obțineți date".

b) pentru fraze de la 8 cuvinte:
- Specificăm pentru filtrul "Frază" - "constă într-un minim de 8 cuvinte";
- Dacă trebuie să vă deplasați într-un anumit oraș de mai jos, specificăm regiunea;
- Faceți clic pe Magnifier și alegeți "Colectați toate tipurile de frecvențe".

Curățarea cuvintelor cheie de la gunoi
După ce am primit informații despre numărul de afișări pentru cheile noastre, puteți începe să utilizați non-adecvați.
Luați în considerare procedura de pași:
1. Mergeți la "Analiza grupurilor" Colector Kei și sortați cheile cu cantitatea de utilizare a cuvintelor. Sarcina de a găsi inadecvate și frecvente și le-a pus în lista cuvintelor de oprire.
Facem totul, precum și în "cuvinte minus".

2. Aplicați la lista frazelor noastre Toate cuvintele de oprire găsite și rulează pe ea pentru a nu pierde cu siguranță interogări țintă. După verificare, faceți clic pe Ștergeți "Expresii marcate".

3. Sursă Frazele Dumbers, care sunt rareori utilizate în intrarea exactă, dar au o frecvență de bază ridicată. Pentru a face acest lucru, în setările programului de colectare a cheilor în cheia și serp, introduceți formula de calcul: tasta 1 \u003d (YandedewordStatBasefreq) / (YandedewordsTquotepointfreq) și salvați modificări.

4. Facem calculul de key 1 și eliminăm aceste fraze pe care acest parametru le-a dovedit de la 100 și mai mult.

Tastele rămase ar trebui să fie grupate pe paginile de îmbarcare.
Clustering.
Distribuția grupurilor în grupuri începe cu fraze de grupare de-a lungul vârfului program gratuit "Clusterizator majento". Vă recomandăm ca un analog să plătească cu o funcționalitate mai largă și o viteză rapidă de lucru - KeyAssort, dar și suficient de liber pentru un mic kernel. Singura nuanță care pentru a lucra în oricare dintre ele va trebui să cumpere limite XML. Prețul mediu este de 5 p. Pentru 1000 de solicitări. Adică, prelucrarea nucleului de mijloc cu 20-30 mii taste va costa 100-150 p. Adresa serviciului care utilizează, privește în ecranul de mai jos.

Esența clusteringului Tastele Această metodă este de a combina în grupuri de expresii care au în top 10 Yandex:
- uRL-uri comune cu celălalt (greu)
- cu cea mai mare frecvență interogare din grup (moale).
În funcție de numărul de astfel de coincidențe pentru diferite site-uri, pragurile de grupare se disting: 2, 3, 4 ... 10.
Avantajul metodei este gruparea frazelor în funcție de nevoile oamenilor și nu numai pe conexiuni sinonime. Acest lucru vă permite să înțelegeți imediat ce cuvinte cheie pot fi utilizate pe o singură pagină de îmbarcare.
Pentru informații se vor potrivi:
- Moale cu prag 3-4 și apoi curățarea cu mâinile;
- Hard pe 3-Ke, apoi combinând clusterele în sens.
Magazinele online și site-urile comerciale sunt de obicei avansate de Hard-Y cu un prag de grupare de trei ori, așa că o voi ridica într-un articol separat.
Pentru proiectul nostru după gruparea prin metoda dur pe 3 a transformat 317 de grupuri.

Verificarea concurenței
Nu are sens să avanseze prin cereri extrem de competitive. Este dificil să intri în vârf și fără ea nu va exista nici un trafic pe articol. Pentru a înțelege ce subiecte este avantajos să scrieți utilizând următoarea metodă:
Se concentrează în mod obișnuit pe frecvența exactă a grupului de expresii prin care articolul este scris și concurența pe mutagen. Pentru site-urile de informare, vă recomand, luați subiectul pentru a lucra, în care frecvența totală exactă de 300 și mai mare și coeficientul competitiv de la 1 la 12 inclusiv.
În teme comerciale, se concentrează asupra marginalității bunurilor sau a serviciilor și modul în care concurenții fac în top 10. Chiar și 5-10 interogările țintă pe lună pot fi un motiv pentru a face o pagină separată sub ea.
Cum să verificați concurența la cerere:
a) manual, condus de fraza adecvată în serviciul însuși sau prin sarcini de masă;

b) în modul lot prin programul Colector Kay.

Selecția subiectelor și grupului
Luați în considerare fiecare dintre grupurile rezultate pentru proiectul nostru după clustering și alegeți subiectul pentru site.
Majento Spre deosebire de asistentul cheie nu face posibilă descărcarea de date despre numărul de spectacole pentru fiecare frază, deci va trebui să le eliminați suplimentar prin Kay Collector.
Instrucțiuni:
1) descărcați toate grupurile din Majentor în format CSV;
2) Ambreierea frazelor din Excel pe masca "Grup: cheie";
3) Încărcați lista rezultată în Sollector-cheie. În setări, acesta trebuie să fie o marcă de verificare în modul Import "Grup: cheie" și să nu monitorizați prezența frazelor în alte grupuri;

4) Înlătăm frecvența de bază și exactă pentru cuvintele cheie din grupurile nou create. (Dacă utilizați assort cheie, nu este necesar să faceți acest lucru. Programul vă permite să lucrați cu coloane suplimentare)
5) Căutăm clustere cu un intenten unic, care conține cel puțin 3 fraze și numărul de hit-uri la toate cererile în valoare de mai mult de 300. Apoi, verificăm 3-4 cea mai mare frecvență a acestora pe competiția mutagen. Dacă printre aceste fraze există chei cu concurență mai mică de 12 - iau în muncă;
6) Vedem restul grupurilor. Dacă frazele apropiate se găsesc și merită vizionată într-o singură pagină - combinăm. Pentru grupurile care conțin noi semnificații, ne uităm la perspectivele frecvenței totale a frazelor, dacă este mai mică de 150 pe lună, apoi lăsați-o până în momentul în care treceți prin întregul nucleu. Se poate dovedi a fi combinat cu un alt cluster și obține 300 de spectacole precise - acesta este cel puțin din care merită să faceți un articol de lucru. Pentru a accelera grupul manual, utilizați uneltele auxiliare: Filtru rapid și dicționarul de frecvență. Acestea vă vor ajuta să găsiți rapid expresii potrivite din alte clustere;

Atenţie!!! Cum să înțelegeți că clusterele pot fi combinate? Luăm 2 chei de frecvență de la cei preluați la punctul 5 pentru pagina de destinație și 1 solicitare din partea noului grup.
Le adăugăm la instrumentul Arsenkin "Descărcarea top 10", indicați regiunea dorită, dacă este necesar. Mai mult, ne uităm la numărul de intersecții de culoare pentru a treia frază cu restul. Combinăm grupurile dacă sunt de la 3 sau mai multe. Dacă nu există coincidențe sau una, este imposibil să se combine - diferite intensuri, în cazul a 2 intersecții, a se vedea emiterea de către mâini și folosiți logica.
7) După gruparea cheilor, primim o listă de subiecte promițătoare pentru articole și semantice sub ele.

Eliminarea cererilor de alt tip de conținut
În pregătirea nucleului semantic este important să se înțeleagă că pentru bloguri și site-uri de informare, nu sunt necesare cereri comerciale. La fel cum magazinele online nu au nevoie de informații.
Rămânem prin fiecare grup și curăță totul nu este necesar dacă este imposibil să determinăm cu precizie intenția interogării - compararea emiterii sau utilizarea instrumentelor:
- Verificarea comercializării de la Pixel Tuls (gratuit, dar cu o limită de zi a verificărilor);
- service Just-Magic, Clustering Cu marcajul de verificare Verificați interogarea comercială (taxă, cost depinde de tarif)
După aceea, mergeți la ultimul pas.
Optimizarea frazelor
Optimizăm kernelul semantic, astfel încât este convenabil să lucrați cu acesta în viitorul specialist SEO și copywriter. Pentru a face acest lucru, vom lăsa frazele cheie din fiecare grup care reflectă cea mai mare parte nevoile oamenilor și conțin cât mai multe sinonime cât mai multă fraze principale.
Algoritmul de acțiuni:
- Sortați cuvintele cheie în Excel sau Colector Kay alfabetic de la A la Z;
- Alegeți cele care dezvăluie subiectul din diferite părți și cuvinte diferite. Alte lucruri fiind egale au lăsat fraza cu o frecvență precisă mai mare sau în care indicatorul cheie 1 (raportul dintre frecvența de bază la exact);
- Eliminăm cuvântul cheie cu numărul de spectacole cu o lună mai mică de 7, care nu suportă noi sensuri și nu conțin sinonime unice.
Un exemplu de cum arată un kernel semantic compus competent -
Am remarcat frazele care nu sunt potrivite pentru intensitate. Dacă vă neglijați prin recomandările mele privind gruparea manuală și pentru a nu verifica compatibilitatea, se va dovedi că pagina va fi optimizată pentru fraze cheie incompatibile și poziții înalte privind solicitările progresive nu mai văd.
Lista de verificare finală
- Selectăm principalele interogări de înaltă frecvență care stabilesc subiecții;
- Căutăm sinonime pentru ei folosind coloana din stânga și cea dreaptă Wordstat, site-urile de concurenți și fragmentele lor;
- Extindeți cererile de recuperare primite în coloana din stânga Wordstat;
- Pregătim o listă de cuvinte stop și să aplicăm frazele rezultate;
- Parsim sfaturi Yandex și Google;
- Îndepărtați frecvența de bază și precisă;
- Extindeți lista cuvintelor minus. Curățați de cererile de gunoi și cu tape
- Facem clusterizare prin majento sau keyassort. Pentru site-urile de informații din modul moale, pragul 3-4. Pentru resursele comerciale de Internet utilizând metoda ta cu prag 3.
- Importăm date în Kay Collector și determinăm competiția 3-4 fraze pentru fiecare cluster cu o intensitate unică;
- Alegem subiecte și determinăm cu paginile de destinație pentru interogările bazate pe evaluarea numărului total de spectacole exacte în toate frazele de la un cluster (de la 300 de informații "și concurența pentru cea mai mare frecvență a acestora pe mutagen (până la 12) .
- Pentru fiecare pagină potrivită, căutăm alte clustere cu nevoi similare ale utilizatorilor. Dacă le putem lua în considerare pe o singură pagină - combinăm. Atunci când nevoia nu este clară sau există suspiciuni că, ca răspuns, ar trebui să existe un alt tip de conținut sau pagini - verificați prin emitere sau prin instrumente pixel sau doar-magie. Pentru site-urile de conținut, kernelul ar trebui să fie alcătuit din solicitări de informații, Comercială de la tranzacțional. Ștergem prea mult.
- Sortați cheile în fiecare grup prin alfabetic și lăsați-le pe cei care descriu subiectul din diferite părți și cuvinte diferite. Alte lucruri fiind egale cu prioritatea acestor solicitări care sunt mai mici decât raportul frecvenței de bază la numărul exact și mai mare de spectacole exacte pe lună.
Ce să faci cu SEO-Core după crearea sa
Ca o listă de chei, le-au dat autorului și a scris complet un articol excelent, dezvăluind toate semnificațiile. Eh, ceva ce sunt blocat ... textul sensibil va fi posibil numai dacă copywriterul înțelege în mod clar că doriți de la el și cum să vă verificați.
Vom analiza 4 componente, lucru bine, pe care sunteți garantat pentru a obține o mulțime de trafic țintă pe articol:
O structură bună. Analizăm solicitările selectate pentru pagina de destinație și dezvăluie ce are nevoie de oameni în acest subiect. Apoi, scrieți un plan pentru un articol care le răspunde pe deplin. Sarcina este de a face ca oamenii să meargă la site a primit un răspuns volumetric și cuprinzător la semantica pe care ați făcut-o. Acesta va da o bună relevanță comportamentală și mare intensității. După ce ați compilat un plan, consultați site-urile concurenților prin o cerere de căutare promovată de bază. Trebuie să faceți într-o astfel de secvență. Asta este, mai întâi noi noi, atunci ne uităm la alții și dacă trebuie să fim rafinați.
Optimizarea sub taste. Articolul în sine este ascuțit sub 1-2 cele mai multe chei de frecvență cu concurență pe mutagen până la 12. Alte 2-3 fraze de frecvență la mijloc pot fi utilizate ca titluri, dar într-o formă diluată, adică, introducerea suplimentară non-temă în ele , folosind sinonime și cuvânt. Principalul accent pe care îl facem pe fraze de frecvență redusă, din care scoateți partea unică - coada și implementarea uniformă în text. Motoarele de căutare se vor găsi și vor lipi.
Sinonime pentru cererile de bază. Le scriem separat de kernelul nostru semantic și le punem sarcina copywriterului să le folosească în mod egal în text. Acest lucru va contribui la reducerea densității cuvintelor noastre principale și textul va fi suficient de optimizat pentru a intra în partea de sus.
Fraze de specificare tematică.Prin ei înșiși, LSI nu promovează pagina, dar prezența lor indică faptul că cel mai probabil textul scris aparține expertului Peru și acesta este deja un plus pentru calitatea conținutului. Pentru a căuta fraze tematice, utilizați instrumentul Instrumente pentru un copywriter de la pixeli Tuls.

Metoda alternativă de selecție a frazelor-cheie utilizând servicii de analiză a concurenților
Există o abordare rapidă a creării unui kernel semantic, care se aplică atât utilizatorilor nou-veniți, cât și celor cu experiență. Esența metodei este că alegem inițial cheile nu pentru întregul site sau categorie, ci în mod specific în articol, pagina de ședere.
Acesta poate fi realizat de 2 moduri care diferă în modul în care alegem temele pentru pagină și cât de profund extind frazele cheie:
- utilizând parsarea principală a cheii;
- pe baza analizei concurenților.
Fiecare dintre ele poate fi implementat la un nivel simplu și mai complex. Vom analiza toate opțiunile.
Fără utilizarea programelor
Copiatorul sau webmasterul nu doresc adesea să se ocupe de interfața unui număr mare de programe, dar aveți nevoie de teme bune și de fraze cheie sub ele.
Această metodă este doar pentru începători și cei care nu doresc să se deranjeze. Toate acțiunile sunt făcute fără utilizarea de software suplimentar, folosind servicii simple și ușor de înțeles.
Ce va dura:
- Keys.so Serviciu pentru analiza concurenților - 1500 p. În reducere de promovare "Altblog" - 15%;
- Mutagen. Verificați concurența de interogare - 30 de copeici, colectarea frecvenței de bază și exacte - 2 kopeck-uri pentru 1 verificare;
- Buvillers - o versiune gratuită sau un cont de afaceri - 995 p. (acum cu o reducere de 695 p)
Opțiunea 1. Selectați subiectul prin intermediul parcelei principale:
- Selectăm tastele principale de la subiect în sens larg folosind brainstorming-ul și coloana din stânga și dreapta a Yandex Wordstat;
- Mai mult, căutăm sinonime pentru ei, a căror metode au fost menționate mai devreme;
- Scorim toate cererile de marker primite către Bookvilk (trebuie să plătim pentru rata plătită) în modul avansat "Căutare după lista cuvintelor cheie";
- Specificăm în filtru: "! Exactul! Frecvența" de la 50, numărul de cuvinte de la 3;
- Descărcați întreaga listă în Excel;
- Noi alocăm toate cuvintele cheie și trimiteți la gruparea la serviciul "Pumnii clastier". Dacă site-ul este ales regional orașul necesar. Pragul de clustering pentru site-urile de informații concediu pe 2, pentru comercial 3-KU;
- După grupare, alegeți teme pentru articole prin navigarea clusterelor rezultate. Luăm pe cei în care cantitatea de fraze de la 3 și cu un intenten unic. Este mai bine să înțelegeți nevoile oamenilor care ajută la analiza adreselor URL ale site-urilor de sus în coloana "Concurenți" (pe dreapta în placa de service Kulakov). De asemenea, nu uităm să verificăm competiția pentru Mutagen. Pierdem 2-3 cereri din cluster. Dacă mai mult de 12, atunci nu trebuie să luați subiectul;
- Numele paginii viitoare de aterizare a fost determinată, rămâne să alegeți fraze cheie pentru aceasta;
- De la câmpul "Concurenții" Copiază 3 Ullas cu un tip de pagini adecvate (dacă site-ul este informativ - ia referințe la articole, dacă sunt comerciale, apoi pe magazine);
- Introduceți-le secvențial în chei.So și descărcați toate frazele cheie pe ele;
- Le combinăm în Excel și eliminăm duplicatul;
- Numai datele nu sunt suficiente, deci este necesar să le extindem. Vom folosi din nou buckvilicul;
- Lista rezultată este trimisă la clustering în pumnii "Clientizator";
- Selectăm grupurile de solicitări care sunt potrivite pentru pagina de destinație, concentrându-se asupra intenției;
- Îndepărtăm frecvența de bază și exactă prin mutagenul în modul "Sarcini de masă";
- Încărcați o listă cu date actualizate de numărul de spectacole din Excel. Îndepărtați zero pentru ambele tipuri de frecvențe;
- De asemenea, în Excel, adăugați formula pentru relația de frecvență de bază pentru a exacta și a lăsa doar cheile în care este mai mică de 100;
- Ștergem cererile unui alt tip de conținut;
- Lăsăm frazele pe care cele mai complete cuvintele cele mai complete și diferite dezvăluie intenția principală;
- Repetăm \u200b\u200btoate aceleași acțiuni pe paragrafele 8-19 pentru restul.
Opțiunea 2. Selectați subiectul prin analiza concurenților:
1. Căutăm site-uri de vârf în subiectul nostru, condus de cererile RF și vizualizarea emiterii prin instrumentul Arsenkin "Top 10". Este suficient să găsiți 1-2 resurse adecvate.
Dacă promovăm site-ul într-un anumit oraș, indicăm regionalitatea;
2. Mergeți la chei.so service și introduceți adresele URL ale site-urilor care au găsit și priviți la ce fel de pagini de concurenți aduc cel mai mare trafic.
3. 3-5 dintre cele mai exacte cereri de frecvență de la acestea verifică competitivitatea. Dacă este mai mare de 12 în toate frazele, atunci este mai bine să căutați un alt subiect mai puțin competitiv.
4. Dacă aveți nevoie să găsiți mai multe site-uri de analiză, deschideți fila "Competitori" și setați parametrii: similar cu 3, colaborare - 10. Sortăm datele privind scăderea traficului.
5. După ce am ales subiectul, conducem numele la emitere și copiați 3 Ullas din partea de sus.
6. Apoi repetați articolele 10-19 de la prima opțiune.
Folosind un colector Kei sau Word
Această metodă va fi diferită de cea utilizată anterior pentru utilizarea pentru unele colectori cheie de programare a programului și o expansiune cheie mai profundă.
Ce va dura:
- programul de colectare cheie - 1800 de ruble;
- toate aceleași servicii ca în modul anterior.
"Avansat - 1"
- PARSIM coloana din stânga și dreapta a lui Yandex pe tot parcursul frazei;
- Îndepărtați frecvența exactă și de bază prin intermediul colectorului Kay;
- Calculați cheia 1;
- Ștergem cererile zero și cu cheia 1\u003e 100;
- Apoi, facem totul, precum și în paragrafele 18-19 din opțiunea 1.
"Avansat - 2"
- Facem pașii 1-5, ca în realizarea 2;
- Colectăm pe fiecare cheile de url în cheile.
- Eliminăm duplicatul în Kay Collector;
- Repetăm \u200b\u200bparagrafele 1-4, ca în metoda "avansată -1".
Comparați acum numărul de chei obținute și frecvența lor totală precisă la colectarea cu diferite metode:
După cum vedem din masă, cel mai bun rezultat a arătat o metodă alternativă pentru crearea unui miez sub pagina - "Avansat 1.2". A fost posibilă obținerea a 34% mai multe taste țintă, iar traficul total pe cluster a transformat cu 51% mai mult decât în \u200b\u200bcazul unei metode clasice.
Mai jos, pe ecran, se poate observa cum arată miezul finit, în fiecare dintre cazuri. Am luat fraze cu un număr precis de depozite de la 7 pe lună, astfel încât calitatea cuvântului cheie să poată fi estimată. Pentru semantica completă, consultați tabelul de pe linkul "Vezi".
DAR) 
B) 
ÎN) 
Acum știi că cea mai obișnuită cale nu este întotdeauna făcută, așa cum face toată lumea, cea mai credincioasă și corectă, dar să nu refuze alte metode. Depinde mult de tema în sine. Pentru site-urile comerciale, unde cheile nu sunt atât de mult, destul de suficient și opțiunea clasică. Pe site-urile de informații, puteți obține, de asemenea, rezultate excelente dacă compilați corect o copierație TK corect, faceți o structură bună și o optimizare SEO. Vom vorbi despre toate acestea în detaliu în următoarele articole.
3 erori frecvente atunci când creați un kernel semantic
1. Colectați fraze pe partea de sus. Nu este suficient să recurgeți cuvântul pentru a obține un rezultat bun!
Mai mult de 70% din cererile care sunt aduse rar sau perioade, nu ajung acolo. Dar, printre care, există fraze cheie cu o conversie bună și o concurență foarte scăzută. Cum să nu le pierdeți? Asigurați-vă că colectați solicitări de căutare și combinați-le cu date din diferite surse (contoare pe site-uri, servicii statistice și baze de date).
2. Amestecarea informațiilor și a cererilor comerciale pe o singură pagină.Am dezasamblat deja că frazele cheie diferă în funcție de tipul de nevoi. Dacă un vizitator vine pe site-ul dvs., care dorește să facă o achiziție și vede ca un răspuns la pagina sa de solicitare cu un articol, cum credeți că va fi satisfăcut? Nu! Sistemele de căutare se gândesc, de asemenea, când pagina este clasată, ceea ce înseamnă despre topul în frazele de mijloc și RF puteți uita imediat. Prin urmare, dacă vă îndoiți de definiția tipului de solicitare, consultați emiterea sau utilizați instrumentele Pixel Tuls, Just-Magins pentru a determina comercialismul.
3. Selecție pentru a promova cereri foarte competitive. Pozițiile pentru frazele RF VK sunt de 80-70% dependente de factorii comportamentali și să-i facă să intre în partea de sus. Cu cât mai mulți solicitanți, cea mai lungă coadă de la cei care doresc și peste cerințele pentru site-uri. Totul, ca în viață sau sport. Este mult mai greu să devii un campion mondial decât obținerea titlului în orașul tău.
Prin urmare, este mai bine să introduceți o nișă liniștită și nu supraîncălzită.
Anterior, a fost și mai complicat să fie pe partea de sus. În partea de sus stătea pe principiul care a reușit, a mâncat el. Liderii au căzut la primele locuri și nu le-ar putea mișca, acumulând factori comportamentali. Și cum să le obțineți dacă vă aflați pe a doua sau a treia pagină ... Yandex a rupt acest cerc închis în vara anului 2015, introducând un algoritm multiplu de gangster. Esența lui este doar că crește și coboară în mod aleatoriu pozițiile de site-uri pentru a înțelege dacă candidații mai demni păreau să găsească în partea de sus.
Câți bani sunt necesari pentru început?
Pentru a răspunde la această întrebare, luăm în considerare costurile arsenalului necesar al programelor și serviciilor de a pregăti și despre frazele cheie necunoscute la 100 de articole.
Minimul (potrivit pentru opțiunea clasică):
1. Slobel - gratuit
2. Majento Clusterizator - gratuit
3. Să recunoască captura - 30 de ruble.
4. Limitele XML - 70 de ruble.
5. Verificați concurența cererii Mutagen - 10 verificări pe zi gratuit
6. Dacă nu sunteți tratat oriunde și sunteți gata să cheltuiți pe o parsare 20-30 de ore, puteți face fără un proxy.
—————————
Rezultatul este de 100 de ruble. Dacă introduceți captchasul dvs. și limitele XML ajung în schimbul transferate de pe site-ul dvs., apoi pregătiți cu adevărat kernelul în general gratuit. Este necesar doar să petreceți ziua pe alta la înființarea și stăpânirea programelor și alte 3-4 zile pentru a vă aștepta rezultatele parsarelor.
Set standard semantist (pentru metoda avansată și clasică):
1. Kay Collector - 1900 de ruble
2. Kay Assort - 1700 de ruble
3. Bookwarix (contul de afaceri) - 650 de ruble.
4. SERVICIUL DE ANALIZA COMPETITOR - 1500 de ruble.
5. 5 Proxy - 350 de ruble pe lună
6. Antikapitch - aproximativ 30 de ruble.
7. Limitele XML - aproximativ 80 de ruble.
8. Verificarea concurenței cu mutagen (1 check \u003d 30 kopecks) - face 200 de ruble.
———————-
Rezultatul este de 6410 de ruble. Desigur, este posibil să se facă fără KeyAssort, înlocuindu-l cu un clusterizator majento și în loc de colectorul Kay pentru a folosi un cuvânt. Atunci destul și 2810 de ruble.
Ar trebui să am încredere în dezvoltarea kernelului "Profi" sau mai bine să-i dau seama și să o fac singur?
Dacă o persoană este angajată în mod regulat în lucrul său preferat, pompând în ea, apoi după logică, rezultatele sale ar trebui să fie exact mai bune decât noul venit în acest domeniu. Dar, cu selecția cheii, totul se dovedește exact opusul.
De ce în 90% din cazuri, un nou venit face mai bine profesioniști?
E totul despre calea. Sarcina semantistă nu colectează cel mai bun kernel pentru dvs., ci pentru a vă îndeplini munca pentru timpul minim și că calitatea sa aranjată.
Dacă faci totul pentru acei algoritmi despre care au spus ei devreme - rezultatul va fi un ordin de mărime mai mare din două motive:
- Înțelegeți subiectul. Deci, știți nevoile clienților dvs. sau ale utilizatorilor site-ului dvs. și puteți în etapa inițială pentru a extinde cererile de marcare pentru parsare, folosind un număr mare de sinonime și cuvinte specifice.
- Vrei să faci totul calitativ. Proprietarul de afaceri sau angajat al companiei în care funcționează, desigur, vine la întrebarea mai responsabil și va încerca să facă totul la maxim. Cu cât depășește mai mult kernelul și cererile mai scăzute de competitive în acesta, cu atât mai mult va fi posibil să se asambleze traficul țintă și, prin urmare, să profite de aceleași investiții în conținut va fi mai mare.
Cum de a găsi restul de 10% care fac ca kernelul să fie mai bun decât tine?
Căutați companii în care selecția frazelor cheie este competența esențială. Și discutați imediat ce rezultatul doriți, ca oricine altcineva sau maxim. În al doilea caz, va fi de 2-3 ori mai scump, dar pe termen lung se plătește în mod repetat. Pentru cei care doresc să comande un serviciu cu mine, toate informațiile și condițiile necesare. Calitate garantata!
De ce este atât de important să lucrați pe deplin de semantică
Aici, ca în orice sferă, principiul "selecției bune și rele" funcționează. Care este esența lui?
În fiecare zi ne confruntăm cu faptul că alegem:
- adică cu o persoană care pare a fi nimic, dar nu se agață sau dezamăgitoare în sine pentru a construi relații armonioase cu cei care au nevoie;
- munca care nu-i place sau nu găsește o muncă, atunci ce sufletul mințește și o face cu profesia ta;
- Închiriați o cameră pentru magazin într-un punct necorespunzător sau încă așteptați până când vă eliberați, opțiunea corespunzătoare;
- luați echipa nu cel mai bun manager. Vânzări și unul care sa dovedit mai bine la interviul de astăzi.
Se pare că totul este clar. Și dacă te uiți la ea, pe de altă parte, prezentând fiecare alegere ca o investiție în viitor. Aici începe cel mai interesant!
Salvat pe acest lucru. kernel, 3-5 mii. Satisfăcut ca elefanții! Dar ceea ce duce la:
a) pentru site-uri de informare:
- Pierderi privind traficul de cel puțin 1,5 ori cu aceleași investiții în conținut. Comparând. metode diverse Obținerea frazelor cheie, am aflat deja modul în care o metodă alternativă vă permite să colectați 51% mai mult;
- Proiectul trimite rapid în extrădare. Concurenții sunt ușor de realizat în jurul nostru, oferind un răspuns mai complet asupra intensității.
b) pentru proiecte comerciale:
- Mai puțin conduc sau își sporesc costul. Dacă avem semantică, la fel ca toți ceilalți, ne îndreptăm pe aceleași cereri ca și concurenții. Un numar mare de Sugestiile cu o cerere constantă reduce cota fiecăruia pe piață;
- Conversie scăzută. Cereri specifice Mai bine convertite la vânzări. Economisiți la șapte. Kernel, pierdem cele mai multe chei de conversie;
- Mai greu de avansat. Mulți care doresc să fie în top - deasupra cerințelor pentru fiecare dintre candidați.
Vă doresc întotdeauna să faceți o alegere buna Și să investească numai în plus!
P.S. Bonus "Cum să scrieți un articol bun cu semantica rea", precum și alte vieți de viață și câștiguri pe Internet, citiți în grupul meu

































