Dotazy v Accessu jsou primárním nástrojem pro získávání, aktualizaci a manipulaci s daty v databázových tabulkách. Access v souladu s koncepcí relačních databází používá k provádění dotazů strukturovaný dotazovací jazyk (SQL). Jakýkoli dotaz v Accessu je implementován pomocí příkazů SQL.
Hlavním typem dotazu je výběrový dotaz. Výsledkem tohoto dotazu je nová tabulka, která existuje před uzavřením dotazu. Záznamy jsou tvořeny kombinací záznamů tabulek, na kterých je dotaz postaven. Způsob kombinování záznamů tabulky je určen při definování jejich vztahu v datovém schématu nebo při vytváření dotazu. Výběrové podmínky formulované v dotazu umožňují filtrovat záznamy, které tvoří výsledek spojování tabulek.
Access může vytvářet několik typů dotazů:
- žádost o načtení- vybírá data z jedné tabulky nebo dotazu nebo více souvisejících tabulek a dalších dotazů. Výsledkem je tabulka, která existuje před uzavřením dotazu. Tvorba záznamů výsledkové tabulky se provádí v souladu se stanovenými podmínkami výběru a při použití více tabulek spojením jejich záznamů;
- dotaz na vytvoření tabulky- vybere data z propojených tabulek a dalších dotazů, ale na rozdíl od výběrového dotazu uloží výsledek do nové trvalé tabulky;
- aktualizovat, přidávat, mazat požadavky- jsou akční požadavky, v důsledku kterých se mění údaje v tabulkách.
Dotazy v Accessu v návrhovém režimu obsahují datové schéma, které zobrazuje použité tabulky, a formulář dotazu, který konstruuje strukturu tabulky dotazu a podmínky pro výběr záznamů (obrázek 4.1).
Pomocí dotazu můžete provádět následující typy zpracování dat:
- zahrnout do tabulky dotazu uživatelem vybraná pole tabulky;
- provádět výpočty v každém z přijatých záznamů;
- vybrat záznamy, které splňují kritéria výběru;
- vytvořit novou virtuální tabulku založenou na spojení záznamů souvisejících tabulek;
- skupinové záznamy, které mají stejné hodnoty v jednom nebo několika polích, současně provádějí statistické funkce na jiných polích skupiny a zahrnují jeden záznam pro každou skupinu ve výsledku;
- vytvořit novou databázovou tabulku pomocí dat z existujících tabulek;
- aktualizovat pole ve vybrané podmnožině záznamů;
- odstranit vybranou podmnožinu záznamů z databázové tabulky;
- přidat vybranou podmnožinu záznamů do jiné tabulky.
Dotazy v Accessu slouží jako zdroje záznamů pro další dotazy, formuláře, sestavy. Pomocí dotazu můžete z několika tabulek shromáždit kompletní informace pro vytvoření určitého dokumentu předmětné oblasti a následně z nich vytvořit formulář - elektronickou reprezentaci tohoto dokumentu. Pokud průvodce vytvoří formulář nebo sestavu na základě několika propojených tabulek, automaticky se pro ně vygeneruje dotaz jako zdroj záznamů.
Chcete-li konsolidovat, podívejte se na video tutoriál.
Žádosti jsou psány bez uvozovek, od MySQL, MS SQL a PostGree jsou rozdílní.
SQL dotaz: získání specifikovaných (povinných) polí z tabulky
SELECT id, country_title, count_people FROM table_nameZískáme seznam záznamů: VŠECHNY země a jejich populace. Názvy povinných polí jsou odděleny čárkami.
SELECT * FROM název_tabulky
* označuje všechna pole. To znamená, že budou dojmy VŠECHNO datová pole.
SQL dotaz: výstup záznamů z tabulky s výjimkou duplikátů
SELECT DISTINCT country_title FROM table_nameZískáme seznam záznamů: země, kde se nacházejí naši uživatelé. Může být mnoho uživatelů z jedné země. V tomto případě je to váš požadavek.
SQL dotaz: zobrazení záznamů z tabulky podle zadané podmínky
SELECT id, country_title, city_title FROM table_name WHERE count_people> 100000000Získáme seznam rekordů: země, kde je počet lidí vyšší než 100 000 000.
SQL dotaz: zobrazení záznamů z tabulky s řazením
SELECT id, název_města FROM název_tabulky ORDER BY název_městaZískáme seznam záznamů: města v abecedním pořadí. Na začátku A, na konci I.
SELECT id, název_města FROM název_tabulky ORDER BY název_města DESC
Získáme seznam záznamů: města obráceně ( DESC) OK. Na začátku já, na konci A.
SQL dotaz: počítání počtu záznamů
VYBERTE POČET (*) FROM název_tabulkyDostaneme počet (počet) záznamů v tabulce. V tomto případě NEEXISTUJE ŽÁDNÝ seznam záznamů.
SQL dotaz: výstup požadovaného rozsahu záznamů
SELECT * FROM název_tabulky LIMIT 2, 3Z tabulky získáme 2 (druhý) a 3 (třetí) záznamy. Požadavek je užitečný při vytváření navigace na WEB stránkách.
SQL dotazy s podmínkami
Výstup záznamů z tabulky podle dané podmínky pomocí logických operátorů.
SQL dotaz: konstrukce AND
SELECT id, city_title FROM table_name WHERE country = "Rusko" AND oil = 1Dostáváme seznam záznamů: města z Ruska A mít přístup k ropě. Při použití operátoru A, pak se musí obě podmínky shodovat.
SQL dotaz: konstrukce NEBO
SELECT id, city_title FROM table_name WHERE country = "Rusko" OR country = "USA"Získáme seznam záznamů: všechna města z Ruska NEBO USA. Při použití operátoru NEBO, pak musí odpovídat alespoň jedna podmínka.
SQL dotaz: AND NOT konstrukt
SELECT id, user_login FROM table_name WHERE country = "Russia" AND NOT count_comments<7Získáme seznam záznamů: všichni uživatelé z Ruska A kdo vyrobil NE MÉNĚ 7 komentářů.
SQL dotaz: konstrukce IN (B).
SELECT id, user_login FROM table_name WHERE country IN ("Rusko", "Bulharsko", "Čína")Získáme seznam záznamů: všichni uživatelé, kteří žijí v ( V) (Rusko nebo Bulharsko nebo Čína)
SQL dotaz: NENÍ VE výstavbě
SELECT id, user_login FROM table_name WHERE country NOT IN ("Rusko", "Čína")Získáme seznam záznamů: všichni uživatelé, kteří nežijí v ( NE V) (Rusko nebo Čína).
SQL dotaz: konstrukce IS NULL (prázdné nebo NE prázdné hodnoty)
SELECT id, user_login FROM table_name WHERE status IS NULLZískáme seznam záznamů: všichni uživatelé, kde není definován stav. NULL je samostatné téma, a proto se kontroluje samostatně.
SELECT id, user_login FROM table_name WHERE state IS NOT NULL
Získáme seznam záznamů: všichni uživatelé, kde je definován stav (NE NULA).
SQL dotaz: konstrukce LIKE
SELECT id, user_login FROM table_name WHERE příjmení LIKE "Ivan%"Získáme seznam záznamů: uživatelé, jejichž příjmení začíná kombinací „Ivan“. Znak % znamená JAKÝKOLI počet JAKÝCHKOLI znaků. Chcete-li najít znak %, musíte použít escapující "Ivan \%".
SQL dotaz: konstrukt BETWEEN
SELECT id, user_login FROM table_name WHERE plat MEZI 25000 A 50000Získáme seznam záznamů: uživatelé, kteří dostávají platy od 25 000 do 50 000 včetně.
Logických operátorů je HODNĚ, proto si podrobně prostudujte dokumentaci k SQL serveru.
Složité SQL dotazy
SQL dotaz: kombinace více dotazů
(SELECT id, user_login FROM table_name1) UNION (SELECT id, user_login FROM table_name2)Získáme seznam záznamů: uživatelé, kteří jsou registrováni v systému, a také uživatelé, kteří jsou registrováni na fóru samostatně. S operátorem UNION lze kombinovat více dotazů. UNION se chová jako SELECT DISTINCT, to znamená, že zahodí duplicitní hodnoty. Chcete-li získat absolutně všechny záznamy, musíte použít operátor UNION ALL.
SQL dotaz: počítání hodnot polí MAX, MIN, SUM, AVG, COUNT
Výstup jedna, maximální hodnota čítače v tabulce:
SELECT MAX (počítadlo) FROM název_tabulkyVýstup jedna, minimální hodnota čítače v tabulce:
SELECT MIN (počítadlo) FROM název_tabulkyZobrazení součtu hodnot všech čítačů v tabulce:
SELECT SUM (počítadlo) FROM název_tabulkyZobrazení průměrné hodnoty počítadla v tabulce:
VYBERTE AVG (počítadlo) FROM název_tabulkyZobrazení počtu počítadel v tabulce:
SELECT COUNT (počítadlo) FROM název_tabulkyZobrazení počtu přepážek v dílně č. 1, v tabulce:
SELECT COUNT (pult) FROM table_name WHERE office = "Obchod č. 1"Toto jsou nejoblíbenější příkazy. Tam, kde je to možné, se doporučuje používat pro výpočty SQL dotazy tohoto druhu, protože žádné programovací prostředí se nemůže porovnávat v rychlosti zpracování dat než samotný SQL server při zpracování vlastních dat.
SQL dotaz: seskupování záznamů
SELECT kontinent, SUM (country_area) FROM země GROUP BY kontinentuDostaneme seznam záznamů: s názvem kontinentu a se součtem rozloh všech jejich zemí. To znamená, že pokud existuje adresář zemí, kde má každá země zaznamenanou svou oblast, pak pomocí klauzule GROUP BY můžete zjistit velikost každého kontinentu (na základě seskupení podle kontinentu).
SQL dotaz: pomocí více tabulek přes alias
SELECT o.order_no, o.amount_paid, c.company FROM orders AS o, customer AS with WHERE o.custno = c.custno AND c.city = "Tyumen"Získáváme seznam záznamů: objednávky od zákazníků, kteří žijí pouze v Ťumenu.
U správně navržené databáze tohoto typu je totiž dotaz nejčastější, proto byl v MySQL zaveden speciální operátor, který pracuje mnohonásobně rychleji než výše napsaný kód.
SELECT o.order_no, o.amount_paid, z.company FROM orders AS o LEFT JOIN customer AS z ON (z.custno = o.custno)
Vnořené poddotazy
SELECT * FROM název_tabulky WHERE plat = (SELECT MAX (plat) FROM zaměstnance)Získáme jeden záznam: informace o uživateli s maximální mzdou.
Pozornost! Vnořené poddotazy jsou jedním z úzkých míst na serverech SQL. Spolu se svou flexibilitou a výkonem také výrazně zvyšují zátěž serveru. Což vede ke katastrofálnímu zpomalení práce ostatních uživatelů. Případy rekurzivních volání s vnořenými dotazy jsou velmi časté. Proto důrazně doporučuji NEPOUŽÍVAT vnořené dotazy, ale rozdělit je na menší. Nebo použijte výše uvedenou kombinaci LEFT JOIN. Kromě tohoto typu požadavků jsou požadavky zvýšeným ohniskem narušení bezpečnosti. Pokud se rozhodnete použít vnořené poddotazy, musíte je navrhnout velmi pečlivě a provést počáteční spuštění na kopiích databází (testovacích databázích).
SQL dotazy mění data
SQL dotaz: INSERT
Instrukce VLOŽIT umožňují vkládat záznamy do tabulky. Jednoduše řečeno, vytvořte v tabulce řádek s daty.
Možnost číslo 1. Často se používá instrukce:
INSERT INTO table_name (id, user_login) VALUES (1, "ivanov"), (2, "petrov")Ve stole " název_tabulky"Najednou budou vloženi 2 (dva) uživatelé.
Možnost číslo 2. Je pohodlnější použít styl:
INSERT název_tabulky SET id = 1, user_login = "ivanov"; INSERT název_tabulky SET id = 2, user_login = "petrov";To má své výhody i nevýhody.
Hlavní nevýhody:
- Mnoho malých SQL dotazů běží o něco pomaleji než jeden velký SQL dotaz, ale ostatní dotazy budou zařazeny do fronty pro službu. To znamená, že pokud je po dobu 30 minut prováděn velký SQL dotaz, pak po celou tuto dobu bude zbytek dotazů kouřit bambus a čekat, až na ně přijde řada.
- Požadavek se ukazuje být masivnější než předchozí verze.
Hlavní výhody:
- Během malých SQL dotazů nejsou ostatní SQL dotazy blokovány.
- Snadnost čtení.
- Flexibilita. V této volbě nelze sledovat strukturu, ale přidávat pouze potřebné údaje.
- Při vytváření archivů tímto způsobem můžete snadno zkopírovat jeden řádek a spustit jej přes příkazový řádek (konzole), čímž neobnovíte celý ARCHIV.
- Styl psaní je podobný příkazu UPDATE, což usnadňuje zapamatování.
SQL dotaz: AKTUALIZACE
UPDATE table_name SET user_login = "ivanov", user_surname = "Ivanov" WHERE id = 1Ve stole " název_tabulky"V záznamu s id = 1 budou hodnoty polí user_login a user_surname změněny na zadané hodnoty.
SQL dotaz: DELETE
DELETE FROM název_tabulky WHERE id = 3Záznam s ID číslem 3 bude v tabulce název_tabulky smazán.
- Pro kompatibilitu s různými programovacími jazyky, jako jsou Delphi, Perl, Python a Ruby, se doporučuje psát všechny názvy polí malými písmeny a v případě potřeby je oddělit vynucenou mezerou „_“.
- Kvůli čitelnosti pište příkazy SQL VELKÝMI písmeny. Vždy si pamatujte, že kód po vás mohou přečíst jiní lidé a s největší pravděpodobností vy sami po N množství času.
- Pole pojmenujte od začátku podstatného jména a poté akci. Například: city_status, user_login, user_name.
- Snažte se vyhnout záložním slovům v různých jazycích, která mohou způsobit problémy v SQL, PHP nebo Perl, jako je (název, počet, odkaz). Například: odkaz lze použít v MS SQL, ale je vyhrazen v MySQL.
Tento materiál je krátkou referencí pro každodenní práci a netvrdí, že je super mega autoritativním zdrojem, který je primárním zdrojem SQL dotazů pro konkrétní databázi.
Každý z nás se pravidelně setkává a využívá různé databáze. Když si vybereme emailovou adresu, pracujeme s databází. Databáze využívají vyhledávače, banky k ukládání zákaznických dat atd.
Ale navzdory neustálému používání databází existuje i pro mnoho vývojářů softwarových systémů mnoho „prázdných míst“ kvůli různým výkladům stejných pojmů. Než se podíváme na jazyk SQL, stručně definujeme základní databázové pojmy. Tak.
Databáze - soubor nebo sada souborů pro ukládání uspořádaných datových struktur a jejich vztahů. Velmi často se řídicímu systému říká databáze – je to pouze úložiště informací v určitém formátu a může pracovat s různými DBMS.
stůl - Představte si složku, ve které jsou uloženy dokumenty seskupené podle určitého kritéria, například seznam objednávek za poslední měsíc. Toto je tabulka v počítači. Samostatná tabulka má svůj jedinečný název.
Datový typ - druh informací, které mohou být uloženy v samostatném sloupci nebo řádku. Mohou to být čísla nebo text ve specifickém formátu.
Sloupec a řádek- všichni jsme pracovali s tabulkami, které mají také řádky a sloupce. Každá relační databáze pracuje s tabulkami podobným způsobem. Řádky se někdy nazývají záznamy.
Primární klíč- každý řádek tabulky může mít jeden nebo více sloupců pro svou jednoznačnou identifikaci. Bez primárního klíče je velmi obtížné aktualizovat, upravovat a mazat požadované řádky.
Co je SQL?
SQL(angličtina - strukturovaný dotazovací jazyk) byl vyvinut pouze pro práci s databázemi a v současnosti je standardem pro všechny populární DBMS. Syntaxe jazyka se skládá z malého počtu operátorů a je snadné se ji naučit. Ale i přes vnější jednoduchost umožňuje vytváření sql dotazů pro složité operace s databází libovolné velikosti.
Od roku 1992 existuje obecně uznávaný standard nazvaný ANSI SQL. Definuje základní syntaxi a funkce operátorů a je podporován všemi lídry na trhu DBMS, jako je ORACLE Není možné v jednom malém článku zvážit všechny vlastnosti jazyka, proto se krátce zamyslíme pouze nad základními SQL dotazy . Příklady jasně ukazují jednoduchost a možnosti jazyka:
- tvorba databází a tabulek;
- načítání dat;
- přidávání záznamů;
- úpravy a mazání informací.
SQL datové typy
Všechny sloupce v databázové tabulce ukládají stejný datový typ. Datové typy v SQL jsou stejné jako v jiných programovacích jazycích.
Vytvářejte tabulky a databáze

Existují dva způsoby, jak vytvořit nové databáze, tabulky a další dotazy v SQL:
- přes konzolu DBMS
- Použití online administračních nástrojů, které jsou součástí databázového serveru.
Operátor vytvoří novou databázi VYTVOŘIT DATABÁZI<наименование базы данных>; ... Jak vidíte, syntaxe je jednoduchá a stručná.
Tabulky uvnitř databáze vytváříme pomocí příkazu CREATE TABLE s následujícími parametry:
- název tabulky
- názvy sloupců a datové typy
Jako příklad vytvoříme tabulku komodit s následujícími sloupci:
Vytvoříme tabulku:
VYTVOŘIT TABULKU Komodita
(id_komodity CHAR (15) NOT NULL,
vendor_id CHAR (15) NOT NULL,
název_komodity CHAR (254) NULL,
commodity_price DECIMAL (8,2) NULL,
commodity_desc VARCHAR (1000) NULL);
Tabulka má pět sloupců. Za názvem následuje datový typ, sloupce jsou odděleny čárkami. Hodnota sloupce může být null (NULL) nebo musí být vyplněna (NOT NULL), což je určeno při vytváření tabulky.
Načítání dat z tabulky

Operátor výběru dat je nejčastěji používaným SQL dotazem. Pro získání informací je nutné uvést, co chceme z takové tabulky vybrat. Začněme jednoduchým příkladem:
SELECT název_komodity FROM Komodita
Po příkazu SELECT specifikujeme název sloupce, abychom získali informace, a FROM definuje tabulku.
Výsledkem provedení dotazu budou všechny řádky tabulky s hodnotami Commodity_name v pořadí, v jakém byly vloženy do databáze, tzn. bez jakéhokoli třídění. K uspořádání výsledku se používá dodatečná klauzule ORDER BY.
U dotazu na několik polí je uvádíme oddělená čárkami, jako v následujícím příkladu:
SELECT commodity_id, commodity_name, commodity_price FROM Commodity
Je možné získat hodnotu všech sloupců řádku jako výsledek dotazu. Chcete-li to provést, použijte znak "*":
VYBERTE * Z Komodity
- SELECT navíc podporuje:
- Řazení dat (OBJEDNAT PODLE operátora)
- Výběr podle podmínek (KDE)
- Termín seskupení (GROUP BY)
Přidejte řádek

Pro přidání řádku do tabulky se používají SQL dotazy s příkazem INSERT. Přidání lze provést třemi způsoby:
- přidat nový celý řádek;
- část provázku;
- výsledky dotazu.
Chcete-li přidat celý řádek, musíte zadat název tabulky a hodnoty sloupců (polí) nového řádku. Uveďme příklad:
INSERT IN TO Commodity VALUES ("106", "50", "Coca-Cola", "1,68", "Bez alkoholu,)
Příklad přidá do tabulky nový produkt. Hodnoty jsou uvedeny po VALUES pro každý sloupec. Pokud pro sloupec neexistuje žádná odpovídající hodnota, je nutné zadat hodnotu NULL. Sloupce jsou vyplněny hodnotami v pořadí určeném při vytváření tabulky.
Pokud přidáte pouze část řádku, musíte explicitně zadat názvy sloupců, jako v příkladu:
INSERT INTO Commodity (commodity_id, vendor_id, commodity_name)
VALUES ("106", '50 "," Coca-Cola ",)
Zadali jsme pouze identifikátory produktu, dodavatele a jeho název a zbývající pole jsme nechali prázdná.
Přidání výsledků dotazu
INSERT se používá hlavně k přidávání řádků, ale lze jej také použít k přidání výsledků příkazu SELECT.
Změna dat

Chcete-li změnit informace v polích databázové tabulky, musíte použít příkaz UPDATE. Operátor lze použít dvěma způsoby:
- Všechny řádky v tabulce jsou aktualizovány.
- Pouze pro konkrétní linku.
UPDATE má tři hlavní prvky:
- tabulka, ve které je třeba provést změny;
- názvy polí a jejich nové hodnoty;
- podmínky pro výběr řádků ke změně.
Podívejme se na příklad. Řekněme, že se změnily náklady na položku s ID = 106, takže tento řádek je třeba aktualizovat. Píšeme následující operátor:
AKTUALIZACE SADA komodit commodity_price = "3,2" WHERE commodity_id = "106"
Uvedli jsme název tabulky, v našem případě Komodita, kde bude aktualizace provedena, poté po SET - novou hodnotu sloupce a našli požadovaný záznam zadáním požadované hodnoty ID do WHERE.
Chcete-li upravit více sloupců, za příkazem SET se zadá více párů sloupec-hodnota oddělených čárkami. Podívejme se na příklad, který aktualizuje název a cenu produktu:
AKTUALIZACE SADA komodit commodity_name = 'Fanta', commodity_price = "3.2" WHERE commodity_id = "106"
Chcete-li odstranit informace ve sloupci, můžete jej nastavit na hodnotu NULL, pokud to struktura tabulky umožňuje. Je třeba si uvědomit, že NULL je přesně "žádná" hodnota a nikoli nula ve formě textu nebo čísel. Smažeme popis produktu:
AKTUALIZACE SADA komodit commodity_desc = NULL WHERE id_komodity = "106"
Mazání řádků

SQL dotazy k odstranění řádků v tabulce jsou prováděny příkazem DELETE. Existují dva případy použití:
- některé řádky jsou v tabulce odstraněny;
- všechny řádky v tabulce jsou odstraněny.
Příklad odstranění jednoho řádku z tabulky:
DELETE FROM Commodity WHERE commodity_id = "106"
Po DELETE FROM zadáme název tabulky, ve které budou řádky smazány. Klauzule WHERE obsahuje podmínku, podle které budou vybrány řádky pro smazání. V příkladu odstraňujeme řádek pro produkt s ID = 106. Je velmi důležité upřesnit KDE. vynechání tohoto příkazu smaže všechny řádky v tabulce. To platí i pro změnu hodnoty polí.
Příkaz DELETE neobsahuje názvy sloupců ani metaznaky. Odstraní řádky úplně, ale nemůže odstranit jediný sloupec.
Použití SQL v aplikaci Microsoft Access

Obvykle se používá interaktivně k vytváření tabulek, databází, ke správě, úpravám, analýze dat v databázi a k vkládání dotazů SQL Access prostřednictvím pohodlného interaktivního návrháře dotazů (Query Designer), pomocí kterého můžete vytvářet a okamžitě spouštět příkazy SQL libovolného složitost...
Podporován je i režim přístupu k serveru, ve kterém lze Access DBMS použít jako generátor SQL dotazů na libovolný ODBC zdroj dat. Tato schopnost umožňuje aplikacím Access interakci s jakýmkoli formátem.
SQL rozšíření
Vzhledem k tomu, že dotazy SQL nemají všechny možnosti procedurálních programovacích jazyků, jako jsou smyčky, větve atd., vyvíjejí dodavatelé databází svou vlastní verzi SQL s pokročilými funkcemi. V prvé řadě se jedná o podporu uložených procedur a standardních operátorů procedurálních jazyků.
Nejběžnější dialekty jazyka:
- Oracle Database - PL / SQL
- Interbase, Firebird - PSQL
- Microsoft SQL Server - Transact-SQL
- PostgreSQL - PL / pgSQL.
SQL na internetu
MySQL je distribuován pod GNU General Public License. Existuje komerční licence s možností vyvíjet vlastní moduly. Jako nedílná součást je součástí nejoblíbenějších sestav internetových serverů, jako jsou XAMPP, WAMP a LAMP, a je nejoblíbenějším DBMS pro vývoj aplikací na internetu.
Byl vyvinut společností Sun Microsystems a v současnosti je podporován společností Oracle Corporation. Podporovány jsou databáze až do 64 terabajtů, SQL: standard syntaxe 2003, replikace databáze a cloudové služby.
Tabulkové výrazy poddotazy jsou pojmenovány a používají se tam, kde se očekává, že tabulka existuje. Existují dva typy tabulkových výrazů:
odvozené tabulky;
zobecněné tabulkové výrazy.
Tyto dvě formy tabulkových výrazů jsou diskutovány v následujících podkapitolách.
Odvozené tabulky
Odvozená tabulka je tabulkový výraz zahrnutý v klauzuli FROM dotazu. Odvozené tabulky lze použít, když aliasy sloupců nejsou proveditelné, protože překladač SQL zpracovává jiný příkaz předtím, než je znám alias. Níže uvedený příklad se pokouší použít alias sloupce v situaci, kdy je jiná klauzule zpracována dříve, než je znám alias:
POUŽÍVEJTE SampleDb; SELECT MONTH (EnterDate) jako enter_month FROM Works_on GROUP BY enter_month;
Pokus o provedení tohoto dotazu bude mít za následek následující chybovou zprávu:
Msg 207, Level 16, State 1, Line 5 Neplatný název sloupce "enter_month". (Zpráva 207: Úroveň 16, Stav 1, Řádek 5 Neplatný název sloupce enter_month)
Příčinou chyby je, že klauzule GROUP BY je zpracována před zpracováním souvisejícího seznamu SELECT a při zpracování této skupiny není znám alias sloupce enter_month.
Tento problém lze vyřešit použitím odvozené tabulky, která obsahuje předchozí dotaz (bez klauzule GROUP BY), protože klauzule FROM se provádí před klauzulí GROUP BY:
POUŽÍVEJTE SampleDb; SELECT enter_month FROM (SELECT MONTH (EnterDate) as enter_month FROM Works_on) AS m GROUP BY enter_month;
Výsledek spuštění tohoto dotazu bude vypadat takto:
Typicky lze tabulkový výraz umístit kdekoli v příkazu SELECT, kde se může objevit název tabulky. (Výsledkem tabulkového výrazu je vždy tabulka nebo ve zvláštních případech výraz.) Následující příklad ukazuje použití tabulkového výrazu v seznamu select příkazu SELECT:
Výsledek tohoto dotazu:

Zobecněné tabulkové výrazy
Common Table Expression (CTE) je pojmenovaný tabulkový výraz podporovaný jazykem Transact-SQL. Obecné tabulkové výrazy se používají v následujících dvou typech dotazů:
nerekurzivní;
rekurzivní.
Tyto dva typy požadavků jsou popsány v následujících částech.
OTB a nerekurzivní dotazy
Jako alternativu k odvozeným tabulkám a pohledům můžete použít nerekurzivní formulář OTB. Obvykle je OTB definováno S klauzulemi a volitelný dotaz, který odkazuje na název použitý v klauzuli WITH. Klíčové slovo WITH je v Transact-SQL nejednoznačné. Abyste předešli nejednoznačnosti, ukončete příkaz před klauzulí WITH středníkem.
POUŽÍVEJTE AdventureWorks2012; SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue> (SELECT AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR (OrderDate) = "2005") AND Freight> (SELECT AVG (TotalDue) FROM Sales.Sales2WHEREDer500RyaHea 2,5;
Dotaz v tomto příkladu vybere objednávky, jejichž celkové daně (TotalDue) jsou vyšší než průměr všech daní a jejichž poplatky za dopravu (Dopravné) jsou vyšší než 40 % průměru daní. Hlavní vlastností tohoto dotazu je jeho objem, protože poddotaz musí být zapsán dvakrát. Jedním z možných způsobů, jak snížit velikost konstrukce dotazu, je vytvořit pohled, který obsahuje poddotaz. Toto řešení je však poněkud obtížné, protože vyžaduje vytvoření pohledu a jeho odstranění po ukončení provádění dotazu. Nejlepším přístupem by bylo vytvořit OTB. Níže uvedený příklad ukazuje použití nerekurzivního OTB, který zkracuje definici dotazu výše:
POUŽÍVEJTE AdventureWorks2012; WITH price_calc (year_2005) AS (SELECT AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR (OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue> (SELECT price_20055 FROM) A 05)
Syntaxe klauzule WITH v nerekurzivních dotazech je:
Parametr cte_name představuje název OTB, který identifikuje výslednou tabulku, a parametr column_list představuje seznam sloupců ve výrazu tabulky. (Ve výše uvedeném příkladu se OTB jmenuje price_calc a má jeden sloupec rok_2005.) Parametr inner_query představuje příkaz SELECT, který definuje sadu výsledků odpovídajícího tabulkového výrazu. Definovaný tabulkový výraz pak lze použít ve vnějším dotazu external_query. (Vnější dotaz ve výše uvedeném příkladu používá OTB price_calc a jeho sloupec year_2005 ke zjednodušení dvojitě vnořeného dotazu.)
OTB a rekurzivní dotazy
Tato část představuje materiál se zvýšenou složitostí. Proto se při prvním čtení doporučuje přeskočit a vrátit se k němu později. OTB mohou implementovat rekurze, protože OTB mohou obsahovat odkazy na sebe. Základní syntaxe OTB pro rekurzivní dotaz vypadá takto:
Parametry cte_name a column_list mají stejný význam jako v OTB pro nerekurzivní dotazy. Tělo klauzule WITH se skládá ze dvou dotazů kombinovaných operátorem UNION VŠECHNY... První dotaz se zavolá pouze jednou a začne sčítat výsledek rekurze. První operand operátoru UNION ALL neodkazuje na OTB. Tento dotaz se nazývá referenční dotaz nebo zdroj.
Druhý požadavek obsahuje odkaz na OTB a představuje jeho rekurzivní část. Z tohoto důvodu se nazývá rekurzivní člen. V prvním volání rekurzivní části představuje OTB reference výsledek referenčního dotazu. Rekurzivní člen používá výsledek prvního volání dotazu. Poté systém znovu zavolá rekurzivní část. Volání rekurzivního člena je ukončeno, když předchozí volání k němu vrátí prázdnou sadu výsledků.
Operátor UNION ALL zřetězí aktuálně nashromážděné řetězce a také další řetězce přidané aktuálním voláním do rekurzivního člena. (Přítomnost operátoru UNION ALL znamená, že duplicitní řádky nebudou z výsledku odstraněny.)
Nakonec parametr external_query definuje vnější dotaz, který používá OTB k získání všech volání do spojení obou členů.
K demonstraci rekurzivního formuláře OTB používáme tabulku Letadlo definovanou a vyplněnou kódem uvedeným v příkladu níže:
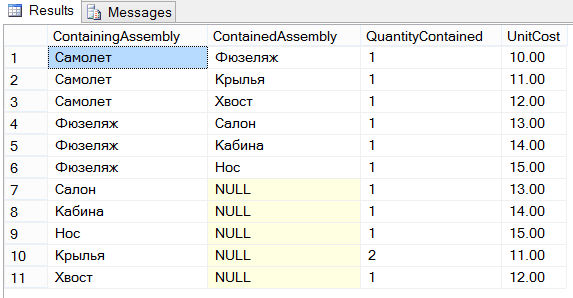
POUŽÍVEJTE SampleDb; VYTVOŘIT TABULKU Letadlo (obsahující sestavu VARCHAR (10), sestavu obsahující VARCHAR (10), množství obsažené INT, jednotkové náklady DECIMAL (6,2)); INSERT INTO Airplane VALUES ("Letadlo", "Trup", 1, 10); INSERT INTO Airplane VALUES ("Letadlo", "Křídla", 1, 11); INSERT INTO Airplane VALUES ("Letadlo", "Ocas", 1, 12); INSERT INTO Airplane VALUES ("Trup", "Salon", 1, 13); INSERT INTO Airplane VALUES ("Trup", "Kabina", 1, 14); INSERT INTO Airplane VALUES ("Trup", "Nos", 1, 15); INSERT INTO Airplane VALUES ("Salon", NULL, 1.13); INSERT INTO Airplane VALUES ("Kabina", NULL, 1, 14); INSERT INTO Airplane VALUES ("Nos", NULL, 1, 15); INSERT INTO Airplane VALUES ("Křídla", NULL, 2, 11); INSERT INTO Airplane VALUES ("Tail", NULL, 1, 12);
Tabulka Letadlo má čtyři sloupce. Sloupec ContainedAssembly identifikuje sestavu a sloupec ContainedAssembly identifikuje díly (jeden po druhém), které tvoří odpovídající sestavu. Obrázek níže poskytuje grafické znázornění možného typu letadla a jeho součástí:

Tabulka Letadlo se skládá z následujících 11 řádků:
Níže uvedený příklad ukazuje klauzuli WITH použitou k definování dotazu, který počítá celkové náklady na každé sestavení:
POUŽÍVEJTE SampleDb; WITH seznam_dílů (sestava1, množství, cena) JAKO (SELECT ContainedSembly, QuantityContained, UnitCost FROM Letadlo WHERE ContainedAssembly JE NULL UNION VŠECHNY VYBERTE a.ContainingSembly, a.QuantityContained, CAST (l.množství * l.cena JAKO DECIMAL) ) FROM seznam_dílů l, Letadlo a WHERE l.sestava1 = a.Obsahovaná Sestava) VYBERTE sestavu1 "Díl", množství "Množství", cena "Cena" ZE seznamu_dílů;
Klauzule WITH definuje seznam OTB s názvem seznam_dílů se třemi sloupci: sestava1, množství a náklady. První příkaz SELECT v příkladu je volán pouze jednou, aby se zachovaly výsledky prvního kroku procesu rekurze. Příkaz SELECT na posledním řádku příkladu zobrazí následující výsledek.
Poslední aktualizace: 07/05/2017
V předchozím tématu byla v SQL Management Studio vytvořena jednoduchá databáze s jednou tabulkou. Nyní pojďme definovat a provést první SQL dotaz. Chcete-li to provést, otevřete SQL Management Studio, klepněte pravým tlačítkem myši na prvek nejvyšší úrovně v Průzkumníku objektů (název serveru) a v zobrazené kontextové nabídce vyberte položku Nový dotaz:
Poté se v centrální části programu otevře okno pro zadávání SQL příkazů.
Spusťte dotaz na tabulku, která byla vytvořena v předchozím tématu, konkrétně z ní získáme všechna data. Naše databáze se nazývá univerzita a tabulka je dbo.Students, takže abychom získali data z tabulky, zadáme následující dotaz:
VYBERTE * Z univerzity.dbo.Studenti
Příkaz SELECT umožňuje vybrat data. FROM označuje zdroj, odkud lze data získat. Ve skutečnosti tímto dotazem říkáme „VYBRAT vše Z tabulky univerzita.dbo.Studenti“. Stojí za zmínku, že pro název tabulky je použita její úplná cesta s uvedením databáze a schématu.
Po zadání dotazu klikněte na tlačítko Execute na panelu nástrojů nebo můžete stisknout klávesu F5.
V důsledku provedení dotazu se ve spodní části programu objeví malá tabulka, která zobrazuje výsledky dotazu – tedy všechna data z tabulky Studenti.
Pokud potřebujeme provést více dotazů na stejnou databázi, můžeme k potvrzení databáze použít příkaz USE. V tomto případě při dotazech na tabulky stačí zadat jejich název bez názvu databáze a schématu:
POUŽÍVEJTE univerzitní SELECT * FROM Studenti
V tomto případě provádíme požadavek na server jako celek, můžeme přistupovat k libovolné databázi na serveru. Ale můžeme také provádět dotazy pouze v rámci konkrétní databáze. Chcete-li to provést, klikněte pravým tlačítkem myši na požadovanou databázi a v kontextovém menu vyberte položku Nový dotaz:
Pokud v tomto případě chceme provést dotaz do výše použité tabulky Studenti, pak bychom v dotazu nemuseli uvádět název databáze a schéma, protože tyto hodnoty by již byly jasné.






























")


