Paljud artiklid on kirjutatud semantilise kerneli valiku kohta, kuid on veel vigu. Kuidas kiireneda semantiline kernel Suure hulga peamisi päringuid? Kas mul on vaja laiendada semantilist kerneli aja jooksul? Kuidas levitada märksõnu lehel? Nendele ja teistele küsimustele lugege meie petma lehel.
Tähelepanu! 23. oktoobril tulevad välja järgmine väljaanne "optimeerija võrevoodi", tema teema - "CMS" .
Saada oma küsimused ja meie eksperdid vastavad teile!
Semantiline kernel
1. Kuidas teha semantiline kernel poe jaoks, kas on olemas konkreetseid funktsioone?
Semantilise kerneli tegemisel veebipoodiks ei tohiks võtta mitte ainult kõrgsageduslikke päringuid ja tootevalik suurendab ja edendaks lehekategooriate ja kaupade kaarte aktiivselt.
Seetõttu selliste ressursside vaate taotluse "Osta nokia telefon N8 " on rohkem konverteerimise ja tõhusamaks kui päringu kõrgema sagedusega "Osta telefoni".
Semantilise tuuma tegemiseks, mis viib saidi külastajate külastajad, saate kasutada kahte võimalust: automaatne ja käsiraamat.
Taotluste automaatset valikut saab teha spetsiaalsete teenuste ja programmide abil. (Näiteks online-teenus Seolib.ru, võti koguja, Slobeli jne).
Käsitsi meetod on hea, sest saate valida taotlusi TARGETi lehekülgede kohta - kaardid ja kategooriad valikukavade abil:
- "Toode + täiendavad sõnad"
- "Osta + kaup + täiendavad sõnad"
- "Müük + toode + täiendavad sõnad"
- "Hind + toode + täiendavad sõnad"
- "Omadused + toode + täiendavad sõnad"
- "Kirjeldus + toode + täiendavad sõnad"
- "Foto + toode + täiendavad sõnad" jne.
Samal ajal, semantilise tuum, me ei ole mitte ainult kaubandusliku, vaid ka teabe taotlusi, mis muudavad meie tuuma ja ankrussemaks loomulikumaks.
Näiteks kategooria kaupade "nutitelefoni Apple iPhone" online poe mobiiltelefonid Võite leida taotlusi kasutades lihtsa tabeli Excelis:
See tähendab, et tabelis olevate andmete põhjal valisime 3 Apple iPhone'i nutitelefonide ühe lehekülje ühe lehekülje kohta:
- "Osta nutitelefon Apple iPhone 3 4 GB valge »
- "Müük nutitelefoni Apple iPhone 4 8 GB Black"
- "Kirjeldus nutitelefoni Apple iPhone 5 16 GB White"
2. Kuidas valida piirkondliku uudiste saidi jaoks semantiline tuum? IT-teemad.
Valige semantiline tuum ja seejärel kirjutage selle all olevad uudised - vale lähenemisviis iga uudiste saidi jaoks, sealhulgas IT-teemad.
Uudiste saidi esmane ülesanne on operatiivse, huvitava ja asjakohase teabe avaldamine praeguste sündmuste kohta, teave, mis on täna lugejatest huvitatud. Ainult selle lähenemisviisiga suudab sait saada populaarseks, vallutada kasutaja usaldust ja seetõttu ja otsingumootoreid. Pärast seda põhimõtet moodustavad loomulikult teie saidi õige semantilise tuuma. Lõppude lõpuks nimetatakse peamised teemad (taotlused), ühel või teisel viisil ühel või teisel viisil. Kui teie vaba aeg jääb, on parem seda kulutada avaldatud materjalide kvaliteedi ja kvaliteedi suurendamise ja parandamise suurenemisele kui teatavate taotluste koostamisel artiklite ettevalmistamiseks.
3. Kas tasub kasutada kõrgsageduslikke päringuid semantilise südamikuga?
Uued saidid võivad kasutada uusi sageduslikke päringuid, kuid see sõltub teema ja konkurentsi tasandil. Mida kõrgem on konkurentsi tase, seda raskem (või võimatu) kohandada saidi edendamist, kuna otsingumootorid eelistavad vana, usaldusvahendeid.
Näiteks vaatame väljastamist Top-10 taotlusel "Kliimaseadme" (Yandex otsingumootor "Moskva"):

Sites, mille vanus on vähem kui kaks aastat, on soovitatav liikuda keskmise sageduse ja madala sagedusega taotlustele. Kasutades neid semantilise kernel, siis ei veeta eelarve edendamise ja saate meelitada sihtrühma saidile. Keskel-i. madala sageduse taotlused on kõige rohkem konversioon, mis viib potentsiaalsete klientide kohale.
4. Kuidas teha semantiline tuum tohutu hulk võtmeid? Mida see peatub ja mida sellises olukorras ära visata? Ilmselgelt on võimatu töötada mitme tuhande võtmega.
Mõned saladus ei eksisteeri - töö on hoolikalt ja vajadusel peab töötama mitme tuhande võtmega.
Töö hõlbustamiseks on olemas viise. Taotluste valiku esimeses etapis on mugav kasutada automaatseid statistika kogumisteenuseid, konfigureerimist "stopp-sõnad" ja täpsustades vajalikke piirkondi. Automaatne teenus vabaneda vajadusest käsitsi sisestada sõnu Wordstat.yandex.ru teenindusele.
Saadud taotluste loetelu tuleks jagada mitmeks prioriteetseks rühmaks. Siin, muidugi, see kõik sõltub teie konkreetse teema. Näiteks kui teil on müügi sait, vajate kõigepealt tehingutüüpe tüüpe "Osta", "Hind" jne.
5. Pärast seda, millal tasub semantilise kerneli lõpuleviimist ja laiendada ja kas see on üldse väärt?
Võite laiendada semantilist tuuma ja vajadust. See on optimaalne, et seda teha paar kuud pärast edutamist, kui peamine etapp on juba möödas ja sait on võtnud juhtivaid positsioone vähemalt 70% päringute esimesest nimekirjast.
Kerneli laiendamisel valige taotlused selliselt, et nad lõikuvad algse nimekirjaga. Vastasel juhul, kui te parandate teksti, päiseid ja meta-silte iga kord, kui saate teksti muuta, võivad otsingumootorid otsingumootorid leida ebaloomulikku ja kahtlast ja alandada saiti väljaandmisse.
Semantilise kerneli laiendamisel lisaks standardmeetodid Soovide loendi loomine on soovitatav kasutada Google.Naltics ja Yandex.Metrics andmeid.
Kuidas Data Services võib olla kasulikud, näitame YANDEX.METRICSi näites

Ja teile esitatakse kõigi taotluste loetelu, mille kohta külastati saidile külastusi, kus külastajate arv iga taotluse kohta:

Selles nimekirjas valige päringud, mis on suunatud teie ressursile ja ei kuulu esialgse semantilise südamikuga. Seejärel kontrollige saidi positsioone vastavalt vastuvõetud loendile ja saate kõigepealt võtta need päringud, mille jaoks sait ei ole top 10. Ülejäänud taotluste puhul saate perioodiliselt jälgida positsioone ja pingutage need seemnete korral.
6. Nagu semantilise tuuma moodustamisel määrake, millised prioriteetsed taotlused, mis on vabatahtlik?
Prioriteedi ja täiendavate päringute jagamiseks peate kaaluma, millist tüüpi need on seotud. Kolm tüüpi eristatakse: kõrgsagedus (HF), madala sagedusega (LF) ja kesksagedus (s). RF-päring on kõige populaarsem taotlus ja selle ümber on vähem populaarsem SCH ja LF. Seetõttu on prioriteet HF ja täiendav - SCH ja lühike. Näiteks RF taotlus - "Plastic Windows" Peamine taotlus leheküljel, SC taotlus - "Plastkeaknad Moskvas" ja LF taotlus - Täiendavad taotlused.
7. Mis peaks olema number märksõnad lehele? Täpsemalt numbritega - 3, 10, 15?
See on unikaalselt vastatud keeruliseks, sest Iga individuaalne olukord nõuab erinevaid lähenemisviise. Kõige õigesti optimeerige leht ühe HF taotluse alla, 2-3 SCH-päring ja täiendavalt - NF-i taotluste kohaselt. Logic on lihtne - üks lehekülg läheb ühe peamise taotluse, mille ümber kõike "keerutab".
Näiteks, "Plastic Windows" - RF taotlus; "Plastic Windows osta", "Plastic Windows Moskva" - SC taotlused; "Plastic Windows osta Moskvas" - LF päring. Lehekülje edendamist on raske reklaamida, kui seda taotlete optimeerida "Printimine logod" ja "kasvuhoone film". Erand on ainult kodu ", sest See peaks kirjeldama kogu koha saidi teenuseid.
Pange tähele, et täiendavate sõnadega päringuid "Osta", "Hulgimüük", "Hind" See ei ole soovitatav optimeerida teisi lehekülgi, välja arvatud see, kus peamine, kõrgsageduslik päring asub. Näiteks lehtprogramm edendati "Plastkeaknad", Tuleb liigutada ja taotluse korral "Plastic Windows osta".
8. Kas tasub müüa teabe taotlusi semantilise tuum, see on üsna hea või ei ole veel vaja selliseid taotlusi?
Kindlasti seda väärt. Kirjutamisel on see täiendav liiklus, mis võib kaasa tuua ka konversiooni. Informatsiooni sektsioonide loomisel kaubanduslikul alal on oluline järgida mitmeid põhimõtteid:
- infomaterjalid peaksid kasutajatele olema tõesti kasulikud, et teavitada neid olulist ja kasulikku teavet. On vaja valmistada kõrgekvaliteedilised väljaanded ja mitte ainult täitke sektsiooni artikleid, "teritatud" taotluste alusel;
- Ära unusta, et teie sait on peamiselt kaubanduslik. Enamiku teemade puhul ületab olukord, millal teabete arv ületab tootekaartide arvu, see on imelik;
- proovige panna lingid keha lingides müügi saidi lehekülgi. See suurendab infoliikluse tõhusust.
9. Kuidas tõhusamalt rakendada viiteid sageduste sisu sees, s.o ühe taseme seondumissageduste või LF-HF-i erinevate sagedustega väänata?
Niipalju kui me mõistame, puudutab küsimus sisemist transfine'i.
Peregonovka strateegiad Seal on suur summa, kuid me ei soovita "lisada" mõiste taotluse sageduse. On oluline, et transfine oleks kasulik. Kui viide sisu kasutab - see aitab. Kui link "surnud" ja ärge kasutage seda - selle tunnet, tõenäoliselt ei ole palju. Ja puudub erinevus, viitate RF-i päringu lehele LF-i taotlusele või vastupidi.
Loomulikult on sisemise transfine'i mõju LF taotluste jaoks märgatavam, kuna need on vähem "nõudlikud" kui suure sagedusega päringud suure konkurentsiga. Aga taas kordame seda, et soov "olla kinnitatud" konkreetsele ülejooksu algoritmile, mõtlemata, kui kasutaja vajab palju kiirendamist, mitte ainult ei aita, vaid võib kahjustada. Otsingumootorid ei meeldi rämpsposti saatjad.
10. Ma tegin semantilise tuuma, keskendudes Yandexile, kuigi mul on Ukraina sait ja enamik külastajaid tulevad Google'ist. Kas see süda sobib Google'ile (ma arvan, kas Yandex ja Google'i kasutajad Palun praktiseerige taotlusi) või peate tegema uue?
Olulised erinevused Yandexi taotlustes ja Google'i kasutajate taotlustes ei täheldata tavaliselt. Kui valiku võttis arvesse piirkonda (teie puhul Ukrainas), siis ei tohiks olla probleeme.
Mõnede teemade puhul võib piirkond oluliselt olulised (seda saab valida, kui analüüsitakse taotlusi Yandex Wordstat.). Õigusaktide erinevus või teatavate tootjate populaarsus võib põhjustada vahet. Sellisel juhul peate teie teema vaatama. Kui piirkondlikke erinevusi ei ole, siis saate valida valitud tuuma turvaliselt põhi.
11. Minu sait liigub "kaamelite" ja selle sõna taotlusel, mis on top 3. Aga vastavalt sõna "kaamel" see ei ole isegi top 30. Miks see nii? Kas mitmuse või ainus märksõna kasutamine mõjutab saidi asendit?
Jah, paljudel juhtudel mõjutab, sest Yandex, kes otsib mitmekordset ja ainult numbrit, võib see oluliselt erineda, tähendab see, et ta tajub neid taotlusi erinevalt. Lisaks on taotluste sagedusel märkimisväärne erinevus. Näiteks, kui vaatate Yandex.wordstat.ru (Moskva) taotlused "! Plastic aken" ja "Plastkeaknad", siis esimene sagedus on 7650 ja teine \u200b\u200bon 169315. Seega on väljastamine täiesti erinev, sest See on selgelt erinevad taotlused. Tutvuge selle sõnaga ettevaatlikult lehe optimeerimiseks, sest Kui valite vale vormi - kaotab liikluse.
12. Nende kaubanduslike pakkumiste puhul teevad paljud edendamisettevõtted tabeli semantilise südamiku ja iga fraasi iga-aastase hinnaga, et leida 1-3, 4-6, 7-10 positsiooni Yandexis, Google'is. Kuidas seda eelarvet kaaluda?
Küsimus on üsna keeruline, sest iga ettevõte võib omada oma koefitsiente ja see on ebamõistlik rääkida kõikidest ettevõtetest.
Tavaliselt arvutatakse päringukulu, mis põhineb selle keerukusel (teisisõnu, kui palju aega töötaja annab aega sellele taotlusele või taotlusrühmale) ja nõutav võrdlusmass. Lisaks peaksite kaaluma reklaamitavate taotluste koguarvu (mida rohkem taotlusi, odavamad neist, kuna saidi üldine võrdlusmass on suurem).
13. Küsimus on järgmine. Mul on domeen (RU), ostis 1,5 aastat tagasi. Kui ma loonud selle saidi, ma ei arvanud liiga palju ettevalmistamisel semantilise tuuma (meditsiiniteemad, 40 lehekülge indeksis, ei ole külastajaid). Tahtsin küsida - kui ma hakkan looma uue saidi selle domeeni (teine \u200b\u200bteema), juba koos semantilise tuuma ettevalmistamisel jne, sest selliseid samme töödeldakse otsingumootorite poolt, kuidas seda indekseeritakse, Pärast seda, millist aega toimub? Või kas see on parem luua uusi teemasid uue domeeni ja unustada vana (RU)?
Kui praegune sait ei kohaldata filtreid ja domeeni sobib teistele teie isikutele (pidage meeles, et see peab olema meeldejääv kasutaja ja näitama oma tegevust) - ei tohiks olla probleeme.
Kuid otsingumootorid võivad olla "ettevaatlikud" sama omaniku saidi täielikule muutustele, kuna teema järsk muutus on ebaloogiline. Kõige sagedamini muudab viidete müügi all tehtud saitide teemasid jne.
Teine punkt, millest me tahame hoiatada, on veebisaidi loomine olemasoleva semantilise tuuma all. Esialgu on vaja arendada veebisaidi kontseptsiooni, et mõista, et saate oma kasutajatele anda kasulikule oma unikaalse pakkumise kindlakstegemiseks ja veebisaidi loomisele, valige need päringud, mille sihtsulajad saavad teie juurde minna.
Re-indekseerimise periood on raske, saate navigeerida umbes kuu pikkune.
Varasemad optimeerija pettuse lehed:
Sisse sel hetkel Otsingu edendamiseks mängitakse selliseid tegureid, kuna sisu ja struktuuri mängib olulist rolli oluliseks. Kuid kuidas aru saada, mida kirjutada teksti, millised osad ja luua leheküljed saidil? Lisaks peate täpselt välja selgitama, mida täpselt teie ressursi siht külastaja on huvitatud. Kõigile nendele küsimustele vastamiseks peate semantilise kerneli kokku koguma.
Semantiline kernel - sõnade või fraaside loetelu, mis kajastavad täielikult teie saidi teema.
Artiklis ütlen teile, kuidas seda üles võtta, puhastada ja jagada struktuuri. Tulemuseks on täielik struktuur, mis on lehekülgede kaudu klastrid.
Siin on näide struktuurile purunenud taotluste tuumast:

Klastrite all mõistan teie otsingupäringute jaotust üksikute lehekülgede jaoks. See meetod on oluline nii Yandexi ja Google'i reklaamimiseks. Artiklis kirjeldan täiesti vaba viisi semantilise tuuma loomiseks, kuid ma näitan nii erinevate tasuliste teenustega võimalusi.
Pärast artikli lugemist saate õppida
- Valige oma teema jaoks õiged taotlused
- Koguge fraaside kõige täielikuma tuuma
- Puhastage ebahuvitavatest taotlustest
- Rühm ja luua struktuuri
Koguge semantiline tuum
- Luua sisuka struktuuri kohapeal
- Looge mitmetasandiline menüü
- Täitke leheküljed tekstidega ja kirjutage neile metaandmed ja pealkiri
- Koguge oma saidi positsiooni otsingumootorite soovidest
Semantilise kerneli kogumine ja klastrite kogumine
Google'i ja Yandexi õige koostamine algab teie teema peamiste sõnade määratluse määratlusega. Näiteks ma näitan oma koostamist väljamõeldud online rõivapood. Semantilise kerneli kogumiseks on kolm võimalust:
- Käsiraamat. Kasutades YANDEX WordStat Service, sisestate oma märksõnad ja käed valivad vajalikud fraasid. See meetod on piisavalt kiire, kui teil on vaja kokku panna klahve ühele lehele, aga on kaks minust.
- "Kromade" meetodi täpsus. Selle meetodi kasutamisel saate alati olulisi sõnu jääda.
- Te ei saa semantilise kerneli kokku panna suurele poele, kuigi saate lihtsustamiseks kasutada Yandex Wordstati assistendi plugina - probleem ei lahenda seda.
- Pool-Automaatne. Selles meetodis eeldan programmi kasutamist tuuma kogumiseks ja edasist käsitsi jaotust sektsioonide, lõigete, lehekülgede jms. See meetod kogumise ja klastrite semantiline kernel minu arvates on kõige tõhusam. Sellel on mitmeid eeliseid:
- Kõigi teemade maksimaalne katvus.
- Kvaliteedi jaotus
- Automaatne. Tänapäeval on mitmeid teenuseid, mis pakuvad täielikult automaatset kerneli kogumist või teie taotluste klastrite. Täielikult automaatne valik - ma ei soovita kasutada, sest Semantilise kerneli kogumise ja klastrite kvaliteet on hetkel üsna madal. Automaatsed päringud Klasterdus - populaarsuse omandamine ja toimub, kuid peate veel mõned leheküljed oma kätega ühendama, sest Süsteem ei anna ideaalset valmislahendust. Ja minu arvates sa lihtsalt segaduses ja te ei saa projekti projekti.
Kompileerimiseks ja klastrite täieliku semantilise tuuma mis tahes projekti puhul 90% juhtudest, kasutan pool-automaatset meetodit.
Niisiis, et me peame täitma järgmisi samme:
- Teemade taotluste valik
- Kerneli valimine taotluste kohta
- Puhastamine mitte-siht-päringutest
- Klastrite (murdke fraasid struktuuri)
Näide semantilise kerneli õmblusest ja ülaltoodud struktuuri rühmitamisel. Ma tuletan teile meelde, et meil on online rõivapood, alustage sillutis 1 punkti.
1. Teie teema fraaside valik
Praeguses etapis vajame tööriista Yandex Wordstatit, konkurente ja loogikat. Selles etapis on oluline kokku panna nimekirja fraasidest, mis on temaatilised kõrgsageduslikud taotlused.
Kuidas valida päringud Semantika kogumise taotlused YANDEX Wordstatiga
Tulge teenusse, valige linna, mida vajate (a) / regioon (id), sõitke kõige "rasva" oma arvamuse taotlustes ja vaadake paremat veergu. Seal leiad temaatilisi sõnu, mida vajate, nii teiste osade kui ka sageduse sünonüümide jaoks kirjutatud fraasi jaoks.

Kuidas valida taotlused enne semantilise kerneli kasutamist konkurentide abil
Sisestage otsingumootori kõige populaarsemad taotlused ja valige üks populaarsemaid saite, millest paljud olete kõige tõenäolisemalt ja sa tead.

Pöörake tähelepanu peamistesse osadesse ja säästa ennast vajalike fraaside salvestamiseks.
Praeguses etapis on oluline teha õigesti: maksimeerida igasuguseid sõnu oma teema ja ei jäta midagi, siis teie semantiline kernel on võimalikult kõige täielikum.
Meie eeskuju suhtes peame tegema nimekirja järgmistest fraasidest / märksõnadest:
- Riietus
- Jalatsid
- Saapad
- Kleidid
- T-särgid
- Aluspesu
- Lühikesed püksid
Millised fraasid sisenevad mõttetuks: Naiste riided, osta kingad, kleit lõpetamist jne. Miks? - Need fraasid on "riided" päringud "SABLES", "kingad", "kleidid" ja lisatakse semantilisele kernelile automaatselt kogumise 2. etapis. Need. Saate neid lisada, kuid see on mõttetu topelttöö.
Milliseid võtmeid peate sobima? "Harfoots", "saapad" ei ole samad kui "saapad". See on oluline sõna vorm, mis on oluline, mitte üksikuid sõnu või mitte.
Keegi on nimekiri võtmelaused pikk ja kes ta koosneb ühest sõnast - Ärge kartke. Näiteks on semantilise kerneli ettevalmistamiseks mõeldud uste poe poes üsna piisavalt sõnu "Uksed".
Ja nii, selle sammu lõpus peaks meil olema sarnane nimekiri.

2. Semantilise kerneli taotluste kogumine
Nõuetekohase täieliku kogumise jaoks vajame programmi. Ma näitan samal ajal eeskuju kahe programmiga:
- Paide - võtmekollektori. Neile, kes on või kes tahavad osta.
- Tasuta - Slovoeb. Tasuta programm neile, kes ei ole valmis raha kulutama.
Avage programm

Loovutama uus projekt Ja helistame seda, näiteks MySite'i

Nüüd, semantilise kerneli edasiseks kogumiseks peame tegema mõned asjad:
Loo uus konto Yandex Mail (Vana see ei ole soovitatav kasutada asjaolu tõttu, et seda saab keelata paljude taotluste jaoks). Niisiis, te loonud näiteks konto [E-posti kaitstud] Parooli Super2018. Nüüd peate määrama selle konto Seadetes AS Ivan.ivanov: Super2018 ja vajutage allosas nuppu "Salvesta muudatused". Loe edasi - Screenshots.

Me valime piirkonna, et kompileerida semantiline kernel. Sa pead valima ainult piirkonnad, kus te liigute ja klõpsake nuppu Salvesta. Sellest sõltub taotluste sagedusest ja kas nad jäävad põhimõtteliselt kogumisse.

Kõik seaded on lõpetatud, jääb meie kurja fraasi lisamiseks esimeses etapis ja klõpsake semantilise kerneli nuppu "Start Collection".

Protsess on täielikult automaatne ja piisavalt pikk. Kohvi tegemisel saate kohvi teha ja kui teema on lai, näiteks nagu see, mida me kogume - see on mitu tundi 😉
Kui kõik fraasid koguvad teid, et näha midagi sarnast:

Ja sellel etapil on lõpetatud - jätkake järgmisele sammule
3. Semantilise kerneli puhastamine
Esiteks peame kustutama taotlused, mida me ei huvita (Neurozzi):
- Seotud teise kaubamärgiga, näiteks "Gloria teksad", "ECCO"
- Teabe taotlused, näiteks "Ma kannan saapad", "teksad suurus"
- Sarnaselt objektil, kuid mitte seotud teie ettevõttega, näiteks "B rõivad", "Naiste hulgimüük"
- Taotlused, mitte mingil juhul seotud teemaga, näiteks "Sims kleidid", "kassi saapad" (sellised taotlused pärast semantilise tuuma valimist on üsna palju)
- Teiste piirkondade taotlused, Metro, linnaosad, tänavatel (olenemata sellest, millises piirkonnas olete kogutud taotlused - teine \u200b\u200bpiirkond on ikka veel olemas)
Puhastamine tuleb läbi viia käsitsi järgmiselt:

Me sisestame sõna, vajutage "Enter", kui meie loodud semantilise kernel on need fraase, mida me vajame, me eraldame leitud ja klõpsake nuppu Kustuta.
Soovitan sisestada sõna mitte täielikult, vaid kasutades disaini ilma eeltingimusteta ja lõppu, st Kui me kirjutame sõna "au", leiame ta fraase "Osta Gloria teksad" ja "Osta Gloria teksad". Kui kirjutate "Gloria" - "Gloria" ei leitud.
Seega peate läbima kõik punktid ja eemaldage semantilisest kernelile tarbetute taotluste hulgast. See võib võtta märkimisväärse aja ja võib-olla väljub see, et eemaldate suurema osa kogutud päringutest, kuid tulemus on täieõiguslik puhastus ja õige loend igasuguste reklaamitavate taotluste kohta.
Lahendage nüüd kõik teie taotlused Excelile

Samuti saate semantilistest päringutest massiivselt eemaldada, tingimusel et teil on nimekiri. Seda saab teha stop-sõnadega ja seda on lihtne teha tüüpilise sõnade rühma linnade, metrooga, tänavatel. Nimekiri sellistest sõnadest, mida ma kasutan, saate alla laadida lehe allosas.
4. Semantilise kerneli klastrite
See on kõige olulisem ja huvitavam osa - on vaja jagada meie määrused lehekülgede ja osade kohta, mis agregaadis loovad teie saidi struktuuri. Natuke teooria - kui taotluste juhindumine:
- Võistlejad. Võite pöörata tähelepanu sellele, kuidas semantiline kernel oma konkurentidelt ülevalt ja tegutseda sarnaselt, vähemalt peamiste osadega. Ja ka vaadata, millised leheküljed on madala sagedusega taotluste väljaandmisel. Näiteks, kui te ei ole kindel, et "teha või mitte" eraldi sektsiooni "punane nahast seelik" taotlus, juhtige fraasi otsingumootori ja vaata väljastusi. Kui väljastamine sisaldab ressursse, kus on selliseid sektsioone, tähendab see, et see on mõttekas teha eraldi lehekülge.
- Logics. Tehke kogu semantilise kerneli grupeerimise loogika abil: struktuur peab olema selge ja esindama oma peaga lehekülgede struktureeritud lehte.
Ja paar rohkem nõu:
- Leheküljele ei soovitata paigaldada vähem kui 3 taotlust.
- Ärge tehke liiga palju pesitseva taset, proovige seda teha, et nad oleksid 3-4 (Site.ru / Kategooria / alamkategooria / alamkategooria)
- Ära tee pikad URL-id, kui semantilise kerneli klastriks on palju pesitsemise tasemeid, proovige vähendada kõrgelt kategooriate hierarhiat, st "Vash-site.ru/zhenskaya-odezhda/palto-Dlya-Palto asemel" vah-site.ru/zhenshinam/palto / krasnoe "asemel
Nüüd harjutada
Näites oleva tuuma klastrite
Alustamiseks jagame kõiki põhikategooriate taotlusi. Võistlejate loogika vaatamine - rõivapoodide peamised kategooriad on: Meeste rõivad, naiste rõivad, lasteriided, samuti hulk teisi kategooriaid, mis ei ole seotud põranda / vanusega, näiteks lihtsalt "kingad" , ülerõivad.
Me gruppi semantiline tuum on siis, kui excel abi. Avage meie fail ja tegu:
- Me jagame peamisi sektsioone
- Võtke üks osa ja jagage see §-s
Ma näitan ühe osa - meeste riided ja selle alajao. Teiste võtmete eraldamiseks peate esile tõstma kogu lehte ja klõpsake tingimusliku vormingu-\u003e koodi valiku reegleid-\u003e Tekst sisaldab

Nüüd aknas, mis avaneb, kirjutame me "abikaasa" ja vajutage Enter.

Nüüd on kõik meie meeste riiete võtmed esile tõstetud. See on piisav, et filtrit kasutada valitud võtmete eraldamiseks ülejäänud meie kokkupandud semantilisest kernelist.
Nii et lülitage filtri sisse: peate veergu esile tõstma ja vajutage sorteerimis- ja filtreerimis-\u003e filtreerige

Ja nüüd sorteeritud

Loo eraldi leht. Lõika valitud jooned ja sisestage need seal. Nii peate kerneli jätkata ja murdma.
Muutke selle lehe nime "meeste riietele", leht, kus kõik muu on semantiline kernel, nimi "Kõik taotlused". Seejärel looge teine \u200b\u200bleht, nimi see "struktuur" ja pane see kõigepealt. Struktuuri lehel luua puu. Sa peaksid nüüd sellist õnnestunud:

Nüüd peame jagama suur osa meeste riided §-st ja allsektsioone.
Kasutamise ja üleminekute mugavuse huvides teie klastrite semantilise kerneli järgi asetage viited struktuurile sobivatele lehtedele. Selle tegemiseks paremklõpsake soovitud elemendil struktuuri ja teha nagu ekraanipilte.

Ja nüüd peame eraldama oma käed taotluste jagamiseks, eemaldades samaaegselt seda, mida ei pruugi olla märganud ja eemaldatud kerneli puhastusfaasis. Lõppkokkuvõttes tänu semantilise kerneli klastrisse peaksite olema selle sarnase struktuuri:


Nii. Mida me õppinud tegema:
- Vali taotlused, mida vajate semantilise kerneli kogumiseks
- Koguge nende taotluste kõik võimalikud fraasid
- Puhas
- Klaster ja luua struktuuri
See tänu sellise kloseeritud semantilise kerneli loomisele saate teha:
- Looge kohapeal struktuur
- Loo menüü
- Tekstite kirjutamine, Metauring, Taitla
- Koguge positsioone kõnelejate jälgimiseks taotlustes
Nüüd vähe programme ja teenuseid
Programmid semantilise kerneli kogumiseks
Siin kirjeldan mitte ainult programme, vaid ka pluginad ja võrguteenuseid, mida ma kasutan
- Yandex Wordstati assistent on plugin, tänu sellele on mugav valida Vordstati taotlused. Suurepärane väikese saidi või 1 lehekülje kiire koostamiseks.
- Caicollector (Slobel - tasuta versioon) - täieõiguslik programm klastrite ja semantilise kerneli loomiseks. Evoideerib suurt populaarsust. Suur hulk funktsionaalset lisaks põhisuunas: võtmete valik teiste süsteemide hunnik, autoklaasimise võimalus, kogudes positsioone Yandexis ja Google'is ja palju muud.
- Lihtsalt maagia - multifunktsionaalne võrguteenus südamiku tegemiseks, autoriseerimiseks, teksti kvaliteedi ja muude funktsioonide tegemiseks. Teenus tingimuslikult tasuta, täieõigusliku töö jaoks, mida peate tellima liitumistasu.
Täname teid artikli lugemise eest. Tänu sellele samm-sammult juhisele saate teha oma saidi semantilise tuuma, et edendada Yandexis ja Google'is. Kui teil on küsimusi vasakule - küsi kommentaare. Allpool on boonused.
Semantiline kernel on päris kihlveo teema, eks? Täna me parandab selle koos kogudes semantika selles õppetund!
Ei usu? - Vaata ennast - see on piisav lihtsalt sõita Yandex või Google fraasi semantiline tuum saidi. Ma arvan, et täna ma parandan selle tüütu vea.
Aga tegelikult, mis ta teie jaoks on - täiuslik semantika? Te võite arvata, et rumala küsimus, kuid tegelikult ta on täiesti nehall, vaid enamik veebimeistrid ja veebisaitide omanikud usuvad, et nad saavad semantiliste tuumade valmistamiseks ja et iga koolipoiss hakkab sellega kogu sellega toime tulema, jah, nad ise üritavad õpetada teisi ... Aga tegelikult on kõik palju raskem. Kui ma küsisin minult - mida ma peaksin alguses tegema? - sait ja sisu või sEZ KERNELJa küsis isikult, kes ei pea ennast uustulnukaks tegevjuht. Siin see probleem Ja lubage mul mõista kõiki selle probleemi raskust ja ebaselgust.
Semantiline kernel on aluse aluseks - esimene esimene koda, mis seisab enne ja alustate mis tahes reklaamikampaania Internetis. Koos selle semantika saidi on kõige jõuline protsess, mis nõuab palju aega, kuid rohkem tänan teid igal juhul.
Noh ... Loome tema koos!
Väikese eessõna
Et luua semantiline valdkonnas saidi, me vajame ühe ainus programm - Võtme koguja.. Kollektori näitel välja selgitan ma väikese grupi kogumise näide. Lisaks makstud programm, On ka tasuta analoogid nagu Slobel ja teised.
Semantika kogutud mitmes põhietapis, mille hulgas tuleks eraldada:
- brainstorming - analüüs põhi fraasid ja koolitus parsing
- parsing - algse semantika laiendamine Vordstati ja muude allikate alusel
- avamine - pärast parsimist
- analüüs - sageduse, hooajalisuse, konkurentsi ja muude oluliste näitajate analüüs
- rafineerimis- - Gruuplemine, kaubandus- ja teabelausete eraldamine tuumas
Kõige rohkem olulised etapid Kogumine ja arutatakse allpool!
Video - konkurentide semantilise kerneli koostamine
Ajurünnakud semantilise kerneli loomisel - tüve aju
Selles etapis on see vajalik pidage meeles valiku tegemisekssemantiline tuum saidi ja tulla nii palju fraase kui võimalik meie teema all. Niisiis, käivitage Kay koguja ja valige wordstati parsing, nagu on näidatud ekraanipilt:

Meil on väike aken, kus pead kehtestama maksimaalse fraaside meie teema. Nagu ma juba ütlesin, Käesolevas artiklis loome selle blogi jaoks näidete komplektNii võivad fraasid olla järgmised:
- sEO blogi
- sEO blogi
- blogi SEO kohta
- blogi SEO kohta.
- edendamine
- edendamine projekt
- edendamine
- edendamine
- blogide reklaamimine
- blogi edendamine
- blogi edendamine
- blogi edendamine
- edendamise artiklid
- aktiveeritud reklaam
- miralinks.
- töö SAPE-s.
- ostmine lingid
- linkide ostmine
- optimeerimine
- lehekülje optimeerimine
- sisemine optimeerimine
- sõltumatu edendamine
- kuidas ressursi edendada
- kuidas oma saiti reklaamida
- kuidas saidi reklaamida
- kuidas saidi reklaamida
- sõltumatu edendamine
- vaba edendamine
- vaba edendamine
- otsingumootori optimeerimine
- kuidas edendada saiti Yandexis
- kuidas edendada saiti Yandexis
- edendamine Yandexi all.
- edendamine Google'i all
- edendamine Google'is
- indekseerimine
- kiirenduse indekseerimine
- valige Doonori sait
- doonori kassasse
- promotion Postov
- postituste kasutamine
- blogi edendamine
- algoritm Yandex
- uuenda Titz
- otsi andmebaasi värskendus
- upDieti Yandex
- lingid igavesti
- igavesed viited
- rentide rent
- rendi viide
- lingid igakuise maksega
- semantilise tuuma koostamine
- saladuste edendamine
- saladuste edendamine
- secrets SEO.
- saladuste optimeerimine
Ma arvan, et see on piisav ja nii nimekiri lehe põrandast;) Üldiselt on idee see, et esimeses etapis peate oma tööstusharu analüüsima, et maksimeerida ja valida nii palju lausete peegeldavaid lauseid. Kuigi siis, kui sa sellel etapil midagi ei vastanud - ärge meeleheitel - mõisteta fraase ilmnevad tingimata järgmistel etappidelLihtsalt peate tegema palju lisatööd, kuid mitte midagi kohutavat. Me võtame meie nimekirja ja kopeerime võti kogujasse. Järgmisena klõpsa nupule - Poule koos Yandex.wordstatiga.:
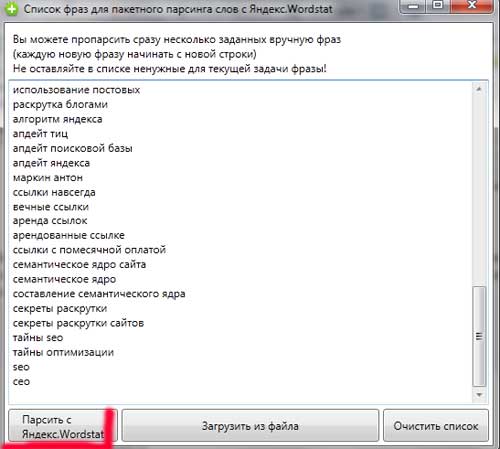
Parsing võib võtta üsna pikka aega, nii et sa peaksid olema kannatlik. Semantiline tuum läheb tavaliselt 3-5 päeva ja esimene päev, mil te lähete aluse semantilise kerneli ja parsimise ettevalmistamisse.
Selle kohta, kuidas töötada ressursiga, siis kuidas valida märksõnad, mida ma kirjutasin üksikasjaliku juhendi. Ja saate teada saidi edendamise kohta NF-i taotlustes.
Lisaks ütlen, et selle asemel, et ajurünnaku asemel saame kasutada konkurentide semantikat ühe spetsialiseerunud teenustega, näiteks spywords. Selle teenuse liideses sisestame lihtsalt märksõna, mida vajate ja vaatame peamisi konkurente, kes esinevad sellel fraasis peal. Veelgi enam, semantika saidi võistleja saab täielikult maha laadida selle teenusega.

Järgmisena saame valida ükskõik millise neist ja tõmmata välja oma taotlused, mis jäävad prügi ja kasutavad põhilisi semantikaid edasiseks parsimiseks. Või me saame seda veelgi lihtsam ja kasutada.
Semantika puhastamine
Niipea kui WordStat Parsing täielikult peatub - on aeg semantilise kerneli välja lõigata. See etapp on väga oluline, nii et me peaksime seda piisavalt tähelepanu pöörama.
Niisiis, mu parsing lõppes, kuid fraasid osutusid PaljuJa seetõttu võivad sõnade sõnad meilt liiga palju ära võtta. Seega, enne kui menetluse sageduse määratlusele, on vaja toota sõnade esmane puhastus. Me teeme seda mitmetes etappides:
1. Filtreerige päringuid väga madala sagedusega
Selleks põhineb see sageduse sorteerimise sümbolil ja hakata välja kõik taotlused, millel on sagedused alla 30:
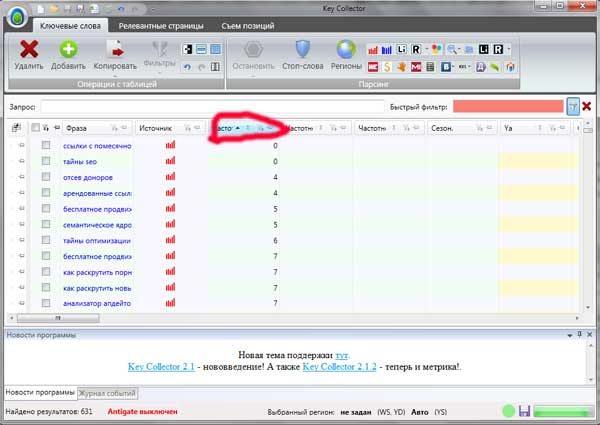
Ma arvan, et selle elemendiga saate kergesti toime tulla.
2. Eemaldage tähenduse taotlustes sobivat
Selliseid päringuid, millel on piisav sagedus ja madal konkurents, kuid nad üldse ei sobi meie teema jaoks. Sellised võtmed tuleb enne võti täpsete eesmärkide kontrollimist eemaldada, sest Kontroll võib võtta palju aega. Me kustutame selliseid võtmeid käsitsi. Niisiis, minu blogi jaoks olid nad tarbetud:
otsingumootori optimeerimise kursused müügiedendussaidi müümine
Semantilise tuuma analüüs
Selles etapis peame kindlaks määrama meie võtmete täpse sageduse, mille jaoks peate pildil näidatud suurenduse sümbolis:

Protsess on üsna pikk, nii et saate minna ja teha ise tee)
Kui kontroll oli edukas - on vaja jätkata meie kerneli puhastamist.
Ma soovitan teil eemaldada kõik võtmed sagedusega vähem kui 10 taotlust. Ka teie blogi jaoks kustutan kõik kõik taotlused, millel on väärtused üle 1000, kuna ma ei kavatse selliseid taotlusi ikka veel planeerida.
Eksport ja semantilise kerneli eksport ja rühmitamine
Ära arva, et see etapp on viimane. Mitte üldse! Nüüd peame sellest tulenevat rühma üle kandma maksimaalse nähtavuse eksisteerimiseks. Järgmisena me sorteerime läbi lehekülgi ja siis näeme palju puudusi, mille korrigeerimine ja me tegeleme.
Saidi eksporditud semantika exel on täiesti lihtne. Selleks peate lihtsalt klõpsama vastava iseloomuga, nagu on näidatud pildil:
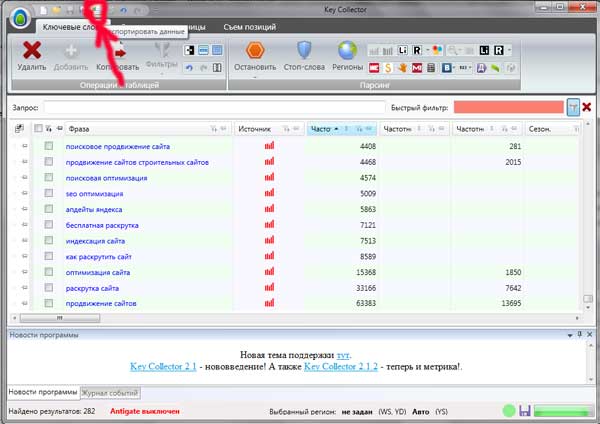
Pärast sisestamist Exelile näeme me järgmist pilti:

Punktiga tähistatud veerud tuleb eemaldada. Seejärel looge teine \u200b\u200btabel exelis, kus sisaldub lõplik semantiline tuum.
Uus tabel on 3 veergu: Urlleheküljed, märksõna fraas ja see sagedus. URLina valige või juba olemasolev lehekülg või leht, mis kujundatakse perspektiivis. Kõigepealt vali mu blogi peamise lehe võtmed:

Pärast kõiki manipulatsioone näeme järgmist pilti. Ja soovitab viivitamata mitmeid järeldusi:
- sellised sagedus päringud, kuna vaja on palju suuremat saba vähem sageduse fraase kui me näeme
- SEO uudised
- uus võti Surfaced, mida me varem tegime - tegevjuht. Vajadus seda võti analüüsida
Nagu ma ütlesin, ei peida meie võtit. Järgmine samm meie jaoks on nende kolme fraaside ajurünnak. Pärast ajurünnakut kordame kõiki samme, mis algavad nende võtmete esimesest elemendist. Sa võid kõik tunduda liiga pikk ja tüütu teile, kuid see on - see on - semantilise tuuma koostamine on väga vastutustundlik ja hoolikas töö. Kuid pädeva koostatud sekti aitab oluliselt aidata edendada saidi ja võib väga palju säästa oma eelarve.
Pärast kõiki tulusid suutsime selle blogi peamiseks lehele uusi klahve saada:
- parim SEO blogi
- sEO uudised
- artiklid SEO.
Ja mõned teised. Ma arvan, et tehnika on teile arusaadav.
Pärast kõiki neid manipulatsioone näeme, milliseid meie projekti lehekülgi tuleb muuta () ja milliseid uusi lehti lisada. Enamik meie poolt leitud võtmeid (sagedusega kuni 100 ja mõnikord palju suurem) saab kergesti edendada üksi.
Lõplik valamine
Põhimõtteliselt on semantiline tuum peaaegu valmis, kuid seal on veel üks ilus oluline punktMis aitab meil märgatavalt parandada meie peregruppi. Selleks me vajame SeoPult.
* Tegelikult saate kasutada mõnda sarnaseid teenuseid, mis võimaldavad teil õppida näiteks märksõnade konkurentsi, mutageeni!
Niisiis, loome teise tabeli exel ja kopeerida ainult võtmeinimede seal (keskmise veeru). Et palju aega veeta, kopeerida ainult teie blogi põhilehe võtmed:


Seejärel kontrollige oma märksõnade ühe üleminekukulusid:
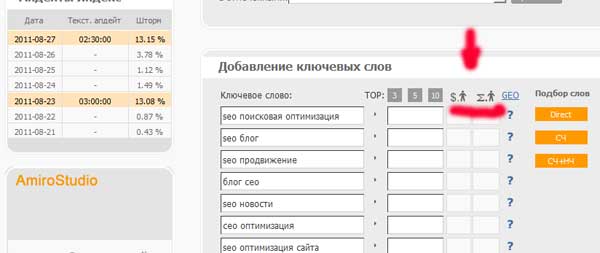
Mõnedele fraasidele ülemineku maksumus ületas 5 rubla. Sellised fraasid tuleb meie tuumalt välja jätta.

Võib-olla on teie eelistused mõnevõrra erinevad, siis saate välistada odavamaid fraase või vastupidi. Oma puhul kustutasin 7 fraasi.
Kasulik teave!
semantilise kerneli valmistamise kohaselt keskendutakse kõige madalamate konkurentsivõimeliste märksõnade sõelumisele.
Kui teil on oma poe - lugema Kui kirjeldatakse, kuidas semantilist südamikut saab kasutada.
Semantilise kerneli klastrite
Olen kindel, et teil on varem seda sõna kuulda, kui otsingu edendamine rakendatakse. Let's aru, millist metsalist on nii ja miks see on vaja kohapeal edendamisel.
Klassikaline otsingu müügiedendusmudeli näeb välja selline:
- Otsingupäringute valimine ja analüüs
- Päringute grupeerimine kohalehtede kohta (sihtlehed)
- SEO-tekstide ettevalmistamine maandumislehtedele, mis põhinevad nende lehekülgede päringute rühmal
Et hõlbustada ja parandada teise etapi ülaltoodud nimekirjas ja toimib klastritena. Sisuliselt on klastrite tarkvara meetod, mis aitab seda etappi lihtsustada suure semantikaga töötamisel, kuid kõik ei ole nii lihtne, sest see võib esmapilgul tunduda.
Klastrite teooria paremaks mõistmiseks peaksite SEO ajaloosse tegema väikese ekskursiooni:
Sõna otseses mõttes paar aastat tagasi, kui termin kloseerimine ei uurinud iga nurga - Sienes, valdav enamik juhtumeid, grupeeritud semantika oma kätega. Aga kui rühmitate tohutu semantika 1000, 10 000 ja isegi 100 000 taotluses, muutus see protseduur tavalise isiku tõeliseks katguardiks. Ja siis hakkas semantika rühma metoodika kasutama kõikjal (ja täna palju kasutavad seda lähenemisviisi). Semantiline rühmitusmeetod hõlmab ühendades üheks osaks semantiliste suhete jaoks päringuid. Näitena - taotlused "Osta pesumasin"Ja" Osta pesumasin 10 000-le "ühesse rühma. Ja kõik oleks hea, aga see meetod sisaldab mitmeid kriitilisi probleeme ja nende arusaamist on vaja tutvustada uut mõistet meie jutustuses, nimelt - " tahtlus”.
Lihtsaim viis selle mõiste kirjeldamiseks võib olla kasutaja vajadus, tema soov. Indentiline ei ole midagi muud kui otsingupäringu sisenemise soov.
Samantika rühmituse põhjal on koguda ühes taotlusrühmas, millel on sama kavatsusega või võimalikult lähedane intensiivsus, ja siin tekib 2 huvitavat funktsiooni, nimelt:
- Sama kavatsused võivad olla mitmeid taotlusi, millel ei ole semantilist lähedust, näiteks - "Autoteenus" ja "Registreeru"
- Taotlused, millel on absoluutne semantiline lähedus, võib sisaldada radikaalselt erinevaid intensiivseid, näiteks õpiku olukorda on "mobiiltelefon" ja "mobiiltelefonid". Ühel juhul tahab kasutaja telefoni osta ja teise filmi vaatamiseks
Niisiis ei võta semantika rühmitus semantilises kirjavahetuses arvesse taotluste intensiivsust. Sel viisil koostatud rühmad ei võimalda teil kirjutada teksti, mis langeb tippu. Selle arusaamatuse kõrvaldamiseks käte grupeerimise ajal, poisid elukutsega "Predial SEO spetsialist»Analüüsitud väljastamise oma kätega.
Sisuliselt klastrite on võrdlus vormitud väljastamise otsingumootori otsimisel korrektsust. Sellest määratlusest peaksite enda eest viivitamatult märkima, et klastrite ise ei ole viimasel juhul tõde, sest vormitud väljastamine ei pruugi täielikult avalikustada (Yandexi baasil võib olla õigesti kombineeritud taotlused rühm).
Klastrite mehaanika on lihtsad ja näeb välja selline:
- Süsteem siseneb vaheldumisi kõik taotlused esitatakse talle otsi väljastamine ja mäletab tippu tulemusi
- Pärast taotluste alternatiivset sisendit ja tulemuste säilitamist otsib süsteem väljaandmise ristmiku. Kui sama sait on sama dokument (saidi leht) on top kohe mitmes taotluses, siis neid taotlusi teoreetiliselt saab kombineerida ühte rühma
- See muutub asjakohaseks selliseks parameetriks rühmitamise rühm, mis räägib süsteemi, kui kaua peab olema ristmikud, mis taotlused võivad ühe grupi lisada. Näiteks kontserni 2 tugevus tähendab, et 2 minuti väljaandmisel peaks olema vähemalt kaks ristmikku. Samuti on lihtsam - vähemalt kaks kahe erineva saidi lehekülge peaks olema ühekordselt ühe ja teise taotlusega üheaegselt kohal. Näide allpool.
- Suure semantika grupeerimisel on taotluste vaheliste linkide loogika asjakohane, mille põhjal on 3 põhitüüpi klastri tüüpi: pehme, keskmise ja raske. Me räägime endiselt klastrite tüübist selle päeviku järgmistes dokumentides.
Kuidas teha teabekomponent saidi nii, et kliendid saaksid selle kiiresti leida
Niisiis otsustasite luua portaali, millele inimesed võiksid leida huvitavat teavet, kuid te teate, et vajame mõningaid oskusi, et edendada, nimelt semantilise tuuma koostamist. Aga semantika lihtsalt soovitab, et sait täidetakse tähendusega. Seetõttu öeldi siin, kuidas tappa kaks jäneset korraga - ja meelitada publiku kasuliku teabe ja mitte sundida otsingumootoreid "vannub".Vana ja uus lähenemisviis saidi teabe ja semantilise kerneli täitmiseks
Saidi loomine, esiteks, peate teadma, millised kasutajad on huvitatud ja kuidas nad otsivad teavet - kõik on samad andmed erinevalt. Ja samuti on vaja arvesse võtta kasutaja huve - sest kuna kogu teie saidil esitatud teave peaks olema igale lugejale huvitav, peavad inimesed lugema. Ja ilma otsingumootoriteta ei ole vaja teha - Yandex ja Google lihtsalt ei aktsepteeri oma portaali omaette, kui täidetakse mitmeid tingimusi.Eelkõige on märksõnade hajutamine, mille otsing fraas koosneb kogu portaalist. Seetõttu on oluline täita semantilise koormuse teksti. See ei ole midagi enamat kui semantiline (semantiline) tuum - sõnade ja fraaside kombinatsioon, mis peegeldavad Interneti-ressursi temaatilist orientatsiooni ja struktuuri. Üldiselt on semantika keeleteaduse jaotus, mis uurib keele osakute semantilist sisu (elemendid) sisu. Igaüks, ilmselt nägid selliseid väljendeid saitidel kui "peategelane aitab sõpradel filme vaadata võrgus, et mitte muutunud kaabakas ohvriks" (fraas ligikaudne, sisuliselt, on arusaadav). Siin kasutaja näeb selgelt, et on märksõna "Vaata filme online", kuid see ei ole tema jaoks tehtud, vaid otsingumootori jaoks. Selle tulemusena võib ta end petta - ei ole vaja sellist rullida, midagi head toob seda. Pädev tekst koos semantilise kerneli kasutuselevõtuga tajutakse palju paremini.
Et kasutaja saaks leida Interneti-ressursi, saate kasutada kahel viisil:
- Esiteks analüüsige klientide otsingupäringuid, mis järgivad portaali struktuuri (semantiline või semantiline kernel käesoleval juhul otsustav väärtus ressursi raamistikus ja struktuuris);
- kõigepealt teha plaan selle kohta, kuidas saidi struktuur välja näeb, enne kui lülitute analüüsile, mida kasutajad on huvitatud (semantiline kernel jagatakse juba valmisportaali raamile).
Esimene lähenemisviis hõlmab kohandamist praeguste tingimustega - ja see valik tõesti toimib. Sellisel juhul on ressursi struktuur kokkuvõtlikult kokku märksõnade all ja jääb objektiks. Teine võimalus on nagu ajamasina laulu "Sa ei tohiks muuta muutuva maailma jaoks - ühel päeval sõidab ta meie all." Selle lähenemisviisi kasutamine valib ärimees ise, et ta tahab potentsiaalsetele kasutajatele öelda. Seda lähenemisviisi võib nimetada omamoodi ennetav - ja ärimees sel juhul muutub teema.
Oluline on mõista, et turunduse ja äritegevuse peamine eesmärk on kliendile keskendumine. Ja teine \u200b\u200bmeetod annab selle lihtsalt. See tähendab, et ettevõtja või turundaja otsustab, milliseid andmeid ta tuleb anda publikule oma portaali abil - ja muidugi peaks muidugi olema mõned teadmised selle kohta, mida räägitakse oma veebilehel. Seetõttu plaanib kõigepealt eeskujuliku kujunduse, lehtede esialgse loetelu ja seejärel analüüsib, kuidas kasutaja otsib vajalikku teavet. Ja ressursi infosisu abil vastutab ta küsimuste eest, mida kasutaja määrab otsingumootori.
Esimene valik on "thebulaarne" meetod. Ta oli pikka aega juhtida ja rakendada seda nüüd. Selle meetodiga oli peamised laused, mille jaoks saidi looja soovis lihtsalt otsingumootori tippu ja seejärel ressursside struktuuri ja võtmed loodi kõikidel lehekülgedel. Teabe sisu optimeeriti võtmesõnade ja fraaside all.
Kuid see meetod praktikas näitab, et äkki otsingumootor on petetud, kuid inimesed seda ei tee. Informatsiooni väärtus ressursside langeb - inimesed ei ole huvitatud lugemisest tekste, mille märksõnu saab jälgida, ta arvab kusagil petmine. Kuid turundus on loodud mitte selle huvides - ärivormide suundumused ja ärimees valib kasutajatele, mida kasutajatega rääkida. Turundus ei tohiks "tantsida kellegi teise Dudka" all tantsida, vastasel juhul lõpetab publik teda austada - ta peab moodustama keskkonna enda, kuid samal ajal olema kliendile orienteeritud. Samuti ei ole ega teine, lähenemisviisi ei ole "sperma" ja sellepärast ta on nördinud.
Vahepeal mõned võimalikud päringud otsingumootori ja siin ka saab mõista, sest seal on suur konkurents internetis täna. Lisaks täidetakse saidid võtmed, mis "armastavad" otsingumootoreid.
Semantilise Kerneli ehitamise kavandatav tulemus on portaali lehekülgede hajutatud peamiste päringute nimekiri. See hõlmab lehekülgede URL-i, taotlusi, mis näitavad sagedust.
Saidi disain
Struktuur või disain, Interneti-ressurss on mingi hierarhiline või auaste, veebilehe skeem. Selle loomisega lahendatakse sellised ülesanded järgmiselt:- Teabe strateegia ja teabe struktuuri planeerimine kasutajale;
- Otsingumootorite portaali juhiste vastavuse tagamine;
- Garantii ergonoomilise ressursi kliendile.
Selleks saate kasutada kõike, mis on mugav - isegi MS Word või Paint, saate selle juhtida ka käest või pliiatsiga tabletist. Struktuuri planeerimisel peate vastama kahele küsimusele:
- Millist teavet teile meeldib ärimees, kellele soovite klientidele edastada;
- Kust avaldada ühe või teise sisu.
Kui te võtate eeskujuna väikesi kondiitritoodangu kujunduse, sisaldab see teabelehti (retseptid, kooki ajalugu), artiklite ja kaupade kataloogi (Showcase). Kui esitate selle skeemi kujul, võib see välja näidata:
Hierarhiline saidi kava
Seejärel koostatakse disain tabeli kujul. See näitab hierarhiat, nimi lehekülg on märksõnade ja nende sageduse veerud sisse lülitatud, samuti näitab lehekülgede URL-id. Kui esitate kondiitritooli disainilaua, võib see olla järgmine:

Nii saab Interneti-ressursi struktuuri (disain) esitada tabelina
Kõigepealt teame ainult "Lehekülje pealkirju" ja " LegendHiljem täidetakse hiljem "ja" URL "," võtmed "ja" sagedus ".
Märksõnad
Oluline on mõista, millised märksõnad on ja millised otsingupäringud kliente rakendavad - ilma selleta ei ole tõhusat saidi loomist ja kasutajatele teavet esitamist. Saate rakendada ühte teenuseid, et valida märksõnad - kuid see on oluline mõista, et need sõnad oleksid asjakohased.Niisiis, võtmed on soovitud ja teabe leidmiseks kasutajad kasutavad sõnad või fraasid. Lihtne näide on valmistada pirukas, see siseneb taotlussüsteemi "Apple Charpecki retsept fotoga" otsingumootoris.
Keys saab jagada mitmeks rühmaks:
Sõltuvalt populaarsusest eraldage:
- Madala sagedusega taotlused (need on näidatud 100-1 000 / kuus);
- Kesksagedus (1000-5 000 kuvamist);
- Kõrgsagedus (taotlused 5000-10 000 kaadri kohta kuus).
Sõltuvalt klientide vajadustest erinevad:
- Teave (kui kasutaja peab leidma mis tahes teavet - näiteks "Kuidas puhastada riideid fuccinist", "millised vitamiinid parandavad naha seisundit");
- Tehingute tegemine (väljastatud päringud, mis on väljastatud tehingu tegemiseks, kuid ilma konkreetse saidi või poe täpsustamata - "Osta diivan", "Laadi mäng", "Tehke krediidi taotlus");
- Navigeerimine (kui klient soovib leida teavet konkreetse saidi kohta - näiteks "WebMoney, et luua kaart", "jälgige Whitepoche'i raadiokoodi", "Eustlus allahindlused");
- Teised (Kui seda on raske kindlaks määrata, mida kasutaja soovib - näiteks fraasi "aju" tutvustamine, ei ole selge, et inimene tahab teada - struktuur, orel, huvitavaid fakte Tema kohta ja lisaks sellele ei ole selge, millist aju on selja või pea kohta).
Nüüd iga elemendi jaoks. Erinevus populaarsuse hindamisel sõltub sellest, kuidas kontekstist on selge, kas kasutajad on ühe või teise teema populaarsuse populaarsed. Otsus tingimuslikult määratlevad mõned eksperdid väiksema arvu taotluste hulka. Näiteks on järgmine: kohapeal, mis kaupleb nutitelefonidega, taotlus "osta samsung telefon"Sagedus näitas 6000 / kuul - keskmise sageduse üks. Samal ajal, spordiklubi, taotluse "Tai poksiväljakoolitus", sagedusega 1000 taotlus on kõrgsagedus.
Kõik see tuleb arvesse võtta ja kujundada äärmiselt laialt levinud semantiline tuuma ja seda tuleks rikastada madala sagedusega fraase tõttu, sest kui te arvate statistikat, siis saab 60% -lt 80% -le kõik kasutaja taotlustest omistada madala- sagedus. See tähendab, et peamine ressurss, mis võimaldab teil meelitada potentsiaalseid kliente saidile, tuleks kasutada madala sagedusega võtmeid - see on mingi kitsasuunalised märksõnad. Sa pead lahjendama neid kõrge ja keskmise sagedusega taotlusi.
Teise rühma tõhusaks kasutamiseks, mille kohaselt märksõnad eristatakse, on vaja kõigepealt, kui nad levitavad lehekülgede võtmete levitamisel või teabe täitmise kava loomisel, et võtta arvesse klientide vajadusi. See tähendab, et artiklid, kus kasutaja antakse teavet, peab vastama nende küsimustele. See on suur osa võtmeisikutest ilma teatud kavatsuseta - see tähendab artiklis artiklis artiklis, siis ei tohiks sisestada sõnad "Osta", "Laadi alla" jms. Sektsioonide "pood", "kataloogi" kataloogi IL "Storefine" julgustatakse vastama kasutaja tehingute taotluste rahuldamata.
Tuleb meeles pidada, et enamik tehingutaotlusi on kaubanduslikud. Ja seega, otsustades müüa koogid, siis võistelda "kook Moskva", "dobryninsky ja partnerid" ja "Viini poes" - kõige rohkem suured tootjad kondiitritooted. Aga kui me kasutame ülaltoodud soovitusi pädevalt, muutub kõik palju lihtsamaks. Laienda semantiline tekst kernel nii palju kui võimalik ja vähendada päringu sagedust. Näiteks sageduse taotluse "osta Ameerika rublakook" sagedus on väiksem kui "Osta American Cake".
Otsingu otsingupäringud
Fraas on Üldine mõistemis sisaldab privaatset. Nii et otsingu fraase - nad hõlmavad keha, spetsifikatsiooni ja saba. Näiteks otsib otsingupäringu "kook", mida me ei saa aru, mida kasutajate vajadused on määrata kondiitritooted, ostavad selle või lihtsalt pilte. Taotlus ise on kõrge sagedus ja see tähendab suurt konkurentsi tulemuste tagamisel. Lisaks toovad päringu kasutuselevõtt kliendi veebisaidile palju kõnesid, mitte üldse huvitatud teabe saamisest ja see mõjutab negatiivselt käitumuslikku tegurit. Ja kõik, sest selline taotlus sisaldab ainult keha.Kui me sisestame sõna "Osta" vormis lisandmooduli, saame kaasatuse ja spetsiifika - mis määrab kliendi kavatsuse määrab. Sõna "Osta" saate asendada "retsepti" ja seejärel selline taotlus muutub teabeks ja kui sisestate "koogid ma armastan kooki", siis on selline küsimus navigatsioon. Seetõttu on pärit konkreetsest märksõnadest mõjutab märksõnu ühele või teisele märksõnadele.
Mõnikord võite seda kohtuda, et kasutaja, kes tahavad teatud asja müüa, tutvustab taotluse "Osta", et näha, kus inimesed ostavad selle teema kõige rohkem.

Kui sisestate fraasi "Osta kook Moskvas" või "Osta kook tellimiseks", siis otsingupäringu viimane osa on saba. Ta selgitab ainult üksikasju selle kohta, kuidas või kus klient kavatseb seda teha. Niisiis, kui klient peab teadma konkreetset kauplust, muutub taotlus navigatsiooniks.
Kaadri struktuur otsingule
Kui me vaatame järgmisi näiteid: "Osta kodukook Alma-Ata", "Napoleon Cake retsept", "Osta tarnekook", näeme, et igas olukorras on kasutaja teatud eesmärk, ja saba täpsustab ainult üksikasjad.Seetõttu esitatakse semantilise kerneli jaoks teenuste ja kaupade peamine terminoloogia portaalis või ettevõtlusalaste tegevuste ja klientide vajadustega seotud. Niisiis, kui inimene vajab kondiitritoodete toodet, on see huvitatud kookidest, marshmallowsist ja prügi, marshmallow, vahvlid, küpsised, meringi, cupcakes jne See on keha peamine päring. Ja siis leidke spetsiifilised ja sabad. Tänu fraasidele "sabad" teil on ja suurendab katvust ning samal ajal muutub see vähem "otsingu konkurendid".
Interneti-ressursid semantilise kerneli tegemiseks (võtmeväärtuste valik)
Selleks, et koguda märksõnu saidi, on palju assistente, mis hõlbustavad elu ärimees. Seal on makstud, mis on vajalikud, kui sait on tohutu või nende komplekt ja vaba, sobib väike portaali jaoks.Artiklis käsitleme järgmisi ressursse:
- Keycollector (makstud);
- Slovoeb (tasuta);
- Wordstat Yandex'a (tasuta);
- AdWords Google'ist (tasuta).
Võtme koguja.
See on makstud tööriist mitme funktsiooniga. See automatiseerib semantilise kerneli ehitamiseks vajalikke toiminguid. Loomulikult saate kasutada programmi tasuta analooge, kuid selle kasutamiseks kasutage korraga mitmeid internetiressursse, kuna sellel programmil on peaaegu midagi piiratud. Enamgi veel, see teenus See on lihtsalt hädavajalik, kui teil on mitte üks sait või mida kasutatakse selleks, et tagada kõik ühe programmiga sobivaks, et mitte otsida kolmanda osapoole ressursse, samuti kui teil on mitu saiti või semantilise sisu vajab suurt sait.See pakub järgmisi funktsioone:

Siin näeb välja nagu võtmekollektor
Slovoeb.
See teenus on tasuta. Arendajad on samad, kes lõi peamise kollektoriprogrammi. Programmi kasutamiseks programmi kasutamiseks peate sisselogimise määrama otsese konto otsekontole. See on tingitud asjaolust, et Yandex saab konto blokeerida automaatse päringu tõttu, nii et ärge kasutage peamist.Ressurss pakub järgmisi funktsioone:
- Märksõnade kogumine Wordstati kaudu;
- Kõrge sageduse filtri taotlused;
- Otsinguviisade süntaksianalüüs.

Interface Slovoeb.
Kuidas programm töötab? Alustada uue projekti loomist. Valige "Lisa fraasid" - siin on fraase, mis kasutavad kliente, et otsida teavet konkreetse toote kohta.

Otsingu fraasi lisamine programmi
Valige menüü "Sõnade kogumine ja statistika" valige soovitud element ja käivitage teenus. Näiteks, kui teil on vaja võtmelaused koguda, valige see valik.

Võtmelausete sageduse määramine
Wordstat (Yandexi teenus)
See on vaba ressurss valiku ja analüüsi jaoks. otsi fraasid. On vaja, kui olete valmis päringuid käsitsi analüüsima ja klassifitseerima. Teenus pakub järgmisi valikuid:- Kuvab teavet märksõnade näituste ja taotluste kohta, otsingulausete analüüsimise kohta, analüüsides nii üldisi kui ka mobiilseid andmeid (st näete, kuidas populaarne taotlus on mobiilseadmetes);
- Statistika demonstreerimisel piirkondade kaupa;
- Ekraan andmete populaarsust konkreetse taotluse aja jooksul ("päringu ajalugu");
- Kuvatakse fraas või taotlus ainult kindlaksmääratud kujul (selle jaoks on vaja fraasi tsitaatidesse);
- Statistika näitamine Välja arvatud stop-sõnad (enne seda sõna peate miinus panema nii, et seda ei võeta arvesse);
- Andmete demonstreerimisel valitud ettekäände kasutamisest (sel juhul, enne kui see peaks olema "+");
- Teabe esitamine taotluse kategooria kohta (selle nõudmisrühma jaoks tuleks märgistada sulgudes ja peamised võimalused - otsese kaldkriidi eraldamiseks "|" | Cake "," tellida kappekyk "," osta Cape "," tellige pie "ja" osta pie ", järgige juhiseid, nagu allpool näidatud pildil);
- Kuvab andmeid taotluste kohta, viidates konkreetsetele valdkondadele.

Taotlus "Capeeys", üldise statistika

Andmed piirkonna võtme kohta

Siin näete, millal taotlus oli kõige väiksem või kõige vähem populaarne.

Näidata fraasid määratud kujul

Märksõna nr Wordform

Statistika, välja arvatud stop-sõnad

Andmed kuus taotlust kohe - mugav asi, kui teil on vaja kiiresti saada teavet

Kui valite konkreetse piirkonna, näete, mis seal on populaarne
Google AdWords (märksõna planeerija Google'ist)
Kui konkreetses piirkonnas Google on oluliselt juhtiv, on parem kasutada seda teenust. See on mõeldud selle otsingumootori kasutajate vajaduste arvutamiseks. Teenus on tasuta, kuid seal on tasulised teenused (näiteks reklaamide puhul).Tööriist pakub järgmisi funktsioone:
- Teabe kogumine otsingupäringute kohta;
- Uute taotluste kombinatsioonide väljatöötamine ja nende asjakohasuse ja dünaamika prognoosimine.
Konkreetsete taotluste statistika saamiseks peaksite selle võimaluse valima pealeht tööriist. Te peate sisestama huvipakkuvate fraaside ja faili üleslaadimiseks CSV-vormingus, seejärel valige piirkond, mille kohaselt on statistika vajalikud, saate määrata ka stop-sõnad (nagu on kirjeldatud Wordstatis). Kõik on valmis - saate klõpsata "Uuri taotluste arvu".

Teave Google'i taotluste kohta
Teenused, mis pakuvad analüüsiteenuseid
Võite kasutada Google Analyticsi analüütikud või mõõdikud, kui teil on vaja ehitada semantiline tuum olemasoleva ressursi. Need tööriistad aitavad määrata, millised laused klientide otsimiseks tutvustatakse.
Siin saate leida inspiratsiooni märksõnade moodustamiseks.
Lisaks on selle või selle teabe leidmiseks mõeldud ühiste fraaside andmed kontrollima, kasutades Yandexi ja Google'i veebimeistrite kapis. Viimased andmed asuvad otsingukonsoolis, siis peate minema "Otsi liiklusele - otsingupäringu analüüsile".
Webmaster Yandex teeb ettepaneku kasutada sektsioonis "Otsi päringuid - populaarseid taotlusi.
Tööriistad konkurentide saitide analüüsimiseks
Võistlevad saidid on veel üks ressurss, kus saate otsida inspiratsiooni märksõnade otsimiseks. Nende määramiseks on mõttekas lugeda nende avaldamist või kontrollida teksti võtmehoidja HTML-sildi abil veebilehe programmi koodi abil. Või Advage ISTIO-ga, et teid aidata.
ISTIO liidese
Kui teil on vaja analüüsida kogu konkurendi portaali, saate kasutada järgmisi tööriistu:
Nüüd rohkem iga elemendi jaoks.
Peamiste võtmete määramiseks peavad nad salvestama, on võimalik seda teha paberilehel ja arvutiprogrammide abil. Teil on vaja ideid kõigi kolleegide - nad peavad salvestama kõike eranditult: igaüks võib osutuda "võttes Graveyla", mis meelitab kliente teile.
Nimekiri võib välja näeb:

Proovi nimekiri fraasid otsingule
Selles nimekirjas on peaaegu kõik võtmed suure sagedusega, ilma spetsiifilisuseta. Keskmise ja madala sagedusega fraasid võimaldavad tuuma laiendamiseks sama. Nii et mine järgmisele etapile.
Siin lahendatakse see raskus, kasutades märksõnade valimise vahendit. Näiteks saate valida Yandexi teenust - see on üks kõige mugavamaid, hoolimata ilmsest esialgsest keerukust. Siin saate teha siduva konkreetse piirkonnaga, kui pakute toote või teenuse teatud geograafilises objektis.
Nii et selles etapis analüüsime kõiki kolleegide koostatud võtmeid.

Põhiandluse analüüs
Te peate fraaside kopeerima teenuse vasakult veerust ja sisestama tabelisse. Nüüd peaksite keskenduma assistendi paremale veerule - siin Yandex pakub fraase, mida külastajad kasutasid koos põhilise fraasiga. Nii et siin on teil võimalus valida sobivad võtmed ja kopeerida need vasakule veergu. Ärge muretsege, kui midagi ei sobi - need laused on viimases etapis välja jäetud. Ja ta on juba lähedal talvel "Troonide mäng".
Selle faasi tulemus on koostatud nimekirja fraaside otsimiseks, mis on iga põhiklahvist. Selles etapis saab sadu ja isegi tuhandeid erinevaid taotlusi.

Nimekiri fraasidest
Mine sulgemistappi. Ükskõik kui lihtne tundub - see ei ole. See on kõige aeganõudev ja keeruline töö tuumaga. Semantilisest tuumast on vaja käsitsi välja jätta, et see ei sobi talle tähenduses.
Aga te ei tohiks eemaldada madala sagedusega võtmeid - mitte mingil juhul. "Vanakool" optimeerijad lasevad ja seejärel kaaluda seda võtit prügikasti, kuid selle trikki ei ole vaja. Näide: "Toidukooki" võti võtmine põhjal, näete, et teenus näitab näituse ekraani 3 kuu ekraani 3 kuu jooksul Cherepovets'i piirkonnas. "Sularaha" meetod hõlmab oma võtmete viskamist. Aga nüüd sa mõistad, miks te ei tohiks seda teha - ja ma loodan, et see nõuanne ja seejärel kohaldada elus.
Spetsialistid SEO valdkonnas, selleks, et nende lehed oleksid otsingumootorite ülaosas, ostsid nad lingi rentimise üürile. Samal ajal vajasid nad kasutada teatud võtmeid, meetodit rakendatakse nüüd. Ja neid saab mõista, sest madal ekraani sagedusega fraasid reeglina ei maksa lingile kulutatud raha eest.
Aga kui te vaatate "dieedi koogid" vanade kõvenemise silmis ja kliendile orienteeritud ärimees saab avastada lisafunktsioonid. Lõppude lõpuks mõned potentsiaalsed kliendid on tõesti huvitatud sellest - ja mitte vähem tähtsaks on tüdrukud, kes järgivad nende arv. Nii et me teame täpselt, mida see taotlus Keegi on huvitatud ja seetõttu võib rahuliku südametunnistuse hulka kuuluda semantilise südamikuga. Kui teie ettevõtte kondiitritootajad valmistavad ette sellise toote, siis ta tingimata tulla käepärast, kus kauba kirjeldatakse. Ja kui mitte - see teabe sisu võib olla igav portaali teabe osa.

"Toidukooki", mida saab pidada prügi, on tegelikult see ei ole
Mida siis välistada? Joonistame välja:
- Esiteks on see fraasid, kus teised kaubamärgid on olemas;
- Teiseks, korduvad fraasid - näiteks 3 võtmest "koogid tellida uusaasta", "Custom-order koogid", "Cake tellige uusaasta" on esimene võti;
- Kolmandaks, kui te ei tegele sellise asjaga nagu "dumping", siis seetõttu ei ole võtmed sõnade "odav" ja "odavamaks" kasutuselevõtu võtmed kindlasti teile kasulikud;
- Neljandaks, sobimatute piirkondade võtmed - kui te kaubeldakse ainult Cherepovets'is, kuid ärge toimetage lähedalasuundades külades ega kaubandust teatud piirkonnaga, seda andmeid ei ole vaja;
- Viiendaks, võtmed viidates toodetele, mida te teate täpselt, mida ei müü ja seetõttu ei müü;
- Ja kuus, siis ei kasuta kindlasti valesti kirjutatud fraasid - ükskõik, grammatilised vead või kirjad - otsingumootor aitab külastaja otsida "GBHJ; YST" asemel "CapPkequets" asemel "Cappoxy" asemel " .
Voua-la Kui olete avastanud kõik võtmed, mis ei sobi teile, sul on vajalikud võtmed "koogid tellida". Kõigi teiste teistega peate veetma sama asja. Ja järgmine etapp on liigi fraaside klassifikatsioon.
Suurendades vastavuskaardi (asjakohasus) ja võtmeisikute klassifikatsiooni
Otsingu jaoks mõeldud fraasid, mida sihtrühm saab kasutada peamiseks ja leiab, et teie saidi kasutajad integreeritakse T.n. "Semantiline (semantiline) klastrid" on semantilise sisuga sarnaste taotluste kategooriad. See tähendab, et "kook klastri" hõlmab kõiki väljendeid, mis on selle sõnaga otseselt või kaudselt liigendatud - ja sel juhul tõuseb see keeleüksus "privaatne" ja kõik fraasid "üldised". Mis teil on võimalus näha allpool toodud pildil.Pange tähele, et siin on siin teise kolmanda, neljanda kategooria klastrid. Mida suuremad teemad, seda suurem on klastri tasemed. Kuigi de facto saadakse nii, et teise grupi klastrid.

Klastri tasemed
Enamik klastreid määratleti märksõnade loomise esimeses etapis. Loomulikult peate selle teema lihtsalt aru saama, sest teadmata midagi koogid, võite vaevalt teha pädev semantiline tuum. Klastri loomise assistent on ka koostatud saidi skeem.
Teise kategooria klastrite on väga oluline. See peaks lisama spetsifikaadid, mis näitavad klientide eesmärke - see on näiteks koogid, "koogi napoleoni loomise ajalugu". Viimane klaster on teabeosas ja esimene kataloogi.
Nüüd pöördume tagasi veebilehe hierarhilise diagrammile ja arendanud tabelit selle alusel. "Koogid tellida" määratleti YANDEXi teenuse abil ja seejärel ei olnud hiljem loendist välja jäetud. Nüüd peaks see võti olema dispergeeritud vastava partitsiooni lehekülgede vahel.

Seega saate oma saidile dispergeerida otsingufraasi.
Võtke see näide: klastris on fraase, et otsida "koogid jalgpalli teemade tellimiseks".

Jalgpalli koogid, selgub, huvipakkuv kasutaja
Ja kui kondiitritooted toodab seda tüüpi toote, siis me teame, milline osa asub see lehekülg. See tuleb paigutada "koogid mastistist", sest seda materjali kasutatakse sellise kondiitritoodete loomiseks. Niisiis, siin loome sobiva lehekülje. Tutvustame seda Interneti-ressursi kujundamisse, mis näitab sagedusega URL-i ja otsingulauseid.

Lehe loomine asjakohases osas
Sama vahendi abil saate näha sama tööriista abil, mis aitab valida õigeid võtmeid, mis taotleb endiselt kasutajatele jalgpalli teemasid. Need fraasid tuleks lisada ka sellele lehele.

Me mõistame, mida veel olete huvitatud jalgpalli ja kookide kohta
Märkimisväärsed võtmed. Hajutatud ülejäänud otsinguklahvid.
Alguses tõmmatud skeemi võib muuta isegi piiramatu arv kordi - vajadusel saate luua uusi kategooriaid ja sektsiooni. Niisiis, kui see ei eksisteeri lehele "Laste koogid", siis meenutades, et ettevõte suudab koogid teha karikatuuridega "SIG PEPPA" või "kutsikapatrull", saate teha muudatusi ja luua lehekülge. Selleks ajaks võivad need võtmed asuvad sektsioonis "koogid mastistist."

Uue partitsiooni loomine saidi hierarhilises tabelis "Laste koogid"
Seal on kaks olulist nüansse, mida tuleb meeles pidada:
- Klastr ei pruugi sisaldada sobivat fraasi lehekülje jaoks, mida soovite luua. Põhjused võivad olla vale kasutamine Märksõna, lähtudes võtmelaused või lihtsalt madala populaarsusega kaupade või teenuste populaarne populaarsus. Aga samal ajal ei ole see põhjus loobuda lehelt ja müüa kaupu. Näiteks, kui otsingusüsteemis ei leidnud otsingupäringu "kooki siga pipar", kuid kondiitritoodete firma on funktsioone sellise toote valmistamiseks, saate selgitada klientide vajadusi teise teenuse abil. Sellisel juhul leitakse selline taotlus ja enamik neist asuvad asuvad;

Inimesed otsivad ka Peppe Pepepi "
- Noh, pärast mittevajalike võtmete väljajätmist võib esineda täiesti sobimatuid taotlusi. Noh, nad võivad need eemaldada või rakendada teise klastris. Oletame, et kondiitritoodete ettevõte on spetsialiseerunud ainulaadsetele retseptidele ja aeg-testitud koogid nagu "maakonna varemed" või "Napoleon" arvavad, et minevikus on parem lahkuda - selliseid võtmeid saab jääda sektsioonile, kus kasutaja esitatakse Üldteave - antud juhul "Retseptid".
Põhilist fraasi saab paigutada teabeosasse, kui see on külastajate seas väga populaarne.
Niisiis, viimases etapis dispergeerib lehekülgedel kõik võtmed, õpetate portaali veebilehtede loendit, kus on täpsustatud URL-i, taotlused ja nende sagedus. Me läheme kaugemale, see pole kõik.
Semantilise tuuma lõppjärgus rikastumine
Niisiis, nüüd on meil kõik vajame. Meil on tabel koos semantilise tuum, nimekirja esialgse veebilehtede ja võtmelaused, mis määravad teatud klientide vajadusi. Kõik see aitab valmistamisel teabe täitmise kava (sisuplaan). Nüüd, tehes seda üles, peate määrama veebilehe või artikli nime ja lisage otsingumootori peamine päring. Aga see tuleb meeles pidada, et see ei pea alati olema kõige tavalisem võti seisukohast Yandex või Google. Ta peab mõtlema, mida soovite kasutajatele edastada ja asjaolu, et kliendid soovivad saada.Teisi peamisi fraase tuleks rakendada vastusena küsimusele - "Mida ma peaksin kirjutama?" Muidugi, te ei tohiks kohe "lükata" kõik fraasid, mis leiti, kasutades otsingupäringute vahendit konkreetsele sektsioonile - kas see on teabekava lehekülg või konkreetse teenuse või toote ostmine. Seda tuleks uuesti korda korrata: see on vaja kõigepealt pöörata tähelepanu kasutajate teabevajadustele ja mitte nendele teksti "täitematerjalile", mida nad soovivad pillid. Kasutaja alati näeb, kui ta üritab "vihma" - koos pädeva koostamisega teksti, ta isegi mõtetes, et märksõnu kasutati siin.
Lõpuks, mis ei ole veel semantilise tuumaga seotud
Loodan, et küsimusi on juba öeldud, teil ei ole jäänud ja nüüd saate luua kümmekond saite, mis põhinevad saadud teadmistel. Aga siiski peaksite määrama mõned tegevused, mis seda ei tee. Hiljem te olete selles intuitiivne ja nüüd tuleks neid südamest õppida. Siin on mõned näpunäited, mis aitavad saada professionaalseks Interneti-ressursi nõuetekohast koostamist:- Ärge keelduge liiga suure konkurentsi võtmetest. Jah, teil ei ole palju vaja saada kõige rohkem otsingupäringuid "Order Marshlow". Lihtsalt kasutage fraasi sisu ideena;
- Samuti ei tohiks seda madala sagedusega fraase kõrvaldada - need on väga sisu ideed, tänu sellele, millised olete tõenäoliselt võimelised rahuldama neid, kes suutsid selliseid teenuseid leida isegi suurimatest ettevõtetest;
- Ärge kasutage valemite ja koefitsientide võtmeõnade hindamiseks (nagu Kei, KKonkKuge populaarsuse suhe). Vaatame veel kord: semantika - lingvistika sektsioonis. See ei ole täpne teadus, nagu näiteks füüsika või matemaatika. See on lähemal kunstile kui täpseid uuringuid ning valemi või koefitsiendi nõuete täitmine kaotab semantika oma esiletõstmise. Nii et sa kaotad palju ideid teabe täitmiseks, mida saab programmi välistada - kuid mitte programm hiljem lugeda teksti;
- Ärge looge eraldi lehekülge ühe klahvi pärast. Kõik kindlasti kohtusid selliste online-ostudega, kus on spetsiaalseid lehekülgi "Osta kook" ja "tellige kook". Semantiline tuum on kadunud siin, sest sisuliselt on see sama tegevus. Või "Osta odav" ja "Osta odav" - need on sõnad sünonüümid, mistõttu ei ole kasutamata sisu eraldi lehekülg väärt;
- Ei ole vaja täielikult automatiseerida disain semantiline tuuma. Muidugi kasutasite spetsiaalsed tööriistad võtmelaused ja tohutute projektide jaoks on sellised tööriistad lihtsalt hädavajalikud - eriti võti koguja. Kuid ilma analüüsi ilma, mida mehe poolt toodetakse, on võtme väärtus madal. See ei ole suur saladus - isegi need, kes kasutavad vana kooli teadmisi teavad. Teenused muudavad meile lihtsamaks, kogudes teavet, mis vastasel juhul võtaks see pikka aega ja valusalt filtreerida, kuid tekst ei saa. Täpsemalt on sellised programmid olemas, kuid nende väärtus isiku jaoks on väike ja need on ette nähtud täielikult teiseks otstarbeks - mitte lugema kasutajat. Ainult üks, kes mõistab selles valdkonnas midagi, võib tegelikult kindlaks määrata konkurentsi aste, koostab teabefirma kava või analüüsib olukorda selles valdkonnas. Kõik kolm elementi on kaudselt liigendatud veebiressursside struktuuri ja märksõnade dispergeerimisega;
- Ära ole Plush - ei ole vaja keskenduda võtmelaualide kogumisele. Ainult alustades äritegevust, ei ole suurt punkti konkurentide ettevaatliku spionaaži läbiviimisel, koguge maksimaalsed märksõnad kõikidest kättesaadavatest otsingumootoritest kuni Hotbotini ja otsingumootorite uurimiseks. Piisab ühe - maksimaalsete kahe ressursside kasutamiseks ja see võib olla Yandex või Google. Noh või Rambler Mail.ru on halvim, kui see otsingumootor on populaarne teie piirkonnas. Tut.By - kui olete huvitatud konkreetsest Valgevene piirkonnast või Uaprotdl.com - Ukrainas. Kuid neid kasutatakse ainult piirkonnaga seondumisena: kui näiteks Valgevene elanikud on huvitatud "Ksenia Sitnik" koogid, ei ütle Venemaa resident üldse midagi. Ja seetõttu ei ole ka teie veebisaidi ülehinnatud.
Peame meeles pidama, miks ja miks sa tundud ehitad. Ja ka see on semantiline.
Nii et pärast seda, turundus või SEO?
On võimatu öelda, et üks teine \u200b\u200bvastuolus. Turustaja võib olla hea "CEESHNIK" ja vastupidi. Lihtsalt isikust, kes suudaks oma saidile semantilise kerneli õigesti teha, võtab see peamiselt ärimehe loogika ja turundaja (orientatsioon kliendile) ja veelgi - SEO valdkonnas spetsialisti oskused (nõuetekohaselt paigaldamine) Märksõnad). Sa pead mõistma, et teie ärimees võib pakkuda potentsiaalset tarbijat. Pärast seda tuleb aru saada, kuidas kliendid otsivad ja leida vajalikud andmed. Ja ülalkirjeldatud instrumendid aitavad kaasa. Analüüsige, Sift tarbetu, leida kõige sobivamad võtmed, klassifitseerida neid ja ergonoomiliselt hajutatud kogu struktuuri saidi. Ja Vua-la, nüüd on tulnud hetkeks, kui saate alustada sisu kava moodustumist. Tähelepanu !!!. Haldamine ei vastuta selle sisu eest.Sageli algaja Webmasters, silmitsi vajadust luua semantiline tuum, ei tea, kust alustada. Kuigi selles protsessis ei ole midagi keerulist. Lihtsamalt öeldes peate koguma peamiste fraaside nimekirja, mille jaoks Interneti kasutajad teie saidi kohta teavet otsivad.
Täiendavam ja täpsem on see lihtsam koopia hea koopia kirjutamine ja teil on soovitud taotluste otsimisel suured positsioonid. Kuidas teha suured ja kvaliteetsed semantilised tuumad õigesti ja mida nendega teha, kõrval, et sait läheb tippu ja kogub palju liiklust, ning see kõne selles materjalis.
Semantiline kernel on tähenduses usaldatud võtmelaused, kus iga rühm kajastab ühte vajadust või kasutaja soovi (kavatsuste). See tähendab, mida inimene mõtleb, ajendab tema taotlus otsinguringile.
Tuume loomise kogu protsessi saab esitada 4 sammuga:
- Kogu ülesanne või probleem;
- Pea me sõnastame, kuidas leida oma lahendus otsingu kaudu;
- Sõida taotluse Yandexile või Google'ile. Lisaks meile teevad teised inimesed sama;
- Kõige sagedasemad kõnevõimalused jagunevad analüüsiteenuseid ja saada peamisteks fraasideks, mida me vajame ja rühmime vajadustele. Kõigi nende manipulatsioonide tulemusena saadakse semantiline tuum.
Kas on vaja valida võtmelaused või kas te saate ilma selleta teha?
Varem oli semantika selleks, et leida teema kõige sagedamini märksõnad, sisestage need teksti ja saada otsingus hea nähtavuse. Viimase viie aasta jooksul otsingumootorid püüavad minna mudelile, kus asjakohasust dokumendi taotluse hinnatakse mitte sõnade arv ja erinevaid nende variatsioonide tekstis, kuid vastavalt hindamise kavatsuse avalikustamine.
Google on alustanud 2013. aastal Hummingbird algoritmi, Yandexi 2016. ja 2017. aastal vastavalt palae ja kuninganna tehnoloogiatega.
Texts kirjutatud ilma XIA ei saa täielikult avalikustada teema, mis tähendab konkureerida tippu kõrgsagedus- ja kesksageduste taotluste ei tööta. Panuste tegemine madala sagedusega taotlustele ei ole mõtet - neile liiga vähe liiklust.
Kui soovite ja tulevikus edukalt edendada ennast või oma toodet internetis - peate õppima, kuidas teha õige semantika, mis täiendab täielikult kasutajate vajadusi.
Otsingupäringute klassifikatsioon
Me uurime 3 tüüpi parameetreid, mille kohta märksõnu hinnatakse.
Sagedus:
- Kõrgsagedus (HF) - teema määratlevad fraasid. Koosneb 1-2 sõnast. Keskmiselt algab otsingupäringute arv 1000-3000 kuus ja jõuab sadade tuhandete muljeid sõltub teemast. Kõige sagedamini nende all on saitide peamised leheküljed.
- Keskmise kvaliteediklassi (SCH) - eraldi juhised subjektil. Eelistatavalt sisaldavad 2-3 sõna. Täpse sagedusega 500-1000-ni. Tavaliselt kategooriate kaubandusliku koha või teema suurte teavitamistoodete teema.
- Madala sagedusega (LF) - taotlused, mis on seotud konkreetse vastuse otsimisega. Reeglina alates 3-4 sõna. See võib olla tootekaart või artikli teema. Keskmiselt otsite 50-500 inimest kuus.
- Statistiliste meetrite metriliste või andmete analüüsimisel saate täita teise võtmete mikrokiirega. Need on fraasid, mis küsivad sageli otsingus. See ei ole mõtet teritama nende all, mida leht ei ole. See on piisav, et olla LF ülaosas, mis hõlmab neid.
Konkurentsivõime jaoks:
- Highborne (VC);
- Vahemere (SC);
- Longcoveri (NK);
Vajadustele:
- Navigeerimine. Väljendage kasutaja soovi leida konkreetse Interneti-ressursi või selle kohta teavet;
- Teave. Mida iseloomustab teabe kättesaadavus teabe saamisel vastuseks taotlusele;
- Tehing. Otseselt seotud sooviga osta;
- Fuzzy või tavaline. Need, kelle suhtes on raske täpselt kindlaks määrata.
- Geo-sõltuv ja geoni sõltuv. Peegeldavad vajadust otsida teavet või teha tehingu oma linna või ilma piirkondliku sidumiseta.

Sõltuvalt saidi tüübist saab semantilise kerneli võtmelausete valimisel manustada järgmisi soovitusi.
- Teaberessurss. Põhirõhk tuleks teha otsimisel artiklid kujul SCH ja madala konkurentsi LF taotlusi. Soovitatav on avaldada teema lai ja sügav, lohistades lehele suure hulga LF-klahve.
- E-poe või kaubanduslik sait. Kogume HF, SCH ja LF, mis on kõige selgemalt segmenteeritud nii, et kõik fraasid olid tehingutüüpiks ja seotud ühe klastriga. Rõhuasetus on hästi konverteeritava NC NK märksõnade otsimisel.
Kuidas teha suur semantiline kernel - samm-sammult juhised
Me läksime artikli põhiasse osa, kus ma järjekindlalt demonteerib peamised etapid, mida peate tulevase saidi kerneli ehitamiseks minema.
Selleks, et protsess oleks selgem, antakse kõik sammud näidetega.
Otsi põhilisi fraase
Koodeksiga töötamine algab põhiliste sõnade ja fraaside (HF) esmaste nimekirja valiku valikuga, mida iseloomustavad kõige paremini teemad ja neid kasutatakse laias mõttes. Neid nimetatakse ka markeriteks.
See võib olla nagu toodete suundade ja liikide nimed, populaarsed küsimused teemast. Reeglina koosnevad need 1-2 sõnast ja seal on kümneid ja mõnikord sadu tuhandeid näitajaid kuus. Paremad võtmed on paremad mitte võtta miinussõnade uputamine laienemisfaasis.
Mugavam valida marker fraase kasutades. Uurides taotlust sellele, vasakpoolses veerus näeme fraasid, mida ta sisaldab iseenesest, paremal - sarnased taotlused, millest saate tihti leida teema laiendamiseks. Samuti näitab teenus fraasi põhitegevuse, mis on mitu korda kuus kuud kõigis Wordformsis ja selle sõnadega lisamisega.

Selline sagedus ei ole väga huvitav, mistõttu on vaja kasutada operaatoreid täpsemate väärtuste saamiseks. Me analüüsime, mis see on ja mida.
Operaatorid Yandex Wordstat:
1) "..." - hinnapakkumised. Tsitaatide taotlus võimaldab teil jälgida, mitu korda Yandexis otsisite fraasi kõigi oma sõnaformidega, kuid lisamata teisi sõnu (saba).

2)! - hüüumärk. Kasutades seda enne iga sõna taotluse, me parandame selle oma kuju ja saada arvu kaebuste otsingus märksõna ainult määratud sõna kujul, kuid sabaga.

3) "! ...! ...! ..." - hinnapakkumisi ja hüüumärk enne iga sõna. Optimaiseri kõige olulisem operaator. See võimaldab teil mõista, mitu korda märksõna taotletakse kuu rangelt vastavalt antud fraasile, nagu on kirjutatud, lisamata sõnu.

4) +. Yandex Vordstat ei võta arvesse eessõnad ja asesõnad taotlemisel. Kui teil on vaja neid näidata - pane plussmärgi nende ees.

viis) -. Teine kõige olulisem operaator. Sellega sõnad, mis ei sobi kiiresti kõrvaldatud. Selle rakendamiseks pärast analüüsitud fraasi, paneme miinus ja peatada sõna. Kui need on mõnevõrra korrata protseduuri.

6) (... | ...). Kui teil on vaja Yandexist saada, sõlmivad mitu fraasid samaaegselt need sulgudes ja jagavad otsest ori. Praktikas kasutatakse meetodit harva.

Teenusega töötamise mugavuse huvides soovitan esitada Wordstati assistendi brauserile spetsiaalse laienduse. See asetatakse Mozilile, Google Chrome'ile, I.Baurazerile ja võimaldab teil kopeerida fraase ja nende sagedust ühe klõpsuga "+" või "Lisa kõik" ikoon.

Oletame, et otsustasime oma blogi tegevjuhile teha. Valige selle jaoks 7 peamist fraasi:
- semantiline kernel;
- optimeerimine;
- copywriting;
- edendamine;
- rahastamine;
- Otsene
Otsi sünonüüme
Kui küsitakse otsingusüsteemide abil, saavad kasutajad kasutada sõnade sulgemist, vaid erinevalt kirjalikult.
Näiteks "auto" ja "auto".
Oluline on leida, kuidas peamistele sõnadele võimalikult sünonüümid suurendada tulevase semantilise tuuma katvuse suurendamiseks. Kui seda ei tehta, siis kui pardal, me jätame kogu peamiste fraaside kiht, mis näitavad kasutajate vajadusi.
Mida me kasutame:
- Ajurünnaku;
- Õige veerg Yandex Wordstat;
- Külalaevade taotlused;
- Special termin, lühendid, slängi väljendeid teema;
- Blocks Yandex ja Google - koos "päringu nimi" otsivad;
- Võistlejate snappets.
Valitud teema kõigi tegevuste tulemusena saame sellise fraaside nimekirja:

Peamiste taotluste laiendamine
Me murdame need märksõnad inimeste põhivajaduste tuvastamiseks selles valdkonnas.
Mugavam teha seda peamise kollektoriprogrammis, kuid kui see on kahju maksta 1800 rubla litsentsi kohta, kasutage seda vaba analoog - mõõk.
Vastavalt funktsionaalsusele see on muidugi nõrgem, kuid väikeste projektide sobib.
Kui te ei soovi programmide töösse süveneda, saate kasutada just-maakesi teenuseid ja kiirustada analüüsi. Aga siiski on parem kulutada veidi aega ja tegeleda tarkvaraga.
Ma näitan KAY-kollektoris töötamise põhimõtet, kuid kui te töötate koos sõnaga, siis kõik mõistetakse ka kõik. Programmi liides on sarnane.
Menetlus:
1) Lisame programmi põhilaused ja eemaldada nende põhi- ja täpse sageduse. Kui plaanime edendada konkreetses piirkonnas - näitame piirkondlikkust. Teabekohtade jaoks ei ole kõige sagedamini vajalik.

2) Sparks vasakule veerg Yandex Wordstat vastavalt lisatud sõnad saada kõik taotlused meie teema.

3) väljumisel pöörasime 3374 fraasi. Me eemaldame nende täpse sageduse, nagu esimeses punktis.

4) Kontrollige, kas nimekirjas puuduvad võtmed nulliga põhitegevusega.

Kui me eemaldame ja läheme järgmise sammu juurde.
Miinus-sõnad
Paljud hooletusprotseduurid miinussõnade kogumise kord, asendades selle fraaside eemaldamisega, mis ei ole sobivad. Aga hiljem mõistate, et see on mugav ja tõesti säästab aega.
Avage Kay Collectori andmekaart -\u003e Analüüsis. Valige grupeerimisliik vastavalt üksikutele sõnadele ja lehtedele Nimekirja võtmed. Kui näete fraasi, mis ei sobi - vajutage sinist ikooni ja lisage sõna asemel sõna, et kõik selle wordware stop sõnad.

SLOBELis rakendatakse stoppla sõnadega tööd lihtsustatud versioonis, kuid saate teha ka oma fraaside loendi, mis ei sobi ja rakendage neid loendisse.
Ärge unustage kasutada põhitegevuse sorteerimist ja fraaside arvu. See valik aitab kiiresti vähendada allikate fraaside loendit või lõigata harva välja.

Kui oleme koostanud stopp-sõnade nimekirja, rakendage neid meie projektile ja jätkake otsinguväljakogude kogumist.
Parsimise nõuanded
Kui sisestate taotluse Yandexile või Google'ile, pakuvad otsingumootorid oma võimalusi jätkata kõige populaarsemaid fraase, mis on ajendatud Internetist. Neid märksõnu nimetatakse otsingunõueteks.
Paljud neist ei kuulu Wordstati juurde, nii et semantilise ehitamisel peate selliseid taotlusi koguma.
Kay kollektor, vaikimisi parsiidi neid büst lõpus, kirillitsa ja ladina tähestikku ja ruumi pärast iga fraasi. Kui olete valmis protsessi oluliselt kiirendama, kui olete valmis protsessi oluliselt kiirendama, asetage punkt "Koguge ainult tippnõudeid ilma katkestamiseta ja ruumi pärast fraasi".

Sageli leiate otsingumootorite hulgas häid sagedus ja konkurentsi fraasid kümnetes aegadel madalamal kui Vordstatis, nii et kitsastes nišides soovitan koguda maksimaalselt sõnu.
Otsingumootori serverite samaaegsete apellatsioonide arv sõltub otse otsimisaeg otseselt. Maksimaalne Kei koguja toetab 50 liiklust.
Aga selleks, et analüüsida taotlusi selles režiimis, siis on vaja nii palju volikirja ja kontod Yandex.
Meie projekti jaoks selgus pärast käskude kogumist selgus 29595 unikaalse fraasi. Aja jooksul võttis kogu protsess 10 lõngast veidi rohkem kui 2 tundi. See tähendab, et kui on 50, paned me 25 minuti pärast.

Kõigi fraaside põhi- ja täpse sageduse määratlus
Täiendava töö jaoks on oluline kindlaks määrata põhi- ja täpse sageduse ja katkesta kõik null. Väikese arvu näitustega taotlused jäävad sihtmärgile.
See aitab paremini mõista sisemist ja luua artikli täielikumat struktuuri kui ülaosas.
Sageduse eemaldamiseks esimene sear kõik tarbetu:
- sõnad
- võtmed teiste sümbolitega;
- hollandi fraasid (kaudse Oak "tööriista analüüs) kaudu)

Ülejäänud fraaside puhul määratleme täpne ja põhitegevus.
aga) fraaside puhul kuni 7 sõna:
- Me valime filtri kaudu "fraas koosneb enam kui 7 sõna"
- Avage aken "Kollektsioon Yandexdirect" klõpsates ikoonil "D";
- Kui täpsustate piirkonda;
- Valige garanteeritud ekraanirežiim;
- Me panime kogumisperioodi - 1 kuu ja märkme soovitud sageduse liikide kohal;
- Klõpsake "Get Data".

b) 8 sõna fraaside puhul:
- Me täpsustame veeru "fraasi" filtri - "koosneb vähemalt 8 sõnaga";
- Kui teil on vaja liikuda allolevas linnas, määrame piirkonna;
- Klõpsake suurendaja ja valige "Koguge kõik sagedused".

Prügi puhastamine prügi
Kui me said teavet meie võtmete kuvamiste arvu kohta, saate alustada sobiva kasutamise kasutamise.
Mõtle menetluse sammuks:
1. Mine "Gruppide analüüs" Kei koguja ja me sorteerime võtmed sõna kasutamise suuruse järgi. Ülesanne leida ebapiisav ja sagedane ja panna need nimekirja stop sõnad.
Me teeme kõik nii hästi kui "miinus sõnad".

2. Kohaldage meie fraaside loendisse kõik stop-sõnad leitud ja töötavad, et kindlasti ei kaota sihtmärgi päringuid. Pärast kontrollimist klõpsake nuppu Kustuta "Märgistatud fraasid".

3. Allikas puudusi laused, mida harva kasutatakse täpset sisenemist, kuid neil on kõrge alussagedus. Selleks sisestage võtme ja Serp peamise kollektori programmi seadetes arvutusvalemi: võti 1 \u003d (Yandexwordstatbasefreq) / (YandexwordstatquePointfreq) ja salvestage muudatused.

4. Teeme võti 1 arvutus ja eemaldada need fraasid, et see parameeter osutus 100 ja rohkem.

Ülejäänud võtmed peaksid grupeeritud pardaleheküljed.
Klastrite
Rühmade jaotus rühmade algab klastrite fraasidega piki ülevalt tasuta programm "Majento klastri". Ma soovitan, et makstud analoog laiema funktsionaalsuse ja kiire töö kiirusega - võtmehoidja, kuid ka piisavalt väike väike tuuma. Ainus nüanss, mis üheski neist tööks on vaja osta XML-piirid. Keskmine hind on 5 lk. 1000 taotlust. See tähendab, et keskmise südamiku töötlemine 20-30 tuhande võtmega maksab 100-150 lk. Teenuse aadressi, mis kasutab, vaadake allolevas ekraanipilt.

Võtmete klastrite olemus See meetod on kombineerida nende fraaside rühmade rühmadesse, millel on 10 Yandex:
- Ühised URL-id üksteisega (kõva)
- kõige sageduspäringu grupis (pehme).
Sõltuvalt erinevate saitide arvutuste arvust eristatakse klastrite künnised: 2, 3, 4 ... 10.
Meetodi eeliseks on fraaside rühmitamine inimeste vajaduste järgi ja mitte ainult sünonüümide ühendused. See võimaldab teil kohe mõista, milliseid märksõnu saab kasutada ühel parlamendilil.
Informatsioonide jaoks sobivad:
- Pehme künnisega 3-4 ja seejärel puhastage kätega;
- Raske 3-ke ja seejärel kombineerides klastreid tähenduses.
Online-kauplused ja kaubanduslikud saidid on tavaliselt arenenud kõva-y kolmekordse klastrite künnisega, nii et ma tõstan selle eraldi artiklis.
Sest meie projekti pärast grupeerimist kõva meetodiga 3. selgus 317 rühma.

Konkurentsi kontroll
See ei ole mõtet edendada väga konkurentsivõimeliste taotluste kaudu. Ülaosasse on raske siseneda ja ilma selleta ilma liiklust ei liiklust. Et mõista, milliseid teemasid on kasulik kirjutada järgmise meetodi abil:
Keskenduge fraasirühma täpsele sagedusele, millega artikkel on kirjalik ja konkurents mutageenil. Informatsioon saite, ma soovitan teha teema tööle, kus täielik täpne sagedus 300 ja kõrgem ja konkurentsikoefitsient 1 kuni 12 kaasava.
Kaubanduslikes teemadel keskenduge kaupade või teenuste marginaalsusele ja kuidas konkurendid teevad top 10. Isegi 5-10 sihtpunkti kuus võib olla põhjus teha eraldi lehekülje all.
Kuidas kontrollida konkureerida taotluse:
a) käsitsi, mis ajendas teenuse ise või massiliste ülesannete kaudu asjakohane fraas;

b) Partii režiimis läbi Kay Collectori programmi.

Teemade valimine ja rühmitamine
Mõtle iga saadud gruppi meie projekti pärast klastrite ja valida teema saidi.
Majento Erinevalt võti-assort ei võimalda iga fraasi näituste arvu andmete arvu alla laadida, nii et peate neid Kay kollektori kaudu lisaks eemaldama.
Juhend:
1) tühjendage kõik Grupid Majentost CSV-vormingus;
2) siduda fraasid Excelil "Grupp: võti" mask;
3) Laadige saadud nimekiri võtmehoidjasse. Seadetes peab see olema impordirežiimis "Grupp: võtme kontrollmärk ja mitte jälgida fraaside olemasolu teistes rühmades;

4) Me eemaldada põhilised ja täpsed sagedused märksõnade äsja loodud rühmade. (Kui kasutate võti sorte, ei ole vaja teha. Programm võimaldab teil töötada täiendavate veergudega)
5) Otsime klastreid ainulaadse intenteerimisega, mis sisaldavad vähemalt 3 fraasi ja kõigi taotluste arvu suuremate taotluste arvu üle 300. Järgmisena kontrollime 3-4 kõige sagedust mutageenil konkurentsile. Kui nende fraaside hulgas on konkurentsi võtmed, mis on vähem kui 12-aastased - töötavad;
6) Me vaatame ülejäänud rühma. Kui leitakse tähenduse lähedal olevad fraasid ja seda tasub vaadata ühe lehekülje piires - ühendame. Uute tähenduste sisaldavate rühmade puhul vaatame väljavaateid fraaside täieliku sageduse väljavaateid, kui see on vähem kui 150 kuus, siis asetage see hetkeni, mil te kogu tuuma läbi lähete. See võib osutuda kombineerida teise klastriga ja saada 300 täpset näitust - see on minimaalne, millest ta väärib tööd tööle. Käsitsi grupi kiirendamiseks kasutage abitööriistad: kiire filter ja sagedussõnastik. Nad aitavad teil kiiresti leida sobivaid fraase teistest klastritest;

Tähelepanu !!! Kuidas mõista, et klastreid saab kombineerida? Me võtame 2 sagedusvõtit nendest väljavõtmisel lõikes 5 maandumisleheküljele ja uue rühma taotlusele.
Lisame need Arsenkini tööriistale "Mahalaadimine Top 10", märkige vajadusel soovitud piirkond. Lisaks vaatame kolmas fraasi värvi ristumiskohtade arvu ülejäänud. Me ühendame rühmade, kui nad on 3 või enam. Kui ei ole kokku puutumata ega üks, on võimatu kombineerida - erinevate intensiivide puhul, 2 ristmikel, vt oma käte väljastamist ja kasutage loogikat.
7) Pärast valijate grupeerimist saame nimekirja paljulubava teemade nimekirja nende all olevate artiklite ja semantika teemade nimekirja.

Taotluste eemaldamine teise sisu tüübi jaoks
Semantilise tuuma valmistamisel on oluline mõista, et blogide ja teabekohtade jaoks ei ole kaubanduslikud taotlused vajalikud. Nii nagu veebipoodid ei vaja teavet.
Me jookseme läbi iga rühma ja puhastame kõik on tarbetu, kui päringu eesmärk on täpselt kindlaks määrata - emiteerimise võrdlemine või tööriistade kasutamine:
- Pixel Tulls'i turustamise kontrollimine (tasuta, kuid päevapiiranguga);
- teenus Lihtsalt maagia, klastrite kontrollmärgi kontrollmärgiga Kontrollige kaubanduslikult päringut (tasu, maksumus sõltub tariifist)
Pärast seda minge viimasele sammule.
Fraase optimeerimine
Me optimeerime semantilist tuuma, nii et see on mugav töötada sellega tulevikus SEO spetsialist ja copywriteris. Selleks jätame peamised fraasid igas rühmas, mis peegeldavad peamiselt inimeste vajadusi ja sisaldavad võimalikult palju sünonüüme peamistele fraasidele.
Algoritmi meetmete:
- Sorteeri märksõnad Excelis või Kay kollektori tähestikulises järjekorras A kuni Z;
- Vali need, kes paljastavad teema erinevatest külgedest ja erinevad sõnad. Muud asjad, mis on võrdsed lausest kõrgema täpse sagedusega või milles võti 1 indikaator (põhisageduse suhe täpne);
- Me eemaldame märksõna, mille arv näitab kuu vähem kui 7, mis ei kanna uusi tähendusi ega sisalda unikaalset sünonüüme.
Näide sellest, kuidas kompeteeritud semantiline tuum välja näeb -
Ma märkisin fraasid ei sobi intensiivsusele. Kui te eirata minu soovitusi käsitsi grupeerimise ja mitte kontrollida ühilduvuse ta väljastab, et leht optimeeritud kokkusobimatu võtmelaused ja suured positsioone progressiivsetele taotlustele ei näe enam.
Lõplik kontrollnimekiri
- Me valime peamised kõrgsageduslikud päringud, mis seadistavad teemad;
- Otsime nende sünonüüme, kasutades vasaku ja parema veeru Wordstati, konkurentide veebisaitide ja nende haarattide kasutamist;
- Laienda vastuvõetud taaskasutamise taotlused vasakule veergu Wordstatile;
- Me koostame nimekirja stop-sõnad ja kohaldatakse saadud fraase;
- Parsim Tips Yandex ja Google;
- Eemaldage põhi- ja täpne sagedus;
- Laiendage miinussõnade loendit. Me puhastame prügi ja RAHESi taotlustest
- Me teeme Clusteriseerimist Majento või Keyasti kaudu. Informatsiooni saitide pehme režiimis, künnise 3-4. Commercial Interneti-ressursside puhul, kasutades kõva meetodi künnisega 3.
- Me impordime andmeid Kay kollektoris ja määrame kindlaks iga klastri võistluse 3-4 fraaside jaoks ainulaadse intensiivsusega;
- Me valime teemasid ja määrame maandumislehekülgede jaoks päringuid, mis põhinevad täpsete näituste koguarvu hindamisel kõigis klastrites (alates 300-st informatsiooniks) ja konkurentsi kõige sageduseks mutageenil (kuni 12) .
- Iga sobiva lehekülje jaoks otsime teisi sarnaste kasutajate vajaduste klastreid. Kui me saame neid ühel lehel pidada - me ühendame. Kui vajadus ei ole selge või on kahtlusi, et sellele vastuseks sellele peaks olema teine \u200b\u200bsisu või lehekülgede tüüp - kontrollige, väljastades või tööriistade pixel Tulside või lihtsalt maagiaga. Sisu saitide puhul peaks kernel koosnema teabetaotlusedTehingute kaubanduslik kaubandus. Me kustutame liiga palju.
- Me sorteerime iga grupi võtmed tähestikulises järjekorras ja jätsime need nendest, kes kirjeldavad teemat erinevatest külgedest ja erinevatest sõnadest. Muud asjad, mis on võrdsed nende taotluste prioriteediga, mis on väiksemad kui põhisageduse ja täpsete näitajate arvu suhe kuus.
Mida teha SEO-tuuma pärast selle loomist
Nimekirja võtmete loendist andsid nad neile autorile ja ta kirjutas suurepärase artikli täielikult, avalikustades kõik tähendused. Eh, midagi, mida ma olen ummikus ... Sensible tekst on võimalik ainult siis, kui copywriter mõistab selgelt, et sa tahad teda ja kuidas ennast kontrollida.
Me analüüsime 4 komponenti, hästi tööd, mida sa garanteeritud, et saada palju sihtmärgi liiklust artiklis:
Hea struktuur. Analüüsime maandumislehe jaoks valitud taotlusi ja paljastame, mida inimesed selles küsimuses on vajalikud. Järgmisena kirjutage plaani artiklile, mis neile täielikult vastab. Ülesanne on teha inimesed lähevad saidile sai mahuline ja tervikliku vastuse semantika te valmistate. See annab hea käitumusliku ja väga oluline intensiivsusega. Kui olete plaani koostanud, vaadake konkurentide saitidel, võttes põhilise edutatava otsingutaotluse. Sa pead tegema sellises järjestuses. See tähendab, et kõigepealt me \u200b\u200bise teeme, siis me vaatame teisi ja kui me peame rafineerima.
Optimeerimine võtmete all. Artiklis on teritamine vastavalt 1-2 kõige sagedusklahvidega mutageeni konkurentsiga kuni 12-ni. Teine 2-3 keskmise sageduse fraase saab kasutada pealkirjadena, kuid lahjendatud kujul, mis tähendab, et täiendava mitte-teema sisestamine nende juurde , kasutades sünonüüme ja sõna. Peamine fookus Me teeme madala sagedusega fraasid, mis tõmbab välja unikaalse osa - saba ja ühtlaselt teksti. Otsingumootorid ise leiavad ja liimi.
Põhialade sünonüümid. Me kirjutame need meie semantilisest kernelist eraldi ja paneme Copywriter ülesandeks neid tekstis ühtlaselt kasutada. See aitab vähendada meie peamiste sõnade tihedust ja teksti optimeeritakse piisavalt, et tippu sattuda.
TEHNILISED FRAASID.Autor ise, LSI ei edendada lehele, kuid nende kohalolek näitab, et tõenäoliselt kirjalik tekst kuulub Peruu ekspert ja see on juba pluss kvaliteedi sisu. Temaatiliste fraaside otsimiseks kasutage Pixel Tulse'i copywriter'i tööriista tööriista.

Alternatiivne meetod Võtmelaused, kasutades võistleja analüüsi teenuseid
Semantilise kerneli loomiseks on kiire lähenemisviis, mis on kohaldatav nii uustulnukate kui ka kogenud kasutajatele. Meetodi olemus on see, et me esialgu vali võtmed mitte kogu saidi või kategooria jaoks, vaid konkreetselt artikli all istekoha lehel.
Seda saab realiseerida 2 viise, mis erinevad, kuidas me valime lehe teemad ja kui sügavalt laiendada võtmelaused:
- peamiste klahvide kasutamine;
- põhineb konkurentide analüüsile.
Igaüks neist saab rakendada lihtsas ja keerulisemas tasemel. Me analüüsime kõiki võimalusi.
Ilma programmide kasutamiseta
Koopiamasin või veebimeister ei taha sageli tegeleda suure hulga programmide liidesega, vaid teil on vaja hea teemasid ja peamisi fraase.
See meetod on vaid algajatele ja neile, kes ei taha vaeva. Kõik tegevused tehakse ilma täiendava tarkvara kasutamiseta, kasutades lihtsaid ja arusaadavaid teenuseid.
Mis võtab:
- Keys.So Service konkurentide analüüs - 1500 lk. Promotion "Altblog" - 15% soodustust;
- Mutageen. Kontrollige päringu konkurentsi - 30 Kopecks, põhi- ja täpse sageduse kogumise - 2 kopikat 1 kontrollimiseks;
- Buvillars - tasuta versioon või ärikonto - 995 lk. (nüüd soodushinnaga 695 p)
Valik 1. Valige teema läbi peamise fraasi maatüki:
- Me valime objektist peamised võtmed laias mõttes, kasutades Yandex Wordstati ajurünnakut ja vasakut ja paremat veerust;
- Lisaks otsime nende sünonüüme, mille meetodeid olid varakult öeldud;
- Me hindame kõik vastuvõetud markeri taotlused Raamatulennukile (peate tasuma tasu eest tasuma) arenenud režiimis "Otsi märksõnade loendis";
- Me täpsustame filtris: "! Täpne! Sagedus" 50-st sõnade arvust 3;
- Mahalaadimiseks kogu nimekirja Excelis;
- Me eraldame kõik märksõnad ja saata grupeerimisele "Clastier rusikate" teenusesse. Kui sait on piirkondlik piirkondlik vajalikku linna. Klastlitööstuse künnis teabe saitide lahkumiseks 2, kaubandusliku 3-KU jaoks;
- Pärast grupeerimist valida teemad artiklite sirvimise saadud klastrid. Me võtame need, kus fraase summa 3-st ja ainulaadse intenteerimisega. Parem on mõista inimeste vajadusi, mis aitavad analüüsida saitide URL-id ülevalt veeru "konkurendid" (paremal Kulakovi teenuseplaadil). Me ei unusta ka kontrollida mutageeni võistlust. Me purustame 2-3 taotlust klastrist. Kui rohkem kui 12, siis ei tohiks teemat võtta;
- Määrati tulevase sihtlehe nimi, jääb selleks peamised laused;
- Väli "Konkurentide" koopia 3 Ullas sobiva tüüpi lehekülgedega (kui sait on teave - viige viiteid artiklitele, kui kaubanduslik, siis kauplustes);
- Sisestage need järjestikku võtmetes ja laadima kõik nende võtmelaused;
- Me ühendame need Excelis ja eemaldame duplikaat;
- Andmed Ainult teenus ei ole piisav, seega on vaja neid laiendada. Me kasutame tahket tahket;
- Saadud nimekiri saadetakse klastrile "kliendivalem" rusikas;
- Me valime lossimislehe jaoks sobivate taotluste rühmadele, keskendudes kavatsusele;
- Me eemaldame põhilise ja täpse sageduse mutageeni kaudu "Mass ülesannete" režiimis;
- Laadige loend ajakohastatud andmetega Excelis näituste arvu järgi. Eemaldage mõlema sageduste tüübi null;
- Samuti lisage Excelis põhisageduse suhte suhte valem täpsuseks ja jätma ainult need võtmed, milles see on väiksem kui 100;
- Me kustutame teise sisu taotlused;
- Jätame fraase, et kõige tõhusamad ja erinevad sõnad näitavad peamist kavatsust;
- Me kordame kõiki samu meetmeid lõigetes 8-19 ülejäänud ülejäänud.
Option 2. Valige teema konkurentide analüüsi kaudu:
1. Otsime meie teema parimaid saite, mis ajendasid RF taotlusi ja vaatades väljastamise tööriista Arsenkin "Top 10" kaudu. See on piisav, et leida 1-2 sobivat ressursse.
Kui me edendame saiti konkreetses linnas, näitame piirkondlikkust;
2. Mine võtmed.So teenindamiseks ja sisestage saitide URL-id, mis leidsid ja vaatasid, milliseid konkurentide lehekülgi kõige rohkem liiklust toovad.
3. 3-5 kõige täpsemate sageduste taotluste kohta konkurentsivõime kontrollimiseks. Kui see on kõigis fraasides üle 12, siis on parem otsida teist teemat vähem konkurentsivõimeliseks.
4. Kui teil on vaja leida rohkem analüüsisaiteid, avage vahekaart "Võistlejad" ja seadke parameetrid: Sarnaselt 3, koostöö - 10. me sorteerime andmed liikluse vähenemise kohta.
5. Pärast seda, kui oleme teema valinud, sõitke oma nimi väljastusse ja koopia 3 Ullas ülevalt.
6. Järgmine, korduvad üksused 10-19 alates 1. valiku.
Kasutades kollektori kei või sõna
See meetod erineb eelnevalt kasutatavast kasutamisest mõnede operatsioonide programmi võtme koguja ja sügavamat peamist laienemist.
Mis võtab:
- võtme koguja programm - 1800 rubla;
- kõik samad teenused nagu eelmisel viisil.
"Advanced - 1"
- Parsim Yandexi vasakule ja paremale veeru kogu fraaside loendis;
- Eemaldage Kay koguja täpne ja põhitegevus;
- Arvuta võti 1;
- Me kustutame nullpäringud ja võtmega 1\u003e 100;
- Seejärel teeme kõik nii võimaluse 1 punktides 18-19.
"Advanced - 2"
- Teeme samme 1-5, nagu teostuses 2;
- Me kogume iga URL-i võtmeid võtmes.So;
- Me eemaldame Kay kollektoris duplikaadi;
- Me kordame lõikeid 1-4, nagu "Advanced -1" meetodis.
Nüüd võrrelda saadud võtmete arvu ja nende täpset kogusagedust erinevate meetodite kogumisel:
Nagu näeme tabelist, näitas parim tulemus alternatiivset meetodit tuuma loomiseks lehe all - "Advanced 1.2". Oli võimalik saada 34% rohkem sihtnuppi ja kogu liiklus klastris pöördus 51% rohkem kui klassikalise meetodi puhul.
Allpool ekraanipilte, võib näha, kuidas lõpetatud tuum välja näeb, iga juhtumi. Ma võtsin fraase täpse arvu hoiused 7 kuus, nii et märksõna kvaliteeti saaks hinnata. Täieliku semantika jaoks vaadake tabelit "Vt" linki.
AGA) 
B) 
Sisse) 
Nüüd sa tead, et kõige levinum viis ei ole alati tehtud, sest kõik teevad, kõige ustavam ja õige, kuid mitte keelduda muid meetodeid. Palju sõltub teemast ise. Äripaikade puhul, kus võtmed ei ole nii palju, piisavad ja klassikaline valik. Infosaitide kohta saate ka suurepäraseid tulemusi, kui te õigesti koostate korjaldase õigesti õigesti, teha hea struktuuri ja SEO optimeerimise. Me räägime sellest üksikasjalikult järgmistes artiklites.
3 sagedased vead semantilise kerneli loomisel
1. Koguge fraasid tipega. See ei ole piisav, et kuurordida WordStat saada hea tulemuse!
Rohkem kui 70% taotlustest, mida harva või perioodide toonud, ei jõua nad sinna. Kuid nende hulgas on sageli hea konverteerimise ja väga madala konkurentsiga võtmeisikute. Kuidas mitte jätta neid? Koguge kindlasti otsinguviisade ja ühendage need erinevate allikate andmetega (, saitide, statistiliste ja andmebaasi teenuste loendurid).
2. Teabe ja äritaotluste segamine ühel lehel.Oleme juba lahti võtnud, et peamised fraasid erinevad vajaduste liigist erinevad. Kui külastaja saabub teie saidile, kes soovib ostu sooritada ja näeb vastusena oma taotluse lehele koos artikliga, kuidas te arvate, et see on rahul? Mitte! Otsingusüsteemid mõtlevad ka siis, kui leht on järjestatud, mis tähendab keskmise ja RF fraaside ülemist ülaosa, mida saate kohe unustada. Seega, kui te kahtlete taotluse liiki määratlusega, vaadake väljastamist või kasutage pixel Tulls tööriistu, lihtsalt-maakesi, et teha kindlaks kaubandus.
3. Valik väga konkurentsivõimeliste taotluste edendamiseks. RF VK fraaside positsioonid on 60-70% sõltuvad käitumuslikest teguritest ja saada need tippu jõudmiseks. Mida rohkem taotlejaid, pikim järjekorda nendelt, kes soovivad ja kõrgemaid saitide nõudeid. Kõik, nagu elus või spordis. Maailma meistriks on palju raskem raskem kui teie linna pealkirja saamine.
Seetõttu on parem siseneda vaiksele ja mitte ülekuumenenud nišile.
Varem oli see veelgi keerulisem olla peal. Üles seisis põhimõttel, kes juhtis, ta sõi. Juhid langesid esimestesse kohtadesse ja nad võiksid neid liigutada ainult, kogudes käitumistegurid. Ja kuidas neid saada, kui olete teisel või kolmandal leheküljel ... Yandex rippinud selle suletud ringi 2015. aasta suvel, tutvustades mitme gangsteri algoritmi. Sisuliselt see on just see juhuslikult suurendada ja alandada positsioone saitide mõistmiseks, kas rohkem väärt kandidaate tundus leida ülaosas.
Kui palju raha alustamiseks on vaja?
Sellele küsimusele vastamiseks kaalume programmide ja teenuste vajaliku arsenali kulusid, et valmistada ja teadmata peamisi fraase 100 artikli kohta.
Minimaalne (sobib klassikalisele valikule):
1. Slobeli - tasuta
2. Majento klastri - tasuta
3. Tunnistage Captchi - 30 rubla.
4. XML-piirid - 70 rubla.
5. Kontrollige mutageeni taotluse konkurentsi - 10 kontrolli päevas tasuta
6. Kui te ei kohelda kuskil ja valmis kulutama parsidesse 20-30 tundi saate teha ilma volikirjata.
—————————
Tulemuseks on 100 rubla. Kui sisestate CAPTCHAS-i ja XML-piirid saavad oma saidilt üle kantud, valmistate tuuma üldiselt tasuta. Ainult päev on vaja veeta programmide ja teiste 3-4 päeva loomise ja haldamise veetmise veetmiseks, et oodata parsimise tulemusi.
Standardse semantistikomplekt (arenenud ja klassikalise meetodi jaoks):
1. Kay koguja - 1900 rubla
2. Kay Assort - 1700 rubla
3. BOOKWARIX (ärikonto) - 650 rubla.
4. Keys.So konkurendi analüüsi teenus - 1500 rubla.
5. 5 puhverserver - 350 rubla kuus
6. Antikapitch - umbes 30 rubla.
7. XML-piirid - umbes 80 rubla.
8. Konkurentsi kontrollimine Mutageni poolt (1 Check \u003d 30 Kopecks) - Tee 200 rubla.
———————-
Tulemuseks on 6410 rubla. Muidugi on võimalik teha ilma võtmeallikata, asendades selle Majento klastri ja Kay kollektori asemel sõna kasutamiseks. Siis piisavalt ja 2810 rubla.
Kas ma peaksin usaldama "Profi" kerneli arengut või paremat selle väljatöötamist ja tegema seda ise?
Kui inimene regulaarselt tegeleb oma lemmik asja, pumpamine välja, siis pärast loogika, selle tulemused peaksid olema täpselt parem kui uustulnuk selles valdkonnas. Kuid võti valikuga selgub kõik täpselt vastupidine.
Miks 90% juhtudest teeb uustulnuk parema professionaalseks?
See kõik on tee. Semantistliku ülesanne ei kogu teie jaoks parimat kernelit, vaid täita oma tööd minimaalse aja jooksul ja et selle kvaliteet teie jaoks korraldas.
Kui teete kõik ise nende algoritmide jaoks, mille kohta nad ütlesid varakult - tulemus on suurusjärgus suurem kahel põhjusel:
- Sa mõistad teema. Niisiis, sa tead oma klientide või saidi kasutajate vajadusi ning saate esialgses etapis laiendada parsimise markeri taotlusi, kasutades suurt hulka sünonüüme ja konkreetseid sõnu.
- Huvitatud teha kõike kvalitatiivselt. Ettevõtte omanik või töötaja ettevõttes, kus see toimib muidugi, tuleb küsimusele vastutustundlikumalt ja püüan teha kõik maksimaalsele. Mida täpsem on see kernel ja madalamate konkurentsivõimeliste taotluste täitmine, seda rohkem on võimalik sihtliikluse koguda ja seetõttu kasum sama investeeringuga sisu on suurem.
Kuidas leida ülejäänud 10%, mis muudavad kerneli paremaks kui sina?
Otsige ettevõtteid, kus peamiste fraaside valik on võtmepädevus. Ja arutage kohe, milline tulemus soovite, nagu kõik teisedki või maksimaalsed. Teisel juhul on see 2-3 korda kallim, kuid pikemas perspektiivis maksab see korduvalt ära. Neile, kes soovivad tellida teenust koos minuga, kogu vajaliku teabe ja tingimustega. Kvaliteedigarantii!
Miks see on nii oluline semantika täielikult töötada
Siin, nagu igas valdkonnas, on "hea ja halva valiku" põhimõte. Mis on tema olemus?
Iga päev seisame silmitsi asjaoluga, et me valime:
- tähendus isikuga, kes näib olevat midagi, vaid ei kinnita ega pettunud ennast harmooniliste suhete loomiseks nendega, kes vajavad;
- töö, mis ei meeldi või leida tööd, siis mida hing asub ja teeb seda oma elukutsega;
- rentida ruumi kauplusele mitte-kontrollpunktis või oota ikka veel, kuni te vaba, sobiv valik;
- võtke meeskond mitte parim juht Müük ja üks, kes on tänapäeva intervjuudes paremini näidanud.
Tundub, et kõik on selge. Ja kui te vaatate seda teiselt poolt, esitades iga valikuvõimaluse investeeringuna tulevikus. Siin algab see kõige huvitavama!
Salvestatud sellele. Kernel, 3-5 tuhat. Rahul nagu elevandid! Aga see, mis see toob kaasa:
a) Teabekohtade jaoks:
- Kahjum liikluse vähemalt 1,5 korda sama investeeringud sisu. Võrdlemine mitmesugused meetodid Võtmelaused saamine oleme juba avastanud kogenud viis, et alternatiivne meetod võimaldab teil koguda 51% rohkem;
- Projekt saadab kiiresti väljaandmisse. Võistlejad on meie ümber lihtne saada, andes intensiivsusele täielikuma vastuse.
b) kaubanduslike projektide puhul:
- Vähem pliid või suurendada nende maksumust. Kui meil on semantika, nagu kõik teisedki, liigume me samade taotlustega konkurentidena. Suur hulk Ettepanekud pideva nõudlusega vähendab igaühe osakaalu turul;
- Madal konversioon. Konkreetsed taotlused Paremini konverteeritud müügiks. Salvestage seitse. Kernel, me kaotame kõige konversiooniklahve;
- Raskem edasi liikuda. Paljud soovivad olla ülaosas iga kandidaadi nõuete kohal.
Soovin teile alati teha hea valik Ja investeerida ainult pluss!
P.S. Bonus "Kuidas kirjutada hea artikkel halbade semantikaga", samuti muu elu töö elu ja töötasu internetis, loe minu grupis

































