As consultas no Access são a principal ferramenta para recuperar, atualizar e manipular dados em tabelas de banco de dados. O Access, de acordo com o conceito de bancos de dados relacionais, utiliza Structured Query Language (SQL) para executar as consultas. Qualquer consulta no Access é implementada usando instruções SQL.
O principal tipo de consulta é uma consulta selecionada. O resultado desta consulta é uma nova tabela que existe antes de a consulta ser fechada. Os registros são formados pela combinação dos registros das tabelas nas quais a consulta é construída. A forma de combinar os registros da tabela é especificada ao definir sua relação no esquema de dados ou ao criar uma consulta. As condições de seleção formuladas na consulta permitem filtrar os registros que constituem o resultado da junção de tabelas.
O Access pode criar vários tipos de consultas:
- buscar pedido- seleciona dados de uma única tabela ou consulta, ou várias tabelas relacionadas e outras consultas. O resultado é uma tabela que existe antes do fechamento da consulta. A formação dos registros da tabela de resultados é realizada de acordo com as condições de seleção especificadas e quando se utilizam várias tabelas pela combinação de seus registros;
- consulta para criar uma tabela- seleciona dados de tabelas interconectadas e outras consultas, mas, ao contrário de uma consulta selecionada, salva o resultado em uma nova tabela permanente;
- atualizar, adicionar, excluir solicitações- são solicitações de ação, como resultado das quais os dados nas tabelas são alterados.
As consultas no Access em modo de design contêm um esquema de dados que exibe as tabelas usadas e um formulário de consulta, que constrói a estrutura da tabela de consulta e as condições para selecionar os registros (Figura 4.1).
Usando uma consulta, você pode executar os seguintes tipos de processamento de dados:
- incluir na tabela de consulta os campos da tabela selecionada pelo usuário;
- fazer cálculos em cada um dos registros recebidos;
- selecionar registros que atendam aos critérios de seleção;
- criar uma nova tabela virtual baseada na união de registros de tabelas relacionadas;
- agrupar registros que possuem os mesmos valores em um ou vários campos, simultaneamente realizam funções estatísticas em outros campos do grupo e incluem um registro para cada grupo no resultado;
- crie uma nova tabela de banco de dados usando dados de tabelas existentes;
- atualizar os campos no subconjunto de registros selecionado;
- exclua o subconjunto de registros selecionado da tabela do banco de dados;
- adicione o subconjunto de registros selecionado a outra tabela.
As consultas no Access servem como fontes de registros para outras consultas, formulários, relatórios. Usando uma consulta, você pode coletar informações completas para a formação de um determinado documento da área de assunto a partir de várias tabelas e, em seguida, usá-las para criar um formulário - uma representação eletrônica desse documento. Se um formulário ou relatório for criado pelo assistente com base em várias tabelas interconectadas, uma consulta será gerada automaticamente para eles como uma fonte de registro.
Para consolidar, assista ao vídeo tutorial.
As solicitações são escritas sem aspas de escape, uma vez que MySQL, MS SQL e PostGree Eles são diferentes.
Consulta SQL: obtenção de campos especificados (obrigatórios) de uma tabela
SELECT id, country_title, count_people FROM table_nameRecebemos uma lista de registros: TODOS os países e sua população. Os nomes dos campos obrigatórios são separados por vírgulas.
SELECT * FROM nome_tabela
* denota todos os campos. Ou seja, haverá impressões TUDO campos de dados.
Consulta SQL: registros de saída de uma tabela, excluindo duplicatas
SELECT DISTINCT country_title FROM table_nameObtemos uma lista de registros: os países onde nossos usuários estão localizados. Pode haver muitos usuários de um país. Neste caso, este é o seu pedido.
Consulta SQL: exibição de registros de uma tabela de acordo com uma condição especificada
SELECT id, country_title, city_title FROM table_name WHERE count_people> 100000000Obtemos uma lista de registros: países onde o número de pessoas é superior a 100 milhões.
Consulta SQL: exibindo registros de uma tabela com ordenação
SELECT id, city_title FROM table_name ORDER BY city_titleObtemos uma lista de registros: cidades em ordem alfabética. No início de A, no final de I.
SELECT id, city_title FROM table_name ORDER BY city_title DESC
Recebemos uma lista de registros: cidades ao contrário ( DESC) OK. No começo eu, no final A.
Consulta SQL: contando o número de registros
SELECT COUNT (*) FROM nome_tabelaObtemos o número (número) de registros na tabela. Neste caso, NÃO existe uma lista de registros.
Consulta SQL: produz o intervalo necessário de registros
SELECT * FROM nome_tabela LIMIT 2, 3Obtemos 2 (segundos) e 3 (terceiros) registros da tabela. A solicitação é útil ao criar navegação em páginas da WEB.
Consultas SQL com condições
Saída de registros de uma tabela de acordo com uma determinada condição usando operadores lógicos.
Consulta SQL: construção E
SELECT id, city_title FROM table_name WHERE country = "Russia" AND oil = 1Recebemos uma lista de registros: cidades da Rússia E têm acesso a óleo. Quando o operador é usado E, então as duas condições devem corresponder.
Consulta SQL: construção OR
SELECT id, city_title FROM table_name WHERE country = "Rússia" OR country = "USA"Recebemos uma lista de registros: todas as cidades da Rússia OU EUA. Quando o operador é usado OU, então, pelo menos uma condição deve corresponder.
Consulta SQL: E NÃO construir
SELECT id, user_login FROM table_name WHERE country = "Russia" E NÃO count_comments<7Recebemos uma lista de registros: todos os usuários da Rússia E Quem fez NÃO MENOS 7 comentários.
Consulta SQL: construção IN (B)
SELECT id, user_login FROM table_name WHERE country IN ("Rússia", "Bulgária", "China")Recebemos uma lista de registros: todos os usuários que vivem em ( NO) (Rússia, Bulgária ou China)
Consulta SQL: construção NOT IN
SELECT id, user_login FROM table_name WHERE country NOT IN ("Rússia", "China")Recebemos uma lista de registros: todos os usuários que não moram em ( NÃO EM) (Rússia ou China).
Consulta SQL: construção IS NULL (valores vazios ou NÃO vazios)
SELECT id, user_login FROM table_name WHERE status IS NULLObtemos uma lista de registros: todos os usuários cujo status não foi definido. NULL é um tópico separado e, portanto, verificado separadamente.
SELECT id, user_login FROM nome_tabela ONDE o estado NÃO É NULO
Obtemos uma lista de registros: todos os usuários onde o status é definido (NÃO ZERO).
Consulta SQL: construção LIKE
SELECT id, user_login FROM table_name ONDE sobrenome LIKE "Ivan%"Obtemos uma lista de registros: usuários cujo sobrenome começa com a combinação "Ivan". O sinal% significa QUALQUER número de QUALQUER caractere. Para encontrar o sinal%, você precisa usar o escape "Ivan \%".
Consulta SQL: construção BETWEEN
SELECT id, user_login FROM table_name ONDE salário ENTRE 25000 E 50000Recebemos uma lista de registros: usuários que recebem salários de 25.000 a 50.000 inclusive.
Existem MUITOS operadores lógicos, portanto, estude a documentação do servidor SQL em detalhes.
Consultas SQL complexas
Consulta SQL: combinação de várias consultas
(SELECT id, user_login FROM table_name1) UNION (SELECT id, user_login FROM table_name2)Obtemos uma lista de cadastros: usuários cadastrados no sistema, bem como usuários cadastrados no fórum separadamente. Várias consultas podem ser combinadas com o operador UNION. UNION atua como SELECT DISTINCT, ou seja, descarta valores duplicados. Para obter absolutamente todos os registros, você precisa usar o operador UNION ALL.
Consulta SQL: contando valores de campo MAX, MIN, SUM, AVG, COUNT
Saída de um, o valor máximo do contador na tabela:
SELECT MAX (contador) FROM nome_tabelaSaída de um, o valor mínimo do contador na tabela:
SELECT MIN (contador) FROM nome_tabelaExibindo a soma de todos os valores do contador na tabela:
SELECT SUM (contador) FROM nome_tabelaExibindo o valor médio do contador na tabela:
SELECIONE AVG (contador) FROM nome_tabelaExibindo o número de contadores na tabela:
SELECT COUNT (contador) FROM nome_tabelaExibição do número de contadores na oficina nº 1, na tabela:
SELECT COUNT (contador) FROM nome_tabela WHERE escritório = "Loja # 1"Esses são os comandos mais populares. Recomenda-se, sempre que possível, o uso de consultas SQL desse tipo para cálculos, uma vez que nenhum ambiente de programação pode comparar a velocidade de processamento de dados com o próprio servidor SQL ao processar seus próprios dados.
Consulta SQL: agrupamento de registros
SELECT continente, SUM (country_area) FROM país GROUP BY continenteObtemos uma lista de registros: com o nome do continente e com a soma das áreas de todos os seus países. Ou seja, se houver um diretório de países onde cada país tem sua área registrada, então usando a cláusula GROUP BY, é possível saber o tamanho de cada continente (com base no agrupamento por continente).
Consulta SQL: usando várias tabelas por meio de alias
SELECT o.order_no, o.amount_paid, c.company FROM orders AS o, customer AS with WHERE o.custno = c.custno AND c.city = "Tyumen"Recebemos uma lista de registros: pedidos de clientes que moram apenas em Tyumen.
Na verdade, com um banco de dados deste tipo devidamente projetado, a consulta é a mais frequente, portanto, um operador especial foi introduzido no MySQL, que funciona muitas vezes mais rápido do que o código escrito acima.
SELECT o.order_no, o.amount_paid, z.company FROM orders AS o LEFT JOIN customer AS z ON (z.custno = o.custno)
Subconsultas aninhadas
SELECT * FROM nome_tabela WHERE salário = (SELECT MAX (salário) FROM funcionário)Recebemos um registro: informações sobre o usuário com salário máximo.
Atenção! As subconsultas aninhadas são um dos gargalos nos servidores SQL. Junto com sua flexibilidade e potência, eles também aumentam significativamente a carga no servidor. O que leva a uma desaceleração catastrófica no trabalho de outros usuários. Casos de chamadas recursivas com consultas aninhadas são muito comuns. Portanto, eu recomendo fortemente NÃO usar consultas aninhadas, mas dividi-las em consultas menores. Ou use a combinação LEFT JOIN acima. Além desse tipo de solicitação, as solicitações são um foco crescente de violações de segurança. Se você decidir usar subconsultas aninhadas, precisará projetá-las com muito cuidado e fazer as execuções iniciais nas cópias dos bancos de dados (bancos de dados de teste).
Consultas SQL alterando dados
Consulta SQL: INSERT
Instruções INSERIR permitem inserir registros em uma tabela. Em palavras simples, crie uma linha com os dados da tabela.
Opção número 1. A instrução é frequentemente usada:
INSERT INTO table_name (id, user_login) VALUES (1, "ivanov"), (2, "petrov")Na mesa " Nome da tabela"2 (dois) usuários serão inseridos de uma vez.
Opção número 2. É mais conveniente usar o estilo:
INSERT table_name SET id = 1, user_login = "ivanov"; INSERT table_name SET id = 2, user_login = "petrov";Isso tem suas vantagens e desvantagens.
Principais desvantagens:
- Muitas consultas SQL pequenas são executadas um pouco mais lentamente do que uma consulta SQL grande, mas outras consultas serão enfileiradas para o serviço. Ou seja, se uma grande consulta SQL for executada por 30 minutos, então, durante todo esse tempo, o resto das consultas fumarão bambu e aguardarão sua vez.
- O pedido acabou sendo mais massivo do que a versão anterior.
Vantagens principais:
- Durante pequenas consultas SQL, outras consultas SQL não são bloqueadas.
- Facilidade de leitura.
- Flexibilidade. Nesta opção, você não pode seguir a estrutura, mas apenas adicionar os dados necessários.
- Ao formar arquivos desta forma, você pode facilmente copiar uma linha e executá-la através da linha de comando (console), não restaurando assim todo o ARQUIVO.
- O estilo de escrita é semelhante ao da instrução UPDATE, o que a torna mais fácil de lembrar.
Consulta SQL: UPDATE
UPDATE table_name SET user_login = "ivanov", user_surname = "Ivanov" WHERE id = 1Na mesa " Nome da tabela"No registro com id = 1, os valores dos campos user_login e user_surname serão alterados para os valores especificados.
Consulta SQL: DELETE
DELETE FROM table_name WHERE id = 3O registro com id número 3 será excluído da tabela nome_tabela.
- Recomenda-se escrever todos os nomes de campo em letras minúsculas e, se necessário, separá-los com um espaço forçado "_" para compatibilidade com diferentes linguagens de programação como Delphi, Perl, Python e Ruby.
- Escreva comandos SQL em letras MAIÚSCULAS para facilitar a leitura. Lembre-se sempre de que outras pessoas podem ler o código depois de você e, provavelmente, você mesmo depois de N período de tempo.
- Campos de nomes a partir do início do substantivo e, em seguida, a ação. Por exemplo: city_status, user_login, user_name.
- Tente evitar palavras de retorno em diferentes linguagens que podem causar problemas em SQL, PHP ou Perl, como (nome, contagem, link). Por exemplo: link pode ser usado no MS SQL, mas é reservado no MySQL.
Este material é uma referência curta para o trabalho diário e não pretende ser uma fonte super-mega autorizada, que é a fonte primária de consultas SQL para um banco de dados específico.
Cada um de nós regularmente se depara e usa vários bancos de dados. Quando escolhemos um endereço de email, estamos trabalhando com um banco de dados. Os bancos de dados usam mecanismos de pesquisa, bancos para armazenar dados de clientes, etc.
Mas, apesar do uso constante de bancos de dados, mesmo para muitos desenvolvedores de sistemas de software existem muitos "pontos em branco" devido a diferentes interpretações dos mesmos termos. Daremos uma breve definição dos termos básicos do banco de dados antes de examinar a linguagem SQL. Então.
Base de dados - um arquivo ou conjunto de arquivos para armazenar estruturas de dados ordenadas e seus relacionamentos. Muitas vezes, um sistema de controle é chamado de banco de dados - é apenas um armazenamento de informações em um determinado formato e pode funcionar com vários SGBDs.
tabela - Imagine uma pasta que armazena documentos agrupados por determinado critério, por exemplo, uma lista de pedidos do último mês. Esta é a tabela no computador. Uma tabela separada tem seu próprio nome exclusivo.
Tipo de dados - o tipo de informação que pode ser armazenada em uma coluna ou linha separada. Podem ser números ou texto em um formato específico.
Coluna e linha- todos trabalhamos com planilhas, que também têm linhas e colunas. Qualquer banco de dados relacional funciona com tabelas de maneira semelhante. As linhas às vezes são chamadas de registros.
Chave primária- cada linha da tabela pode ter uma ou mais colunas para sua identificação única. Sem uma chave primária, é muito difícil atualizar, modificar e excluir as linhas necessárias.
O que é SQL?
SQL(Inglês - linguagem de consulta estruturada) foi desenvolvido apenas para trabalhar com bancos de dados e atualmente é o padrão para todos os DBMS populares. A sintaxe da linguagem consiste em um pequeno número de operadores e é fácil de aprender. Mas, apesar da simplicidade externa, permite a criação de consultas sql para operações complexas com um banco de dados de qualquer tamanho.
Desde 1992, existe um padrão geralmente aceito chamado ANSI SQL. Ele define a sintaxe e funções básicas dos operadores e é suportado por todos os líderes do mercado de SGBD, como ORACLE. É impossível considerar todos os recursos da linguagem em um pequeno artigo, por isso consideraremos brevemente apenas consultas SQL básicas . Os exemplos mostram claramente a simplicidade e os recursos da linguagem:
- criação de bases de dados e tabelas;
- buscar dados;
- adicionar registros;
- modificação e exclusão de informações.
Tipos de dados SQL
Todas as colunas em uma tabela de banco de dados armazenam o mesmo tipo de dados. Os tipos de dados em SQL são iguais aos de outras linguagens de programação.
Crie tabelas e bancos de dados

Existem duas maneiras de criar novos bancos de dados, tabelas e outras consultas em SQL:
- através do console DBMS
- Usando as ferramentas de administração online incluídas com o servidor de banco de dados.
Um novo banco de dados é criado pelo operador CRIAR BASE DE DADOS<наименование базы данных>; ... Como você pode ver, a sintaxe é simples e concisa.
Criamos tabelas dentro do banco de dados com a instrução CREATE TABLE com os seguintes parâmetros:
- Nome da tabela
- nomes de coluna e tipos de dados
Como exemplo, vamos criar uma tabela Commodity com as seguintes colunas:
Criamos uma mesa:
CRIAR TABELA Commodity
(commodity_id CHAR (15) NÃO NULO,
vendor_id CHAR (15) NÃO NULO,
commodity_name CHAR (254) NULL,
commodity_price DECIMAL (8,2) NULL,
commodity_desc VARCHAR (1000) NULL);
A tabela possui cinco colunas. O nome é seguido pelo tipo de dados, as colunas são separadas por vírgulas. O valor da coluna pode ser nulo (NULL) ou deve ser preenchido (NOT NULL), e isso é determinado quando a tabela é criada.
Buscando dados de uma tabela

O operador de seleção de dados é a consulta SQL usada com mais frequência. Para obter informações, é necessário indicar o que queremos selecionar dessa tabela. Vamos começar com um exemplo simples:
SELECIONE commodity_name FROM Commodity
Após a instrução SELECT, especificamos o nome da coluna para obter as informações e FROM define a tabela.
O resultado da execução da consulta será todas as linhas da tabela com os valores Commodity_name na ordem em que foram inseridos no banco de dados, ou seja, sem qualquer classificação. Uma cláusula ORDER BY adicional é usada para ordenar o resultado.
Para uma consulta em vários campos, nós os listamos separados por vírgulas, como no exemplo a seguir:
SELECT commodity_id, commodity_name, commodity_price FROM Commodity
É possível obter o valor de todas as colunas de uma linha como resultado de uma consulta. Para fazer isso, use o sinal "*":
SELECIONE * DA commodity
- Além disso, o SELECT oferece suporte a:
- Classificação de dados (operador ORDER BY)
- Seleção de acordo com as condições (ONDE)
- Termo de agrupamento (GROUP BY)
Adicione a linha

Para adicionar uma linha à tabela, são usadas consultas SQL com a instrução INSERT. A adição pode ser feita de três maneiras:
- adicione uma nova linha inteira;
- parte de uma corda;
- resultados da consulta.
Para adicionar uma linha completa, você deve especificar o nome da tabela e os valores das colunas (campos) da nova linha. Vamos dar um exemplo:
INSERT INTO Commodity VALUES ("106", "50", "Coca-Cola", "1,68", "Sem Alcogol,)
O exemplo adiciona um novo produto à mesa. Os valores são especificados após VALUES para cada coluna. Se não houver um valor correspondente para a coluna, NULL deve ser especificado. As colunas são preenchidas com valores na ordem especificada quando a tabela foi criada.
Se você adicionar apenas uma parte de uma linha, deve especificar explicitamente os nomes das colunas, como no exemplo:
INSERT INTO Commodity (commodity_id, vendor_id, commodity_name)
VALORES ("106", '50 "," Coca-Cola ",)
Inserimos apenas os identificadores do produto, fornecedor e seu nome, e deixamos o restante dos campos em branco.
Adicionando resultados de consulta
INSERT é usado principalmente para adicionar linhas, mas também pode ser usado para adicionar os resultados de uma instrução SELECT.
Mudança de dados

Para alterar as informações nos campos da tabela do banco de dados, você deve usar a instrução UPDATE. O operador pode ser usado de duas maneiras:
- Todas as linhas da tabela são atualizadas.
- Apenas para uma linha específica.
UPDATE tem três elementos principais:
- a tabela na qual você precisa fazer alterações;
- nomes de campo e seus novos valores;
- condições para selecionar as linhas a serem alteradas.
Vejamos um exemplo. Digamos que o custo de um item com ID = 106 mudou, então esta linha precisa ser atualizada. Escrevemos o seguinte operador:
UPDATE Commodity SET commodity_price = "3.2" WHERE commodity_id = "106"
Indicamos o nome da tabela, no nosso caso Commodity, onde será realizada a atualização, depois de SET - o novo valor da coluna e encontramos o registro requerido especificando o valor do ID requerido em WHERE.
Para modificar várias colunas, vários pares de valor de coluna são especificados após a instrução SET, separados por vírgulas. Vejamos um exemplo que atualiza o nome e o preço de um produto:
ATUALIZAR Commodity SET commodity_name = 'Fanta', commodity_price = "3.2" ONDE commodity_id = "106"
Para remover informações em uma coluna, você pode defini-la como NULL se a estrutura da tabela permitir. Deve-se lembrar que NULL é exatamente "nenhum" valor, e não zero na forma de texto ou números. Vamos excluir a descrição do produto:
UPDATE Commodity SET commodity_desc = NULL WHERE commodity_id = "106"
Excluindo linhas

As consultas SQL para excluir linhas em uma tabela são executadas pela instrução DELETE. Existem dois casos de uso:
- certas linhas são excluídas da tabela;
- todas as linhas da tabela são excluídas.
Um exemplo de exclusão de uma linha de uma tabela:
DELETE FROM Commodity WHERE commodity_id = "106"
Depois de DELETE FROM, especificamos o nome da tabela na qual as linhas serão excluídas. A cláusula WHERE contém uma condição pela qual as linhas para exclusão serão selecionadas. No exemplo, estamos excluindo a linha do produto com ID = 106. É muito importante especificar ONDE. omitir essa instrução excluirá todas as linhas da tabela. Isso também se aplica à alteração do valor dos campos.
A instrução DELETE não inclui nomes de colunas ou metacaracteres. Exclui linhas inteiramente, mas não pode excluir uma única coluna.
Usando SQL no Microsoft Access

Geralmente é usado interativamente para criar tabelas, bancos de dados, para gerenciar, modificar, analisar dados em um banco de dados e para incorporar consultas SQL Access por meio de um Designer de Consulta interativo conveniente, com o qual você pode construir e executar imediatamente instruções SQL de qualquer complexidade ...
O modo de acesso ao servidor também é suportado, no qual o Access DBMS pode ser utilizado como gerador de consultas SQL a qualquer fonte de dados ODBC. Esse recurso permite que os aplicativos do Access interajam com qualquer formato.
Extensões SQL
Como as consultas SQL não possuem todos os recursos das linguagens de programação procedural, como loops, branches, etc., os fornecedores de banco de dados desenvolvem sua própria versão do SQL com recursos avançados. Em primeiro lugar, é o suporte para procedimentos armazenados e operadores padrão de linguagens procedurais.
Os dialetos mais comuns do idioma:
- Banco de dados Oracle - PL / SQL
- Interbase, Firebird - PSQL
- Microsoft SQL Server - Transact-SQL
- PostgreSQL - PL / pgSQL.
SQL na Internet
O MySQL é distribuído sob a GNU General Public License. Existe uma licença comercial com a capacidade de desenvolver módulos personalizados. Como parte integrante, está incluído nas montagens mais populares de servidores de Internet, como XAMPP, WAMP e LAMP, e é o DBMS mais popular para o desenvolvimento de aplicativos na Internet.
Ele foi desenvolvido pela Sun Microsystems e atualmente é suportado pela Oracle Corporation. São suportados bancos de dados de até 64 terabytes, padrão de sintaxe SQL: 2003, replicação de banco de dados e serviços em nuvem.
Expressões de tabela as subconsultas são nomeadas e usadas onde a tabela deve existir. Existem dois tipos de expressões de tabela:
tabelas derivadas;
expressões de tabela generalizadas.
Essas duas formas de expressões de tabela são discutidas nas subseções a seguir.
Tabelas derivadas
Tabela derivadaé uma expressão de tabela incluída na cláusula FROM da consulta. As tabelas derivadas podem ser usadas quando os aliases de coluna não são viáveis porque o conversor de SQL processa outra instrução antes que o alias seja conhecido. O exemplo abaixo tenta usar um alias de coluna em uma situação em que outra cláusula é processada antes que o alias seja conhecido:
USE SampleDb; SELECT MONTH (EnterDate) como enter_month FROM Works_on GROUP BY enter_month;
A tentativa de executar esta consulta resultará na seguinte mensagem de erro:
Msg 207, nível 16, estado 1, linha 5 Nome de coluna inválido "enter_month". (Msg 207: Nível 16, Estado 1, Linha 5 Nome de coluna inválido enter_month)
A causa do erro é que a cláusula GROUP BY é processada antes que a lista SELECT associada seja processada e o alias da coluna enter_month não é conhecido durante o processamento deste grupo.
Este problema pode ser resolvido usando uma tabela derivada que contém a consulta anterior (sem a cláusula GROUP BY), uma vez que a cláusula FROM é executada antes da cláusula GROUP BY:
USE SampleDb; SELECT enter_month FROM (SELECT MONTH (EnterDate) como enter_month FROM Works_on) AS m GROUP BY enter_month;
O resultado da execução desta consulta será assim:
Normalmente, a expressão da tabela pode ser colocada em qualquer lugar na instrução SELECT onde o nome da tabela pode aparecer. (O resultado de uma expressão de tabela é sempre uma tabela ou, em casos especiais, uma expressão.) O exemplo a seguir mostra o uso de uma expressão de tabela na lista de seleção de uma instrução SELECT:
O resultado desta consulta:

Expressões de tabela generalizadas
Expressão de tabela comum (CTE)é uma expressão de tabela nomeada com suporte da linguagem Transact-SQL. Expressões de tabela genéricas são usadas nos dois tipos de consulta a seguir:
não recursivo;
recursivo.
Esses dois tipos de solicitações são discutidos nas seções a seguir.
OTB e consultas não recursivas
Você pode usar o formulário OTB não recursivo como uma alternativa às tabelas e visualizações derivadas. Normalmente OTB é definido por COM cláusulas e uma consulta opcional que faz referência ao nome usado na cláusula WITH. A palavra-chave WITH é ambígua em Transact-SQL. Para evitar ambigüidade, termine a instrução que precede a cláusula WITH com um ponto-e-vírgula.
USE AdventureWorks2012; SELECIONE SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue> (SELECT AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR (OrderDate) = "2005") AND Freight> (SELECIONE AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR (OrderDate 2005 ") / 2,5;
A consulta neste exemplo seleciona pedidos cujos impostos totais (TotalDue) são maiores que a média de todos os impostos e cujos encargos de frete (Frete) são maiores que 40% da média dos impostos. A principal propriedade desta consulta é o seu volume, já que a subconsulta precisa ser escrita duas vezes. Uma maneira possível de reduzir o tamanho da construção da consulta é criar uma visualização que contenha uma subconsulta. Mas esta solução é um tanto difícil, pois requer a criação de uma visualização e, em seguida, sua exclusão após o final da execução da consulta. A melhor abordagem seria criar um OTB. O exemplo abaixo demonstra o uso de OTB não recursivo, que abrevia a definição de consulta acima:
USE AdventureWorks2012; WITH price_calc (year_2005) AS (SELECT AVG (TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR (OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue> (SELECT year_2005 FROM price_calc) E Fre2005) / 2,5;
A sintaxe da cláusula WITH em consultas não recursivas é:
O parâmetro cte_name representa o nome OTB que identifica a tabela resultante e o parâmetro column_list representa a lista de colunas na expressão da tabela. (No exemplo acima, o OTB é denominado price_calc e tem uma coluna, year_2005.) O parâmetro inner_query representa uma instrução SELECT que define o conjunto de resultados da expressão de tabela correspondente. A expressão de tabela definida pode então ser usada na consulta externa outer_query. (A consulta externa no exemplo acima usa o preço_calc OTB e sua coluna ano_2005 para simplificar a consulta aninhada dupla.)
OTB e consultas recursivas
Esta seção apresenta material de complexidade aumentada. Portanto, ao lê-lo pela primeira vez, é recomendável ignorá-lo e retornar a ele mais tarde. Os OTBs podem implementar recursões, pois os OTBs podem conter referências a si próprios. A sintaxe OTB básica para uma consulta recursiva é assim:
Os parâmetros cte_name e column_list têm o mesmo significado que em OTB para consultas não recursivas. O corpo da cláusula WITH consiste em duas consultas combinadas pelo operador UNION ALL... A primeira consulta é chamada apenas uma vez e começa a acumular o resultado da recursão. O primeiro operando do operador UNION ALL não se refere a OTB. Essa consulta é chamada de consulta ou fonte de referência.
A segunda solicitação contém um link para OTB e representa sua parte recursiva. Por isso, é chamado de membro recursivo. Na primeira chamada para a parte recursiva, a referência OTB representa o resultado da consulta de referência. O membro recursivo usa o resultado da primeira chamada para a consulta. Depois disso, o sistema chama a parte recursiva novamente. Uma chamada para um membro recursivo é encerrada quando uma chamada anterior para ele retorna um conjunto de resultados vazio.
O operador UNION ALL concatena as strings atualmente acumuladas, bem como as strings adicionais adicionadas pela chamada atual ao membro recursivo. (A presença do operador UNION ALL significa que as linhas duplicadas não serão removidas do resultado.)
Finalmente, o parâmetro outer_query define uma consulta externa que usa OTB para obter todas as chamadas para a união de ambos os membros.
Para demonstrar um formulário OTB recursivo, usamos a tabela Avião definida e preenchida com o código mostrado no exemplo abaixo:
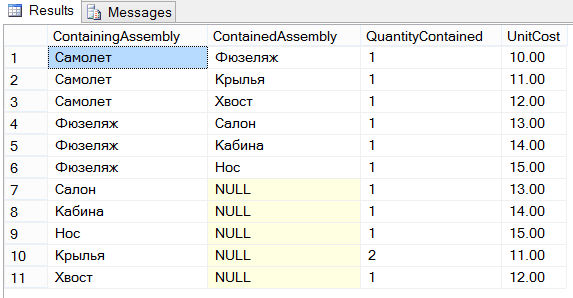
USE SampleDb; CREATE TABLE Avião (ContainingAssembly VARCHAR (10), ContainedAssembly VARCHAR (10), QuantityContained INT, UnitCost DECIMAL (6,2)); INSERT INTO Airplane VALUES ("Airplane", "Fuselage", 1, 10); INSERT INTO Airplane VALUES ("Airplane", "Wings", 1, 11); INSERT INTO Airplane VALUES ("Airplane", "Tail", 1, 12); INSERT INTO Airplane VALUES ("Fuselage", "Salon", 1, 13); INSERIR EM AVIÕES VALORES ("Fuselagem", "Cabine", 1, 14); INSERT INTO Airplane VALUES ("Fuselage", "Nose", 1, 15); INSERIR EM AVIÕES VALORES ("Salão", NULL, 1.13); INSERIR EM AVIÕES VALORES ("Cabine", NULL, 1, 14); INSERT INTO Avião VALORES ("Nose", NULL, 1, 15); INSERIR EM AVIÕES VALORES ("Asas", NULL, 2, 11); INSERT INTO Avião VALORES ("Tail", NULL, 1, 12);
A tabela Avião possui quatro colunas. A coluna ContainingAssembly identifica a montagem e a coluna ContainedAssembly identifica as peças (uma após a outra) que constituem a montagem correspondente. A figura abaixo fornece uma ilustração gráfica de um possível tipo de aeronave e suas partes constituintes:

A tabela Avião consiste nas seguintes 11 linhas:
O exemplo abaixo mostra a cláusula WITH usada para definir uma consulta que calcula o custo total de cada montagem:
USE SampleDb; COM list_of_parts (assembly1, quantidade, custo) AS (SELECT ContainingAssembly, QuantityContained, UnitCost FROM Airplane WHERE ContainedAssembly IS NULL UNION TODOS SELECIONE a.ContainingAssembly, a.QuantityContained, CAST (l.quantity * l.cost AS DECIMAL (6,2) ) FROM list_of_parts l, Airplane a WHERE l.assembly1 = a.ContainedAssembly) SELECT assembly1 "Parte", quantidade "Qty", custo "Price" FROM list_of_parts;
A cláusula WITH define uma lista OTB chamada list_of_parts com três colunas: assembly1, quantidade e custo. A primeira instrução SELECT no exemplo é chamada apenas uma vez para preservar os resultados da primeira etapa do processo de recursão. A instrução SELECT na última linha do exemplo exibe o seguinte resultado.
Última atualização: 05/07/2017
No tópico anterior, um banco de dados simples com uma tabela foi criado no SQL Management Studio. Agora vamos definir e executar a primeira consulta SQL. Para fazer isso, abra o SQL Management Studio, clique com o botão direito do mouse no elemento de nível superior no Object Explorer (nome do servidor) e selecione New Query no menu de contexto que aparece:
Depois disso, uma janela para inserir comandos SQL será aberta na parte central do programa.
Vamos executar uma consulta à tabela que foi criada no tópico anterior, em particular, iremos obter todos os dados dela. Nosso banco de dados é denominado universidade, e a tabela é dbo.Students, portanto, para obter os dados da tabela, inseriremos a seguinte consulta:
SELECT * FROM university.dbo.Students
A instrução SELECT permite que você selecione dados. FROM indica a fonte de onde obter os dados. Na verdade, com esta consulta, dizemos "SELECT all FROM table university.dbo.Students". Vale ressaltar que para o nome da tabela é utilizado o seu caminho completo, indicando o banco de dados e o esquema.
Após inserir a consulta, clique no botão Executar da barra de ferramentas ou pressione a tecla F5.
Como resultado da execução da consulta, uma pequena tabela aparece na parte inferior do programa que exibe os resultados da consulta - ou seja, todos os dados da tabela Alunos.
Se precisarmos fazer várias consultas ao mesmo banco de dados, podemos usar o comando USE para confirmar o banco de dados. Neste caso, ao fazer consultas às tabelas, basta especificar o seu nome sem o nome da base de dados e do esquema:
USE universidade SELECT * FROM Students
Nesse caso, estamos realizando uma solicitação para o servidor como um todo, podemos acessar qualquer banco de dados do servidor. Mas também podemos executar consultas apenas em um banco de dados específico. Para fazer isso, clique com o botão direito do mouse no banco de dados necessário e selecione o item Nova Consulta no menu de contexto:
Se neste caso quisermos executar uma consulta à tabela Alunos utilizada acima, não teríamos que indicar o nome da base de dados e o esquema na consulta, uma vez que estes valores já estariam claros.






























")


