Receber dados privados nem sempre significa hackear - às vezes são publicados em domínio público. Conhecimento Configurações do Google e um pouco de engenhosidade permitirá que você encontre muitas coisas interessantes - de números de cartão de crédito a documentos do FBI.
AVISO
Todas as informações são fornecidas apenas para fins informativos. Nem os editores nem o autor são responsáveis por qualquer possível dano causado pelos materiais deste artigo.Tudo está conectado à Internet hoje, pouco se importando em restringir o acesso. Portanto, muitos dados privados tornam-se presas dos motores de busca. Os robôs Spider não estão mais limitados a páginas da Web, mas indexam todo o conteúdo disponível na Web e adicionam constantemente informações confidenciais aos seus bancos de dados. Aprender esses segredos é fácil - você só precisa saber como perguntar sobre eles.
Procurando por arquivos
Em mãos capazes, o Google encontrará rapidamente tudo o que há de ruim na Web, como informações pessoais e arquivos para uso oficial. Eles geralmente ficam escondidos como uma chave debaixo do tapete: não há restrições reais de acesso, os dados ficam apenas na parte de trás do site, onde os links não levam. A interface da web padrão do Google fornece apenas configurações básicas pesquisa avançada, mas mesmo esses serão suficientes.
Existem dois operadores que você pode usar para restringir as pesquisas do Google a arquivos de um determinado tipo: filetype e ext . O primeiro define o formato que o mecanismo de pesquisa determinou pelo cabeçalho do arquivo, o segundo - a extensão do arquivo, independentemente de seu conteúdo interno. Ao pesquisar em ambos os casos, você precisa especificar apenas a extensão. Inicialmente, o operador ext era conveniente para usar nos casos em que não havia características de formato específicas para o arquivo (por exemplo, para procurar arquivos de configuração ini e cfg, dentro dos quais qualquer coisa pode estar). Agora os algoritmos do Google mudaram e não há diferença visível entre os operadores - os resultados são os mesmos na maioria dos casos.

Filtrando a saída
Por padrão, o Google procura por palavras e, em geral, por quaisquer caracteres inseridos em todos os arquivos nas páginas indexadas. Você pode limitar o escopo da pesquisa por domínio nível superior, um site específico ou a localização da sequência desejada nos próprios arquivos. Para as duas primeiras opções, a declaração do site é usada, seguida do nome do domínio ou do site selecionado. No terceiro caso, todo um conjunto de operadores permite pesquisar informações em campos de serviço e metadados. Por exemplo, allinurl encontrará o especificado no corpo dos próprios links, allinanchor - no texto fornecido com a tag , allintitle - nos cabeçalhos das páginas, allintext - no corpo das páginas.
Para cada operador existe uma versão mais leve com um nome mais curto (sem o prefixo all). A diferença é que allinurl encontrará links com todas as palavras, enquanto inurl só encontrará links com a primeira delas. A segunda e as palavras subsequentes da consulta podem aparecer em qualquer lugar nas páginas da web. O operador inurl também difere de outro similar em significado - site . O primeiro também permite encontrar qualquer sequência de caracteres no link para o documento desejado (por exemplo, /cgi-bin/), que é amplamente utilizado para encontrar componentes com vulnerabilidades conhecidas.
Vamos tentar na prática. Pegamos o filtro allintext e fazemos com que a consulta retorne uma lista de números de cartão de crédito e códigos de verificação, que expirarão somente após dois anos (ou quando seus donos se cansarem de alimentar todos em fila).
Allintext: data de validade do número do cartão /2017 cvv 
Quando você lê as notícias de que um jovem hacker "invadiu os servidores" do Pentágono ou da NASA, roubando informações classificadas, na maioria dos casos é precisamente essa técnica elementar de usar o Google. Suponha que estamos interessados em uma lista de funcionários da NASA e seus detalhes de contato. Certamente essa lista está em formato eletrônico. Por conveniência ou por descuido, também pode estar no próprio site da organização. É lógico que neste caso não haverá referências a ele, pois se destina ao uso interno. Que palavras podem estar em tal arquivo? Pelo menos - o campo "endereço". É fácil testar todas essas suposições.

inurl: nasa.gov tipo de arquivo: xlsx "endereço"

Usamos a burocracia
Tais achados são uma ninharia agradável. A pegadinha realmente sólida vem de um conhecimento mais detalhado dos operadores do Google Webmaster, da própria Web e da estrutura do que você está procurando. Conhecendo os detalhes, você pode filtrar facilmente a saída e refinar as propriedades dos arquivos necessários para obter dados realmente valiosos no restante. É engraçado que a burocracia vem em socorro aqui. Ele produz formulações típicas que facilitam a busca de informações secretas que vazaram acidentalmente na Web.
Por exemplo, o carimbo da declaração de distribuição, que é obrigatório no escritório do Departamento de Defesa dos EUA, significa restrições padronizadas na distribuição de um documento. A letra A marca lançamentos públicos em que não há nada secreto; B - destinado apenas ao uso interno, C - estritamente confidencial, e assim por diante até F. Separadamente, há a letra X, que marca informações especialmente valiosas que representam um segredo de estado do mais alto nível. Procurem esses documentos aqueles que devem fazê-lo de plantão, e nos limitaremos aos arquivos com a letra C. De acordo com a DoDI 5230.24, essa marcação é atribuída a documentos que contenham uma descrição de tecnologias críticas que estejam sob controle de exportação. Você pode encontrar essas informações cuidadosamente guardadas em sites no domínio de nível superior .mil alocado ao Exército dos EUA.
"DECLARAÇÃO DE DISTRIBUIÇÃO C" inurl:navy.mil 
É muito conveniente que apenas sites do Departamento de Defesa dos EUA e suas organizações contratadas sejam coletados no domínio .mil. Os resultados de pesquisa limitados por domínio são excepcionalmente limpos e os títulos falam por si. É praticamente inútil procurar segredos russos dessa maneira: o caos reina nos domínios .ru e .rf, e os nomes de muitos sistemas de armas soam como botânicos (PP "Kiparis", armas autopropulsadas "Acacia") ou até fabuloso (TOS "Pinóquio").

Ao examinar cuidadosamente qualquer documento de um site no domínio .mil, você pode ver outros marcadores para refinar sua pesquisa. Por exemplo, uma referência às restrições de exportação "Sec 2751", que também é conveniente para pesquisar informações técnicas interessantes. De tempos em tempos, ele é removido dos sites oficiais, onde já apareceu, portanto, se você não conseguir seguir um link interessante nos resultados da pesquisa, use o cache do Google (operador de cache) ou o site do Internet Archive.
Subimos nas nuvens
Além de documentos desclassificados acidentalmente de departamentos governamentais, links para arquivos pessoais do Dropbox e outros serviços de armazenamento de dados que criam links "privados" para dados publicados publicamente ocasionalmente aparecem no cache do Google. É ainda pior com serviços alternativos e self-made. Por exemplo, a consulta a seguir encontra os dados de todos os clientes da Verizon que possuem um servidor FTP instalado e usando ativamente um roteador em seu roteador.
Allinurl:ftp://verizon.net
Existem agora mais de quarenta mil pessoas inteligentes, e na primavera de 2015 havia uma ordem de magnitude a mais. Em vez de Verizon.net, você pode substituir o nome de qualquer provedor conhecido e, quanto mais famoso, maior a captura. Através do servidor FTP integrado, você pode ver os arquivos em uma unidade externa conectada ao roteador. Normalmente, este é um NAS para trabalho remoto, uma nuvem pessoal ou algum tipo de download de arquivo ponto a ponto. Todo o conteúdo dessa mídia é indexado pelo Google e outros mecanismos de busca, para que você possa acessar os arquivos armazenados em unidades externas por meio de um link direto.

Configurações de espionagem
Antes da migração em massa para as nuvens, servidores FTP simples, que também não tinham vulnerabilidades, funcionavam como armazenamentos remotos. Muitos deles ainda são relevantes hoje. Por exemplo, o popular programa WS_FTP Professional armazena dados de configuração, contas de usuário e senhas no arquivo ws_ftp.ini. É fácil de encontrar e ler porque todas as entradas são armazenadas em texto simples e as senhas são criptografadas usando o algoritmo Triple DES após ofuscação mínima. Na maioria das versões, basta descartar o primeiro byte.

Descriptografar essas senhas é fácil usando o utilitário WS_FTP Password Decryptor ou um serviço da web gratuito.

Quando se fala em hackear um site arbitrário, geralmente significa obter uma senha de logs e backups de CMS ou arquivos de configuração de aplicativos de comércio eletrônico. Se você conhece sua estrutura típica, pode indicar facilmente as palavras-chave. Linhas como as encontradas em ws_ftp.ini são extremamente comuns. Por exemplo, Drupal e PrestaShop sempre têm um ID de usuário (UID) e uma senha correspondente (pwd), e todas as informações são armazenadas em arquivos com a extensão .inc. Você pode procurá-los assim:
"pwd=" "UID=" ext:inc
Revelamos senhas do DBMS
Nos arquivos de configuração dos servidores SQL, os nomes de usuário e endereços de e-mail são armazenados em texto não criptografado e, em vez de senhas, seus hashes MD5 são registrados. Descriptografá-los, estritamente falando, é impossível, mas você pode encontrar uma correspondência entre pares conhecidos de hash-senha.

Até agora, existem DBMSs que nem usam hash de senha. Os arquivos de configuração de qualquer um deles podem simplesmente ser visualizados no navegador.
Intext: DB_PASSWORD tipo de arquivo: env

Com o advento de Servidores Windows o lugar dos arquivos de configuração foi parcialmente ocupado pelo registro. Você pode pesquisar em suas ramificações exatamente da mesma maneira, usando reg como o tipo de arquivo. Por exemplo, assim:
Tipo de arquivo: reg HKEY_CURRENT_USER "Senha"=
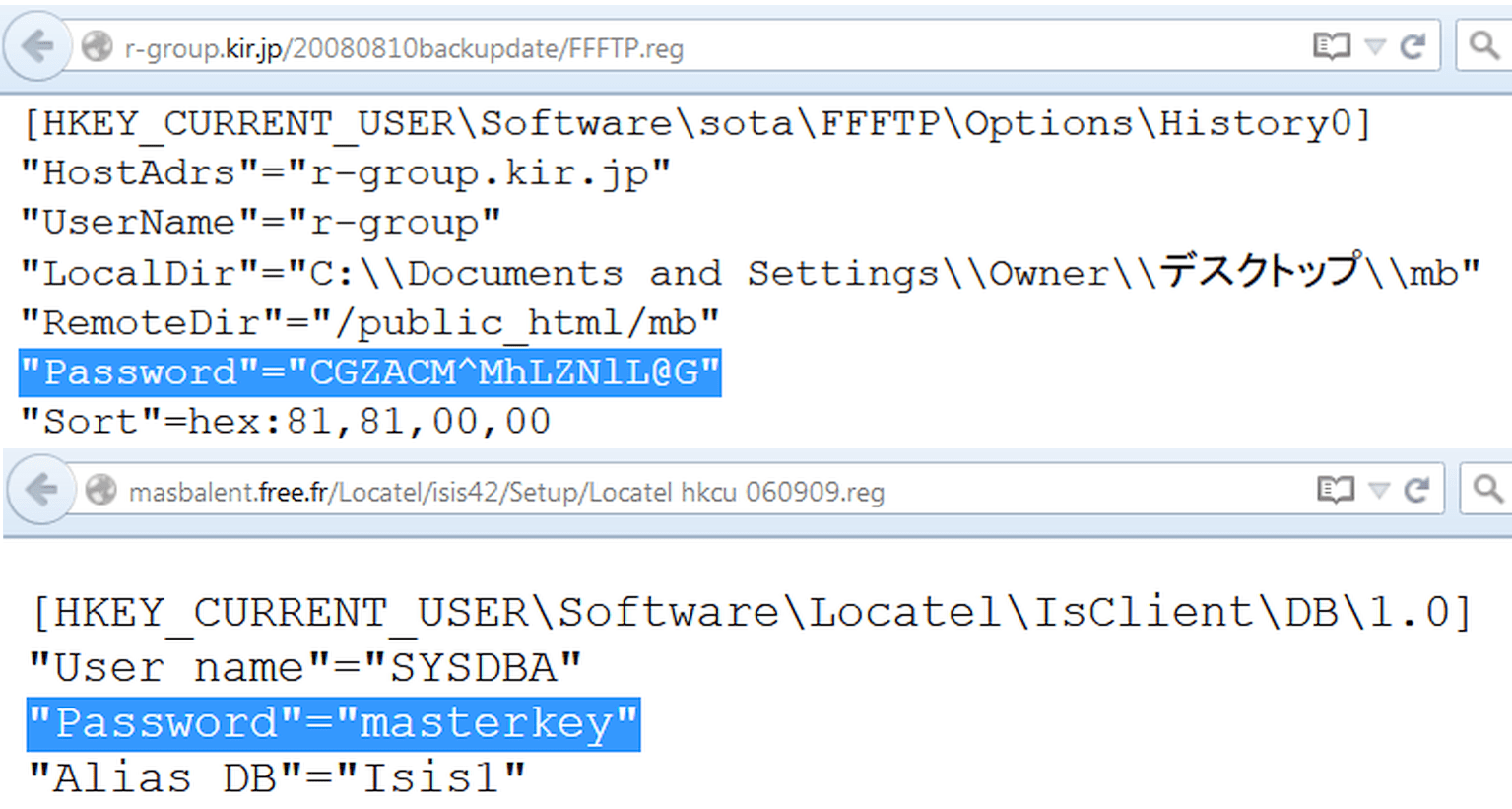
Não se esqueça do óbvio
Às vezes, é possível obter informações classificadas com a ajuda de acidentalmente abertas e capturadas no campo de visão dados do google. A opção ideal é encontrar uma lista de senhas em algum formato comum. Armazene as informações da conta em um arquivo de texto, Documento do Word ou eletrônico planilha do Excel Somente pessoas desesperadas podem, mas sempre há o suficiente.
Tipo de arquivo: xls inurl: senha

Por um lado, existem muitos meios para prevenir tais incidentes. É necessário especificar direitos de acesso adequados no htaccess, corrigir o CMS, não usar scripts à esquerda e fechar outros buracos. Há também um arquivo com uma lista de exclusão robots.txt, que proíbe os mecanismos de pesquisa de indexar os arquivos e diretórios especificados nele. Por outro lado, se a estrutura do robots.txt em algum servidor for diferente do padrão, fica imediatamente claro o que eles estão tentando ocultar nele.

A lista de diretórios e arquivos em qualquer site é precedida pelo índice de inscrição padrão de. Como deve aparecer no título para fins de serviço, faz sentido limitar sua busca ao operador intitle. Coisas interessantes podem ser encontradas nos diretórios /admin/, /personal/, /etc/ e até mesmo /secret/.

Acompanhe as atualizações
A relevância é extremamente importante aqui: vulnerabilidades antigas são fechadas muito lentamente, mas o Google e seus resultados de pesquisa estão mudando constantemente. Existe até uma diferença entre o filtro "último segundo" (&tbs=qdr:s no final da URL de solicitação) e o filtro "tempo real" (&tbs=qdr:1).
O intervalo de tempo da data da última atualização do arquivo do Google também é indicado implicitamente. Por meio da interface gráfica da web, você pode selecionar um dos períodos típicos (hora, dia, semana etc.) ou definir um intervalo de datas, mas esse método não é adequado para automação.
A partir da aparência da barra de endereços, pode-se apenas adivinhar uma maneira de limitar a saída de resultados usando a construção &tbs=qdr:. A letra y depois de especificar um limite de um ano (&tbs=qdr:y), m mostra os resultados do último mês, w da semana, d do dia anterior, h da última hora, n do minuto, e s para me dar um segundo. Os resultados mais recentes divulgados ao Google são encontrados usando o filtro &tbs=qdr:1.
Se você precisar escrever um script complicado, será útil saber que o intervalo de datas está definido no Google no formato juliano por meio do operador daterange. Por exemplo, é assim que você pode encontrar a lista Documentos PDF com a palavra confidencial carregada de 1º de janeiro a 1º de julho de 2015.
Tipo de arquivo confidencial: pdf intervalo de datas: 2457024-2457205
O intervalo é especificado no formato de data juliana sem decimais. É inconveniente traduzi-los manualmente do calendário gregoriano. É mais fácil usar um conversor de data.
Segmentação e filtragem novamente
Além de especificar operadores adicionais na consulta de pesquisa, eles podem ser enviados diretamente no corpo do link. Por exemplo, a característica filetype:pdf corresponde à construção as_filetype=pdf. Assim, é conveniente definir quaisquer esclarecimentos. Digamos que a saída de resultados apenas da República de Honduras seja definida adicionando a construção cr=countryHN ao URL de pesquisa, mas apenas da cidade de Bobruisk - gcs=Bobruisk . Consulte a seção do desenvolvedor para obter uma lista completa de .
As ferramentas de automação do Google são projetadas para facilitar a vida, mas muitas vezes aumentam o incômodo. Por exemplo, a cidade de um usuário é determinada pelo IP do usuário por meio do WHOIS. Com base nessas informações, o Google não apenas equilibra a carga entre os servidores, mas também altera os resultados. Procurar Resultados. Dependendo da região, para a mesma consulta, resultados diferentes chegarão à primeira página e alguns deles podem ficar completamente ocultos. Sinta-se como um cosmopolita e procure informações de qualquer país ajudará seu código de duas letras após a diretiva gl=country . Por exemplo, o código da Holanda é NL, enquanto o Vaticano e a Coreia do Norte não têm seu próprio código no Google.
Muitas vezes, os resultados da pesquisa ficam confusos mesmo depois de usar alguns filtros avançados. Nesse caso, é fácil refinar a consulta adicionando algumas palavras de exceção (cada uma delas é precedida por um sinal de menos). Por exemplo, banking , names e tutorial são frequentemente usados com a palavra Personal. Portanto, resultados de pesquisa mais limpos mostrarão não um exemplo de consulta de livro didático, mas um refinado:
Intitle:"Índice de /Pessoal/" -nomes -tutorial -banco
Último exemplo
Um hacker sofisticado se distingue pelo fato de fornecer tudo o que precisa por conta própria. Por exemplo, uma VPN é uma coisa conveniente, mas cara ou temporária e com restrições. Inscrever-se sozinho é muito caro. É bom que haja assinaturas em grupo, mas com o GoogleÉ fácil fazer parte de um grupo. Para fazer isso, basta encontrar o arquivo de configuração Cisco VPN, que tem uma extensão PCF bastante fora do padrão e um caminho reconhecível: Program Files\Cisco Systems\VPN Client\Profiles . Um pedido e você se junta, por exemplo, à simpática equipe da Universidade de Bonn.
Tipo de arquivo: pcf vpn OR Group

INFORMAÇÕES
O Google encontra arquivos de configuração com senhas, mas muitos deles são criptografados ou substituídos por hashes. Se você vir strings de comprimento fixo, procure imediatamente um serviço de descriptografia.As senhas são armazenadas de forma criptografada, mas Maurice Massard já escreveu um programa para descriptografá-las e está fornecendo gratuitamente via thecampusgeeks.com.
Com a ajuda do Google, são realizados centenas de diferentes tipos de ataques e testes de penetração. Existem muitas opções, afetando programas populares, principais formatos de banco de dados, inúmeras vulnerabilidades PHP, nuvens e assim por diante. Saber exatamente o que você está procurando torna muito mais fácil obter as informações que você precisa (especialmente as informações que você não pretendia tornar públicas). Não apenas Shodan alimenta ideias interessantes, mas qualquer banco de dados de recursos de rede indexados!
Este artigo será útil principalmente para otimizadores iniciantes, porque os mais avançados já devem saber tudo sobre eles. Para usar este artigo com a máxima eficiência, é desejável saber exatamente quais palavras precisam ser promovidas para as posições corretas. Se você ainda não tem certeza sobre a lista de palavras ou usa um serviço de sugestão de palavras-chave, é um pouco confuso, mas você pode descobrir.
Importante! Certifique-se de que o Google está ciente de que os usuários comuns não os usarão e apenas os especialistas em promoção recorrerão à ajuda deles. Portanto, o Google pode distorcer ligeiramente as informações fornecidas.
Operador de título:
Uso: título: palavra
Exemplo: intitle: promoção do site
Descrição: Ao utilizar este operador, você receberá uma lista de páginas que contêm a palavra que lhe interessa no título (título), no nosso caso, trata-se da frase "promoção do site" na íntegra. Observe que não deve haver um espaço após os dois pontos. O título da página é importante na classificação, portanto, leve seus títulos a sério. Ao usar essa variável, você pode estimar o número aproximado de concorrentes que também querem estar nas primeiras posições para essa palavra.
Operador Inurl:
Uso: inurl:frase
Exemplo: inurl: cálculo de custo de otimização de mecanismo de pesquisa
Descrição: Este comando mostra sites ou páginas que possuem a palavra-chave original em seu URL. Observe que não deve haver um espaço após os dois pontos.
Operador de âncora:
Uso:âncora:frase
Exemplo: inanchor:seo books
Descrição: O uso desse operador ajudará você a ver as páginas vinculadas à palavra-chave que está sendo usada. Este é um comando muito importante, mas infelizmente os mecanismos de busca relutam em compartilhar essas informações com os SEOs por motivos óbvios. Existem serviços, Linkscape e Majestic SEO, que estão dispostos a fornecer essas informações por uma taxa, mas fique tranquilo, as informações valem a pena.
Além disso, vale lembrar que agora o Google está prestando cada vez mais atenção na “confiança” do site e cada vez menos massa de links. Claro, os links ainda são um dos fatores mais importantes, mas a “confiança” está desempenhando um papel cada vez mais importante.
Uma combinação de duas variáveis dá bons resultados, por exemplo, intitle:inanchor promotion:website promotion. E o que vemos, o mecanismo de pesquisa nos mostrará os principais concorrentes, cujo título da página contém a palavra “promoção” e links de entrada com a âncora “promoção do site”.
Infelizmente, essa combinação não permite descobrir a "confiança" do domínio, que, como já dissemos, é muito um fator importante. Por exemplo, muitos sites corporativos mais antigos não têm tantos links quanto seus concorrentes mais jovens, mas eles têm muitos links antigos que colocam esses sites no topo dos resultados de pesquisa.
Operador do site:
Uso: site: endereço do site
Exemplo: site: www.aweb.com.ua
Descrição: Com este comando, você pode ver uma lista de páginas que são indexadas pelo mecanismo de pesquisa e que ele conhece. É usado principalmente para conhecer as páginas dos concorrentes e analisá-las.
instrução de cache:
Uso: cache: endereço da página
Exemplo: cache:www.aweb.com.ua
Descrição: Este comando mostra um “instantâneo” da página desde a última vez que o robô visitou o site e, em geral, como ele vê o conteúdo da página. Ao verificar a data do cache da página, você pode determinar com que frequência os robôs visitam o site. Quanto mais autoritário o site, mais frequentemente os robôs o visitam e, consequentemente, quanto menos autoritário (de acordo com o Google) o site, menos frequentemente os robôs tiram fotos da página.
O cache é muito importante na hora de comprar links. Quanto mais próxima a data de cache da página estiver da data de compra do link, mais rápido seu link será indexado pelo mecanismo de pesquisa do Google. Às vezes, descobrimos páginas com uma idade de cache de 3 meses. Ao comprar um link em tal site, você apenas desperdiçará seu dinheiro, pois é bem possível que o link nunca seja indexado.
Operador de links:
Uso: link: URL
Exemplo: link: www.aweb.com.ua
Descrição: operador de link: procura e mostra as páginas que ligam ao URL. Pode ser tanto a página principal do site quanto a interna.
Operador relacionado:
Uso: relacionado: URL
Exemplo: Relacionado: www.aweb.com.ua
Descrição: A instrução related: exibe páginas que o mecanismo de pesquisa considera semelhantes à página especificada. Para um humano, todas as páginas resultantes podem não ter nada semelhante, mas para um mecanismo de pesquisa, elas têm.
Operador de informações:
Uso: info:url
Exemplo: Informações: www.aweb.com.ua
Descrição: Ao utilizar este operador, poderemos obter informações sobre a página que é conhecida pelo motor de busca. Pode ser o autor, a data de publicação e muito mais. Além disso, na página de pesquisa, o Google oferece várias ações de uma só vez que pode fazer com esta página. Ou, mais simplesmente, sugerirá o uso de alguns dos operadores que descrevemos acima.
Operador Allintitle:
Uso: allintitle:frase
Exemplo: allintitle:awebpromoção
Descrição: Se começarmos consulta de pesquisa desta palavra, obteremos uma lista de páginas cujo título contém a frase inteira. Por exemplo, se tentarmos pesquisar a palavra allintitle:aweb promotion, obteremos uma lista de páginas que possuem essas duas palavras em seus títulos. E não é necessário que eles sejam um após o outro, eles podem estar localizados em locais diferentes no cabeçalho.
Operador Allintext:
Uso: allintext: palavra
Exemplo: allintext:otimização
Descrição: Este operador pesquisa todas as páginas que contêm a palavra especificada no corpo do texto. Se tentarmos usar a otimização allintext:aweb, veremos uma lista de páginas no texto em que essas palavras ocorrem. Ou seja, nem toda a frase é “otimização aweb”, mas ambas as palavras são “otimização” e “aweb”.
Como pesquisar usando google.com
Todo mundo provavelmente sabe como usar um mecanismo de busca como o Google =) Mas nem todo mundo sabe que se você compor corretamente uma consulta de pesquisa usando estruturas especiais, poderá obter os resultados do que procura com muito mais eficiência e rapidez =) Neste artigo Vou tentar mostrar isso e como você precisa fazer para pesquisar corretamente
O Google oferece suporte a vários operadores de pesquisa avançada que têm um significado especial ao pesquisar em google.com. Normalmente, esses operadores alteram a pesquisa ou até mesmo dizem ao Google para fazer tudo. tipos diferentes procurar. Por exemplo, a construção link:é um operador especial, e a consulta link:www.google.com não fará uma pesquisa normal, mas encontrará todas as páginas da web que tenham links para google.com.
tipos de solicitação alternativos
cache: Se você incluir outras palavras na consulta, o Google destacará essas palavras incluídas no documento armazenado em cache.
Por exemplo, cache: www.website mostrará o conteúdo em cache com a palavra "web" destacada.
link: a consulta de pesquisa acima mostrará as páginas da Web que contêm links para a consulta especificada.
Por exemplo: link: www.site exibirá todas as páginas que possuem um link para http://www.site
relacionado: Exibe páginas da Web que estão "relacionadas" à página da Web especificada.
Por exemplo, Relacionado: www.google.com listará as páginas da web semelhantes à página inicial do Google.
informações: Solicitar informações: fornecerá algumas informações que o Google possui sobre a página da Web solicitada.
Por exemplo, informações: site irá mostrar informações sobre o nosso fórum =) (Armada - Fórum de webmasters adultos).
De outros pedidos de informação
definir: A consulta define: fornecerá uma definição das palavras que você digitar depois disso, compiladas de várias fontes online. A definição será para a frase inteira inserida (ou seja, incluirá todas as palavras na consulta exata).
ações: Se você iniciar uma consulta com ações: o Google tratará o restante dos termos da consulta como símbolos de cotações de ações e criará um link para uma página que mostra as informações preparadas para esses símbolos.
Por exemplo, ações: intel yahoo mostrará informações sobre a Intel e o Yahoo. (Observe que você deve imprimir caracteres de notícias de última hora, não o nome da empresa)
Modificadores de solicitação
site: Se você incluir site: em sua consulta, o Google limitará os resultados aos sites encontrados nesse domínio.
Você também pode pesquisar por zonas individuais, como ru, org, com, etc ( site:com site:ru)
allintitle: Se você executar uma consulta com allintitle:, o Google limitará os resultados com todas as palavras de consulta no título.
Por exemplo, allintitle: pesquisa do Google
retornará todas as páginas de pesquisa do Google, como imagens, Blog, etc.
título: Se você incluir intitle: em sua consulta, o Google restringirá os resultados a documentos que contenham essa palavra no título.
Por exemplo, título: Negócios
allinurl: Se você executar uma consulta com allinurl: o Google limitará os resultados com todas as palavras de consulta na URL.
Por exemplo, allinurl: pesquisa no google retornará documentos com google e pesquisará no título. Além disso, como opção, você pode separar as palavras com uma barra (/) e as palavras em ambos os lados da barra serão pesquisadas na mesma página: Exemplo allinurl: foo/bar
inurl: Se você incluir inurl: em sua consulta, o Google limitará os resultados a documentos que contenham essa palavra no URL.
Por exemplo, Animação inurl:site
em texto: pesquisa apenas no texto da página a palavra especificada, ignorando o título e os textos dos links, e outras coisas não relacionadas. Há também um derivado deste modificador - allintext: Essa. além disso, todas as palavras na consulta serão pesquisadas apenas no texto, o que também é importante, ignorando as palavras usadas com frequência nos links
Por exemplo, intext: fórum
intervalo de datas: pesquisas em intervalos de tempo (daterange:2452389-2452389), as datas de hora são especificadas no formato juliano.
Bem, e todos os tipos de exemplos interessantes de solicitações
Exemplos de compilação de consultas para o Google. Para spammers
inurl:control.guest?a=sign
Site:books.dreambook.com “URL da página inicial” “Assine meu” inurl:sign
Site: www.freegb.net Página inicial
Inurl:sign.asp "Contagem de caracteres"
"Mensagem:" inurl:sign.cfm "Remetente:"
inurl:register.php “Registro de Usuário” “Site”
Inurl:edu/guestbook “Assine o livro de visitas”
Inurl:post "Postar comentário" "URL"
Inurl:/archives/ “Comentários:” “Lembrar das informações?”
“Script e livro de visitas criado por:” “URL:” “Comentários:”
inurl:?action=add “phpBook” “URL”
Intitle: "Enviar nova história"
Revistas
inurl:www.livejournal.com/users/mode=reply
inurl greatestjournal.com/mode=reply
Inurl:fastbb.ru/re.pl?
inurl:fastbb.ru /re.pl? "Livro de visitas"
Blogues
Inurl:blogger.com/comment.g?”postID”"anonymous"
Inurl:typepad.com/ “Postar um comentário” “Lembrar informações pessoais?”
Inurl:greatestjournal.com/community/ “Postar comentário” “endereços de pôsteres anônimos”
“Comentário de postagem” “endereços de pôsteres anônimos” -
Intitle:"Postar comentário"
Inurl:pirillo.com “Postar comentário”
Fóruns
Inurl:gate.html?”name=Forums” “mode=reply”
inurl:”forum/posting.php?mode=reply”
inurl:”mes.php?”
inurl:”membros.html”
inurl:forum/memberlist.php?”
Hackeando com o Google
Alexandre Antipov
motor de busca Sistema Google(www.google.com) oferece muitas opções de pesquisa. Todos esses recursos são uma ferramenta de pesquisa inestimável para um usuário de Internet pela primeira vez e, ao mesmo tempo, uma arma ainda mais poderosa de invasão e destruição nas mãos de pessoas com más intenções, incluindo não apenas hackers, mas também criminosos não informáticos e até terroristas.
(9475 visualizações em 1 semana)
Denis Batrankov
denisNOSPAMixi.ru
Atenção:Este artigo não é um guia para ação. Este artigo foi escrito para vocês, administradores de servidores WEB, para que percam a falsa sensação de que estão seguros, e finalmente entenderão a insidosidade desse método de obtenção de informações e começarão a proteger seu site.
Introdução
Por exemplo, encontrei 1670 páginas em 0,14 segundos!
2. Vamos inserir outra linha, por exemplo:
inurl:"auth_user_file.txt"um pouco menos, mas isso já é suficiente para download gratuito e para adivinhar senhas (usando o mesmo John The Ripper). Abaixo vou dar mais alguns exemplos.
Portanto, você precisa perceber que o mecanismo de pesquisa do Google visitou a maioria dos sites da Internet e armazenou em cache as informações contidas neles. Essas informações armazenadas em cache permitem que você obtenha informações sobre o site e o conteúdo do site sem uma conexão direta com o site, apenas pesquisando as informações armazenadas internamente pelo Google. Além disso, se as informações no site não estiverem mais disponíveis, as informações no cache ainda poderão ser preservadas. Tudo o que é necessário para este método é conhecer algumas Palavras do Google. Essa técnica é chamada de Google Hacking.
Pela primeira vez, informações sobre o Google Hacking apareceram na lista de discussão Bugtruck 3 anos atrás. Em 2001, este tema foi levantado por um estudante francês. Aqui está um link para esta carta http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html . Ele dá os primeiros exemplos de tais solicitações:
1) Índice de /admin
2) Índice de /senha
3) Índice de /mail
4) Índice de / +banques +filetype:xls (para frança...)
5) Índice de / +passwd
6) Índice de/senha.txt
Este tópico fez muito barulho na parte de leitura em inglês da Internet recentemente: depois de um artigo de Johnny Long publicado em 7 de maio de 2004. Para um estudo mais completo sobre o Google Hacking, aconselho que acesse o site deste autor http://johnny.ihackstuff.com. Neste artigo, quero apenas atualizar você.
Quem pode usar:
- Jornalistas, espiões e todas aquelas pessoas que gostam de meter o nariz nos negócios de outras pessoas podem usar isso para procurar evidências comprometedoras.
- Hackers procurando alvos adequados para hackear.
Como o Google funciona.
Para continuar a conversa, deixe-me lembrá-lo de algumas das palavras-chave usadas nas consultas do Google.
Pesquise usando o sinal +
O Google exclui palavras sem importância, em sua opinião, da pesquisa. Por exemplo, palavras interrogativas, preposições e artigos em inglês: por exemplo são, de, onde. Em russo idioma do Google parece considerar todas as palavras importantes. Se a palavra for excluída da pesquisa, o Google escreverá sobre ela. Para que o Google comece a pesquisar páginas com essas palavras, você precisa adicionar um sinal de + antes delas sem espaço antes da palavra. Por exemplo:
ás + de base
Pesquisar por sinal -
Se o Google encontrar um grande número de páginas das quais é necessário excluir páginas com determinados tópicos, você poderá forçar o Google a pesquisar apenas páginas que não contenham determinadas palavras. Para fazer isso, você precisa indicar essas palavras colocando um sinal na frente de cada uma - sem espaço antes da palavra. Por exemplo:
pesca - vodka
Pesquise com o sinal ~
Você pode procurar não apenas a palavra especificada, mas também seus sinônimos. Para fazer isso, preceda a palavra com o símbolo ~.
Encontrar uma frase exata usando aspas duplas
O Google pesquisa em cada página todas as ocorrências das palavras que você escreveu na string de consulta e não se importa com a posição relativa das palavras, o principal é que todas as palavras especificadas estejam na página ao mesmo tempo ( Esta é a ação padrão). Para encontrar a frase exata, você precisa colocá-la entre aspas. Por exemplo:
"livro"
Para ter pelo menos uma das palavras especificadas, você deve especificar a operação lógica explicitamente: OR. Por exemplo:
livro de segurança OU proteção
Além disso, você pode usar o sinal * na string de pesquisa para denotar qualquer palavra e. para representar qualquer personagem.
Encontrar palavras com operadores adicionais
Existe operadores de pesquisa, que são especificados na string de pesquisa no formato:
operador: search_term
Os espaços ao lado dos dois pontos não são necessários. Se você inserir um espaço após dois pontos, verá uma mensagem de erro e, antes dela, o Google os usará como uma string de pesquisa normal.
Existem grupos de operadores de pesquisa adicionais: idiomas - indique em qual idioma você deseja ver o resultado, data - limite os resultados nos últimos três, seis ou 12 meses, ocorrências - indique onde no documento você precisa procurar a string: em todos os lugares, no título, na URL, domínios - pesquise o site especificado ou vice-versa exclua-o da pesquisa, pesquisa segura - bloqueie sites que contenham o tipo especificado de informações e remova-os das páginas de resultados da pesquisa.
No entanto, alguns operadores não precisam de um parâmetro adicional, por exemplo, a consulta " cache:www.google.com"pode ser chamado como seqüência completa para pesquisar, e algumas palavras-chave, pelo contrário, exigem a presença de uma palavra de pesquisa, por exemplo " site:www.google.com ajuda". À luz do nosso tópico, vejamos os seguintes operadores:
Operador |
Descrição |
Requer parâmetro adicional? |
pesquise apenas o site especificado em search_term |
||
pesquisar apenas em documentos com o tipo search_term |
||
encontrar páginas contendo search_term no título |
||
encontre páginas contendo todas as palavras search_term no título |
||
encontre páginas que contenham a palavra search_term em seu endereço |
||
encontre páginas que contenham todas as palavras search_term em seu endereço |
Operador site: limita a pesquisa apenas ao site especificado, e você pode especificar não apenas Nome do domínio mas também o endereço IP. Por exemplo, digite:
Operador tipo de arquivo: restringe as pesquisas a arquivos de um determinado tipo. Por exemplo:
Na data deste artigo, o Google pode pesquisar em 13 formatos de arquivo diferentes:
- Formato de documento portátil da Adobe (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (sem 1, sem 2, sem 3, sem 4, sem 5, sem, sem, sem)
- Lotus Word Pro (lwp)
- MacWrite(mw)
- Microsoft Excel (xl)
- Microsoft PowerPoint(pp)
- Microsoft Word(doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (escrever)
- Formato Rich Text (rtf)
- Flash de Onda de Choque (swf)
- Texto (ans, txt)
Operador link: mostra todas as páginas que apontam para a página especificada.
Deve ser sempre interessante ver quantos lugares na Internet sabem sobre você. Nós tentamos:
Operador cache: mostra a versão em cache do site do Google, como estava quando o Google visitou a página pela última vez. Pegamos qualquer site que muda com frequência e olhamos:
Operador título: procura a palavra especificada no título da página. Operador allintitle:é uma extensão - procura todas as poucas palavras especificadas no título da página. Comparar:
intitle:voo para marte
intitle:flight intitle:on intitle:mars
allintitle:voo para marte
Operador inurl: faz com que o Google mostre todas as páginas que contêm a string especificada no URL. allinurl: procura todas as palavras em um URL. Por exemplo:
allinurl:acid_stat_alerts.php
Este comando é especialmente útil para aqueles que não possuem o SNORT - pelo menos podem ver como ele funciona em um sistema real.
Métodos de hackers do Google
Assim, descobrimos que, usando uma combinação dos operadores e palavras-chave acima, qualquer pessoa pode coletar as informações necessárias e pesquisar vulnerabilidades. Essas técnicas são frequentemente chamadas de Google Hacking.
mapa do site
Você pode usar o site: declaração para ver todos os links que o Google encontrou no site. Normalmente, as páginas que são criadas dinamicamente por scripts não são indexadas usando parâmetros, então alguns sites usam filtros ISAPI para que os links não fiquem no formulário /article.asp?num=10&dst=5, mas com barras /artigo/abc/num/10/dst/5. Isso é feito para garantir que o site seja geralmente indexado pelos mecanismos de pesquisa.
Vamos tentar:
site: www.whitehouse.gov whitehouse
O Google acha que cada página de um site contém a palavra whitehouse. Isso é o que usamos para obter todas as páginas.
Há também uma versão simplificada:
site: whitehouse.gov
E a melhor parte é que os camaradas do whitehouse.gov nem sabiam que analisamos a estrutura do site e até as páginas em cache que o Google baixou para si. Isso pode ser usado para estudar a estrutura dos sites e visualizar o conteúdo sem ser notado por enquanto.
Listando arquivos em diretórios
Servidores WEB podem mostrar listas de diretórios de servidores em vez do usual páginas HTML. Isso geralmente é feito para forçar os usuários a selecionar e baixar arquivos específicos. No entanto, em muitos casos, os administradores não têm intenção de mostrar o conteúdo de um diretório. Isso ocorre devido à configuração incorreta do servidor ou falta de pagina inicial no diretório. Como resultado, o hacker tem a chance de encontrar algo interessante no diretório e usá-lo para seus próprios propósitos. Para encontrar todas essas páginas, basta notar que todas elas contêm as palavras: index of em seu título. Mas como o índice de palavras não contém apenas essas páginas, precisamos refinar a consulta e levar em consideração as palavras-chave na própria página, portanto, consultas como:
intitle:index.of diretório pai
intitle:index.of name size
Como a maioria das listagens de diretórios são intencionais, você pode ter dificuldade em encontrar listagens perdidas na primeira vez. Mas pelo menos você poderá usar as listagens para determinar a versão do servidor WEB, conforme descrito abaixo.
Obtendo a versão do servidor WEB.
Saber a versão do servidor WEB é sempre útil antes de iniciar qualquer ataque hacker. Novamente, graças ao Google, é possível obter essas informações sem se conectar a um servidor. Se você observar atentamente a lista de diretórios, poderá ver que o nome do servidor WEB e sua versão são exibidos lá.
Apache1.3.29 - Servidor ProXad em trf296.free.fr Porta 80
Um administrador experiente pode alterar essas informações, mas, via de regra, é verdade. Assim, para obter esta informação, basta enviar um pedido:
intitle:index.of server.at
Para obter informações de um servidor específico, refinamos a solicitação:
intitle:index.of server.at site:ibm.com
Ou vice-versa, estamos procurando servidores rodando em uma versão específica do servidor:
intitle:index.of Apache/2.0.40 Server em
Esta técnica pode ser usada por um hacker para encontrar uma vítima. Se, por exemplo, ele tiver um exploit para uma determinada versão do servidor WEB, ele poderá encontrá-lo e tentar o exploit existente.
Você também pode obter a versão do servidor observando as páginas que são instaladas por padrão ao instalar uma nova versão do servidor WEB. Por exemplo, para ver a página de teste do Apache 1.2.6, basta digitar
intitle:Test.Page.for.Apache.funcionou!
Além disso, alguns sistemas operacionais instalam e iniciam imediatamente o servidor WEB durante a instalação. No entanto, alguns usuários nem estão cientes disso. Naturalmente, se você perceber que alguém não excluiu a página padrão, é lógico supor que o computador não foi submetido a nenhuma configuração e provavelmente está vulnerável a ataques.
Tente procurar por páginas do IIS 5.0
allintitle:Bem-vindo aos Serviços de Internet do Windows 2000
No caso do IIS, você pode determinar não apenas a versão do servidor, mas também a versão do Windows e do Service Pack.
Outra forma de determinar a versão do servidor WEB é procurar manuais (páginas de ajuda) e exemplos que podem ser instalados no site por padrão. Os hackers encontraram algumas maneiras de usar esses componentes para obter acesso privilegiado ao site. É por isso que você precisa remover esses componentes no local de produção. Sem contar o fato de que pela presença desses componentes você pode obter informações sobre o tipo de servidor e sua versão. Por exemplo, vamos encontrar o manual do apache:
inurl:módulos manuais de diretivas do apache
Usando o Google como um scanner CGI.
O scanner CGI ou o scanner WEB é um utilitário para procurar scripts e programas vulneráveis no servidor da vítima. Esses utilitários precisam saber o que procurar, para isso eles possuem uma lista completa de arquivos vulneráveis, por exemplo:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Podemos encontrar cada um desses arquivos usando o Google, adicionalmente usando as palavras index of ou inurl com o nome do arquivo na barra de pesquisa: podemos encontrar sites com scripts vulneráveis, por exemplo:
allinurl:/random_banner/index.cgi
Com conhecimento adicional, um hacker pode explorar uma vulnerabilidade de script e usar a vulnerabilidade para forçar o script a servir qualquer arquivo armazenado no servidor. Por exemplo, um arquivo de senha.
Como se proteger de ser hackeado pelo Google.
1. Não carregue dados importantes no servidor WEB.
Mesmo se você postou os dados temporariamente, pode esquecê-los ou alguém terá tempo para encontrar e pegar esses dados antes de apagá-los. Não faça isso. Existem muitas outras maneiras de transferir dados que os protegem contra roubo.
2. Verifique seu site.
Use os métodos descritos para pesquisar seu site. Verifique seu site periodicamente para novos métodos que aparecem no site http://johnny.ihackstuff.com. Lembre-se de que, se você deseja automatizar suas ações, precisa obter uma permissão especial do Google. Se você ler com atenção http://www.google.com/terms_of_service.html, então você verá a frase: Você não pode enviar consultas automatizadas de qualquer tipo para o sistema do Google sem permissão prévia expressa do Google.
3. Você pode não precisar que o Google indexe seu site ou parte dele.
O Google permite que você remova um link para seu site ou parte dele de seu banco de dados, bem como remova páginas do cache. Além disso, você pode proibir a pesquisa de imagens em seu site, proibir a exibição de pequenos fragmentos de páginas nos resultados da pesquisa. Todas as opções para excluir um site estão descritas na página http://www.google.com/remove.html. Para isso, você deve confirmar que é realmente o proprietário deste site ou inserir tags na página ou
4. Use robots.txt
Sabe-se que os motores de busca procuram o arquivo robots.txt na raiz do site e não indexam as partes marcadas com a palavra Não permitir. Você pode usar isso para impedir que parte do site seja indexada. Por exemplo, para evitar a indexação de todo o site, crie um arquivo robots.txt contendo duas linhas:
Agente de usuário: *
não permitir: /
O que mais acontece
Para que a vida não pareça mel para você, vou dizer no final que existem sites que seguem aquelas pessoas que, usando os métodos acima, procuram brechas em scripts e servidores WEB. Um exemplo dessa página é
Apêndice.
Um pouco doce. Tente um dos seguintes para você:
1. #mysql dump filetype:sql - procura por dumps do banco de dados mySQL
2. Relatório de Resumo de Vulnerabilidade do Host - mostrará quais vulnerabilidades outras pessoas encontraram
3. phpMyAdmin rodando em inurl:main.php - isso forçará o fechamento do controle via painel phpmyadmin
4. Não para distribuição confidencial
5. Detalhes da Solicitação de Variáveis do Servidor da Árvore de Controle
6. Executando no modo filho
7. Este relatório foi gerado pelo WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs - talvez alguém precise de arquivos de configuração de firewall? :)
10. intitle:index.of finance.xls - hmm....
11. intitle: Índice de bate-papos dbconvert.exe - logs de bate-papo icq
12. intext:Análise de tráfego de Tobias Oetiker
13. intitle:Estatísticas de uso geradas pelo Webalizer
14. intitle:estatísticas de estatísticas avançadas da web
15. intitle:index.of ws_ftp.ini - ws ftp config
16. inurl:ipsec.secrets contém segredos compartilhados - chave secreta - boa descoberta
17. inurl:main.php Bem-vindo ao phpMyAdmin
18. inurl:server-info Informações do servidor Apache
19. site: notas de administração edu
20. ORA-00921: fim inesperado do comando SQL - obter caminhos
21. intitle:index.of trillian.ini
22. intitle: Índice de pwd.db
23. intitle:index.of people.lst
24. intitle:index.of master.passwd
25.inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.of administrators.pwd
29. intitle:Index.of etc shadow
30. intitle:index.of secring.pgp
31. inurl:config.php dbuname dbpass
32. inurl:executar tipo de arquivo:ini
Centro de treinamento "Informzaschita" http://www.itsecurity.ru - um centro especializado líder no campo da educação segurança da informação(Licença do Comitê de Educação de Moscou nº 015470, Credenciamento Estadual nº 004251). O único centro de treinamento autorizado de empresas segurança da Internet Systems e Clearswift na Rússia e países da CEI. Centro de treinamento autorizado da Microsoft (especialização em segurança). Os programas de treinamento são coordenados com a Comissão Técnica Estadual da Rússia, FSB (FAPSI). Certificados de treinamento e documentos estaduais sobre treinamento avançado.
SoftKey é um serviço exclusivo para compradores, desenvolvedores, revendedores e parceiros afiliados. Além disso, esta é uma das melhores lojas de software on-line da Rússia, Ucrânia, Cazaquistão, que oferece aos clientes uma ampla variedade, muitos métodos de pagamento, processamento rápido (geralmente instantâneo), rastreamento do processo de atendimento do pedido na seção pessoal, vários descontos da loja e fabricantes ON.
Caros amigos, hoje vou partilhar convosco um dos meus mais recentes desenvolvimentos na promoção do website. Vou lhe dizer como remover a data de publicação das SERPs e quais vantagens isso oferece.
Como você sabe, nos resultados da emissão de muitas páginas de sites, a data de sua publicação é exibida. As datas permitem que os usuários naveguem pelos resultados da pesquisa e selecionem páginas com informações mais atualizadas e atualizadas.
Na maioria dos casos, eu mesmo prefiro ir a páginas que foram publicadas há pouco tempo e visito materiais de 3 a 5 anos ou mais com muito menos frequência, pois as informações em muitos tópicos geralmente ficam desatualizadas e perdem sua relevância.
Você acha que este artigo receberá Plug-ins do Firefox o número máximo de cliques de uma pesquisa se for datada de 2008?

Ou meu post sobre Plug-ins do WordPress de 2007:

Acho que não, pois as informações desses tópicos ficam desatualizadas com o passar dos anos.
Pensei em como posso usar esse momento para aumentar o tráfego para os sites que promovo. Existem muitos tópicos "evergreen" em que as informações praticamente não ficam desatualizadas, e os materiais publicados há vários anos também serão úteis e interessantes para os visitantes.
Por exemplo, tome o tópico do treinamento do cão. Lá, os princípios básicos não mudaram por muitos anos. Ao mesmo tempo, o proprietário de um site assim ficará triste 😉 quando, em alguns anos, menos visitantes dos resultados da pesquisa forem para seus artigos, pois eles verão a data de publicação e escolherão artigos mais recentes em outros sites simplesmente porque eles são mais recentes, embora possam não ser tão interessantes ou úteis.
Mas se considerarmos tópicos como smartphones, gadgets, moda, roupas femininas, as informações neles ficam desatualizadas muito rapidamente e perdem sua relevância. Não faz sentido remover a data dos resultados da pesquisa.
🔥 Por falar nisso! Estou realizando um curso pago sobre promoção de sites Shaolin SEO em inglês. Se estiver interessado, você pode aplicar em seu site seoshaolin.com.Desejo-lhe alto tráfego em seus sites!
Sobremesa para hoje - um vídeo fascinante sobre como um menino anda de bicicleta 😉 . É melhor que os fracos de coração e as pessoas impressionáveis não assistam 🙂:










 Baixe o aplicativo pokemon go no ios")

















 Quantos núcleos estão no meu computador com Windows 10")




