No coração de lógica difusa encontra-se a teoria dos conjuntos difusos, apresentada em uma série de trabalhos de L. Zade em 1965-1973. Os conjuntos difusos e a lógica difusa são generalizações da teoria dos conjuntos clássica e da lógica formal clássica. A principal razão para o surgimento de uma nova teoria foi a presença de raciocínio difuso e aproximado quando uma pessoa descreve processos, sistemas, objetos.
L. Zadeh, formulando esta propriedade principal dos conjuntos difusos, foi baseado nas obras de seus predecessores. No início da década de 1920, o matemático polonês Lukashevich trabalhou nos princípios da lógica matemática multivalorada, na qual os valores dos predicados podiam ser mais do que apenas “verdadeiros” ou “falsos”. Em 1937, outro cientista americano M. Black aplicou pela primeira vez a lógica de múltiplos valores de Lukashevich a listas como conjuntos de objetos e chamou esses conjuntos de indefinidos.
A lógica difusa como uma direção científica não foi fácil de desenvolver e não escapou às acusações de pseudociência. Mesmo em 1989, quando havia dezenas de exemplos de aplicação bem-sucedida da lógica difusa na defesa, indústria e negócios, a Sociedade Científica Nacional dos Estados Unidos discutiu a questão de excluir materiais em conjuntos difusos dos livros didáticos do instituto.
O primeiro período de desenvolvimento de sistemas fuzzy (final dos anos 60 - início dos anos 70) é caracterizado pelo desenvolvimento do aparato teórico dos conjuntos fuzzy. Em 1970, Bellman e Zadeh desenvolveram a teoria da tomada de decisão em condições difusas.
Nos anos 70-80 (segundo período), os primeiros resultados práticos surgiram no campo do controle difuso de sistemas técnicos complexos (um gerador de vapor com controle difuso). I. Mamdani em 1975 projetou o primeiro controlador operando com base na álgebra de Zade para controlar uma turbina a vapor. Ao mesmo tempo, passou-se a dar atenção à criação de sistemas especialistas baseados em lógica fuzzy, o desenvolvimento de controladores fuzzy. Os sistemas especialistas difusos para apoio à decisão encontraram ampla aplicação na medicina e na economia.
Finalmente, no terceiro período, que vai do final dos anos 80 e continua na atualidade, surgem pacotes de software para construção de sistemas especialistas fuzzy, e os campos de aplicação da lógica fuzzy se expandem significativamente. É usado nas indústrias automotiva, aeroespacial e de transporte, eletrodomésticos, finanças, análise e tomada de decisões de gestão e muitos outros. Além disso, a prova do famoso FAT (Fuzzy Approximation Theorem) de B. Cosco, que afirmava que qualquer sistema matemático pode ser aproximado por um sistema baseado em lógica fuzzy, teve um papel significativo no desenvolvimento da lógica fuzzy.
Os sistemas de informação baseados em conjuntos fuzzy e lógica fuzzy são chamados sistemas difusos.
Dignidade sistemas difusos:
· Funcionando em condições de incerteza;
· Operar com dados qualitativos e quantitativos;
· Uso de conhecimento especializado em gestão;
· Construção de modelos de raciocínio aproximado de uma pessoa;
· Estabilidade em todos os distúrbios possíveis agindo no sistema.
Desvantagens sistemas difusos são:
· Falta de uma metodologia padrão para projetar sistemas fuzzy;
· Impossibilidade de análise matemática de sistemas fuzzy pelos métodos existentes;
· O uso de uma abordagem fuzzy em comparação com a abordagem probabilística não leva a um aumento na precisão dos cálculos.
A teoria dos conjuntos difusos. A principal diferença entre a teoria dos conjuntos fuzzy e a teoria clássica dos conjuntos nítidos é que se para conjuntos nítidos o resultado do cálculo da função característica pode ser apenas dois valores - 0 ou 1, então para conjuntos fuzzy este número é infinito, mas limitado pelo intervalo de zero a um.
Conjunto difuso. Seja U o chamado conjunto universal, a partir dos elementos dos quais todos os outros conjuntos considerados na classe de problemas dada são formados, por exemplo, o conjunto de todos os inteiros, o conjunto de todas as funções suaves, etc. A função característica de um conjunto é uma função cujos valores indicam se é um elemento do conjunto A:

Na teoria dos conjuntos fuzzy, a função característica é chamada de função de pertinência, e seu valor é o grau de pertinência de um elemento x em um conjunto fuzzy A.
Mais estritamente: um conjunto difuso A é uma coleção de pares
![]()
onde está a função de adesão, isto é ![]()
Seja, por exemplo, U = (a, b, c, d, e) ,. Então o elemento a não pertence ao conjunto A, o elemento b pertence a ele em pequena extensão, o elemento c pertence mais ou menos, o elemento d pertence em grande parte, e é um elemento do conjunto A.
Exemplo. Seja o universo U o conjunto de números reais. Um conjunto fuzzy A, denotando um conjunto de números próximos a 10, pode ser especificado pela seguinte função de pertinência (Fig.21.1):
![]() ,
,





Exemplo "Chá quente" X = 0 CC; C = 0/0; 0/10; 0/20; 0,15 / 30; 0,30 / 40; 0,60 / 50; 0,80 / 60; 0, 90/70; 1/80; 1/90; 1/100.

Interseção de dois conjuntos fuzzy (fuzzy "AND"): MF AB (x) = min (MF A (x), MF B (x)). A união de dois conjuntos fuzzy (fuzzy "OR"): MF AB (x) = max (MF A (x), MF B (x)).

De acordo com Lotfi Zadeh, uma variável linguística é uma variável cujos valores são palavras ou frases de uma linguagem natural ou artificial. Os valores de uma variável linguística podem ser variáveis fuzzy, ou seja, a variável linguística está em um nível mais alto do que a variável fuzzy.

Cada variável linguística consiste em: nome; o conjunto de seus valores, também chamado de conjunto de termos base T. Os elementos do conjunto de termos base são nomes de variáveis fuzzy; conjunto universal X; regra sintática G, segundo a qual novos termos são gerados usando palavras de uma linguagem natural ou formal; regra semântica P, que atribui a cada valor de uma variável linguística um subconjunto difuso do conjunto X.





Descrição da variável linguística "Preço das ações" X = Conjunto de termos básicos: "Baixo", "Moderado", "Alto"

Descrição da variável linguística "Idade"




Lógica fuzzy de computação suave, redes neurais artificiais, raciocínio probabilístico, algoritmos evolutivos













Construindo a rede (após a escolha das variáveis de entrada) Selecione a configuração inicial da rede Realize uma série de experimentos com diferentes configurações, lembrando a melhor rede (no sentido de um erro de checkout). Vários experimentos devem ser realizados para cada configuração. Se for observado underfitting no próximo experimento (a rede não produz um resultado de qualidade aceitável), tente adicionar neurônios adicionais à (s) camada (s) intermediária (s). Se isso não funcionar, tente adicionar uma nova camada intermediária. Se ocorrer overfitting (o erro de controle começou a aumentar), tente remover vários elementos ocultos (e possivelmente camadas).

Problemas de mineração de dados resolvidos usando classificação de redes neurais (aprendizagem supervisionada) Clustering de predição (aprendizagem não supervisionada) reconhecimento de texto, reconhecimento de fala, identificação de personalidade encontram a melhor aproximação de uma função dada por um conjunto finito de valores de entrada (exemplos de treinamento, o problema de compressão de informações, reduzindo a dimensão dos dados

A tarefa "Se deve conceder um empréstimo a um cliente" no pacote analítico Deductor (BaseGroup) Conjunto de treinamento - um banco de dados contendo informações sobre os clientes: - Montante do empréstimo, - Prazo do empréstimo, - Finalidade do empréstimo, - Idade, - Sexo, - Educação , - Propriedade privada, - Apartamento, - Área do apartamento. É necessário construir um modelo que seja capaz de dar uma resposta se o Cliente, que deseja obter um empréstimo, se encontra no grupo de risco de inadimplência do empréstimo, ou seja, o usuário deve receber uma resposta à pergunta "Devo fazer um empréstimo?" A tarefa pertence ao grupo de tarefas de classificação, ou seja, aprendendo com um professor.




Vamos considerar alguns dos métodos de computação "soft" que ainda não são amplamente usados nos negócios. Os algoritmos e parâmetros desses métodos são muito menos determinísticos do que os tradicionais. O surgimento dos conceitos de computação "soft" foi causado por tentativas de modelagem simplificada de processos intelectuais e naturais, que são em grande parte aleatórios por natureza.
As redes neurais usam a compreensão moderna da estrutura e do funcionamento do cérebro. Acredita-se que o cérebro seja composto por elementos simples - neurônios, conectados por sinapses, por meio dos quais trocam sinais.
A principal vantagem das redes neurais é a capacidade de aprender pelo exemplo. Na maioria dos casos, o aprendizado é o processo de alterar os coeficientes de ponderação das sinapses de acordo com um algoritmo específico. Isso geralmente requer muitos exemplos e muitos ciclos de treinamento. Aqui você pode fazer uma analogia com os reflexos do cão de Pavlov, em que a salivação de plantão também não começou a aparecer imediatamente. Observamos apenas que os modelos mais complexos de redes neurais são muitas ordens de magnitude mais simples do que o cérebro do cão; e muitos mais ciclos de treinamento são necessários.
O uso de redes neurais se justifica quando é impossível construir um modelo matemático preciso do objeto ou fenômeno em estudo. Por exemplo, as vendas em dezembro costumam ser mais altas do que em novembro, mas não existe uma fórmula para calcular quanto será este ano; para prever o volume de vendas, você pode treinar uma rede neural usando exemplos de anos anteriores.
Entre as desvantagens das redes neurais estão: um longo tempo de treinamento, uma tendência para se ajustar aos dados de treinamento e uma diminuição nas habilidades de generalização com o aumento do tempo de treinamento. Além disso, é impossível explicar como a rede chega a esta ou aquela solução do problema, ou seja, as redes neurais são sistemas de caixa preta, pois as funções dos neurônios e os pesos das sinapses não têm uma interpretação real. No entanto, existem muitos algoritmos de rede neural em que essas e outras desvantagens são de alguma forma niveladas.
Na previsão, as redes neurais são usadas na maioria das vezes de acordo com o esquema mais simples: como dados de entrada, informações pré-processadas sobre os valores do parâmetro previsto para vários períodos anteriores são alimentadas na rede, na saída a rede emite uma previsão para o próximos períodos - como no exemplo acima com vendas. Existem também maneiras menos triviais de obter uma previsão; As redes neurais são uma ferramenta muito flexível, portanto, existem muitos modelos finitos das próprias redes e de seus aplicativos.
Outro método são os algoritmos genéticos. Eles são baseados em busca aleatória direcionada, ou seja, uma tentativa de simular processos evolutivos na natureza. Na versão básica, os algoritmos genéticos funcionam assim:
1. A solução do problema é apresentada na forma de um cromossomo.
2. Um conjunto aleatório de cromossomos é criado - esta é a geração inicial de soluções.
3. Eles são processados por operadores especiais de reprodução e mutação.
4. As soluções são avaliadas e selecionadas com base na função de adequação.
5. Uma nova geração de soluções é exibida e o ciclo se repete.
Como resultado, soluções mais perfeitas são encontradas a cada época de evolução.
Ao usar algoritmos genéticos, o analista não precisa de informações a priori sobre a natureza dos dados iniciais, sobre sua estrutura, etc. A analogia aqui é transparente - a cor dos olhos, o formato do nariz e a espessura do cabelo nas pernas são codificados em nossos genes pelos mesmos nucleotídeos.
Na previsão, os algoritmos genéticos raramente são usados diretamente, uma vez que é difícil chegar a um critério de avaliação de uma previsão, ou seja, um critério de seleção de decisões - no nascimento é impossível determinar quem uma pessoa se tornará - um astronauta ou um alconauta. Portanto, geralmente os algoritmos genéticos servem como um método auxiliar - por exemplo, ao treinar uma rede neural com funções de ativação não padronizadas, em que é impossível usar algoritmos de gradiente. Aqui, como exemplo, podemos citar redes MIP, que prevêem com sucesso fenômenos aparentemente aleatórios - o número de manchas no sol e a intensidade do laser.
Outro método é a lógica difusa que simula processos de pensamento. Ao contrário da lógica binária, que requer formulações precisas e inequívocas, o fuzzy oferece um nível diferente de pensamento. Por exemplo, formalizar a declaração “as vendas do mês passado foram baixas” dentro da lógica binária tradicional ou “booleana” requer uma distinção clara entre vendas “baixas” (0) e “altas” (1). Por exemplo, as vendas iguais ou superiores a 1 milhão de shekels são altas, menos as vendas são baixas.
Surge a pergunta: por que as vendas no nível de 999.999 shekels já são consideradas baixas? Obviamente, esta não é uma afirmação totalmente correta. A lógica difusa opera com conceitos mais suaves. Por exemplo, as vendas de NIS 900.000 seriam consideradas altas com uma classificação de 0,9 e baixas com uma classificação de 0,1.
Na lógica fuzzy, as tarefas são formuladas em termos de regras que consistem em conjuntos de condições e resultados. Exemplos das regras mais simples: "Se os clientes tivessem um prazo de empréstimo modesto, as vendas seriam razoáveis", "Se os clientes recebessem um desconto decente, as vendas seriam boas."
Depois de definir o problema em termos de regras, os valores claros das condições (prazo do empréstimo em dias e o valor do desconto em porcentagem) são convertidos em uma forma difusa (grande, pequeno, etc.). Em seguida, eles são processados usando operações lógicas e a transformação inversa em variáveis numéricas (o nível previsto de vendas em unidades de produção).
Comparados aos métodos probabilísticos, os difusos podem reduzir drasticamente a quantidade de cálculos realizados, mas geralmente não aumentam sua precisão. Dentre as desvantagens de tais sistemas, pode-se notar a ausência de uma metodologia de projeto padronizada, a impossibilidade de análises matemáticas pelos métodos tradicionais. Além disso, em sistemas fuzzy clássicos, um aumento no número de grandezas de entrada leva a um aumento exponencial no número de regras. Para superar essas e outras desvantagens, como no caso das redes neurais, existem muitas modificações nos sistemas lógicos difusos.
Dentro da estrutura dos métodos de computação suave, os chamados algoritmos híbridos podem ser distinguidos, os quais incluem vários componentes diferentes. Por exemplo, redes lógicas difusas, ou as já mencionadas redes neurais com aprendizado genético.
Em algoritmos híbridos, via de regra, existe um efeito sinérgico no qual as desvantagens de um método são compensadas pelas vantagens de outros, e o sistema final apresenta um resultado que não está disponível para nenhum dos componentes separadamente.
Título: Lógica difusa e redes neurais artificiais.Como você sabe, o aparato de conjuntos fuzzy e lógica fuzzy tem sido usado com sucesso por um longo tempo (mais de 10 anos) para resolver problemas nos quais os dados iniciais não são confiáveis e são mal formalizados. Os pontos fortes desta abordagem:
-descrição das condições e métodos de resolução do problema numa linguagem próxima do natural;
-universalidade: de acordo com o famoso FAT (Fuzzy Approximation Theorem), provado por B.Kosko em 1993, qualquer sistema matemático pode ser aproximado por um sistema baseado em lógica fuzzy;
Ao mesmo tempo, certas desvantagens são características dos sistemas especialistas e de controle difusos:
1) o conjunto inicial de regras difusas postuladas é formulado por um especialista humano e pode ser incompleto ou contraditório;
2) o tipo e os parâmetros das funções de pertinência que descrevem as variáveis de entrada e saída do sistema são escolhidos subjetivamente e podem não refletir totalmente a realidade.
Para eliminar, ao menos parcialmente, as deficiências apontadas, vários autores propuseram implementar sistemas especialistas difusos e de controle com sistemas adaptativos - ajustando, conforme o sistema funcione, tanto as regras quanto os parâmetros das funções de pertinência. Entre as várias variantes dessa adaptação, uma das mais bem-sucedidas, aparentemente, é o método das chamadas redes neurais híbridas.
Uma rede neural híbrida é formalmente idêntica em estrutura a uma rede neural multicamadas com treinamento, por exemplo, de acordo com o algoritmo de retropropagação de erro, mas as camadas ocultas nela correspondem aos estágios de funcionamento do sistema difuso. Então:
A -1ª camada de neurônios desempenha a função de introduzir fuzziness com base nas funções de pertinência fornecidas das entradas;
A segunda camada exibe um conjunto de regras difusas;
- A 3ª camada tem a função de nitidez.
Cada uma dessas camadas é caracterizada por um conjunto de parâmetros (parâmetros de funções de pertinência, regras de decisão fuzzy, ativos
funções, pesos das conexões), cujo ajuste é executado, em essência, da mesma forma que para as redes neurais convencionais.
O livro examina os aspectos teóricos dos componentes de tais redes, nomeadamente, o aparato da lógica fuzzy, os fundamentos da teoria das redes neurais artificiais e das redes híbridas próprias em relação aos problemas de controlo e tomada de decisão em condições de incerteza.
É dada especial atenção à implementação de software dos modelos destas abordagens utilizando as ferramentas do sistema matemático MATLAB 5.2 / 5.3.
Artigos anteriores:
Os conjuntos difusos e a lógica difusa são generalizações da teoria dos conjuntos clássica e da lógica formal clássica. Esses conceitos foram propostos pela primeira vez pelo cientista americano Lotfi Zadeh em 1965. A principal razão para o surgimento de uma nova teoria foi a presença de raciocínio difuso e aproximado quando uma pessoa descreve processos, sistemas, objetos.
Antes que a abordagem fuzzy para modelar sistemas complexos fosse reconhecida em todo o mundo, demorou mais de uma década desde o início da teoria dos conjuntos fuzzy. E neste caminho de desenvolvimento de sistemas fuzzy, costuma-se distinguir três períodos.
O primeiro período (final dos anos 60 - início dos 70) é caracterizado pelo desenvolvimento do aparato teórico dos conjuntos difusos (L. Zadeh, E. Mamdani, Bellman). No segundo período (70-80), os primeiros resultados práticos surgiram no campo do controle fuzzy de sistemas técnicos complexos (um gerador de vapor com controle fuzzy). Ao mesmo tempo, passou-se a dar atenção às questões de construção de sistemas especialistas baseados em lógica fuzzy, o desenvolvimento de controladores fuzzy. Os sistemas especialistas difusos para apoio à decisão são amplamente utilizados na medicina e na economia. Finalmente, no terceiro período, que vai do final dos anos 80 e continua na atualidade, surgem pacotes de software para construção de sistemas especialistas fuzzy, e os campos de aplicação da lógica fuzzy se expandem significativamente. É usado nas indústrias automotiva, aeroespacial e de transporte, eletrodomésticos, finanças, análise e tomada de decisões de gestão e muitos outros.
A marcha triunfal da lógica fuzzy ao redor do mundo começou depois que Bartholomew Kosco provou o famoso FAT (Teorema de Aproximação Fuzzy) no final dos anos 80. Nos negócios e nas finanças, a lógica difusa ganhou aceitação depois que, em 1988, um sistema especialista baseado em regras difusas para prever indicadores financeiros foi o único a prever um colapso do mercado de ações. E o número de aplicativos difusos bem-sucedidos está atualmente na casa dos milhares.
Aparato matemático
A característica de um conjunto fuzzy é a função de associação. Denotamos por MF c (x) - o grau de pertinência a um conjunto difuso C, que é uma generalização do conceito de função característica de um conjunto ordinário. Então, um conjunto fuzzy C é o conjunto de pares ordenados da forma C = (MF c (x) / x), MF c (x). O valor MF c (x) = 0 significa nenhuma associação no conjunto, 1 - associação completa.
Vamos ilustrar isso com um exemplo simples. Vamos formalizar a definição imprecisa de "chá quente". O x (área de raciocínio) será a escala de temperatura em graus Celsius. Obviamente, ele variará de 0 a 100 graus. Um conjunto difuso para chá quente pode ter a seguinte aparência:
C = (0/0; 0/10; 0/20; 0,15 / 30; 0,30 / 40; 0,60 / 50; 0,80 / 60; 0,90 / 70; 1/80; 1/90; 1/100).
Assim, o chá com uma temperatura de 60 C pertence ao conjunto "Quente" com um grau de pertencimento a 0,80. Para uma pessoa, o chá a uma temperatura de 60 C pode ser quente, para outra pode não estar muito quente. É nisso que se manifesta a indistinção da atribuição do conjunto correspondente.
Para conjuntos fuzzy, bem como para os comuns, as operações lógicas básicas são definidas. Os mais básicos necessários para os cálculos são intersecção e união.
Interseção de dois conjuntos fuzzy (fuzzy "AND"): A B: MF AB (x) = min (MF A (x), MF B (x)).
A união de dois conjuntos fuzzy (fuzzy "OR"): A B: MF AB (x) = max (MF A (x), MF B (x)).
Na teoria dos conjuntos fuzzy, foi desenvolvida uma abordagem geral para a execução dos operadores de intersecção, união e complemento, implementada nas chamadas normas triangulares e conormes. As implementações acima de operações de interseção e união são os casos mais comuns de norma t e conor t.
Para descrever conjuntos fuzzy, os conceitos de variáveis fuzzy e linguísticas são introduzidos.
Uma variável fuzzy é descrita por um conjunto (N, X, A), onde N é o nome da variável, X é um conjunto universal (área de raciocínio), A é um conjunto fuzzy em X.
Os valores de uma variável linguística podem ser variáveis fuzzy, ou seja, a variável linguística está em um nível mais alto do que a variável fuzzy. Cada variável linguística consiste em:
- títulos;
- o conjunto de seus valores, também chamado de conjunto de termos básico T. Os elementos do conjunto de termos básico são nomes de variáveis difusas;
- conjunto universal X;
- regra sintática G, segundo a qual novos termos são gerados usando palavras de uma linguagem natural ou formal;
- regra semântica P, que atribui a cada valor de uma variável linguística um subconjunto difuso do conjunto X.
Considere um conceito tão difuso como "Preço das Ações". Este é o nome da variável linguística. Vamos formar um conjunto de termos básico para isso, que consistirá em três variáveis difusas: "Baixo", "Moderado", "Alto" e definir a área de raciocínio na forma X = (unidades). A última coisa a fazer é construir funções de pertinência para cada termo linguístico do conjunto de termos base T.
Existem mais de uma dúzia de formas de curvas típicas para atribuir funções de pertinência. As mais difundidas são: funções de pertinência triangulares, trapezoidais e gaussianas.
A função de pertinência triangular é determinada por um triplo de números (a, b, c), e seu valor no ponto x é calculado de acordo com a expressão:
$$ MF \, (x) = \, \ begin (casos) \; 1 \, - \, \ frac (b \, - \, x) (b \, - \, a), \, a \ leq \, x \ leq \, b & \ \\ 1 \, - \, \ frac (x \, - \, b) (c \, - \, b), \, b \ leq \, x \ leq \ , c & \ \\ 0, \; x \, \ não \ em \, (a; \, c) \ \ end (casos) $$
Para (b-a) = (c-b), temos o caso de uma função de pertinência triangular simétrica, que pode ser especificada exclusivamente por dois parâmetros do triplo (a, b, c).
Da mesma forma, para definir a função de associação trapezoidal, você precisa de quatro números (a, b, c, d):
$$ MF \, (x) \, = \, \ begin (casos) \; 1 \, - \, \ frac (b \, - \, x) (b \, - \, a), \, a \ leq \, x \ leq \, b & \\ 1, \, b \ leq \, x \ leq \, c & \\ 1 \, - \, \ frac (x \, - \, c) (d \, - \, c), \, c \ leq \, x \ leq \, d & \\ 0, x \, \ não \ em \, (a; \, d) \ \ end (casos) $$
Quando (b-a) = (d-c), a função de pertinência trapezoidal assume uma forma simétrica.
A função de pertinência do tipo gaussiano é descrita pela fórmula
$$ MF \, (x) = \ exp \ biggl [- \, (\ Bigl (\ frac (x \, - \, c) (\ sigma) \ Bigr)) ^ 2 \ biggr] $$
e opera com dois parâmetros. Parâmetro c denota o centro de um conjunto fuzzy, e o parâmetro é responsável pela inclinação da função.

O conjunto de funções de pertinência para cada termo do conjunto de termos base T são geralmente representados juntos em um gráfico. A Figura 3 mostra um exemplo da variável linguística “Preço da Ação” descrita acima, e a Figura 4 mostra a formalização do conceito impreciso de “Idade Humana”. Portanto, para uma pessoa de 48 anos, o grau de pertencimento ao conjunto "Jovem" é 0, "Médio" - 0,47, "Acima da média" - 0,20.


O número de termos em uma variável linguística raramente excede 7.
Inferência difusa
A base para a operação de inferência lógica difusa é a base de regras contendo declarações difusas na forma "Se-então" e funções de pertinência para os termos linguísticos correspondentes. Nesse caso, as seguintes condições devem ser atendidas:
- Há pelo menos uma regra para cada termo linguístico na variável de saída.
- Para qualquer termo na variável de entrada, há pelo menos uma regra na qual esse termo é usado como pré-requisito (o lado esquerdo da regra).
Caso contrário, existe uma base de regra difusa incompleta.
Deixe a base de regra ter m regras da forma:
R 1: SE x 1 é A 11 ... E ... x n é A 1n, ENTÃO y é B 1
…
R i: SE x 1 é A i1 ... E ... x n é A em ENTÃO y é B i
…
R m: SE x 1 é A i1 ... E ... x n é A mn, ENTÃO y é B m,
onde x k, k = 1..n - variáveis de entrada; y - variável de saída; Um conjunto fuzzy dado ik com funções de pertinência.
O resultado da inferência difusa é um valor claro da variável y * com base nos valores claros fornecidos x k, k = 1..n.
Em geral, o mecanismo de inferência inclui quatro estágios: introdução difusa (fuzzificação), inferência difusa, composição e redução para clareza ou defuzzificação (ver Figura 5).

Os algoritmos de inferência fuzzy diferem principalmente no tipo de regras usadas, operações lógicas e um tipo de método de defuzzificação. Modelos de inferência difusa para Mamdani, Sugeno, Larsen, Tsukamoto foram desenvolvidos.
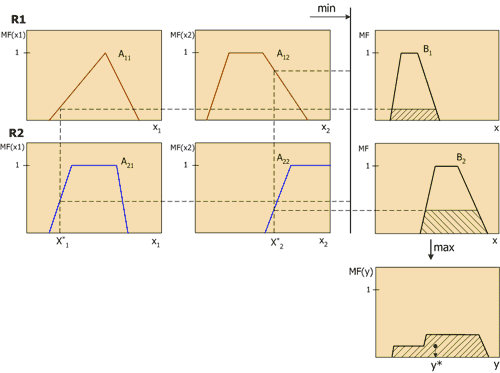
Vamos dar uma olhada mais de perto na inferência difusa usando o mecanismo Mamdani como exemplo. Esta é a inferência mais comum em sistemas fuzzy. Ele usa composição minimax de conjuntos difusos. Este mecanismo inclui a seguinte seqüência de ações.
- Procedimento de fuzzificação: os graus de verdade são determinados, ou seja, os valores das funções de pertinência para o lado esquerdo de cada regra (pré-requisitos). Para uma base de regra com m regras, denotamos os graus de verdade como A ik (x k), i = 1..m, k = 1..n.
Inferência difusa. Primeiro, os níveis de "recorte" são determinados para o lado esquerdo de cada regra:
$$ alfa_i \, = \, \ min_i \, (A_ (ik) \, (x_k)) $$
$$ B_i ^ * (y) = \ min_i \, (alfa_i, \, B_i \, (y)) $$
Composição, ou união das funções truncadas obtidas, para as quais é utilizada a composição máxima de conjuntos fuzzy:
$$ MF \, (y) = \ max_i \, (B_i ^ * \, (y)) $$
onde MF (y) é a função de pertinência do conjunto fuzzy final.
Desfasificação ou redução à clareza. Existem vários métodos de defuzzificação. Por exemplo, o método do centro do meio ou o método do centróide:
$$ MF \, (y) = \ max_i \, (B_i ^ * \, (y)) $$
O significado geométrico desse valor é o centro de gravidade da curva MF (y). A Figura 6 mostra graficamente o processo de inferência fuzzy de Mamdani para duas variáveis de entrada e duas regras fuzzy R1 e R2.
Integração com paradigmas inteligentes
A hibridização de métodos de processamento inteligente de informações é o lema sob o qual os anos 90 passaram entre os pesquisadores ocidentais e americanos. Como resultado da combinação de várias tecnologias de inteligência artificial, um termo especial apareceu - "computação suave", que foi introduzido por L. Zadeh em 1994. Atualmente, a computação suave reúne áreas como: lógica fuzzy, redes neurais artificiais, raciocínio probabilístico e algoritmos evolutivos. Eles se complementam e são usados em várias combinações para criar sistemas inteligentes híbridos.
A influência da lógica difusa acabou por ser talvez a mais extensa. Assim como os conjuntos fuzzy expandiram o escopo da teoria matemática clássica dos conjuntos, a lógica fuzzy "invadiu" quase a maioria dos métodos de mineração de dados, dotando-os de novas funcionalidades. Os exemplos mais interessantes de tais associações são dados a seguir.
Redes neurais difusas
Redes fuzzy-neurais realizam inferências baseadas no aparato da lógica fuzzy, entretanto, os parâmetros das funções de pertinência são ajustados usando os algoritmos de aprendizagem da rede neural. Portanto, para selecionar os parâmetros de tais redes, aplicaremos o método de retropropagação do erro originalmente proposto para treinar um perceptron multicamadas. Para isso, o módulo de controle fuzzy é apresentado na forma de uma rede multicamadas. Uma rede neural difusa geralmente consiste em quatro camadas: uma camada de fuzzificação para variáveis de entrada, uma camada de agregação de valor de ativação de condição, uma camada de agregação de regra difusa e uma camada de saída.
As mais difundidas atualmente são as arquiteturas de rede neural difusa, como ANFIS e TSK. Está provado que tais redes são aproximadoras universais.
Algoritmos de aprendizado rápido e capacidade de interpretação do conhecimento acumulado - esses fatores tornaram as redes neurais fuzzy uma das ferramentas mais promissoras e eficazes para computação soft hoje.
Sistemas fuzzy adaptativos
Os sistemas fuzzy clássicos têm a desvantagem de que, para a formulação de regras e funções de pertinência, é necessário envolver especialistas em uma determinada área, o que nem sempre é possível garantir. Os sistemas fuzzy adaptativos resolvem esse problema. Em tais sistemas, a seleção de parâmetros de um sistema fuzzy é realizada no processo de aprendizagem de dados experimentais. Algoritmos de aprendizagem para sistemas fuzzy adaptativos são relativamente trabalhosos e complexos em comparação com algoritmos de aprendizagem para redes neurais e, via de regra, consistem em duas etapas: 1. Geração de regras linguísticas; 2. Correção das funções de filiação. O primeiro problema é um problema do tipo enumerado, o segundo é a otimização em espaços contínuos. Nesse caso, surge uma certa contradição: para gerar regras fuzzy, são necessárias funções de pertinência e, para realizar inferência fuzzy, regras. Além disso, ao gerar regras fuzzy automaticamente, é necessário garantir sua integridade e consistência.
Uma parte significativa dos métodos de treinamento de sistemas fuzzy usa algoritmos genéticos. Na literatura de língua inglesa, isso corresponde a um termo especial - Sistemas Genéticos Fuzzy.
Um grupo de pesquisadores espanhóis liderado por F. Herrera deu uma contribuição significativa para o desenvolvimento da teoria e prática de sistemas fuzzy com adaptação evolutiva.
Consultas difusas
As consultas fuzzy são uma tendência promissora nos sistemas modernos de processamento de informações. Esta ferramenta permite formular consultas em linguagem natural, por exemplo: "Listar ofertas de habitação de baixo custo perto do centro da cidade", o que não é possível com o mecanismo de consulta padrão. Para tanto, foram desenvolvidas álgebra relacional fuzzy e extensões especiais das linguagens SQL para consultas fuzzy. A maior parte da pesquisa nesta área pertence aos cientistas da Europa Ocidental D. Dubois e G. Prade.
Regras de associação difusas
Regras associativas difusas são uma ferramenta para extrair padrões de bancos de dados que são formulados na forma de declarações linguísticas. Conceitos especiais de transação difusa, suporte e validade da regra de associação difusa são introduzidos aqui.
Mapas cognitivos difusos
Os mapas cognitivos difusos foram propostos por B. Kosko em 1986 e são usados para modelar as relações causais identificadas entre os conceitos de uma determinada área. Ao contrário dos mapas cognitivos simples, os mapas cognitivos difusos são gráficos direcionados difusos, cujos nós são conjuntos difusos. As arestas direcionadas do gráfico não apenas refletem as relações causais entre os conceitos, mas também determinam o grau de influência (peso) dos conceitos relacionados. O uso ativo de mapas cognitivos fuzzy como meio de modelagem de sistemas se deve à possibilidade de representação visual do sistema analisado e à facilidade de interpretação das relações de causa e efeito entre conceitos. Os principais problemas estão associados ao processo de construção de um mapa cognitivo, que não se presta à formalização. Além disso, é necessário comprovar que o mapa cognitivo construído é adequado ao sistema real modelado. Para resolver esses problemas, foram desenvolvidos algoritmos para a construção automática de mapas cognitivos baseados em amostragem de dados.
Agrupamento difuso
Os métodos de agrupamento difuso, em contraste com os métodos bem definidos (por exemplo, redes neurais de Kohonen), permitem que o mesmo objeto pertença simultaneamente a vários agrupamentos, mas com graus variáveis. O agrupamento difuso em muitas situações é mais "natural" do que bem definido, por exemplo, para objetos localizados na borda dos agrupamentos. O mais comum: o algoritmo de auto-organização difusa c-means fuzzy e sua generalização na forma do algoritmo de Gustafson-Kessel.
Literatura
- Zade L. O conceito de variável linguística e sua aplicação na tomada de decisões aproximadas. - M.: Mir, 1976.
- Kruglov V.V., Dli M.I. Sistemas de informação inteligentes: suporte computacional para lógica fuzzy e sistemas de inferência fuzzy. - M.: Fizmatlit, 2002.
- Leolenkov A.V. Modelagem fuzzy em MATLAB e fuzzyTECH. - SPb., 2003.
- Rutkovskaya D., Pilinsky M., Rutkovsky L. Redes neurais, algoritmos genéticos e sistemas difusos. - M., 2004.
- Masalovich A. Lógica difusa em negócios e finanças. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Sistemas Kosko B. Fuzzy como aproximadores universais // IEEE Transactions on Computers, vol. 43, No. 11, novembro de 1994. - P. 1329-1333.
- Cordon O., Herrera F., Um estudo geral em sistemas fuzzy genéticos // Algoritmos genéticos em engenharia e ciência da computação, 1995. - P. 33-57.






 nas aulas de tecnologia")





















 novos pincéis no Photoshop?")




