În inima logica fuzzy se află teoria seturilor fuzzy, prezentată într-o serie de lucrări de L. Zade în 1965-1973. Seturile fuzzy și logica fuzzy sunt generalizări ale teoriei clasice a mulțimilor și ale logicii formale clasice. Motivul principal al apariției unei noi teorii a fost prezența unui raționament neclar și aproximativ atunci când o persoană descrie procese, sisteme, obiecte.
L. Zadeh, formulând această proprietate principală a seturilor fuzzy, s-a bazat pe lucrările predecesorilor săi. La începutul anilor 1920, matematicianul polonez Lukashevich lucra la principiile logicii matematice cu mai multe valori, în care valorile predicatelor ar putea fi mai mult decât „adevărate” sau „false”. În 1937, un alt om de știință american M. Black a aplicat pentru prima dată logica multivalorată a lui Lukashevich la liste ca seturi de obiecte și a numit astfel de seturi nedeterminate.
Logica fuzzy ca direcție științifică nu a fost ușor de dezvoltat și nu a scăpat de acuzațiile de pseudștiință. Chiar și în 1989, când au existat zeci de exemple de aplicare cu succes a logicii fuzzy în apărare, industrie și afaceri, Societatea Națională de Științe din SUA a discutat problema excluderii materialelor de pe seturile fuzzy din manualele de institut.
Prima perioadă de dezvoltare a sistemelor fuzzy (sfârșitul anilor 60 - începutul anilor 70) se caracterizează prin dezvoltarea aparatului teoretic al seturilor fuzzy. În 1970, Bellman și Zadeh au dezvoltat teoria luării deciziilor în condiții neclare.
În anii 70-80 (a doua perioadă), primele rezultate practice au apărut în domeniul controlului fuzzy al sistemelor tehnice complexe (un generator de abur cu control fuzzy). I. Mamdani a proiectat în 1975 primul controler care funcționează pe baza algebrei Zade pentru a controla o turbină cu abur. În același timp, a început să se acorde atenție creării de sisteme expert bazate pe logica fuzzy, dezvoltarea controlerelor fuzzy. Sistemele de experți fuzzy pentru sprijinirea deciziilor au găsit o largă aplicare în medicină și economie.
În cele din urmă, în a treia perioadă, care durează de la sfârșitul anilor 80 și continuă în prezent, apar pachete software pentru construirea de sisteme expert fuzzy, iar câmpurile de aplicare a logicii fuzzy se extind semnificativ. Este utilizat în industria auto, aerospațială și de transport, aparate electrocasnice, finanțare, analiză și luare a deciziilor de gestionare și multe altele. În plus, un rol semnificativ în dezvoltarea logicii fuzzy l-a avut dovada faimosului FAT (Fuzzy Approximation Theorem) de B. Cosco, care a afirmat că orice sistem matematic poate fi aproximat printr-un sistem bazat pe logica fuzzy.
Sistemele de informații bazate pe seturi fuzzy și logică fuzzy sunt numite sisteme fuzzy.
Demnitate sisteme fuzzy:
· Funcționarea în condiții de incertitudine;
· Operarea cu date calitative și cantitative;
· Utilizarea cunoștințelor de specialitate în management;
· Construirea de modele de raționament aproximativ al unei persoane;
· Stabilitate la toate perturbările posibile care acționează asupra sistemului.
Dezavantaje sistemele fuzzy sunt:
· Lipsa unei metodologii standard pentru proiectarea sistemelor fuzzy;
· Imposibilitatea analizei matematice a sistemelor fuzzy prin metodele existente;
· Utilizarea unei abordări fuzzy în comparație cu abordarea probabilistică nu duce la o creștere a preciziei calculelor.
Teoria seturilor fuzzy. Principala diferență între teoria seturilor fuzzy și teoria clasică a seturilor clare este că, dacă pentru seturile clare rezultatul calculării funcției caracteristice poate fi doar două valori - 0 sau 1, atunci pentru seturile fuzzy acest număr este infinit, dar limitat de intervalul de la zero la unu.
Set fuzzy. Fie U așa-numita mulțime universală, din elementele căreia se formează toate celelalte mulțimi considerate în clasa dată de probleme, de exemplu, mulțimea tuturor numerelor întregi, mulțimea tuturor funcțiilor netede etc. Funcția caracteristică a unui set este o funcție ale cărei valori indică dacă este un element al setului A:

În teoria seturilor fuzzy, funcția caracteristică se numește funcție de apartenență, iar valoarea sa este gradul de apartenență al unui element x dintr-un set fuzzy A.
Mai strict: un set fuzzy A este o colecție de perechi
![]()
unde este funcția de membru, adică ![]()
Fie, de exemplu, U = (a, b, c, d, e) ,. Atunci elementul a nu aparține mulțimii A, elementul b îi aparține într-o mică măsură, elementul c mai mult sau mai puțin aparține, elementul d aparține în mare măsură, e este un element al mulțimii A.
Exemplu. Fie universul U setul de numere reale. Un set fuzzy A, care denotă un set de numere apropiate de 10, poate fi specificat prin următoarea funcție de membru (figura 21.1):
![]() ,
,





Exemplu "Ceai fierbinte" X = 0 CC; C = 0/0; 0/10; 0/20; 0,15 / 30; 0,30 / 40; 0,60 / 50; 0,80 / 60; 0, 90/70; 1/80; 1/90; 1/100.

Intersecția a două seturi fuzzy (fuzzy "ȘI"): MF AB (x) = min (MF A (x), MF B (x)). Unirea a două seturi fuzzy ("OR" fuzzy): MF AB (x) = max (MF A (x), MF B (x)).

Potrivit lui Lotfi Zadeh, o variabilă lingvistică este o variabilă ale cărei valori sunt cuvinte sau propoziții ale unui limbaj natural sau artificial. Valorile unei variabile lingvistice pot fi variabile fuzzy, adică variabila lingvistică este la un nivel mai înalt decât variabila fuzzy.

Fiecare variabilă lingvistică constă din: nume; setul valorilor sale, care se mai numește și setul de termeni de bază T. Elementele setului de termeni de bază sunt numele variabilelor fuzzy; set universal X; regula sintactică G, conform căreia se generează noi termeni folosind cuvinte de limbaj natural sau formal; regula semantică P, care atribuie fiecărei valori a unei variabile lingvistice un subset fuzzy al mulțimii X.





Descrierea variabilei lingvistice „Prețul acțiunii” X = Set de termeni de bază: „Scăzut”, „Moderat”, „Ridicat”

Descrierea variabilei lingvistice „vârstă”




Logică fuzzy de calcul soft, rețele neuronale artificiale, raționament probabilistic, algoritmi evolutivi













Construirea rețelei (după alegerea variabilelor de intrare) Selectați configurația inițială a rețelei Efectuați o serie de experimente cu diferite configurații, reținând cea mai bună rețea (în sensul unei erori de checkout). Ar trebui efectuate mai multe experimente pentru fiecare configurație. Dacă în următorul experiment se observă o insuficiență (rețeaua nu produce un rezultat de o calitate acceptabilă), încercați să adăugați neuroni suplimentari la stratul intermediar. Dacă acest lucru nu funcționează, încercați să adăugați un nou strat intermediar. Dacă are loc o supra-montare (eroarea de control a început să crească), încercați să eliminați mai multe elemente ascunse (și, eventual, straturi).

Sarcini de extragere a datelor rezolvate folosind rețelele neuronale Clasificarea (învățarea supravegheată) Clusterul de predicție (învățarea nesupravegheată) recunoașterea textului, recunoașterea vorbirii, identificarea personalității găsesc cea mai bună aproximare a unei funcții dată de un set finit de valori de intrare (exemple de instruire, problema comprimarea informațiilor prin scăderea dimensiunii datelor

Sarcina „Dacă emiteți un împrumut unui client” în pachetul analitic Deductor (BaseGroup) Set de instruire - o bază de date care conține informații despre clienți: - Valoarea împrumutului, - Durata împrumutului, - Scopul împrumutului, - Vârsta, - Sexul, - Educația , - Proprietate privată, - Apartament, - Suprafața apartamentului. Este necesar să se construiască un model care să poată da un răspuns dacă Clientul care dorește să obțină un împrumut se află în grupul de risc al neîndeplinirii obligațiilor de împrumut, adică utilizatorul ar trebui să primească un răspuns la întrebarea „Ar trebui să emit un împrumut?” Sarcina aparține grupului de sarcini de clasificare, adică învățând cu un profesor.




Să luăm în considerare câteva dintre metodele de calcul „soft” care nu sunt încă utilizate pe scară largă în afaceri. Algoritmii și parametrii acestor metode sunt mult mai puțin deterministe decât cele tradiționale. Apariția conceptelor de calcul „soft” a fost cauzată de încercările de modelare simplificată a proceselor intelectuale și naturale, care sunt în mare parte aleatorii.
Rețelele neuronale utilizează înțelegerea modernă a structurii și funcționării creierului. Se crede că creierul este format din elemente simple - neuroni, conectați prin sinapse, prin care schimbă semnale.
Principalul avantaj al rețelelor neuronale este capacitatea de a învăța prin exemplu. În majoritatea cazurilor, învățarea este procesul de modificare a coeficienților de ponderare a sinapselor în funcție de un algoritm specific. Acest lucru necesită de obicei multe exemple și multe cicluri de instruire. Aici puteți desena o analogie cu reflexele câinelui lui Pavlov, în care și salivația la apel nu a început să apară imediat. Observăm doar că cele mai complexe modele de rețele neuronale sunt multe ordine de mărime mai simple decât creierul câinelui; și sunt necesare mult mai multe cicluri de formare.
Utilizarea rețelelor neuronale este justificată atunci când este imposibil să se construiască un model matematic precis al obiectului sau fenomenului studiat. De exemplu, vânzările în decembrie sunt de obicei mai mari decât în noiembrie, dar nu există o formulă prin care să se calculeze cât vor fi mai multe anul acesta; pentru a prezice volumul vânzărilor, puteți antrena o rețea neuronală folosind exemple din anii precedenți.
Printre dezavantajele rețelelor neuronale se numără: timpul lung de antrenament, tendința de a se adapta la datele de antrenament și o scădere a abilităților generalizatoare odată cu creșterea timpului de antrenament. În plus, este imposibil de explicat modul în care rețeaua ajunge la această sau acea soluție a problemei, adică rețelele neuronale sunt sisteme de cutie neagră, deoarece funcțiile neuronilor și ponderile sinapselor nu au o interpretare reală. Cu toate acestea, există o mulțime de algoritmi de rețea neuronală în care aceste și alte dezavantaje sunt cumva nivelate.
În prognoză, rețelele neuronale sunt utilizate cel mai adesea în conformitate cu cea mai simplă schemă: ca date de intrare, informațiile preprocesate despre valorile parametrului prezis pentru mai multe perioade anterioare sunt introduse în rețea, la ieșire rețeaua emite o prognoză pentru perioadele următoare - ca în exemplul de mai sus cu vânzări. Există, de asemenea, modalități mai puțin banale de a obține o prognoză; Rețelele neuronale sunt un instrument foarte flexibil, deci există multe modele finite ale rețelelor în sine și ale aplicațiilor lor.
O altă metodă este algoritmii genetici. Ele se bazează pe căutarea aleatorie direcționată, adică o încercare de a simula procesele evolutive în natură. În versiunea de bază, algoritmii genetici funcționează astfel:
1. Soluția la problemă este prezentată sub forma unui cromozom.
2. Se creează un set aleatoriu de cromozomi - aceasta este generația inițială de soluții.
3. Sunt procesate de operatori speciali de reproducere și mutație.
4. Se efectuează evaluarea soluțiilor și selectarea acestora pe baza funcției de adecvare.
5. Este afișată o nouă generație de soluții și ciclul se repetă.
Ca rezultat, se găsesc soluții mai perfecte cu fiecare epocă a evoluției.
Când folosește algoritmi genetici, analistul nu are nevoie de informații a priori despre natura datelor inițiale, despre structura acestora etc. Analogia de aici este transparentă - culoarea ochilor, forma nasului și grosimea liniei părului. pe picioare sunt codificate în genele noastre de aceleași nucleotide.
În prognoză, algoritmii genetici sunt rareori folosiți direct, deoarece este dificil să vină cu un criteriu de evaluare a unei prognoze, adică un criteriu de selectare a deciziilor - la naștere este imposibil să se determine cine va deveni o persoană - un astronaut sau un alconaut. Prin urmare, algoritmii genetici servesc de obicei ca metodă auxiliară - de exemplu, atunci când se antrenează o rețea neuronală cu funcții de activare nestandardizate, în care este imposibil să se utilizeze algoritmi de gradient. Aici, ca exemplu, putem denumi rețelele MIP, care prezic cu succes fenomene aparent aleatorii - numărul de pete de pe soare și intensitatea laserului.
O altă metodă este logica fuzzy care simulează procesele de gândire. Spre deosebire de logica binară, care necesită formulări precise și lipsite de ambiguitate, logica fuzzy oferă un nivel diferit de gândire. De exemplu, formalizarea declarației „vânzările de luna trecută au fost reduse” în cadrul logicii tradiționale binare sau „booleene” necesită o distincție clară între vânzările „reduse” (0) și „ridicate” (1). De exemplu, vânzările egale sau mai mari de 1 milion de sicli sunt mari, vânzările mai mici sunt mici.
Se pune întrebarea: de ce vânzările la nivelul de 999.999 sicli sunt deja considerate scăzute? Evident, această afirmație nu este pe deplin corectă. Logica fuzzy funcționează cu concepte mai moi. De exemplu, vânzările de 900.000 NIS ar fi considerate mari cu un rang de 0,9 și scăzute cu un rang de 0,1.
În logica fuzzy, sarcinile sunt formulate în termeni de reguli constând din seturi de condiții și rezultate. Exemple ale celor mai simple reguli: „Dacă clienților li s-a acordat un termen modest de împrumut, atunci vânzările vor fi așa”, „Dacă clienților li se oferă o reducere decentă, atunci vânzările vor fi bune”.
După stabilirea problemei în termeni de reguli, valorile clare ale condițiilor (termenul împrumutului în zile și valoarea reducerii în procente) sunt convertite într-o formă neclară (mare, mică etc.). Apoi sunt procesate folosind operații logice și transformarea inversă în variabile numerice (nivelul de vânzări prevăzut în unități de producție).
Comparativ cu metodele probabilistice, cele fuzzy pot reduce drastic cantitatea de calcule efectuate, dar de obicei nu măresc acuratețea lor. Printre neajunsurile unor astfel de sisteme se poate remarca absența unei metodologii standard de proiectare, imposibilitatea analizei matematice prin metode tradiționale. În plus, în sistemele clasice fuzzy, o creștere a numărului de cantități de intrare duce la o creștere exponențială a numărului de reguli. Pentru a depăși aceste și alte dezavantaje, ca în cazul rețelelor neuronale, există multe modificări ale sistemelor logice fuzzy.
În cadrul metodelor de calcul soft, se pot distinge așa-numiții algoritmi hibrizi, care includ mai multe componente diferite. De exemplu, rețelele fuzzy-logice sau rețelele neuronale deja menționate cu învățare genetică.
În algoritmii hibrizi, de regulă, există un efect sinergic, în care dezavantajele unei metode sunt compensate de avantajele altora, iar sistemul final arată un rezultat inaccesibil oricăreia dintre componente separat.
Titlu: Logică fuzzy și rețele neuronale artificiale.După cum știți, aparatul seturilor fuzzy și al logicii fuzzy a fost utilizat cu succes de mult timp (mai mult de 10 ani) pentru rezolvarea problemelor în care datele inițiale sunt nesigure și slab formalizate. Punctele forte ale acestei abordări:
-descrierea condițiilor și metodei de rezolvare a problemei într-un limbaj apropiat de natural;
-universalitatea: conform celebrului FAT (Fuzzy Approximation Theorem), dovedit de B.Kosko în 1993, orice sistem matematic poate fi aproximat printr-un sistem bazat pe logică fuzzy;
În același timp, anumite dezavantaje sunt caracteristice pentru sistemele de control și expert fuzzy:
1) setul inițial de reguli fuzzy postulate este formulat de un expert uman și se poate dovedi incomplet sau contradictoriu;
2) tipul și parametrii funcțiilor de membru care descriu variabilele de intrare și ieșire ale sistemului sunt alese subiectiv și pot să nu reflecte pe deplin realitatea.
Pentru a elimina, cel puțin parțial, deficiențele indicate, un număr de autori au propus să implementeze sisteme de expertizare și control fuzzy cu sisteme adaptive - ajustând, pe măsură ce sistemul funcționează, atât regulile, cât și parametrii funcțiilor de membru. Printre mai multe variante ale unei astfel de adaptări, una dintre cele mai reușite, aparent, este metoda așa-numitelor rețele neuronale hibride.
O rețea neuronală hibridă este în mod formal identică ca structură cu o rețea neuronală multistrat cu antrenament, de exemplu, conform algoritmului de propagare a erorii, dar straturile ascunse din ea corespund etapelor funcționării sistemului fuzzy. Asa de:
Primul strat de neuroni îndeplinește funcția de a introduce fuzziness pe baza funcțiilor de membru date ale intrărilor;
Al doilea strat afișează un set de reguli neclare;
- Al treilea strat are funcția de ascuțire.
Fiecare dintre aceste straturi este caracterizat de un set de parametri (parametrii funcțiilor de apartenență, reguli de decizie fuzzy, active
funcții, greutățile conexiunilor), a căror ajustare se realizează, în esență, în același mod ca și pentru rețelele neuronale convenționale.
Cartea examinează aspectele teoretice ale componentelor unor astfel de rețele, și anume, aparatul logicii fuzzy, fundamentele teoriei rețelelor neuronale artificiale și a rețelelor hibride proprii în raport cu problemele de control și luare a deciziilor în condiții de incertitudine.
O atenție deosebită este acordată implementării software a modelelor acestor abordări folosind instrumentele sistemului matematic MATLAB 5.2 / 5.3.
Articole anterioare:
Seturile fuzzy și logica fuzzy sunt generalizări ale teoriei clasice a mulțimilor și ale logicii formale clasice. Aceste concepte au fost propuse pentru prima dată de omul de știință american Lotfi Zadeh în 1965. Principalul motiv al apariției unei noi teorii a fost prezența unui raționament fuzzy și aproximativ atunci când o persoană descrie procese, sisteme, obiecte.
Înainte ca abordarea fuzzy a modelării sistemelor complexe să fie recunoscută în întreaga lume, a trecut mai mult de un deceniu de la înființarea teoriei seturilor fuzzy. Și pe această cale de dezvoltare a sistemelor fuzzy, se obișnuiește să distingem trei perioade.
Prima perioadă (sfârșitul anilor 60 - începutul anilor 70) se caracterizează prin dezvoltarea aparatului teoretic al seturilor fuzzy (L. Zadeh, E. Mamdani, Bellman). În a doua perioadă (anii 70-80), primele rezultate practice au apărut în domeniul controlului fuzzy al sistemelor tehnice complexe (un generator de abur cu control fuzzy). În același timp, a început să se acorde atenție problemelor construirii unor sisteme expert bazate pe logica fuzzy, dezvoltarea controlerelor fuzzy. Sistemele de experți fuzzy pentru sprijinirea deciziilor sunt utilizate pe scară largă în medicină și economie. În cele din urmă, în a treia perioadă, care durează de la sfârșitul anilor 80 și continuă în prezent, apar pachete software pentru construirea de sisteme expert fuzzy, iar câmpurile de aplicare a logicii fuzzy se extind semnificativ. Este utilizat în industria auto, aerospațială și de transport, aparate electrocasnice, finanțare, analiză și luare a deciziilor de gestionare și multe altele.
Marșul triumfător al logicii fuzzy din întreaga lume a început după ce Bartholomew Kosco a demonstrat celebrul FAT (Fuzzy Approximation Theorem) la sfârșitul anilor '80. În afaceri și finanțe, logica fuzzy a câștigat acceptarea după ce, în 1988, un sistem expert fuzzy bazat pe reguli pentru previzionarea indicatorilor financiari a fost singurul care a prezis o prăbușire bursieră. Și numărul aplicațiilor fuzzy de succes este în prezent de mii.
Aparat matematic
Caracteristica unui set fuzzy este funcția de membru. Notăm prin MF c (x) - gradul de apartenență la un set fuzzy C, care este o generalizare a conceptului funcției caracteristice a unui set obișnuit. Atunci un set fuzzy C este setul de perechi ordonate de forma C = (MF c (x) / x), MF c (x). Valoarea MF c (x) = 0 înseamnă că nu este membru în set, 1 - membru complet.
Să ilustrăm acest lucru cu un exemplu simplu. Să formalizăm definiția imprecisă a „ceaiului fierbinte”. X (aria raționamentului) va fi scara temperaturii în grade Celsius. Evident, va varia de la 0 la 100 de grade. Un set fuzzy pentru ceai fierbinte ar putea arăta astfel:
C = (0/0; 0/10; 0/20; 0,15 / 30; 0,30 / 40; 0,60 / 50; 0,80 / 60; 0,90 / 70; 1/80; 1/90; 1/100).
Deci, ceaiul cu temperatura de 60 C aparține setului „Hot” cu un grad de apartenență la 0,80. Pentru o persoană, ceaiul la o temperatură de 60 C poate fi fierbinte, pentru o altă persoană poate să nu fie prea fierbinte. În aceasta se manifestă indistinctitatea atribuirii setului corespunzător.
Pentru seturile fuzzy, precum și pentru cele obișnuite, sunt definite operațiile logice de bază. Cele mai de bază necesare pentru calcule sunt intersecția și unirea.
Intersecția a două seturi fuzzy (fuzzy "ȘI"): A B: MF AB (x) = min (MF A (x), MF B (x)).
Unirea a două seturi fuzzy ("OR" fuzzy): A B: MF AB (x) = max (MF A (x), MF B (x)).
În teoria seturilor fuzzy, a fost dezvoltată o abordare generală a execuției operatorilor de intersecție, unire și complement, implementată în așa-numitele norme și conorme triunghiulare. Implementările de mai sus ale operațiunilor de intersecție și unire sunt cele mai frecvente cazuri de normă t și t-conorm.
Pentru a descrie seturi fuzzy, sunt introduse conceptele de variabile fuzzy și lingvistice.
O variabilă fuzzy este descrisă de un set (N, X, A), unde N este numele variabilei, X este un set universal (zona raționamentului), A este un set fuzzy pe X.
Valorile unei variabile lingvistice pot fi variabile neclare, adică variabila lingvistică este la un nivel mai înalt decât variabila fuzzy. Fiecare variabilă lingvistică constă din:
- titluri;
- setul valorilor sale, care se mai numește setul de termeni de bază T. Elementele setului de termeni de bază sunt numele variabilelor fuzzy;
- set universal X;
- regula sintactică G, conform căreia se generează noi termeni folosind cuvinte de limbaj natural sau formal;
- regula semantică P, care atribuie fiecărei valori a unei variabile lingvistice un subset fuzzy al mulțimii X.
Luați în considerare un concept atât de neclar ca „Prețul acțiunilor”. Acesta este numele variabilei lingvistice. Să formăm un set de termeni de bază pentru acesta, care va consta din trei variabile fuzzy: „Low”, „Moderate”, „High” și setăm aria raționamentului sub forma X = (unități). Ultimul lucru rămas de făcut este să construim funcții de membru pentru fiecare termen lingvistic din setul de termeni de bază T.
Există peste o duzină de forme de curbă tipice pentru atribuirea funcțiilor de membru. Cele mai răspândite sunt: funcțiile de apartenență triunghiulară, trapezoidală și gaussiană.
Funcția de apartenență triunghiulară este determinată de un triplu de numere (a, b, c), iar valoarea sa în punctul x este calculată în funcție de expresia:
$$ MF \, (x) = \, \ begin (cases) \; 1 \, - \, \ frac (b \, - \, x) (b \, - \, a), \, a \ leq \, x \ leq \, b & \ \\ 1 \, - \, \ frac (x \, - \, b) (c \, - \, b), \, b \ leq \, x \ leq \ , c & \ \\ 0, \; x \, \ not \ in \, (a; \, c) \ \ end (cazuri) $$
Pentru (b-a) = (c-b), avem cazul unei funcții de membru triunghiular simetric, care poate fi specificată în mod unic prin doi parametri din triplul (a, b, c).
În mod similar, pentru a seta funcția de apartenență trapezoidală, aveți nevoie de patru numere (a, b, c, d):
$$ MF \, (x) \, = \, \ begin (cases) \; 1 \, - \, \ frac (b \, - \, x) (b \, - \, a), \, a \ leq \, x \ leq \, b & \\ 1, \, b \ leq \, x \ leq \, c & \\ 1 \, - \, \ frac (x \, - \, c) (d \, - \, c), \, c \ leq \, x \ leq \, d & \\ 0, x \, \ not \ in \, (a; \, d) \ \ end (cazuri) $$
Când (b-a) = (d-c), funcția de apartenență trapezoidală ia o formă simetrică.
Funcția de apartenență de tip gaussian este descrisă prin formulă
$$ MF \, (x) = \ exp \ biggl [- \, (\ Bigl (\ frac (x \, - \, c) (\ sigma) \ Bigr)) ^ 2 \ biggr] $$
și funcționează cu doi parametri. Parametru c denotă centrul unui set fuzzy, iar parametrul este responsabil pentru abruptitatea funcției.

Setul de funcții de membru pentru fiecare termen din setul de termeni de bază T sunt de obicei descrise împreună pe un grafic. Figura 3 prezintă un exemplu al variabilei lingvistice „Prețul acțiunilor” descris mai sus și Figura 4 - formalizarea conceptului imprecis de „vârstă umană”. Deci, pentru o persoană de 48 de ani, gradul de apartenență la setul „Tânăr” este 0, „Medie” - 0,47, „Peste medie” - 0,20.


Numărul de termeni dintr-o variabilă lingvistică depășește rareori 7.
Inferență neclară
Baza pentru funcționarea inferenței fuzzy este baza de reguli care conține declarații fuzzy sub forma „Dacă-atunci” și funcții de apartenență pentru termenii lingvistici corespunzători. În acest caz, trebuie îndeplinite următoarele condiții:
- Există cel puțin o regulă pentru fiecare termen lingvistic din variabila de ieșire.
- Pentru orice termen din variabila de intrare, există cel puțin o regulă în care acest termen este utilizat ca o condiție prealabilă (partea stângă a regulii).
În caz contrar, există o bază de regulă fuzzy incompletă.
Fie ca baza de regulă să aibă m reguli de formă:
R 1: DACĂ x 1 este A 11 ... ȘI ... x n este A 1n, ATUNCI y este B 1
…
R i: DACĂ x 1 este A i1 ... ȘI ... x n este A în ATUNCI y este B i
…
R m: DACĂ x 1 este A i1 ... ȘI ... x n este A mn, ATUNCI y este B m,
unde x k, k = 1..n - variabile de intrare; y - variabilă de ieșire; Un set IK difuz cu funcții de membru.
Rezultatul inferenței fuzzy este o valoare clară a variabilei y * pe baza valorilor clare date x k, k = 1..n.
În general, mecanismul de inferență include patru etape: introducere fuzzy (fuzzification), inferență fuzzy, compoziție și reducere la claritate sau defuzzification (vezi Figura 5).

Algoritmii de inferență difuză diferă în principal în ceea ce privește tipul de reguli utilizate, operațiile logice și un fel de metodă de defuzzificare. Au fost dezvoltate modele de inferență neclară pentru Mamdani, Sugeno, Larsen, Tsukamoto.
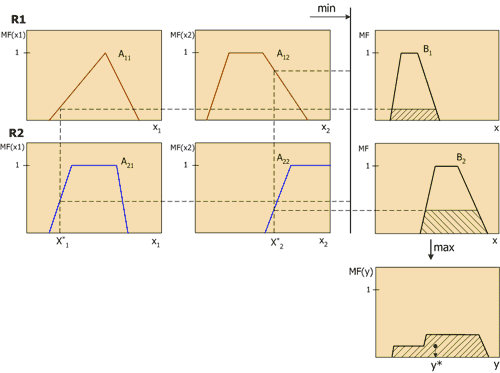
Să aruncăm o privire mai atentă la inferența neclară folosind ca exemplu mecanismul Mamdani. Aceasta este cea mai comună inferență în sistemele fuzzy. Folosește compoziția minimax a seturilor fuzzy. Acest mecanism include următoarea succesiune de acțiuni.
- Procedura de fuzzificare: se determină gradele de adevăr, adică valorile funcțiilor de membru pentru partea stângă a fiecărei reguli (condiții prealabile). Pentru o bază de reguli cu reguli m, denotăm gradele de adevăr ca A ik (x k), i = 1..m, k = 1..n.
Inferență neclară. În primul rând, nivelurile de „tăiere” sunt determinate pentru partea stângă a fiecărei reguli:
$$ alfa_i \, = \, \ min_i \, (A_ (ik) \, (x_k)) $$
$$ B_i ^ * (y) = \ min_i \, (alfa_i, \, B_i \, (y)) $$
Compoziția sau uniunea funcțiilor trunchiate obținute, pentru care se folosește compoziția maximă a seturilor fuzzy:
$$ MF \, (y) = \ max_i \, (B_i ^ * \, (y)) $$
unde MF (y) este funcția de membru al setului final fuzzy.
Defasificare sau reducere la claritate. Există mai multe metode de defasificare. De exemplu, metoda centrului mijlociu sau metoda centrului:
$$ MF \, (y) = \ max_i \, (B_i ^ * \, (y)) $$
Semnificația geometrică a acestei valori este centrul de greutate pentru curba MF (y). Figura 6 prezintă grafic procesul de inferență fuzzy Mamdani pentru două variabile de intrare și două reguli fuzzy R1 și R2.
Integrarea cu paradigme inteligente
Hibridizarea metodelor de procesare inteligentă a informațiilor este deviza sub care au trecut anii 90 în rândul cercetătorilor occidentali și americani. Ca urmare a combinării mai multor tehnologii de inteligență artificială, a apărut un termen special - „soft computing”, care a fost introdus de L. Zadeh în 1994. În prezent, soft computing combină domenii precum: logică fuzzy, rețele neuronale artificiale, raționament probabilistic și algoritmi evolutivi. Se completează reciproc și sunt utilizate în diverse combinații pentru a crea sisteme inteligente hibride.
Influența logicii fuzzy sa dovedit a fi poate cea mai extinsă. Așa cum seturile fuzzy au extins domeniul de aplicare al teoriei matematice clasice a seturilor, logica fuzzy a „invadat” aproape majoritatea metodelor de Data Mining, dotându-le cu noi funcționalități. Cele mai interesante exemple de astfel de asociații sunt date mai jos.
Rețele neuronale neclare
Rețelele fuzzy-neuronale efectuează inferențe pe baza aparatului logicii fuzzy, cu toate acestea, parametrii funcțiilor de apartenență sunt reglați utilizând algoritmii de învățare ai rețelei neuronale. Prin urmare, pentru a selecta parametrii unor astfel de rețele, vom aplica metoda de propagare a erorilor propusă inițial pentru instruirea unui perceptron multistrat. Pentru aceasta, modulul de control fuzzy este prezentat sub forma unei rețele multistrat. O rețea neuronală fuzzy constă de obicei din patru straturi: un strat de fuzzificare pentru variabilele de intrare, un strat de agregare a valorii de activare a condiției, un strat de agregare a regulilor fuzzy și un strat de ieșire.
Cele mai răspândite în prezent sunt arhitecturile de rețea neuronală neclare, cum ar fi ANFIS și TSK. S-a dovedit că astfel de rețele sunt aproximatori universali.
Algoritmi de învățare rapidă și interpretabilitatea cunoștințelor acumulate - acești factori au făcut din rețelele neuronale neclare unul dintre cele mai promițătoare și mai eficiente instrumente pentru soft computing astăzi.
Sisteme fuzzy adaptive
Sistemele clasice fuzzy au dezavantajul că pentru formularea regulilor și funcțiilor de membru este necesar să se implice experți într-un anumit domeniu, ceea ce nu este întotdeauna posibil să se asigure. Sistemele fuzzy adaptive rezolvă această problemă. În astfel de sisteme, selectarea parametrilor unui sistem fuzzy se efectuează în procesul de învățare pe date experimentale. Algoritmii de învățare pentru sistemele fuzzy adaptive sunt relativ laborioși și complexi în comparație cu algoritmii de învățare pentru rețelele neuronale și, de regulă, constau din două etape: 1. Generarea de reguli lingvistice; 2. Corectarea funcțiilor de membru. Prima problemă este o problemă de tip enumerată, a doua este optimizarea în spații continue. În acest caz, apare o anumită contradicție: pentru a genera reguli fuzzy, sunt necesare funcții de membru și pentru a efectua inferență fuzzy, reguli. În plus, atunci când se generează automat reguli neclare, este necesar să se asigure completitudinea și consistența acestora.
O parte semnificativă a metodelor de instruire a sistemelor fuzzy utilizează algoritmi genetici. În literatura de limbă engleză, acesta corespunde unui termen special - Genetic Fuzzy Systems.
Un grup de cercetători spanioli condus de F. Herrera a adus o contribuție semnificativă la dezvoltarea teoriei și practicii sistemelor fuzzy cu adaptare evolutivă.
Interogări neclare
Interogările neclare sunt o tendință promițătoare în sistemele moderne de procesare a informațiilor. Acest instrument vă permite să formulați interogări în limbaj natural, de exemplu: „Enumerați oferte de locuințe cu preț redus aproape de centrul orașului”, ceea ce nu este posibil utilizând mecanismul de interogare standard. În acest scop, au fost dezvoltate algebra relațională fuzzy și extensii speciale ale limbajelor SQL pentru interogări fuzzy. Majoritatea cercetărilor din acest domeniu aparțin oamenilor de știință din Europa de Vest D. Dubois și G. Prade.
Reguli de asociere neclare
Regulile asociative fuzzy sunt un instrument pentru extragerea tiparelor din bazele de date care sunt formulate sub formă de enunțuri lingvistice. Concepte speciale de tranzacție fuzzy, suport și validitate a regulii de asociere fuzzy sunt introduse aici.
Hărți cognitive neclare
Hărțile cognitive neclare au fost propuse de B. Kosko în 1986 și sunt utilizate pentru a modela relațiile cauzale identificate între conceptele unei anumite zone. Spre deosebire de hărțile cognitive simple, hărțile cognitive fuzzy sunt un grafic dirijat fuzzy, ale cărui noduri sunt seturi fuzzy. Marginile direcționate ale graficului reflectă nu numai relațiile cauzale dintre concepte, ci determină și gradul de influență (greutate) al conceptelor conexe. Utilizarea activă a hărților cognitive fuzzy ca mijloc de modelare a sistemelor se datorează posibilității unei reprezentări vizuale a sistemului analizat și ușurinței de interpretare a relațiilor cauză-efect dintre concepte. Principalele probleme sunt asociate cu procesul de construire a unei hărți cognitive, care nu se pretează formalizării. În plus, este necesar să se demonstreze că harta cognitivă construită este adecvată sistemului modelat real. Pentru a rezolva aceste probleme, s-au dezvoltat algoritmi pentru construirea automată a hărților cognitive bazate pe eșantionarea datelor.
Clusterare neclară
Metodele de clusterizare fuzzy, spre deosebire de metodele clare (de exemplu, rețelele neuronale ale lui Kohonen), permit ca același obiect să aparțină simultan mai multor clustere, dar cu grade diferite. Clusterul fuzzy în multe situații este mai „natural” decât clar, de exemplu, pentru obiectele situate la marginea grupurilor. Cel mai comun: algoritmul de autoorganizare f-c-înseamnă generalizarea acestuia sub forma algoritmului Gustafson-Kessel.
Literatură
- Zade L. Conceptul de variabilă lingvistică și aplicarea acesteia la luarea deciziilor aproximative. - M.: Mir, 1976.
- Kruglov V.V., Dli M.I. Sisteme de informații inteligente: suport computerizat pentru logică fuzzy și sisteme de inferență fuzzy. - M.: Fizmatlit, 2002.
- Leolenkov A.V. Modelare fuzzy în MATLAB și fuzzyTECH. - SPb., 2003.
- Rutkovskaya D., Pilinsky M., Rutkovsky L. Rețele neuronale, algoritmi genetici și sisteme fuzzy. - M., 2004.
- Masalovich A. Logică neclară în afaceri și finanțe. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Sisteme fuzzy ca aproximatori universali // IEEE Transactions on Computers, vol. 43, nr. 11, noiembrie 1994. - P. 1329-1333.
- Cordon O., Herrera F., A General study on genetic fuzzy systems // Genetic Algorithms in engineering and computer science, 1995. - P. 33-57.






 în lecțiile de tehnologie")





















 noi pensule în Photoshop?")




