O výběru sémantického jádra bylo napsáno mnoho článků, ale stále dochází k chybám. Jak vybrat sémantické jádro s velkým počtem klíčových slov? Potřebujete časem rozšířit sémantické jádro? Jak distribuovat klíčová slova na stránce? Pro tyto a další otázky si přečtěte náš Cheat Sheet.
Pozornost! Další číslo „Cheat Sheet Optimizer“ vyjde 23. října, jeho téma je "CMS" .
Pošlete své otázky a naši specialisté vám odpoví!
Sémantické jádro
1. Jak správně sestavit sémantické jádro pro internetový obchod, existují nějaké zvláštnosti?
Při sestavování sémantického jádra pro internetový obchod byste měli brát nejen vysokofrekvenční dotazy, ale také pokrýt co nejvíce sortiment produktů a aktivně propagovat stránky kategorií a karty produktů.
Proto u takových prostředků dotaz na formulář "Koupit telefon nokia n8 " bude více konverzní a efektivnější než požadavek s vyšší frekvencí formuláře „Koupit telefon“.
K vytvoření sémantického jádra, které přivede návštěvníky na váš web, můžete použít dvě metody: automatickou a manuální.
Automatický výběr požadavků lze provádět pomocí speciálních služeb a programů (například online služba seolib.ru, klíčový sběratel, Slovoeb atd.).
Ruční metoda je dobrá v tom, že požadavky můžete okamžitě vybrat na vstupních stránkách - produktových kartách a kategoriích pomocí schémat výběru:
- „Produkt + další slova“
- „Koupit + produkt + další slova“
- „Prodej + produkt + další slova“
- „Cena + produkt + další slova“
- „Charakteristiky + produkt + další slova“
- „Popis + produkt + další slova“
- „Fotografie + produkt + další slova“ atd.
Současně v sémantickém jádru budeme dostávat nejen komerční, ale i informační požadavky, díky nimž bude náš základní a kotevní seznam přirozenější.
Například pro kategorii produktů „Smartphone Apple iPhone“ v internetovém obchodě mobilní telefony dotazy můžete vyzvednout pomocí jednoduché tabulky v Excelu:
To znamená, že na základě údajů v tabulce jsme vybrali 3 možnosti dotazu pro jednu stránku kategorie smartphonů „Apple iPhone“:
- "Koupit smartphone Apple iPhone 3 4 Gb bílý “
- „Prodám smartphone Apple iPhone 4 8 Gb černý“
- „Popis smartphonu Apple iPhone 5 16 Gb bílý“
2. Jak vybrat sémantické jádro pro regionální zpravodajský web? IT témata.
Vybrat sémantické jádro a pak pro něj psát zprávy je špatný přístup pro jakýkoli zpravodajský web, včetně IT témat.
Primárním úkolem zpravodajského webu je zveřejňovat včasné, zajímavé a relevantní informace o aktuálním dění, informace, které budou dnes čtenáře zajímat. Pouze s tímto přístupem se může stát web oblíbeným, získat důvěru uživatelů a následně i vyhledávačů. Podle tohoto principu přirozeně vytvoříte správné sémantické jádro svého webu. Koneckonců, hlavní témata (žádosti), tak či onak, budou zmíněna ve zprávách vašeho tématu. Pokud máte ještě volný čas, pak je lepší jej strávit zvýšením množství a zlepšením kvality publikovaných materiálů, než přípravou článků na konkrétní požadavky.
3. Měly by nové weby používat v sémantickém jádru vysokofrekvenční dotazy?
Nové weby mohou používat vysokofrekvenční dotazy, ale to závisí na předmětu a úrovni konkurence. Čím vyšší je úroveň konkurence, tím obtížnější (nebo nemožné) je propagovat web, protože vyhledávače upřednostňují staré důvěryhodné zdroje.
Podívejme se například na výsledky v TOP-10 pro dotaz „klimatizace“ (vyhledávač Yandex, region „Moskva“):

U webů, které jsou mladší než dva roky, se doporučuje postupovat pomocí středofrekvenčních a nízkofrekvenčních dotazů. Když je použijete v sémantickém jádru, nebudete plýtvat svým rozpočtem na propagaci a budete schopni přilákat na web cílové publikum. Je střední a nízkofrekvenční dotazy jsou nejvíce konvertující, což vede na stránky potenciálních zákazníků.
4. Jak složit sémantické jádro s velkým počtem klíčů? Na co se zaměřit a čeho v takové situaci zahodit? Očividně není možné pracovat s několika tisíci klíčů.
Neexistuje žádné tajemství - práce je pečlivá a v případě potřeby musíte pracovat s několika tisíci klíči.
Existují způsoby, jak si práci usnadnit. V první fázi výběru dotazů je vhodné používat služby automatického shromažďování statistik nastavením „zastavovacích slov“ a zadáním požadovaných oblastí. Automatická služba eliminuje potřebu ručně zadávat slova do služby wordstat.yandex.ru.
Výsledný seznam požadavků by měl být rozdělen do několika prioritních skupin. Zde samozřejmě vše závisí na vašem konkrétním tématu. Pokud například máte prodejní web, v první řadě potřebujete transakční dotazy jako "Koupit", "cena" atd.
5. Po jaké době stojí za to doplnit a rozšířit sémantické jádro a má vůbec cenu to dělat?
Je možné a nutné rozšířit sémantické jádro. Optimální je to provést po několika měsících propagace, kdy již hlavní fáze proběhla a web zaujal vedoucí pozice alespoň v 70% prvního seznamu požadavků.
Při rozšiřování jádra byste měli vybírat dotazy tak, aby se překrývaly s původním seznamem. V opačném případě, pokud při rozšiřování jádra upravujete text, záhlaví a metaznačky pro určité dotazy pokaždé, vyhledávačům to může připadat nepřirozené a podezřelé a downgradovat web ve výsledcích vyhledávání.
Při rozšiřování sémantického jádra navíc k standardní metody Při sestavování seznamu požadavků se doporučuje použít data od společností Google.Analytics a Yandex.Metrica.
Jak mohou být tyto služby užitečné, si ukážeme na příkladu Yandex.Metrica - přejděte na Yandex.Metrica, najděte záložky „Zdroje“ - „vyhledávací fráze“:

A zobrazí se vám seznam všech požadavků, u kterých došlo k návštěvám webu, s počtem návštěvníků pro každý požadavek:

Z tohoto seznamu vyberte dotazy, které jsou cílené na váš prostředek a nejsou součástí původního sémantického jádra. Poté zkontrolujte pozici webu podle přijatého seznamu a můžete pro začátek přijmout ty žádosti, pro které není web v TOP-10. U zbývajících požadavků můžete pozice pravidelně sledovat a v případě čerpání je utáhnout.
6. Jak při vytváření sémantického jádra určit, které požadavky jsou prioritní a které další?
Chcete -li rozdělit požadavky na prioritní a dodatečné, musíte zvážit, o jaký typ se jedná. Existují tři typy: vysokofrekvenční (HF), nízkofrekvenční (LF) a střední frekvence (MF). VF požadavek je nejpopulárnější požadavek a kolem něj se tvoří méně populární MF a LF. Prioritou tedy bude KV a další - MF a LF. Například požadavek RF - "plastová okna" hlavní dotaz na stránce, střední rozsah dotazu - „Plastová okna v Moskvě“ a žádost LF - další žádosti.
7. Jaká by měla být částka klíčová slova na stránku? Konkrétně v číslech - 3, 10, 15?
Je těžké jednoznačně odpovědět, tk. každá jednotlivá situace vyžaduje jiný přístup. Nejsprávnější je optimalizovat stránku pro jeden vysokofrekvenční požadavek, 2–3 středofrekvenční požadavky a poté-pro nízkofrekvenční požadavky. Logika je jednoduchá - JEDEN hlavní požadavek jde na jednu stránku, kolem které se vše „točí“.
Například, "plastová okna"- RF žádost; „Koupit plastová okna“, "Plastová okna Moskva"- požadavky středního rozsahu; „Koupit plastová okna v Moskvě“- Žádost LF. Bude obtížné propagovat stránku, pokud ji optimalizujete pro požadavky "Tisk loga" a „skleníkový film“. Jedinou výjimkou je „Hlavní“, protože měl by popisovat celou škálu služeb webu.
U dotazů s dalšími slovy jako "Koupit", "velkoobchod", "cena" nedoporučuje se optimalizovat jiné stránky, kromě té, kde je umístěn hlavní, vysokofrekvenční požadavek. Například stránka propagovaná na žádost „plastová okna“, Měl by být propagován a na vyžádání „Koupit plastová okna“.
8. Měl by prodejní web používat v sémantickém jádru žádosti o informace, je tento provoz docela dobrý, nebo stále není potřeba?
Rozhodně to stojí za to. Jak sám píšete, jedná se o dodatečný provoz, který může také vést ke konverzím. Při vytváření informačních sekcí na komerčním webu je důležité dodržovat několik zásad:
- informační materiály by měly být pro uživatele opravdu užitečné, informovat je o důležitých a užitečných informacích. Je třeba připravit vysoce kvalitní publikace, a ne jen zaplnit sekci články „nabroušenými“ pro žádosti;
- nezapomeňte, že váš web je primárně komerční. U většiny témat bude situace, kdy počet informačních článků překročí počet karet produktů, vypadat divně;
- zkuste umístit odkazy na prodejní stránky webu do těla článků. Tím se zvýší účinnost informačního provozu.
9. Jaký je nejúčinnější způsob implementace odkazů pro geograficky závislé dotazy v rámci obsahu chastotniků, tj. Propojit chastotniky stejné úrovně nebo je propojit s různými chastotniky LF-HF?
Pokud chápeme, otázka se týká interního propojení.
Existuje velké množství propojovacích strategií, ale nedoporučovali bychom „vázané“ na koncepci četnosti požadavků. Je důležité, aby propojení bylo užitečné. Pokud je použit odkaz uvnitř obsahu, pomůže to. Pokud je odkaz „mrtvý“ a není použit, bude z něj pravděpodobně mít malý smysl. A nezáleží na tom, zda odkazujete ze stránky požadavku LF na stránku požadavku KV nebo naopak.
U nízkofrekvenčních dotazů je účinek interního propojení samozřejmě výraznější, protože jsou méně „náročné“ než vysokofrekvenční dotazy s vysokou konkurencí. Ale znovu opakujeme, že touha „držet se“ konkrétního propojovacího algoritmu, aniž bychom přemýšleli o tom, jak moc uživatel propojení potřebuje, nejenže nepomůže, ale také může uškodit. Vyhledávače nemají rády odkazy na spam.
10. Vytvořili pro mě sémantické jádro se zaměřením na Yandex, přestože mám ukrajinské stránky a většina návštěvníků pochází z Googlu. Je toto jádro vhodné pro Google (myslím, že uživatelé Yandexu a Googlu mají podobné dotazy), nebo potřebujete udělat nový?
V dotazech mezi uživateli Yandex a Google obvykle neexistují žádné významné rozdíly. Pokud výběr zohlednil region (ve vašem případě - „Ukrajina“), neměly by být žádné problémy.
U některých témat může být region důležitý (můžete si vybrat při analýze dotazů v Yandex Wordstat). Rozdíly mohou být způsobeny například rozdíly v legislativě nebo oblíbenosti některých výrobců. V takovém případě se musíte podívat na své téma. Pokud neexistují žádné regionální rozdíly, můžete vybrané jádro bezpečně použít jako základní.
11. Moje stránka je propagována dotazem „velbloudi“ a pro toto slovo je v TOP 3. Ale pro slovo „velbloud“ není ani v TOP 30. Proč to může být? Má použití množného nebo jednotného čísla v klíčovém slově vliv na pozici webu?
Ano, v mnoha případech ano. Výsledky vyhledávání na Yandexu pro množné číslo a jednotné číslo se mohou výrazně lišit, což znamená, že tyto dotazy vnímá odlišně. Kromě toho je podstatný rozdíl ve frekvenci požadavků. Pokud se například podíváte na požadavky yandex.wordstat.ru (Moskva) "! plastové okno" a "! plastová okna", pak bude první frekvence 7650 a druhá - 169315. V souladu s tím bude výstup zcela odlišný, protože to jsou zjevně různé požadavky. Dávejte si pozor na to, pro které slovo stránku optimalizovat, protože pokud zvolíte špatný formulář, přijdete o provoz.
12. Ve svých komerčních návrzích mnoho propagačních firem sestaví tabulku se sémantickým jádrem a denními náklady na každou frázi za umístění na 1-3, 4-6, 7-10 pozicích v Yandex, Google. Jak se tento rozpočet vypočítává?
Otázka je poměrně komplikovaná, protože každá společnost může mít své vlastní koeficienty a je nerozumné hovořit o všech společnostech.
Náklady na požadavek se obvykle vypočítávají na základě jeho složitosti (jinými slovy, kolik času zaměstnanec věnuje tomuto požadavku nebo skupině požadavků) a požadovaného objemu referenční hmotnosti. Kromě toho byste měli vzít v úvahu celkový počet propagovaných požadavků (čím více požadavků, tím levnější každý z nich, protože celková hmotnost odkazu na webu bude větší).
13. Otázka zní následovně. Mám doménu (ru) zakoupenou před 1,5 rokem. Když jsem na něm vytvořil web, příliš jsem o sestavení sémantického jádra nepřemýšlel (lékařská témata, 40 stránek v rejstříku, žádní návštěvníci). Chtěl jsem se zeptat - pokud na této doméně začnu vytvářet nový web (jiného tématu), již s kompilací sémantického jádra atd., Jak budou na tyto kroky reagovat vyhledávače, jak bude indexováno, po jakém období dojde ke změnám? Nebo je lepší vytvořit na nové doméně web jiného tématu a zapomenout na ten starý (ru)?
Pokud na aktuálním webu nejsou použity žádné filtry a doména je vhodná pro vaše další téma (pamatujte, že by mělo být pro uživatele zapamatovatelné a odrážet vaše aktivity), neměly by nastat žádné problémy.
Vyhledávače však mohou být „ostražité“ ohledně úplné změny stránek stejného vlastníka, protože náhlá změna předmětu vypadá nelogicky. Nejčastěji prudce mění téma stránek určených k prodeji odkazů atd.
Dalším bodem, před kterým chceme varovat, je vytvoření webu pro stávající sémantické jádro. Nejprve musíte vytvořit koncept webu, porozumět tomu, co můžete dát svým uživatelům, definovat vaši jedinečnou nabídku a po vytvoření webu vybrat ty požadavky, podle kterých k vám mohou cíloví návštěvníci jít.
Je těžké pojmenovat reindexační období, můžete se soustředit zhruba na měsíc a půl.
Předchozí čísla podváděcího listu Optimalizátoru:
PROTI tento moment Pro optimalizaci pro vyhledávače hrají nejdůležitější roli faktory, jako je obsah a struktura. Jak však porozumět tomu, o čem psát text, jaké sekce a stránky na webu vytvářet? Kromě toho musíte přesně zjistit, co cílového návštěvníka vašeho zdroje zajímá. Chcete -li odpovědět na všechny tyto otázky, musíte vybudovat sémantické jádro.
Sémantické jádro- seznam slov nebo frází, které plně odrážejí téma vašeho webu.
V tomto článku vám řeknu, jak jej vyzvednout, vyčistit a rozložit na strukturu. Výsledkem bude kompletní struktura s dotazy seskupenými podle stránky.
Zde je příklad dotazovacího stroje rozděleného do struktury:

Shlukováním mám na mysli rozdělení vašich vyhledávacích dotazů na samostatné stránky. Tato metoda bude relevantní pro propagaci Yandex i Google PS. V článku popíšu zcela bezplatný způsob vytváření sémantického jádra, ale ukážu také možnosti s různými placenými službami.
Po přečtení článku se naučíte
- Vyberte si správné dotazy pro své téma
- Sbírejte nejúplnější jádro frází
- Vyčistěte nezajímavé dotazy
- Seskupte a vytvořte strukturu
Po shromáždění sémantického jádra můžete
- Vytvořte na webu smysluplnou strukturu
- Vytvořit vrstvené menu
- Naplňte stránky texty a napište na ně meta popisy a názvy
- Sbírejte pozici svého webu pro dotazy z vyhledávačů
Shromažďování a seskupování sémantického jádra
Správný návrh pro Google a Yandex začíná identifikací hlavních klíčových frází pro vaše téma. Jako příklad předvedu jeho kompilaci na fiktivním internetovém obchodě s oblečením. Sémantické jádro lze sbírat třemi způsoby:
- Manuál. Pomocí služby Yandex Wordstat zadáváte klíčová slova a ručně vybíráte fráze, které potřebujete. Tato metoda je dostatečně rychlá, pokud potřebujete sbírat klíče na jedné stránce, ale existují dvě nevýhody.
- Přesnost metody je „chromá“. Pokud použijete tuto metodu, můžete vždy přijít o důležitá slova.
- Sémantické jádro nebudete moci sbírat pro velký internetový obchod, i když pro jednoduchost můžete použít plugin Yandex Wordstat Assistant - tím se problém nevyřeší.
- Poloautomatický. V této metodě předpokládám použití programu pro kompilaci jádra a další ruční rozdělení do sekcí, podsekcí, stránek atd. Tato metoda kompilace a shlukování sémantického jádra je podle mého názoru nejefektivnější, protože má řadu výhod:
- Maximální pokrytí všech témat.
- Kvalitativní členění
- Auto. V současné době existuje několik služeb, které nabízejí plně automatické shromažďování jádra nebo seskupování vašich požadavků. Plně automatická možnost - nedoporučuji používat, protože kvalita sběru a shlukování sémantického jádra je v současné době dosti nízká. Automatické shlukování požadavků - získává na popularitě a probíhá, ale přesto musíte některé stránky kombinovat ručně, protože systém neposkytuje dokonalé řešení na klíč. A podle mě se jednoduše zamotáte a nebudete se moci do projektu ponořit.
Ke kompilaci a seskupení plnohodnotného správného sémantického jádra pro jakýkoli projekt v 90% případů používám poloautomatickou metodu.
Abychom tedy mohli provést následující kroky:
- Výběr dotazů pro témata
- Sběr jádra na vyžádání
- Vyčištění nevhodných požadavků
- Shlukování (lámání frází do struktury)
Ukázal jsem příklad výběru sémantického jádra a seskupení do struktury výše. Připomínám, že máme internetový obchod s oblečením, začneme třídit 1 položku.
1. Výběr frází pro vaše téma
V této fázi potřebujeme nástroj Yandex Wordstat, vaši konkurenty a logiku. V tomto kroku je důležité shromáždit seznam frází, které jsou tematickými vysokofrekvenčními dotazy.
Jak vybírat dotazy ke shromažďování sémantiky pomocí Yandex Wordstat
Přejděte na službu, vyberte požadovaná města / oblasti, zadejte podle svého názoru „nejtučnější“ dotazy a podívejte se do pravého sloupce. Najdete tam potřebná tematická slova, jak pro ostatní sekce, tak frekvenční synonyma pro zapsanou frázi.

Jak vybírat dotazy před kompilací sémantického jádra s pomocí konkurentů
Zadejte do vyhledávače nejoblíbenější dotazy a vyberte jeden z nejoblíbenějších webů, z nichž mnohé již pravděpodobně znáte.

Věnujte pozornost hlavním částem a uložte si fráze, které potřebujete.
V této fázi je důležité udělat to správně: pokrýt všechny druhy slov z vašeho předmětu co nejvíce a nic nepropásnout, pak bude vaše sémantické jádro co nejúplnější.
Pro náš příklad musíme uvést následující fráze / klíčová slova:
- oblečení
- Obuv
- Boty
- Šaty
- Trička
- Spodní prádlo
- Šortky
Jaké fráze nemají smysl psát: dámské oblečení, koupit boty, plesové šaty atd. Proč?- Tyto fráze jsou „ocasy“ dotazů „oblečení“, „boty“, „šaty“ a budou automaticky přidány do sémantického jádra ve 2. fázi sběru. Tito. můžete je přidat, ale to by byla zbytečná dvojitá práce.
Jaké klíče musím zadat?„Kotníkové boty“, „kozačky“ nejsou totéž co „kozačky“. Důležitá je forma slova, a ne to, zda jsou tato slova kořenová nebo ne.
Někdo bude mít dlouhý seznam klíčových frází, ale ti, kteří ho mají, se skládají z jednoho slova - nelekejte se. Například pro online obchod dveří, který skládá sémantické jádro, je slovo „dveře“ docela možné.
A tak na konci tohoto kroku bychom měli mít podobný seznam.

2. Shromažďování dotazů na sémantické jádro
Pro správný plnohodnotný sběr potřebujeme program. Ukážu příklad současně na dvou programech:
- Placené - KeyCollector. Pro ty, kteří mají nebo kteří chtějí koupit.
- Zdarma - Slovoeb. Bezplatný program pro ty, kteří nejsou připraveni utratit peníze.
Otevření programu

Tvoříme nový projekt a říkejme tomu například Mysite

Nyní, abychom dále sbírali sémantické jádro, musíme udělat několik věcí:
Vytvořte nový účet na poště Yandex (starý se nedoporučuje, protože jej lze zakázat pro mnoho požadavků). Vytvořili jste si například účet [chráněno emailem] s heslem super2018. Nyní musíte tento účet zadat v nastavení jako ivan.ivanov: super2018 a níže kliknout na tlačítko „uložit změny“. Další podrobnosti viz screenshoty.

Výběr oblasti pro kompilaci sémantického jádra. Musíte vybrat pouze ty oblasti, ve kterých se chystáte propagovat, a kliknout na Uložit. Četnost požadavků bude záviset na tom a na tom, zda budou v zásadě shromažďovány.

Všechna nastavení jsou dokončena, zbývá přidat náš seznam klíčových frází připravených v prvním kroku a stisknout tlačítko „začít sbírat“ sémantické jádro.

Proces je zcela automatický a dostatečně dlouhý. Kávu si zatím můžete uvařit, ale pokud je téma široké, například jako to, které sbíráme, pak je to na pár hodin 😉
Jakmile jsou shromážděny všechny fráze, uvidíte něco takového:

A v této fázi je fáze u konce - pokračujeme k dalšímu kroku.
3. Vyčištění sémantického jádra
Nejprve musíme odstranit požadavky, které nás nezajímají (necílené):
- Souvisí s jinou značkou, jako jsou džíny gloria, ecco
- Informační dotazy, například „nosím boty“, „velikost džínů“
- Předmět je podobný, ale nesouvisí s vaším podnikáním, například „použité oblečení“, „velkoobchodní oblečení“
- Požadavky, které nijak nesouvisí s tématem, například „sims dress“, „puss in boots“ (takových požadavků je po výběru sémantického jádra docela dost)
- Požadavky z jiných regionů, metra, okresů, ulic (nezáleží na tom, pro který region jste požadavky shromáždili - jiný region stále narazí)
Čištění je třeba provést ručně následujícím způsobem:

Zadáme slovo, stiskneme „Enter“, pokud v našem vytvořeném sémantickém jádru najde přesně ty fráze, které potřebujeme, vyberte nalezené a stiskněte smazat.
Doporučuji zadat slovo ne úplně, ale použít konstrukci bez předložek a koncovek, tzn. napíšeme -li slovo „sláva“, najdeme fráze „kup si džíny u glorie“ a „kup si džíny u glorie“. Pokud napíšete „gloria“ - „gloria“ by nebyla nalezena.
Proto musíte projít všechny body a odstranit nepotřebné dotazy ze sémantického jádra. Může to trvat značnou dobu a nakonec můžete většinu shromážděných dotazů smazat, ale výsledkem je úplný čistý a správný seznam všech druhů propagovaných dotazů pro váš web.
Nahrajte nyní všechny své dotazy, aby vynikly

Můžete také masivně odebrat necílové dotazy ze sémantiky za předpokladu, že máte seznam. Můžete to udělat pomocí stop slov a je to snadné pro typickou skupinu slov s městy, metrem, ulicemi. Seznam takových slov, která používám, si můžete stáhnout v dolní části stránky.
4. Shlukování sémantického jádra
Toto je nejdůležitější a nejzajímavější část - je nutné rozdělit naše požadavky na stránky a sekce, které společně vytvoří strukturu vašeho webu. Trochu teorie - čím by se mělo řídit rozdělení požadavků:
- Konkurenti... Můžete věnovat pozornost tomu, jak je seskupeno sémantické jádro vašich konkurentů z TOP a dělat totéž, alespoň u hlavních sekcí. A také se podívejte, které stránky jsou v SERP pro nízkofrekvenční dotazy. Pokud si například nejste jisti „udělat nebo neudělat“ samostatnou sekci pro dotaz „červené kožené sukně“, zadejte frázi do vyhledávače a podívejte se na výsledky. Pokud SERP obsahuje prostředky s takovými sekcemi, pak má smysl vytvořit samostatnou stránku.
- Logika... Proveďte celé seskupení sémantického jádra pomocí logiky: struktura by měla být jasná a v hlavě by vám měl představovat strukturovaný strom stránek s kategoriemi a podkategoriemi.
A ještě pár tipů:
- Nedoporučuje se podávat méně než 3 požadavky na stránku.
- Nevytvářejte příliš mnoho úrovní vnoření, snažte se je udržet 3-4 (site.ru / category / subcategory / sub-sub-subcategory)
- Nedělejte dlouhé adresy URL, pokud máte mnoho úrovní vnoření při klastrování sémantického jádra, zkuste zkrátit URL vyšších kategorií v hierarchii, tj. místo „vash-site.ru/zhenskaya-odezhda/palto-dlya-zhenshin/krasnoe-palto“ udělejte „vash-site.ru/zhenshinam/palto/krasnoe“
Nyní cvičit
Klastrování jádra příkladem
Nejprve seřaďme všechny požadavky do hlavních kategorií. Při pohledu na logiku konkurentů budou hlavními kategoriemi obchodu s oděvy: pánské oděvy, dámské oděvy, dětské oděvy a řada dalších kategorií, které nejsou vázány na pohlaví / věk, například jednoduše „boty“, „Svrchní oděvy“.
Seskupíme sémantické jádro s tímto Excel pomoc... Otevřete náš soubor a pokračujte:
- Rozdělujeme na hlavní části
- Vezmeme jednu sekci a rozdělíme ji na podsekce
Ukážu na příkladu jedné sekce - pánské oblečení a jeho podsekce. Chcete-li oddělit některé klíče od ostatních, musíte vybrat celý list a kliknout na podmíněné formátování-> pravidla pro výběr buněk-> text obsahuje

Nyní do okna, které se otevře, napište „manžel“ a stiskněte Enter.

Všechny naše pánské klíče jsou nyní zvýrazněny. Stačí použít filtr k oddělení vybraných klíčů od zbytku našeho sestaveného sémantického jádra.
Zapneme tedy filtr: je třeba vybrat sloupec s dotazy a kliknout na řazení a filtr-> filtr

A teď pojďme třídit

Vytvořte samostatný list. Vystřihněte vybrané řádky a vložte je tam. Tímto způsobem budete muset jádro dále rozdělit.
Změňte název tohoto listu na „Pánské oblečení“, což je list, kde celý zbytek sémantického jádra pojmenuje „Všechny dotazy“. Poté vytvořte další list, pojmenujte jej „Struktura“ a vložte jej jako první. Na stránce osnovy vytvořte strom. Měli byste dostat něco takového:

Nyní musíme rozdělit velkou část pánského oblečení na podsekce a podsekce.
Pro snadné použití a procházení seskupeným sémantickým jádrem vložte odkazy ze struktury na odpovídající listy. Chcete-li to provést, klepněte pravým tlačítkem myši na požadovanou položku ve struktuře a proveďte postup jako na snímku obrazovky.

A teď musíte metodicky oddělit požadavky rukama a současně vymazat to, čeho si možná nebylo možné všimnout, a odstranit ve fázi čištění jádra. Seskupením sémantického jádra byste nakonec měli skončit se strukturou podobnou této:


Tak. Co jsme se naučili dělat:
- Vyberte dotazy, které potřebujeme ke shromažďování sémantického jádra
- Shromážděte všechny možné fráze pro tyto požadavky
- Čištění od „odpadků“
- Seskupit a vytvořit strukturu
Co můžete udělat dále vytvořením takového seskupeného sémantického jádra:
- Vytvořte strukturu na webu
- Vytvořit nabídku
- Pište texty, meta popisy, názvy
- Sbírejte pozice a sledujte dynamiku na vyžádání
Nyní trochu o programech a službách
Software pro sémantický sběr jádra
Zde popíšu nejen programy, ale také pluginy a online služby, které používám
- Yandex Wordstat Assistant je plugin, který usnadňuje výběr dotazů z Wordstatu. Skvělé pro rychlé sestavení jádra pro malý web nebo 1 stránku.
- Klíčový sběratel (slovo - bezplatná verze) Je kompletní program pro klastrování a vytváření sémantického jádra. Je velmi populární. Kromě hlavní oblasti obrovské množství funkcí: výběr klíčů z mnoha dalších systémů, možnost automatického klastrování, shromažďování pozic na Yandexu a Googlu a mnoho dalšího.
- Just-magic je multifunkční online služba pro základní kompilaci, automatické rozdělování, kontrolu kvality textu a další funkce. Tato služba je shareware, pro plnohodnotnou práci musíte zaplatit předplatné.
Děkujeme za přečtení článku. Díky této příručce krok za krokem budete moci sestavit sémantické jádro svého webu pro propagaci na Yandexu a Googlu. Pokud máte ještě nějaké otázky - zeptejte se v komentářích. Níže jsou uvedeny bonusy.
Sémantické jádro je docela hacknuté téma, že? Dnes to společně napravíme sestavením sémantiky v tomto tutoriálu!
Nevěříš mi? - přesvědčte se sami - stačí jen sémantické jádro webu nahnat do Yandexu nebo Googlu. Myslím, že dnes tuto nepříjemnou chybu napravím.
Ale ve skutečnosti, co je pro tebe - dokonalá sémantika? Můžete si myslet, že je to hloupá otázka, ale ve skutečnosti to ani není hloupost, jde jen o to, že většina webmasterů a majitelů stránek pevně věří, že mohou skládat sémantická jádra a že se s tímto vším dokáže vyrovnat každý školák. a sami se snaží naučit ostatní ... Ale ve skutečnosti je všechno mnohem komplikovanější. Jakmile se mě někdo zeptal - co mám udělat jako první? - samotný web a obsah, příp sem jádro, a zeptal se muže, který se nepovažuje za nováčka v SEO. Tady tato otázka a přiměl mě pochopit složitost a nejednoznačnost tohoto problému.
Sémantické jádro je základem základů - úplně první krok, který předchází a spouští jakýkoli reklamní kampaň na internetu. Spolu s tím je sémantika webu nejtrapnějším procesem, který zabere spoustu času, ale v každém případě se vyplatí s úrokem.
No ... pojďme tvořit jeho spolu!
Malá předmluva
K vytvoření sémantického pole webu potřebujeme jeden a jediný program - Sběratel klíčů... Na příkladu Collector rozeberu příklad sběru malé skupiny seme. Navíc placený program, existují bezplatné analogy jako SlovoEb a další.
Sémantika se shromažďuje v několika základních fázích, z nichž je třeba zdůraznit:
- brainstorming - analýza základních frází a příprava analýzy
- parsing - rozšíření základní sémantiky založené na Wordstatu a dalších zdrojích
- dropout - výpadek po analýze
- analýza - analýza četnosti, sezónnosti, konkurence a dalších důležitých ukazatelů
- revize - seskupení, oddělení komerčních a informačních frází jádra
O většině důležité milníky sbírka a budou probrány níže!
VIDEO - sestavení sémantického jádra pro konkurenty
Sémantické jádro brainstormingu - namáhání mozků
V této fázi je to nutné provést výběr na mysli sémantické jádro webu a vymyslete pro naše téma co nejvíce frází. Spustíme tedy sběratel klíčů a vybereme analyzovat Wordstat jak ukazuje snímek obrazovky:

Před námi se otevře malé okno, kde je nutné zadat maximum frází na naše téma. Jak jsem již řekl, v tomto článku vytvoříme ukázkovou sadu frází pro tento blog fráze tedy mohou být následující:
- seo blog
- SEO blog
- blog o SEO
- blog o seo
- povýšení
- povýšení projekt
- povýšení
- povýšení
- propagace blogu
- propagace blogu
- propagace blogů
- propagace blogu
- propagace články
- propagace článku
- miralinks
- pracovat v sape
- nákup odkazů
- nákup odkazů
- optimalizace
- optimalizace stránky
- vnitřní optimalizace
- vlastní propagace
- jak propagovat zdroj
- jak propagovat vaše stránky
- jak sami propagovat web
- jak sami propagovat webové stránky
- vlastní propagace
- bezplatná propagace
- bezplatná propagace
- optimalizace pro vyhledávače
- jak propagovat web v Yandexu
- jak propagovat web v Yandexu
- propagace pod Yandexem
- Propagace Google
- Propagace Google
- indexování
- zrychlení indexování
- výběr dárce pro web
- screening dárců
- propagace stráží
- používání stráží
- propagace blogu
- Algoritmus Yandex
- aktualizovat tic
- aktualizace základny vyhledávání
- Aktualizace Yandex
- odkazy navždy
- věčné odkazy
- odkaz nájem
- pronajatý odkaz
- odkazy na měsíční platby
- kompilace sémantického jádra
- propagační tajemství
- propagační tajemství
- seo tajemství
- tajemství optimalizace
Myslím, že to stačí, a tak je seznam půl stránky;) Obecně platí, že v první fázi musíte co nejvíce analyzovat své odvětví a vybrat co nejvíce frází, které odrážejí téma webu. . Pokud vám však v této fázi něco chybělo - nezoufejte - chybějící fráze se jistě objeví v dalších fázích„Musíte udělat spoustu práce navíc, ale to je v pořádku. Vezmeme náš seznam a zkopírujeme ho do sběratele klíčů. Dále klikněte na tlačítko - Analyzovat z Yandex.Wordstat:
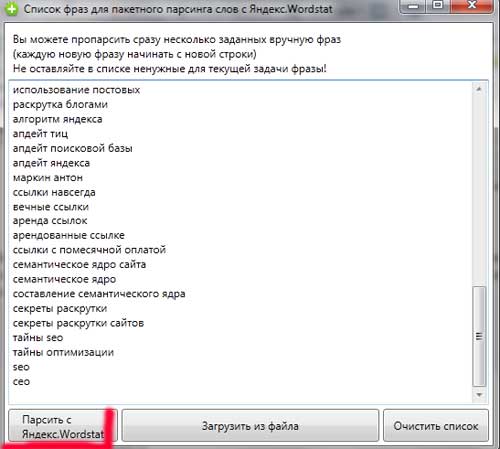
Analýza může trvat docela dlouho, takže buďte trpěliví. Sémantické jádro obvykle trvá 3–5 dní a první den vám zabere přípravu základního sémantického jádra a rozebrání.
Napsal jsem podrobný návod, jak pracovat se zdrojem, jak vybírat klíčová slova. A můžete se dozvědět o propagaci webových stránek pro žádosti o nízkou frekvenci.
Navíc řeknu, že místo brainstormingu můžeme využít hotovou sémantiku konkurentů využívajících některou ze specializovaných služeb, například SpyWords. V rozhraní této služby jednoduše zadáme klíčové slovo, které potřebujeme, a uvidíme hlavní konkurenty, kteří jsou pro tuto frázi přítomni, v TOP. Pomocí této služby lze navíc zcela uvolnit sémantiku webových stránek jakéhokoli konkurenta.

Dále můžeme vybrat kterékoli z nich a vytáhnout jeho požadavky, které zůstanou odstraněny z odpadu a použity jako základní sémantika pro další analýzu. Nebo to můžeme udělat ještě jednodušeji a použít to.
Vyčištění sémantiky
Jakmile se analýza Wordstatu úplně zastaví - je čas vykořenit sémantické jádro... Tato fáze je velmi důležitá, proto jí věnujte náležitou pozornost.
Moje analýza skončila, ale fráze se ukázaly Tolik, a proto nám třídění slov může vzít více času. Proto než přejdete k definici frekvence, měli byste provést primární čištění slov. Uděláme to v několika fázích:
1. Odfiltrujte dotazy s velmi nízkými frekvencemi
Za tímto účelem vyděláme peníze za třídění podle frekvence a začneme uklízet všechny požadavky s frekvencemi pod 30:
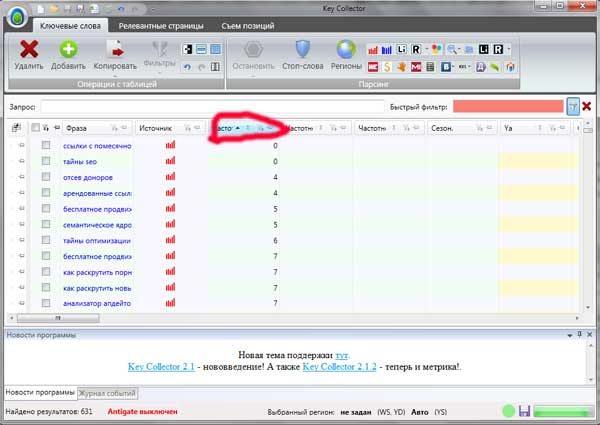
Myslím, že s tímto bodem se můžete snadno vyrovnat.
2. Odstraňme nevhodné dotazy
Existují požadavky, které mají dostatečnou frekvenci a nízkou konkurenci, ale oni vůbec nezapadají do našeho tématu... Takové klíče musí být odstraněny před kontrolou přesného výskytu klíče. ověření může být velmi časově náročné. Ručně takové klíče odstraníme. Pro můj blog se tedy ukázalo jako nadbytečné následující:
kurzy optimalizace pro vyhledávače prodej propagovaného webu
Sémantická základní analýza
V této fázi musíme určit přesné frekvence našich kláves, pro které musíte kliknout na symbol lupy, jak je znázorněno na obrázku:

Tento proces je poměrně dlouhý, takže si můžete jít udělat čaj)
Když je kontrola úspěšná, musíte pokračovat v čištění našeho jádra.
Doporučuji odstranit všechny klíče s frekvencí méně než 10 požadavků. Také pro svůj blog smažu všechny žádosti s hodnotami nad 1 000, protože zatím neplánuji na takové žádosti pokročit.
Export a seskupení sémantického jádra
Nemyslete si, že tato fáze bude poslední. Vůbec ne! Nyní musíme výslednou skupinu pro maximální přehlednost přenést do Exelu. Dále budeme třídit podle stránek a poté uvidíme mnoho nedostatků a opravíme je.
Export sémantiky webu do Excelu není obtížné. Chcete -li to provést, stačí kliknout na odpovídající symbol, jak je znázorněno na obrázku:
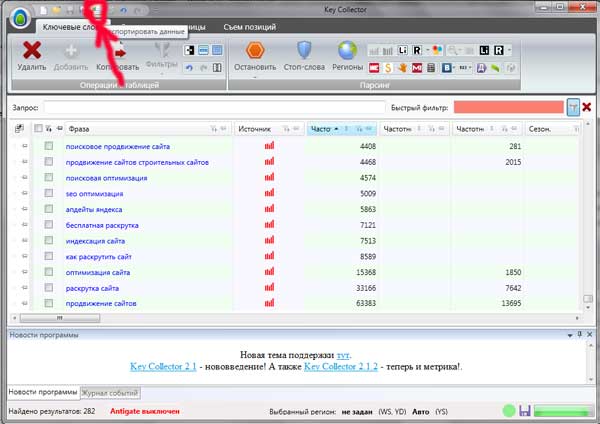
Po vložení do Exelu se nám zobrazí následující obrázek:

Sloupce označené červeně je třeba odstranit. Poté v Exelu vytvoříme další tabulku, která bude obsahovat konečné sémantické jádro.
Nová tabulka bude mít 3 sloupce: Urlstránek, klíčová fráze a jeho frekvence... Jako adresu URL vyberte buď existující stránku, nebo stránku, která bude vytvořena v perspektivě. Nejprve vybereme klíče pro domovskou stránku mého blogu:

Po všech těch manipulacích vidíme následující obrázek. A hned několik závěrů se naznačuje:
- časté dotazy, jako jsou tyto, by měly mít mnohem větší ocas z méně častých frází, než vidíme
- seo novinky
- objevil se nový klíč, který jsme dříve nebrali v úvahu - SEO články... Tento klíč je třeba analyzovat
Jak jsem řekl, ani jeden klíč se před námi nemůže skrývat. Dalším krokem pro nás je brainstorming těchto tří frází. Po brainstormingu zopakujte všechny kroky od prvního bodu pro tyto klávesy. Možná si myslíte, že je to všechno příliš dlouhé a únavné, ale je to tak - sestavení sémantického jádra je velmi zodpovědná a pečlivá práce. Na druhou stranu dobře navržené toto pole výrazně pomůže při propagaci webových stránek a může výrazně ušetřit váš rozpočet.
Po provedení všech operací jsme mohli získat nové klíče pro hlavní stránku tohoto blogu:
- nejlepší seo blog
- seo novinky
- seo články
A někteří další. Myslím, že tato technika je vám jasná.
Po všech těchto manipulacích uvidíme, které stránky našeho projektu je třeba změnit () a které nové stránky přidat. Většinu klíčů, které jsme našli (s frekvencí až 100 a někdy i mnohem vyšší) lze snadno propagovat samostatně.
Konečné vyřazení
V zásadě je sémantické jádro téměř připravené, ale je tu spíše jiné důležitý bod, což nám pomůže výrazně zlepšit naši sem skupinu. K tomu potřebujeme Seopult.
* Ve skutečnosti zde můžete použít kteroukoli z podobných služeb, které vám umožní zjistit konkurenci podle klíčových slov, například Mutagen!
V Exelu tedy vytvoříme další tabulku a zkopírujeme tam pouze názvy klíčů (prostřední sloupec). Abych neztrácel spoustu času, zkopíruji pouze klíče pro hlavní stránku svého blogu:


Poté zkontrolujeme náklady na jedno kliknutí na naše klíčová slova:
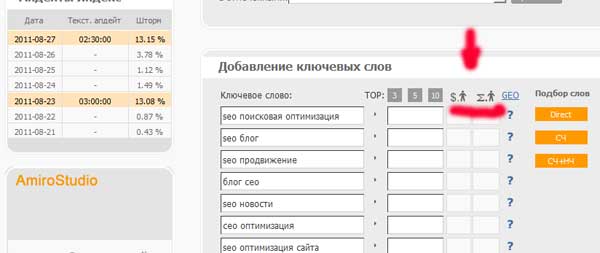
Náklady na přechod u některých frází přesáhly 5 rublů. Takové fráze musí být z našeho jádra vyloučeny.

Možná se vaše preference budou poněkud lišit, pak můžete vyloučit méně nákladné fráze nebo naopak. V mém případě jsem smazal 7 frází.
Užitečné informace!
na sestavení sémantického jádra s důrazem na prozkoumání klíčových slov s nejnižší konkurencí.
Pokud máte vlastní internetový obchod - číst pro popis toho, jak lze sémantické jádro použít.
Sémantické seskupování jader
Jsem si jist, že jste toto slovo v souvislosti s propagací vyhledávačů již slyšeli. Pojďme zjistit, o jaké zvíře se jedná a proč je při propagaci webové stránky potřeba.
Klasický model propagace vyhledávače vypadá takto:
- Výběr a analýza vyhledávacích dotazů
- Seskupování požadavků podle stránek (vytváření vstupních stránek)
- Příprava seo textů pro vstupní stránky na základě skupiny požadavků na tyto stránky
K usnadnění a vylepšení druhé fáze ve výše uvedeném seznamu slouží klastrování. V jádru je clustering softwarová metoda, která slouží ke zjednodušení této fáze při práci s velkou sémantikou, ale vše není tak jednoduché, jak by se na první pohled mohlo zdát.
Pro lepší pochopení teorie shlukování by měl být proveden malý exkurz do historie SEO:
Jen před několika lety, kdy termín shlukování nevypadal ze všech koutů, SEO v drtivé většině případů seskupovaly sémantiku ručně. Ale když byla obrovská sémantika seskupena do 1000, 10 000 a dokonce 100 000 dotazů, tento postup se pro běžného člověka stal skutečnou těžkou prací. A pak se všude začala používat metoda seskupování podle sémantiky (a dnes tento přístup používá mnoho lidí). Metoda seskupování podle sémantiky znamená kombinování dotazů, které mají sémantickou afinitu, do jedné skupiny. Jako příklad - žádosti „koupit pračka“A„ kupte si pračku do 10 000 “byly sloučeny do jedné skupiny. A všechno by bylo v pořádku, ale tuto metodu obsahuje řadu kritických problémů a pro jejich pochopení je nutné do našeho vyprávění zavést nový termín, a to - „ požadovat záměr”.
Nejjednodušší způsob, jak popsat tento výraz, může být potřeba uživatele, jeho touha. Účelem není nic jiného než touha uživatele zadávajícího vyhledávací dotaz.
Základem pro seskupování sémantiky je shromažďovat dotazy, které mají stejný záměr, nebo co nejblíže, do jedné skupiny, a zde se najednou objeví 2 zajímavé funkce, a to:
- Stejný záměr může mít několik dotazů, které nemají žádnou sémantickou blízkost, například - „údržba auta“ a „přihlášení k údržbě“
- Dotazy, které mají absolutní sémantickou podobnost, mohou obsahovat radikálně odlišné záměry, například situace v učebnicích - „mobilní telefon“ a „mobilní telefon“. V jednom případě chce uživatel koupit telefon a v druhém sledovat film
Seskupení sémantiky podle sémantické shody tedy v žádném případě nebere v úvahu záměry požadavků. A takto složené skupiny vám nedovolí napsat text, který se dostane na TOP. V době ručního seskupování, aby se odstranilo toto nedorozumění, kluci s profesí „stoupenec“ Specialista na SEO»Problém jsme analyzovali ručně.
Podstatou shlukování je porovnávání generovaných výsledků vyhledávače při hledání vzorů. Z této definice byste si měli okamžitě poznamenat, že klastrování samo o sobě není konečnou pravdou, protože vygenerovaný problém nemusí zcela odhalit záměr (databáze Yandex jednoduše nemá web, který správně kombinuje požadavky do skupiny).
Mechanika klastrování je jednoduchá a vypadá takto:
- Systém postupně zadává všechny požadavky, které mu byly předloženy Výsledky vyhledávání a pamatuje si výsledky z TOP
- Po zadávání dotazů jeden po druhém a uložení výsledků systém hledá průsečíky ve výstupu. Pokud je stejný web se stejným dokumentem (stránkou) v TOP pro několik dotazů najednou, pak lze tyto dotazy teoreticky spojit do jedné skupiny
- Relevantní je parametr, jako je síla seskupení, který systému přesně říká, kolik průsečíků musí být, aby mohly být dotazy přidány do jedné skupiny. Síla seskupení 2 například znamená, že ve výsledcích musí být alespoň dva průsečíky pro 2 různé dotazy. Aby to bylo ještě jednodušší - u jednoho a druhého požadavku musí být současně v TOPku alespoň dvě stránky dvou různých webů. Viz příklad níže.
- Při seskupování velké sémantiky nabývá na významu logika spojení mezi požadavky, na základě kterých se rozlišují 3 základní typy shlukování: měkký, střední a tvrdý. O typech shlukování si povíme v následujících záznamech tohoto deníku.
Jak správně poskládat informační složku webu, aby ji zákazníci rychle našli
Rozhodli jste se tedy vytvořit portál, kde by lidé mohli najít zajímavé informace, ale víte, že propagace vyžaduje určité dovednosti, konkrétně sestavení sémantického jádra. Sémantika ale předpokládá, že stránka bude naplněna významem. Proto zde budu hovořit o tom, jak zabít dvě mouchy jednou ranou - a přilákat publikum k užitečným informacím, a nenechat vyhledávače „nadávat“.Starý a nový přístup k naplnění webu informacemi a sémantickým jádrem
Při vytváření webové stránky musíte v první řadě vědět, co uživatele zajímá a jak vyhledávají informace - ostatně stejná data lze najít různými způsoby. A je také nutné vzít v úvahu zájmy uživatele - koneckonců, protože všechny informace, které budou na vašem webu prezentovány, by měly zajímat každého čtenáře, pak je třeba lidi ke čtení přitahovat. A bez vyhledávačů se neobejdeme - Yandex a Google prostě portál „nepřijmou“ za svůj, pokud není splněna řada podmínek.Zejména rozházením klíčových slov, která tvoří hledanou frázi, po celém portálu. Proto je důležité vyplnit text sémantickou zátěží. Nejde o nic jiného než o sémantické (sémantické) jádro - kombinaci slov a frází, které odrážejí tematické zaměření a strukturu internetového zdroje. Sémantika je obecně oddělení lingvistiky, které zkoumá sémantický obsah jednotek (prvků) jazyka. Každý pravděpodobně na stránkách viděl takové výrazy jako „Hlavní postava pomáhá svým přátelům sledovat filmy online, aby se nestali oběťmi padoucha“ (přibližná fráze, podstata, doufám, je jasná). Zde uživatel jasně vidí, že existuje klíčové slovo „sledovat filmy online“, ale nebylo to provedeno pro něj, ale pro vyhledávač. V důsledku toho se může cítit oklamán - k tomu není třeba sklouzávat, nic dobrého to nepřinese. Kompetentní text se zavedením sémantického jádra bude vnímán mnohem lépe.
Aby mohl uživatel najít internetový zdroj, existují dva způsoby jeho použití:
- Nejprve analyzujte vyhledávací dotazy zákazníků, na jejichž základě vytvořte strukturu portálu (sémantický nebo sémantický, jádro, v tomto případě má rozhodující význam v rámci a struktuře zdroje);
- nejprve vytvořte plán, jak bude vypadat struktura webu, a poté pokračujte v analýze toho, co uživatele zajímá (sémantické jádro je již distribuováno v hotovém portálovém rámci).
První přístup zahrnuje přizpůsobení převládajícím podmínkám - a tato možnost opravdu funguje. V tomto případě je struktura prostředků spárována s klíčovými slovy a zůstává objektem. Druhá možnost je jako v písni Time Machine „Neměli byste se ohýbat pod měnícím se světem - jednoho dne se skloní pod námi“. Pomocí tohoto přístupu si podnikatel zvolí, co chce sdělit potenciálním uživatelům. Tento přístup lze nazvat jakousi proaktivní - a podnikatel v tomto případě se stane předmětem.
Je důležité pochopit, že hlavním cílem marketingu a podnikání je zaměření na zákazníka. A druhá metoda poskytuje právě to. To znamená, že podnikatel nebo obchodník rozhoduje, jaká data by měl prezentovat publiku pomocí svého portálu - a samozřejmě by měl mít určité znalosti o tom, co bude řečeno na jeho webových stránkách. Proto nejprve naplánuje přibližný návrh zdrojů, předběžný seznam stránek a poté analyzuje, jak uživatel hledá informace, které potřebuje. A pomocí informačního obsahu zdroje odpovídá na otázky, které uživatel pokládá vyhledávači.
První možností je metoda „SEO“. Je vedoucím celkem dlouho a používá se dodnes. Pomocí této metody byly nalezeny klíčové fráze, pro které se tvůrce webu jednoduše chtěl dostat na samý vrchol vyhledávače, a poté byla vytvořena samotná struktura zdroje a klíče byly distribuovány na všechny stránky. Obsah byl optimalizován pro klíčová slova a fráze.
Ale tato metoda v praxi ukazuje, že vyhledávač může být oklamán, ale lidé nejsou. Informační hodnota zdroje klesá - lidi nezajímá čtení textů, podle kterých se dohledávají klíčová slova, myslí si, že jsou někde podvedeni. Marketing však není vytvořen za tímto účelem - obchod formuje trendy a podnikatel si sám vybírá, co chce uživatelům říci. Marketing by neměl „tancovat na melodii někoho jiného“, jinak jej publikum přestane respektovat - musí utvářet samotné prostředí, ale zároveň být orientovaný na zákazníka. Přístup „SEO“ nemá ani jedno, ani druhé, a proto zastarává.
Mezitím kvůli tomu odpadají některé nadějné dotazy pro vyhledávač a tady je to také pochopitelné, protože na internetu je dnes velká konkurence. Stránky jsou navíc plné klíčových slov, která se „líbí“ vyhledávačům.
Plánovaným výsledkem konstrukce sémantického jádra je seznam klíčových dotazů, které jsou roztroušeny po stránkách portálu. Obsahuje URL stránek, požadavky s uvedením frekvence.
Stavba stránek
Struktura nebo konstrukce internetového zdroje je druh hierarchického nebo seřazeného schématu webové stránky. Jeho vytvořením jsou tyto úkoly řešeny jako:- Plánování informační strategie a struktury pro prezentaci informací uživateli;
- Zajištění toho, aby portál vyhovoval předpisům vyhledávačů;
- Záruka ergonomie zdroje pro klienta.
K tomu můžete použít cokoli, co je pohodlné - dokonce i MS Word nebo Paint, můžete to nakreslit ručně nebo na tabletu pomocí stylusu. Při plánování struktury si musíte zodpovědět 2 otázky:
- Jaké informace chcete jako podnikatel sdělit klientům;
- Kde zveřejnit ten či onen obsah.
Pokud vezmeme jako příklad design portálu malé cukrárny, pak bude obsahovat informační stránky (recepty, historie konkrétního dortu), sekci článku a katalog produktů (výkladní skříň). Pokud si to představíte ve formě diagramu, může to vypadat takto:
Hierarchické rozložení stránek
Dále je design vytvořen ve formě stolu. Zde je uvedena hierarchie, jsou uvedeny názvy stránek, zahrnuty jsou sloupce s klíčovými slovy a jejich četnost, jakož i s uvedením adresy URL stránek. Pokud předložíme tabulku stavby cukrárny, může to být následující:

Takto můžete reprezentovat strukturu (konstrukci) internetového zdroje jako tabulku
Nejprve známe pouze „názvy stránek“ a „ Symboly", A" URL "," Klíče "a" Frekvence "budou vyplněny později.
Klíčová slova
Je důležité pochopit, co jsou to klíčová slova a jaké vyhledávací dotazy klienti používají - bez toho nebude vytváření webu a prezentace informací uživatelům efektivní. Pro výběr klíčových slov můžete použít jednu ze služeb - je však důležité pochopit, že tato slova jsou vhodná.Klíče jsou tedy slova nebo fráze, které uživatelé používají k nalezení potřebných informací. Jednoduchý příklad - za účelem výroby koláče zadá do vyhledávače dotaz „recept jablečné charlotte s fotografií“.
Klíče lze rozdělit do několika skupin:
V závislosti na popularitě existují:
- Nízkofrekvenční dotazy (zobrazují 100–1 000 / měsíc);
- Střední frekvence (1 000–5 000 zobrazení);
- Vysoká frekvence (požaduje 5 000–10 000 zobrazení za měsíc).
V závislosti na potřebách zákazníků existují:
- Informační (pokud uživatel potřebuje najít nějaké informace - například „jak vyčistit oblečení od fucorcinu“, „které vitamíny zlepšují stav pokožky“);
- Transakční (žádosti vydané za účelem dokončení transakce, ale bez uvedení konkrétního webu nebo obchodu - „koupit pohovku“, „stáhnout hru“, „požádat o půjčku“);
- Navigační (pokud chce klient najít informace na konkrétním webu - například „webmoney create a card“, „track belpochta track code“, „euroopt discount“);
- Ostatní (pokud je obtížné určit, co uživatel chce - například zadáním fráze „mozek“, není jasné, co chce dotyčný vědět - struktura orgánu, Zajímavosti o něm, a kromě toho není jasné, o jakém mozku mluvíme - páteř nebo mozek).
Nyní pro každou položku. Rozdíl v hodnocení popularity závisí, jak je z kontextu zřejmé, na tom, zda je konkrétní téma mezi uživateli oblíbené. Rozdělení je libovolné, někteří odborníci definují menší počet zobrazení pro požadavky. Příkladem je následující případ: u webu, který prodává chytré telefony, požadavek „koupit Telefon Samsung»S frekvencí 6 000 / měsíc - střední frekvence. Pro sportovní klub je zároveň požadavek na „trénink Muay Thai“ s frekvencí sledování 1 000 žádostí vysokofrekvenční.
To vše je třeba vzít v úvahu a navrhnout extrémně široké sémantické jádro, které by mělo být obohaceno na úkor nízkofrekvenčních frází, protože podle statistik lze 60% až 80% všech uživatelských dotazů připsat nízkofrekvenční. To znamená, že nízkofrekvenční klíče by měly být používány jako hlavní zdroj, který vám umožní přilákat potenciální zákazníky na stránky - to jsou jakási úzce cílená klíčová slova. Musí být zředěny vysokofrekvenčními a středofrekvenčními požadavky.
Abyste efektivně využili druhou skupinu, kterou se klíčová slova liší, měli byste v první řadě při rozhazování klíčů po stránkách nebo při vytváření plánu obsahu zohlednit potřeby zákazníků. To znamená, že články, kde budou uživateli poskytnuty informace, by měly odpovídat na jejich otázky. Toto je většina klíčových frází bez konkrétního záměru - to znamená, že do článků informačního plánu by neměla být vkládána slova „koupit“, „stáhnout“ a podobně. Sekce „Shop“, „Catalogue“ nebo „Showcase“ jsou navrženy tak, aby uspokojily transakční požadavky uživatelů.
Mějte na paměti, že většina transakčních požadavků je komerčních. A proto se při rozhodování o prodeji dortů budete muset utkat s „Tort Moscow“, „Dobryninsky and partners“ a „Vienna shop“ - nejvíce hlavní výrobci cukrovinky. Pokud ale správně použijete výše uvedená doporučení, vše bude mnohem snazší. Rozbalte sémantické jádro textu co nejvíce a snižte frekvenci požadavků. Například frekvence žádosti „koupit americký sekaný dort“ bude mít nižší frekvenci než „koupit americký dort“.
Struktura vyhledávacích dotazů
Fráze je obecný koncept, včetně kvocientu. Stejně tak je tomu u vyhledávacích frází - obsahují tělo, specifikátor a ocas. Vezmeme -li například jako základ vyhledávací dotaz „dort“, nemůžeme pochopit, co uživatel potřebuje - definici cukrářského výrobku, jeho nákup nebo pouze obrázek. Samotný požadavek je vysokofrekvenční, a to znamená vysokou konkurenci v poskytování výsledků. Zavedení požadavku navíc přinese mnoho návštěv stránek klientů, kteří vůbec nemají zájem přijímat informace, které poskytujete, a to negativně ovlivní faktor chování. Důvodem je, že takový požadavek obsahuje pouze tělo.Pokud zavedeme doplněk ve formě slova „koupit“, pak získáme zahrnutí specifikátoru - co určuje záměr zákazníka. Slovo „koupit“ můžete nahradit slovem „recept“ a poté se takový požadavek stane informačním, a pokud zadáte „dorty v Miluji dort“, stane se taková otázka navigační. Proto je na specifikátoru, že klíč patří k jednomu nebo jinému typu klíčových slov.
Někdy se můžete setkat s tím, že uživatel, který chce prodat určitou věc, zadá požadavek „koupit“, aby viděl, kde lidé danou položku nejvíce nakupují.

Pokud zadáte frázi „koupit dort v Moskvě“ nebo „koupit dort na objednávku“, pak je poslední částí vyhledávacího dotazu ocas. Upřesňuje pouze některé podrobnosti o tom, jak a kde to klient zamýšlí udělat. Pokud tedy klient potřebuje znát konkrétní obchod, požadavek se stane navigačním.
Struktura vyhledávacích frází
Podíváme-li se na následující příklady: „kupte si domácí dort v Alma-Atě“, „recept na napoleonský dort“, „kupte si dort s doručením“, uvidíme, že v každé situaci existuje konkrétní cíl uživatele a ocas pouze upřesňuje detaily.Proto je pro sémantické jádro nutné určit základní terminologii spojenou se službami a zbožím, které budou prezentovány na portálu, nebo s obchodními aktivitami a potřebami zákazníků. Pokud tedy člověk potřebuje cukrovinku, pak se bude zajímat o koláče, marshmallow a marshmallows, marshmallows, vafle, sušenky, pusinky, vdolky atd. Toto tělo klíčový požadavek... A pak najdeme specifikátory a ocasy. Díky frázi s „ocasy“ se váš dosah zvyšuje a zároveň je méně „konkurentů ve vyhledávání“.
Internetové zdroje, které vám umožňují formulovat sémantické jádro (výběr klíčových hodnot)
Aby bylo možné sbírat klíčová slova pro váš web, existuje mnoho asistentů, kteří usnadňují život obchodníkovi. Existují placené možnosti, které jsou potřeba, pokud je web obrovský nebo jich je mnoho, a bezplatné možnosti vhodné pro malý portál.V tomto článku se podíváme na následující zdroje:
- KeyCollector (placený);
- SlovoEB (zdarma);
- Wordstat od Yandexu (zdarma);
- AdWords od Google (zdarma).
Sběratel klíčů
Je to placený nástroj s mnoha funkcemi. Automatizuje operace potřebné k vytvoření sémantického jádra. Můžete samozřejmě použít bezplatné analogy programu, ale k tomu budete muset použít několik internetových zdrojů najednou, protože tento program má téměř neomezený výběr. Kromě, tuto službu prostě nenahraditelný, pokud vlastníte více než jeden web, nebo jste zvyklí mít vše v jednom programu, abyste nemuseli hledat zdroje třetích stran, a také pokud máte několik webů nebo velký web potřebuje sémantický obsah.Nabízí následující možnosti:

Tak vypadá KeyCollector
SlovoEB
Tato služba je zdarma. Vývojáři jsou stejní lidé, kteří vytvořili program Key Collector. Aby program mohl používat, musíte zadat přihlášení z dalšího přímého účtu. Důvodem je skutečnost, že Yandex může zablokovat účet kvůli automatickým žádostem, takže byste neměli používat hlavní.Prostředek nabízí následující funkce:
- Shromažďování klíčových slov prostřednictvím Wordstatu;
- Vysokofrekvenční filtr dotazů;
- Analýza tipů pro vyhledávání.

Rozhraní SlovoEB
Jak program funguje? Nejprve vytvoříme nový projekt. Vyberte „přidat fráze“ - zde jsou uvedeny fráze, které zákazníci používají k vyhledání informací o konkrétním produktu.

Přidání hledané fráze do programu
V nabídce „Shromažďovat klíčová slova a statistiky“ vyberte požadovanou položku a spusťte službu. Pokud například potřebujete shromažďovat klíčové fráze, vyberte tuto možnost.

Určení frekvence klíčových frází
Wordstat (služba Yandex)
Toto je bezplatný zdroj pro výběr a analýzu. vyhledávací fráze... Je vyžadováno, pokud jste připraveni analyzovat a klasifikovat dotazy ručně. Služba nabízí následující možnosti:- Zobrazování informací o zobrazeních a dotazech podle klíčových slov, vyhledávacích frází, přičemž můžete analyzovat obecná i mobilní data (to znamená, že vidíte, jak populární je dotaz na mobilních zařízeních);
- Demonstrace statistik podle krajů;
- Zobrazení údajů o oblíbenosti konkrétního dotazu v poměru k času („historie dotazů“);
- Zobrazení fráze nebo dotazu pouze v zadané podobě (k tomu je třeba frázi vložit do uvozovek);
- Zobrazit statistiky, aniž byste vzali v úvahu stop slova (musíte před toto slovo dát mínus, aby nebylo bráno v úvahu);
- Ukázka dat pomocí vybrané předložky (v tomto případě by jí mělo předcházet „+“);
- Zobrazení informací o kategorii požadavků (za tímto účelem by měly být skupiny požadavků uvedeny v závorkách a klíčové možnosti by měly být odděleny lomítkem „|“: to znamená, abyste získali údaje o požadavku „objednat dort “,„ kupte si dort “,„ objednejte si cupcake “,„ kupte si cupcake “,„ objednejte koláč “a„ kupte si koláč “, postupujte podle pokynů na obrázku níže);
- Zobrazí data o požadavcích s odkazem na konkrétní oblasti.

Žádost o košíčky, obecné statistiky

Klíčová data podle regionů

Zde můžete vidět, kdy byl požadavek nejvíce nebo nejméně populární.

Zobrazení fráze v zadané podobě

Informace pro klíč bez slovních forem

Statistiky bez stop slova

Data o šesti požadavcích najednou jsou užitečnou věcí, pokud potřebujete rychle získat informace

Pokud vyberete konkrétní oblast, uvidíte, co je tam populární.
Google AdWords (Plánovač klíčových slov Google)
Pokud je Google v určité oblasti výrazně v čele, pak je lepší využít tuto službu. Je navržen tak, aby vypočítal potřeby uživatelů tohoto vyhledávače. Služba je bezplatná, ale existují placené služby (například pro reklamy).Nástroj nabízí následující funkce:
- Shromažďování informací o vyhledávacích dotazech;
- Vývoj nových kombinací dotazů a předpovídání jejich relevance a dynamiky.
Chcete -li získat statistiky konkrétních požadavků, měli byste tuto možnost vybrat domovská stránka nářadí. Budete muset zadat zájmové fráze a nahrát soubor ve formátu CSV, poté vybrat oblast, pro kterou potřebujete statistiku, můžete také zadat zastavovací slova (jak je popsáno v Wordstatu). Vše je připraveno - můžete stisknout tlačítko „Zjistit počet požadavků“.

Informace o dotazech od společnosti Google
Služby nabízející analytické služby
Pokud potřebujete vytvořit sémantické jádro pro existující zdroj, můžete také použít analytické systémy Google Analytics nebo Metrica. Tyto nástroje vám pomohou identifikovat vyhledávací dotazy, které zákazníci zadávají.
Inspiraci na klíčová slova najdete také zde.
Kromě toho lze údaje o běžných frázích pro klienty, kteří hledají tyto nebo ty informace, kontrolovat pomocí účtu webmasterů Yandex a Google. U posledně jmenovaných jsou data umístěna ve službě Search Console, poté musíte přejít do sekce „Návštěvnost z vyhledávání - analýza vyhledávacích dotazů“.
Webmaster Yandex navrhuje použít sekci „Vyhledávací dotazy - Oblíbené dotazy“.
Nástroje pro analýzu stránek konkurence
Konkurenční stránky jsou dalším zdrojem, kde hledat inspiraci pro klíčová slova. Aby je bylo možné identifikovat, má smysl číst jejich publikace nebo kontrolovat text pomocí značky HTML keywod pomocí programového kódu webové stránky. Nebo vám pomůže Advego s Istiem.
Rozhraní Istio
Pokud potřebujete analyzovat celý portál konkurence, můžete použít následující nástroje:
Nyní podrobněji ke každé položce.
Aby bylo možné určit hlavní klíče, budou muset být zapsány.To lze provést jak na list papíru, tak pomocí počítačových programů. Budete potřebovat nápady od všech svých kolegů - potřebují je všechny zapsat, bez výjimky: každý se může ukázat jako „houští grálu“, které k vám přitáhne klienty.
Seznam může vypadat nějak takto:

Ukázkový seznam frází k hledání
V tomto seznamu jsou téměř všechny klíče vysokofrekvenční, bez jakýchkoli specifik. Fráze se střední a nízkou frekvencí vám umožní rozšířit jádro na maximum. Přejděme tedy k dalšímu kroku.
Zde je tato obtíž vyřešena pomocí nástroje pro vyhledávání klíčových slov. Můžete si například vybrat službu Yandex - je to jedna z nejpohodlnějších, navzdory zjevné počáteční složitosti. Zde můžete odkazovat na konkrétní region, pokud nabízíte produkt nebo službu v konkrétní zeměpisné oblasti.
V této fázi tedy analyzujeme všechny klíče sestavené kolegy.

Analýza hlavního dotazu
Fráze byste měli zkopírovat z levého sloupce služby a vložit do tabulky. Nyní bychom se měli zaměřit na pravý sloupec asistenta - zde Yandex nabízí fráze, které návštěvníci použili společně s hlavní frází. Jedním kliknutím tak máte možnost vybrat příslušné klíče a zkopírovat je do levého sloupce. Pokud se něco z toho nehodí, nemějte strach - tyto fráze budou v konečné fázi odstraněny. A už je blízko, jako zima ve Hře o trůny.
Výsledkem této fáze bude sestavený seznam frází pro vyhledávání, který bude pro každý hlavní klíč. V této fázi mohou dopadnout stovky nebo dokonce tisíce různých požadavků.

Seznam frází
Přecházíme do konečné fáze. Bez ohledu na to, jak lehké to může vypadat, není. Toto je časově nejnáročnější a nejobtížnější práce s jádrem. Je nutné ručně vyloučit ze sémantického jádra to, co mu významově nevyhovuje.
Ale v žádném případě byste neměli odstraňovat nízkofrekvenční klíče. Optimalizátoři „staré školy“ mohou tento klíč nadále považovat za nevyžádanou poštu, ale tento trik nemusí padnout. Příklad: vezmeme -li klíč „dietní koláč“ jako základ, můžete vidět, že služba zobrazuje na obrazovce 3 zobrazení za měsíc v regionu Cherepovets. „Profesionální“ metoda zahrnuje vyhození klíčů. Nyní však pochopíte, proč byste to neměli dělat - a doufám, že budete tuto radu ve svém životě i nadále uplatňovat.
Specialisté na SEO, aby se jejich stránky zobrazovaly v horní části vyhledávačů, zakoupených nebo pronajatých odkazů. Současně museli použít určité klíče, Metoda se stále používá. A lze jim porozumět, protože fráze s nízkou frekvencí zobrazení zpravidla nevyplácejí peníze vynaložené na odkaz.
Pokud se ale podíváte na „dietní koláče“ očima nikoli oldschoolového SEO, ale klienta zaměřeného na podnikatele, můžete otevřít další funkce... Ostatně některé z potenciálních zákazníků to opravdu zajímá - a v neposlední řadě jde o dívky, které si hlídají svoji postavu. Víme to tedy jistě tento požadavek někoho to zajímá, a proto s klidným svědomím může zahrnout do sémantického jádra. Pokud cukráři ve vaší společnosti připraví takový výrobek, určitě se bude hodit tam, kde bude zboží popsáno. A pokud ne, lze tento obsah vyhradit pro informační sekci portálu.

"Dietní dort", který lze ve skutečnosti považovat za odpadky, není
Co tedy vyloučit? Pojďme na to:
- Za prvé jsou to fráze, kde jsou přítomny jiné značky;
- Za druhé, opakované fráze - například ze 3 klíčů „dorty na míru na nový rok“, „dorty na objednání nového“, „objednávka na novoroční dort“ bude stačit první klíč;
- Za třetí, pokud se nevěnujete něčemu takovému, jako je „dumping“, pak vám klíče se zavedením slov „levné“ a „levné“ určitě nebudou užitečné;
- Za čtvrté, klíče s nevhodnými oblastmi - pokud obchodujete pouze v Čerepovci, ale nedodáváte v okolních vesnicích nebo neobchodujete v určité oblasti města, tato data nejsou potřeba;
- Za páté, klíče s odkazy na produkty, o kterých s jistotou víte, že je neprodáte, a tedy neprodáváte;
- A za šesté, určitě nebudete potřebovat fráze, které jsou napsány nesprávně - bez ohledu na to, zda se jedná o gramatické chyby nebo překlepy - vyhledávač pomůže návštěvníkovi, který hledá „gbhj; yst“ místo „koláče“, „cupcakes“ místo „cupcakes“.
Voila, když jste identifikovali všechny klíče, které vám nesedí, obdrželi jste potřebné dorty k objednání klíčů. Se vším ostatním musíte udělat to samé. A další fází bude klasifikace frází do typů.
Vytváření mapy korespondence (relevance) a klasifikace klíčových frází
Vyhledávací fráze, které bude cílové publikum používat jako hlavní, a najdou údaje, které uživatele přivedou na váš web, jsou integrovány do tzv. „Sémantické (sémantické) klastry“ jsou kategorie dotazů, které jsou si sémantickým obsahem podobné. To znamená, že shluk „dort“ zahrnuje všechny fráze, které jsou přímo nebo nepřímo vyjádřeny tímto slovem - a v tomto případě se tato jednotka jazyka jeví jako „konkrétní“ a všechny fráze jsou „obecné“. Co máte možnost rozjímat na obrázku níže.Vezměte prosím na vědomí, že existují také klastry druhé, třetí a čtvrté kategorie. Čím širší je téma, tím více úrovní má klastr. I když se de facto ukazuje, že klastrů druhé skupiny je dost.

Klastrové úrovně
Většina klastrů byla identifikována v první fázi vytváření klíčových slov. Přirozeně k tomu stačí porozumět předloženému tématu, protože aniž byste věděli něco o koláčích, je sotva možné sestavit kompetentně sémantické jádro. Vytvořený diagram stránek bude také sloužit jako asistent při vytváření klastru.
Klastrování ve druhé kategorii je velmi důležité. Zde byste měli přidat specifikátory, které budou indikovat cíle zákazníků - například „koupit dorty“, „historii vytvoření napoleonského dortu“. Poslední klastr přeneseme do informační sekce a první do katalogu.
Nyní jsme opět zpět k hierarchickému schématu webové stránky a tabulce vyvinuté na jejím základě. „Dorty na objednávku“ byly identifikovány pomocí služby Yandex a následně nebyly ze seznamu vyloučeny. Nyní by měl být tento klíč rozptýlen mezi stránky příslušné sekce.

Můžete tak rozptýlit hledanou frázi na svém webu.
Vezměme si tento příklad: klastr obsahuje fráze pro vyhledávání „fotbalové téma dortů na míru“.

Ukázalo se, že fotbalové dorty zajímají uživatele
A pokud cukrárna vyrábí tento typ výrobku, pak víme, ve které sekci bude umístěna tato stránka... Měl by být umístěn do „Mastic Cakes“, protože tento materiál se používá k vytvoření takové cukrárny. Zde tedy vytvoříme odpovídající stránku. Přidáme jej ke konstrukci internetového zdroje s uvedením adresy URL a vyhledávacích frází s frekvencí.

Vytvořte stránku v příslušné sekci
Pomocí stejného nástroje, který pomáhá najít správné klíče, můžete vidět, na co dalšího se uživatelé ptají ohledně fotbalového tématu. Tyto fráze by měly být také zadány na této stránce.

Zjistili jsme, co dalšího zákazníky zajímá ohledně fotbalu a dortu
Označujeme klíče. Rozptylujeme zbylé vyhledávací klíče.
Diagram nakreslený na samém začátku lze neomezeně měnit - v případě potřeby můžete vytvářet nové kategorie a sekce. Pokud tedy stránka „Dětské dorty“ dříve neexistovala, pak si pamatujete, že společnost může vyrábět dorty na zakázku s kreslenými obrázky „Peppa Pig“ nebo „Paw Patrol“, můžete provést změny a vytvořit takovou stránku. Tyto klíče zároveň najdete také v sekci „Mastic Cakes“.

Vytvoření nové sekce v hierarchické tabulce webu „Dětské dorty“
Je třeba mít na paměti dvě důležité věci:
- Klastr nemusí obsahovat vhodnou frázi pro stránku, kterou chcete vytvořit. Důvody mohou být zneužít klíčové slovo, nedostatky služeb pro výběr klíčových frází nebo jednoduše nízká popularita prodávaného produktu nebo služby. Ale zároveň to není vůbec důvod k opuštění stránky a prodeji produktu. Pokud jste například ve vyhledávači nenašli vyhledávací dotaz „Dort Peppa Pig“, ale cukrářská společnost má schopnost takový výrobek vyrobit, pak můžete vyjasnit potřeby zákazníků pomocí jiné služby. V takovém případě bude takový požadavek nalezen a většina z nich je nalezena;

Lidé také hledají „Peppa Pig“
- No a také po vyloučení nepotřebných klíčů mohou zůstat zcela nevhodné požadavky. Lze je buď odebrat, nebo použít na jiný cluster. Řekněme, že se cukrářská společnost specializuje na jedinečné recepty a časem prověřené koláče jako „ruiny hraběte“ nebo „napoleon“ si myslí, že je lepší je nechat v minulosti - takové klíče můžete nechat v sekci, kde bude uživateli poskytnut s obecnými informacemi - v tomto případě „recepty“.
Klíčovou frázi lze také umístit do informační sekce, pokud je mezi návštěvníky velmi oblíbená.
V konečné fázi se tedy po rozptýlení všech klíčů po stránkách naučíte seznam webových stránek portálu, kde jsou uvedeny adresy URL, požadavky a jejich frekvence. Jen do toho, to není vše.
Konečná fáze obohacení sémantického jádra
Takže teď máme vše, co potřebujeme. Máme tabulku se sémantickým jádrem, seznam předběžných webových stránek a klíčové fráze, které identifikují potřeby určitých klientů. To vše pomůže při sestavování plánu obsahu textů (obsahový plán). Nyní při jeho vytváření budete muset zadat název webové stránky nebo článku a zahrnout do něj hlavní dotaz pro vyhledávač. Je ale třeba mít na paměti, že ne vždy to musí být nejběžnější klíč z pohledu Yandexu nebo Googlu. Měl by odrážet to, co chcete sdělit uživatelům a co zákazníci chtějí získat.Jako odpověď na otázku - „O čem mám psát?“ By měly být použity další klíčové fráze. Samozřejmě byste neměli okamžitě „nacpat“ všechny fráze, které byly nalezeny pomocí nástroje pro výběr vyhledávacích dotazů, do té či oné části - ať už jde o informační stránku nebo nabídku nabízející nákup určité služby nebo produktu. Mělo by se to zopakovat na samém konci ještě jednou: musíte v první řadě věnovat pozornost informačním potřebám uživatelů, a ne klíčovým frázím a „nacpávání“ textu jimi, jako pilulky. Uživatel vždy vidí, když se je pokouší „nakrmit“ - pokud je text dobře napsaný, ani ho nenapadne, že zde byla použita klíčová slova.
Konečně o tom, co by se koneckonců nemělo dělat se sémantickým jádrem
Doufám, že už nemáte žádné další dotazy ohledně toho, co již bylo řečeno, a nyní můžete na základě získaných znalostí vytvořit tucet webů. Ale přesto byste měli nastínit některé akce, které byste neměli dělat. Později to intuitivně pochopíte, ale nyní byste se je měli naučit nazpaměť. Zde je několik tipů, které vám pomohou stát se profesionálem ve správném budování vašeho webu:- Neměli byste se vzdávat klíčů, které mají příliš velkou konkurenci. Ano, pro vyhledávací dotazy „objednat marshmallow“ se opravdu nemusíte dostat nahoru. Použijte frázi jako svůj obsahový nápad;
- Také byste se neměli zbavovat frází s nízkou frekvencí - to jsou samotné obsahové nápady, díky kterým budete s největší pravděpodobností schopni uspokojit ty, kteří dokázali najít takové služby i od největších společností;
- K hodnocení klíčových slov nepoužívejte vzorce a koeficienty (jako kei, poměr popularity k konkurenci). Udělejme si opět jasno: sémantika je část lingvistiky. Není to exaktní věda jako fyzika nebo matematika. To je blíže umění než přesnému výzkumu a při dodržení požadavků na splnění vzorce nebo koeficientu ztrácí sémantika chuť. Tímto způsobem ztratíte spoustu nápadů na obsah, který by program mohl vyloučit - ale není to program, který následně přečte text;
- Neměli byste vytvářet samostatnou stránku kvůli jednomu klíči. Každý se pravděpodobně setkal s takovými internetovými obchody, kde jsou speciální stránky „koupit dort“ a „objednat dort“. Sémantické jádro se zde ztrácí, protože ve skutečnosti jde o jednu a tu samou akci. Nebo „nakupujte levně“ a „kupujte levně“ jsou synonymní slova, takže byste neměli stránky samostatně zaplňovat zbytečným obsahem;
- Není třeba plně automatizovat konstrukci sémantického jádra. Ke sběru klíčových frází jste samozřejmě použili speciální nástroje a pro velké projekty jsou tyto nástroje jednoduše nenahraditelné - zejména sběratel klíčů. Ale bez lidské analýzy je hodnota seznamu klíčů nízká. Není to velké tajemství - vědí to i ti, kteří používají znalosti staré školy. Služby nám pouze usnadňují život tím, že shromažďují informace, které by jinak musely být dlouho a bolestně filtrovány, ale nemohou skládat samotný text. Přesněji takové programy existují, ale jejich hodnota pro člověka není velká a jsou určeny pro úplně jiný účel - ne pro čtení uživatelem. Pouze někdo, kdo v této oblasti něčemu rozumí, může skutečně určit míru konkurence, vypracovat plán informační kampaně nebo analyzovat situaci v této oblasti. Všechny tři body jsou nepřímo spojeny s konstrukcí struktury webového zdroje a rozptýlením klíčových slov;
- Nebuďte milí - není třeba se příliš soustředit na sběr klíčových frází. Začíná podnikání, nemá smysl důkladně špehovat konkurenty, sbírat co nejvíce klíčových slov ze všech dostupných vyhledávačů, včetně hotbotů, a zkoumat návrhy hledání. Stačí použít jeden nebo maximálně dva zdroje a může to být yandex nebo google. Pokud je tento konkrétní vyhledávač ve vašem regionu populární, v horším případě se potýkejte s mail.ru. Tut.by - pokud vás konkrétně zajímá běloruský region, nebo uaportal.com - na Ukrajině. Používají se však pouze jako odkaz na region: pokud například obyvatelé Běloruska mají zájem o „koláče s Ksenia Sitnik“, to obyvateli Ruska vůbec neřekne. To znamená, že byste neměli přesycovat své stránky také klíčovými slovy.
Musíte si pamatovat, proč a proč budujete jádro. A také, že je sémantický.
Je to tedy marketing nebo SEO?
Tím nechci říci, že jedno odporuje druhému. Obchodník může být dobrým SEO a naopak. Prostě od člověka, který by byl schopen správně formulovat sémantické jádro pro svůj web, je v první řadě nutná logika obchodníka a marketéra (zaměření na klienta), a pak dovednosti SEO specialisty ( správné umístění klíčových slov). Musíte pochopit, co můžete jako podnikatel potenciálnímu spotřebiteli nabídnout. Poté musíte pochopit, jak zákazníci vyhledávají a nacházejí potřebná data. A výše popsané nástroje s tím pomohou. Analyzujte, odfiltrujte nepotřebné, najděte vhodné klíče podle hodnoty, klasifikujte je a ergonomicky rozdělte do celé struktury webu. A voila, nyní nastal okamžik, kdy můžete začít tvořit svůj obsahový plán. Pozornost!!!. Správa nenese odpovědnost za její obsah.Začínající webmasteři, kteří čelí potřebě vytvořit sémantické jádro, nevědí, kde začít. Ačkoli v tomto procesu není nic složitého. Jednoduše řečeno, musíte shromáždit seznam klíčových frází, podle kterých uživatelé internetu hledají informace na vašem webu.
Čím je úplnější a přesnější, tím snazší je pro copywritera napsat dobrý text a pro vás získat vysoké pozice při hledání požadovaných dotazů. Tento článek bude diskutovat o tom, jak správně skládat velká a kvalitní sémantická jádra a co s nimi dále dělat, aby se web dostal na začátek a sbíral velký provoz.
Sémantické jádro je sada klíčových frází, neseskupených podle významu, kde každá skupina odráží jednu potřebu nebo touhu uživatele (záměr). To je to, o čem si člověk myslí, když zadá svůj dotaz do vyhledávacího panelu.
Celý proces vytváření jádra lze znázornit ve 4 krocích:
- Stojíme před úkolem nebo problémem;
- V hlavě formulujeme, jak můžeme najít jeho řešení pomocí vyhledávání;
- Odesíláme požadavek na Yandex nebo Google. Totéž dělají další lidé kromě nás;
- Nejčastější možnosti hovorů spadají do analytických služeb a stávají se klíčovými frázemi, které shromažďujeme a seskupujeme podle potřeb. V důsledku všech těchto manipulací se získá sémantické jádro.
Je nutné vybrat klíčové fráze, nebo se bez toho obejdete?
Dříve byla sémantika sestavována s cílem najít nejčastější klíčová slova k tématu, zapsat je do textu a získat pro ně dobrou viditelnost při vyhledávání. Za posledních 5 let se vyhledávače snaží přejít na model, kde relevance dokumentu k dotazu nebude hodnocena podle počtu slov a rozmanitosti jejich variací v textu, ale podle posouzení zveřejnění záměru.
Google to spustil v roce 2013 s algoritmem Hummingbird, Yandex v roce 2016 a 2017 s technologiemi Palekh a Korolev.
Texty napsané bez SA nebudou moci plně odhalit téma, což znamená, že nebude fungovat, když bude konkurovat TOP ve vysokofrekvenčních a středofrekvenčních dotazech. Sázet na nízkofrekvenční požadavky nemá smysl - je pro ně příliš malý provoz.
Pokud chcete v budoucnu úspěšně propagovat sebe nebo svůj produkt na internetu, musíte se naučit, jak sestavit správnou sémantiku, která plně odhalí potřeby uživatelů.
Klasifikace vyhledávacích dotazů
Podívejme se na 3 typy parametrů, podle kterých se hodnotí klíčová slova.
Podle frekvence:
- Vysokofrekvenční (HF) - fráze, které definují téma. Skládá se z 1-2 slov. V průměru začíná počet vyhledávacích dotazů od 1 000 do 3 000 za měsíc a v závislosti na tématu může dosáhnout stovek tisíc zobrazení. Nejčastěji jsou pro ně zostřeny hlavní stránky webů.
- Střední frekvence (MF) - oddělené směry v tématu. Většinou obsahují 2–3 slova. S přesnou frekvencí 500 až 1 000. Typicky kategorie komerčních webů nebo témata pro velké informační články.
- Nízkofrekvenční (LF) - dotazy související s hledáním konkrétní odpovědi na otázku. Zpravidla od 3-4 slov. Může to být produktová karta nebo téma článku. V průměru hledá 50 až 500 lidí měsíc.
- Při analýze dat metrik nebo statistik lze najít ještě jeden typ - klíče micro LF. Jedná se o fráze, které jsou často požadovány jednou při vyhledávání. Brousit stránku pro ně nemá smysl. Stačí být nahoře pro basy, které je zahrnují.
Podle konkurenceschopnosti:
- Vysoce konkurenční (VK);
- Střední rozsah (SK);
- Nízká konkurenceschopnost (NK);
Na požádání:
- Navigační. Vyjádřete touhu uživatele najít konkrétní internetový zdroj nebo informace o něm;
- Informační. Charakterizována potřebou informací jako reakce na žádost;
- Transakční. Přímo souvisí s touhou uskutečnit nákup;
- Fuzzy nebo obecně. Ty, u nichž je obtížné přesně určit záměr.
- Geo-dependentní a geo-independent. Odrážejte potřebu vyhledávat informace nebo provádět transakce ve vašem městě nebo bez regionální reference.

V závislosti na typu webu můžete při výběru klíčových frází pro sémantické jádro poskytnout následující doporučení.
- Informační zdroj... Hlavní důraz by měl být na hledání témat pro články ve formě MF a LF dotazů s nízkou konkurencí. Doporučuje se téma otevřít široce a hluboce a zostřit stránku pro velký počet kláves LF.
- Internetový obchod nebo komerční stránky. Shromažďujeme HF, MF a LF, segmentujeme co nejjasněji, takže všechny fráze jsou transakčního typu a patří do jednoho klastru. Zaměřujeme se na nalezení dobře konvertujících nízkofrekvenčních klíčových slov NK.
Jak správně sestavit velké sémantické jádro - pokyny krok za krokem
Přešli jsme k hlavní části článku, kde budu důsledně analyzovat hlavní etapy, které je třeba projít, aby se vybudovalo jádro budoucího webu.
Aby byl proces jasnější, jsou všechny kroky uvedeny s příklady.
Hledejte základní fráze
Práce s jádrem SEO začíná výběrem primárního seznamu základních slov a frází (HF), které nejlépe charakterizují dané téma a jsou použity v širším smyslu. Říká se jim také markery.
Mohou to být buď názvy směrů, nebo typy produktů, oblíbené dotazy z daného tématu. Zpravidla se skládají z 1-2 slov a mají desítky a někdy i stovky tisíc zobrazení za měsíc. Je lepší nebrat příliš široké klíče, abyste se během fáze rozšiřování neutopili v vylučujících klíčových slovech.
Nejpohodlnějším způsobem, jak vybrat fráze značek, je použít. Když do něj zadáme dotaz, v levém sloupci vidíme fráze, které v sobě obsahuje, v pravém - podobné dotazy, ze kterých často najdete témata vhodná k rozbalení. Služba také ukazuje základní frekvenci fráze, tj. Kolikrát byla za měsíc požádána ve všech slovních formách a s přidáním jakýchkoli slov.

Sama o sobě je taková frekvence málo zajímavá, proto, abyste získali přesnější hodnoty, musíte použít operátory. Pojďme analyzovat, co to je a k čemu to je.
Operátoři Yandex Wordstat:
1) "..." - uvozovky. Dotaz v uvozovkách vám umožňuje sledovat, kolikrát byla fráze hledána v Yandexu se všemi jejími slovními formami, ale bez přidání dalších slov (ocasy).

2)! - Vykřičník. Použitím před každým slovem v požadavku opravíme jeho formu a získáme počet zobrazení při hledání klíčové fráze pouze v zadané slovní formě, ale s ocasem.

3) „! ...! ...! ...“ - uvozovky a vykřičník před každým slovem. Nejdůležitější operátor pro optimalizátor. Umožňuje vám pochopit, kolikrát je klíčové slovo požadováno za měsíc striktně pro danou frázi, jak je napsáno, bez přidávání slov.

4) +. Yandex Wordstat při zadávání požadavku nebere v úvahu předložky a zájmena. Pokud ho potřebujete ukázat, postavíme před ně znaménko plus.

5) -. Druhý nejdůležitější operátor. S jeho pomocí jsou rychle odstraněna slova, která se nehodí. Chcete -li jej použít, za analyzovanou frázi vložte mínus a zastavovací slovo. Pokud je jich několik, postup opakujeme.

6) (… |…). Pokud potřebujete získat data z Yandex Wordstat pro několik frází současně, uzavřeme je do závorek a oddělíme lomítkem. V praxi se tato metoda používá jen zřídka.

Pro usnadnění práce se službou doporučuji nainstalovat speciální rozšíření prohlížeče „Wordstat Assistant“. Nainstalováno v prohlížeči Mozila, Google Chrome, J. Browser a umožňuje kopírovat fráze a jejich frekvence jediným kliknutím na ikonu „+“ nebo „Přidat vše“.

Řekněme, že jsme se rozhodli vytvořit si vlastní SEO blog. Vyberme mu 7 hlavních frází:
- sémantické jádro;
- optimalizace;
- copywriting;
- povýšení;
- monetizace;
- Přímo
Hledejte synonyma
Při formulování dotazu do vyhledávačů mohou uživatelé používat slova, která jsou významově podobná, ale pravopisně odlišná.
Například „auto“ a „auto“.
Aby se zvýšilo pokrytí budoucího sémantického jádra, je důležité najít co nejvíce synonym pro hlavní slova. Pokud se tak nestane, pak při analýze vynecháme celou vrstvu klíčových frází, které odhalí potřeby uživatelů.
Co používáme:
- Brainstorm;
- Pravý sloupec Yandex Wordstat;
- Požadavky napsané v azbuce;
- Zvláštní termíny, zkratky, slangové výrazy z předmětu;
- Bloky Yandex a Google - vyhledávání společně s „názvem požadavku“;
- Fragmenty konkurence.
V důsledku všech akcí pro vybrané téma získáme následující seznam frází:

Rozšíření základních dotazů
Pojďme analyzovat tato klíčová slova, abychom identifikovali základní potřeby lidí v této oblasti.
Nejpohodlnější způsob, jak to udělat, je v programu Key Collector, ale pokud je škoda zaplatit za licenci 1 800 rublů, použijte ji analog zdarma- Ústa.
Pokud jde o funkčnost, je určitě slabší, ale je vhodný pro malé projekty.
Pokud se nechcete ponořit do práce programů, můžete využít služby Just-Magiс a Rush Analytics. Ale přesto je lepší strávit trochu času a zjistit software.
Ukážu vám, jak to funguje v Kay Collector, ale pokud pracujete se Slovoebem, pak bude také vše jasné. Rozhraní programu je podobné.
Postup:
1) Přidejte do programu seznam základních frází a odeberte pro ně základní a přesnou frekvenci. Pokud plánujeme propagaci v konkrétním regionu, uvedeme regionálnost. U informačních stránek to většinou není nutné.

2) Pojďme analyzovat levý sloupec Yandex Wordstat přidanými slovy, abychom získali všechny požadavky z našeho tématu.

3) Na výstupu jsme získali 3374 frází. Sundejme je z přesné frekvence, jako v 1. odstavci.

4) Zkontrolujeme, zda jsou v seznamu nějaké klíče s nulovou základní frekvencí.

Pokud existuje, odstraňte jej a přejděte k dalšímu kroku.
Negativní slova
Mnoho lidí postup při shromažďování vylučujících klíčových slov zanedbává a nahrazuje jej odstraněním frází, které nejsou vhodné. Později si ale uvědomíte, že je to pohodlné a opravdu to šetří čas.
V nástroji Collector otevřete kartu Data -> Analýza. Vybereme typ seskupení podle jednotlivých slov a procházíme seznamem kláves. Pokud vidíme frázi, která se nehodí, klikněte na modrou ikonu a přidejte slovo místo všech slovních tvarů do zastavovacích slov.

Ve Slovoebě je práce se zastavovacími slovy implementována ve zjednodušenější podobě, ale můžete si také vytvořit vlastní seznam frází, které se k sobě nehodí, a použít je na seznam.
Nezapomeňte použít třídění podle základní frekvence a počtu frází. Tato možnost pomáhá rychle zredukovat seznam původních frází nebo odfiltrovat vzácné fráze.

Poté, co jsme sestavili seznam zastavovacích slov, použijeme je v našem projektu a pokračujeme ve shromažďování návrhů na hledání.
Analyzovat rady
Když zadáte dotaz na Yandex nebo Google, vyhledávače nabízejí své možnosti pro pokračování z nejoblíbenějších frází, do kterých uživatelé internetu zadávají. Tato klíčová slova se nazývají návrhy vyhledávání.
Mnoho z nich nespadá do Wordstatu, takže při konstrukci sémantického je nutné takové dotazy shromažďovat.
Kay Collector je ve výchozím nastavení analyzuje s iterací koncovek, cyrilice a latinky a s mezerou za každou frází. Pokud jste připraveni obětovat množství, abyste výrazně urychlili proces, zaškrtněte políčko „Sbírejte pouze NEJLEPŠÍ výzvy bez hrubé síly a mezery za frází“.

Mezi návrhy vyhledávání často najdete fráze s dobrou frekvencí a konkurencí desetkrát nižší než ve Wordstatu, takže v úzkých mezerách doporučuji shromáždit co nejvíce slov.
Čas pro analýzu rad přímo závisí na počtu současných volání na servery vyhledávače. Maximální sběratel klíčů podporuje práci s 50 vlákny.
Ale k analýze požadavků v tomto režimu budete potřebovat stejný počet proxy a Yandex účtů.
Po shromáždění tipů pro náš projekt jsme získali 29595 unikátních frází. Pokud jde o čas, celý proces trval o něco více než 2 hodiny na 10 vláknech. To znamená, že pokud je jich 50, ponecháme je do 25 minut.

Určení základny a přesná frekvence pro všechny fráze
Pro další práci je důležité určit základnu a přesnou frekvenci a vyřadit všechny nuly. Pokud jsou cílené, ponechte žádosti s nízkým počtem zobrazení.
To vám pomůže lépe porozumět obsahu a vytvořit úplnější strukturu článku, než je v horní části.
Abychom frekvenci odstranili, nejprve odstraníme všechny nepotřebné:
- opakování slov
- klíče s jinými symboly;
- duplicitní fráze (prostřednictvím nástroje Implicitní duplicitní analýza)

U zbývajících frází určíme přesnou a základní frekvenci.
A) pro fráze do 7 slov:
- Vyberte pomocí filtru „Fráze obsahuje maximálně 7 slov“
- Otevřete okno „Sbírat z Yandex.Direct“ kliknutím na ikonu „D“;
- V případě potřeby uveďte region;
- Vyberte režim zaručených zobrazení;
- Vložíme období sběru - 1 měsíc a zaškrtneme políčka nad požadovanými typy frekvencí;
- Klikněte na „Získat data“.

b) pro fráze od 8 slov:
- Nastavili jsme filtr pro sloupec „Fráze“ - „skládá se alespoň z 8 slov“;
- Pokud potřebujete postoupit v konkrétním městě, uvedeme níže uvedený region;
- Klikněte na lupu a vyberte „Sbírat všechny druhy frekvencí“.

Čištění klíčových slov od odpadků
Poté, co jsme obdrželi informace o počtu zobrazení pro naše klíče, můžeme začít filtrovat ty, které nejsou vhodné.
Zvažme pořadí akcí v krocích:
1. Přejděte do sběrače klíčů „Analýza skupiny“ a seřaďte klíče podle počtu použitých slov. Úkolem je najít necílová a častá a přidat je do seznamu stop slov.
Všechno děláme stejným způsobem jako v odstavci „Mínusová slova“.

2. Aplikujeme všechna nalezená stop slova na seznam našich frází a projdeme ji, abychom pro jistotu neztratili cílové dotazy. Po kontrole klikněte na smazat „Označené fráze“.

3. Filtrujeme fiktivní fráze, které se zřídka používají v přesné shodě, ale mají vysokou základní frekvenci. Chcete -li to provést, v nastavení programu Kay Collector v položce „KEY & SERP“ vložte výpočetní vzorec: KEY 1 = (YandexWordstatBaseFreq) / (YandexWordstatQuotePointFreq) a uložte změny.

4. Vypočítáme KEY 1 a odstraníme ty fráze, pro které je tento parametr 100 nebo více.

Zbývající klíče je třeba seskupit podle vstupní stránky.
Shlukování
Distribuce dotazů do skupin začíná seskupováním frází podle shora volný program„Klastr Majento“. Doporučuji KeyAssort, placený analog s širší funkčností a vyšší rychlostí provozu, ale ten bezplatný je pro malé jádro dostačující. Jedinou výhradou je, že pro práci v kterémkoli z nich budete muset zakoupit limity XML. Průměrná cena - 5 rublů. na 1000 žádostí. To znamená, že zpracování průměrného jádra pro 20–30 tisíc klíčů bude stát 100–150 rublů. Adresu služby, kterou používáte, najdete na obrázku níže.

Podstatou shlukování klíčů pomocí této metody je seskupit ty fráze, které mají Yandex Top 10:
- sdílené adresy URL mezi sebou (tvrdé)
- s nejčastějším požadavkem ve skupině (Soft).
V závislosti na počtu těchto náhod pro různé lokality se rozlišují prahy klastrování: 2, 3, 4 ... 10.
Výhodou této metody je seskupování frází podle potřeb lidí, a nejen podle synonym. To vám umožní okamžitě pochopit, která klíčová slova lze použít na jedné vstupní stránce.
Vhodné pro informativní lidi:
- Měkké s prahem 3-4 a poté kartáčováním ručně;
- Těžko ve 3-ke, a pak sjednocení klastrů podle významu.
Internetové obchody a komerční weby jsou zpravidla propagovány na hardu s prahem shlukování 3. Téma je obsáhlé, proto ho rozeberu později v samostatném článku.
Pro náš projekt jsme po seskupení metodou Hard na 3-ke získali 317 skupin.

Kontrola konkurence
Nemá smysl propagovat vysoce konkurenční dotazy. Na vrchol je těžké se dostat a bez něj nebude k článku žádný provoz. Abychom pochopili, na jaká témata je výhodné psát, používáme následující metodu:
Zaměřujeme se na přesnou frekvenci skupiny frází, pro které je článek psán, a soutěže o Mutagen. U informačních webů doporučuji vzít do práce témata, která mají celkovou přesnou frekvenci 300 a více a koeficient konkurence je od 1 do 12 včetně.
V komerčních tématech se zaměřte na okraje produktu nebo služby a na to, jak to dělají konkurenti v první desítce. I 5-10 cílených dotazů za měsíc může být důvodem, proč pro to vytvořit samostatnou stránku.
Jak zkontrolovat konkurenci na vyžádání:
a) ručně, zadáním příslušné fráze v samotné službě nebo prostřednictvím hromadných úkolů;

b) v dávkovém režimu prostřednictvím programu Key Collector.

Výběr témat a seskupování
Zvažme každou z výsledných skupin pro náš projekt po seskupení a vybereme témata pro web.
Majento, na rozdíl od Key Assortu, neposkytuje možnost stahovat data o počtu zobrazení pro každou frázi, takže je budete muset dodatečně střílet přes Key Collector.
Instrukce:
1) Vyložte všechny skupiny z Majento ve formátu CSV;
2) Spojujeme fráze v Excelu pomocí masky „skupina: klíč“;
3) Načtěte výsledný seznam do klíčového kolektoru. V nastavení musí být v režimu importu „Skupina: Klíč“ zatržítko a nesledovat přítomnost frází v jiných skupinách;

4) Z nově vytvořených skupin odstraníme základní a přesnou frekvenci klíčových slov. (Pokud používáte Key Assort, nemusíte to dělat. Program vám umožňuje pracovat s dalšími sloupci)
5) Hledáme klastry s jedinečným záměrem obsahující alespoň 3 fráze a celkový počet zobrazení pro všechny dotazy je více než 300. Dále zkontrolujeme 3-4 nejčastější z nich na mutagenní konkurenci. Pokud mezi těmito frázemi existují klíče s konkurencí menší než 12 - bereme to do práce;
6) Prohlédneme si zbytek skupin. Pokud existují fráze, které mají blízký význam a stojí za zvážení na stejné stránce, zkombinujeme je. U skupin obsahujících nové významy se díváme na vyhlídky na celkovou frekvenci frází, pokud je nižší než 150 za měsíc, pak ji odkládáme, dokud neprojdeme celé jádro. Snad bude možné je spojit s dalším klastrem a nasbírat 300 přesných dojmů - to je minimum, od kterého stojí za to vzít článek do práce. Chcete -li urychlit ruční seskupování, použijte pomocné nástroje: rychlý filtr a slovník frekvencí. Pomohou vám rychle najít vhodné fráze z jiných klastrů;

Pozornost!!! Jak pochopit, že klastry lze kombinovat? Vezmeme 2 frekvenční klíče z klíčů vybraných v kroku 5 pro vstupní stránku a 1 požadavek z nové skupiny.
Přidejte je do nástroje Arsenkin „Unload Top 10“, v případě potřeby zadejte požadovanou oblast. Dále se podíváme na počet přechodů podle barvy pro 3. frázi se zbytkem. Sdružujeme skupiny, jsou -li jich 3 nebo více. Pokud neexistují náhody nebo jedna věc, nemůžete je kombinovat - různé záměry, v případě 2 křižovatek se podívejte na problém ručně a použijte logiku.
7) Po seskupení klíčů získáme seznam nadějných témat pro články a sémantiku k nim.

Odstranění dalších požadavků na typ obsahu
Při sestavování sémantického jádra je důležité pochopit, že pro blogy a komunikační weby nejsou komerční dotazy potřeba. Stejně jako internetové obchody nepotřebují informace.
Projdeme každou skupinu a vyčistíme vše zbytečné, pokud není možné přesně určit záměr žádosti, porovnáme výsledky nebo použijeme nástroje:
- Kontrola komercializace z Pixel Tools (zdarma, ale s denním limitem kontrol);
- Služba Just-Magic, shlukování zaškrtnutím komerční žádosti (zaplaceno, cena závisí na tarifu)
Poté přejdeme k poslední fázi.
Optimalizace frází
Optimalizujeme sémantické jádro tak, aby bylo vhodné, aby s ním specialista na seo a copywriter v budoucnu pracoval. Za tímto účelem ponecháme v každé skupině klíčové fráze, které plně odrážejí potřeby lidí a obsahují co nejvíce synonym pro hlavní fráze.
Algoritmus akcí:
- Seřadit klíčová slova v Excelu nebo Key Collector abecedně od A do Z;
- Vyberme ty, které odhalí téma z různých stran a různými slovy... Když jsou všechny ostatní věci stejné, ponecháme fráze s vyšší přesnou frekvencí nebo které mají nižší klíč 1 (poměr základní frekvence k přesné);
- Odstraňujeme klíčová slova s méně než 7 zobrazeními za měsíc, která nemají nový význam a neobsahují jedinečná synonyma.
Příklad toho, jak vypadá dobře složené sémantické jádro -
Červeně jsem označil fráze, které neodpovídají záměru. Pokud zanedbáte moje doporučení pro ruční seskupování a nezkontrolujete kompatibilitu, ukáže se, že stránka bude optimalizována pro nekompatibilní klíčové fráze a již neuvidíte vysoké pozice pro propagované dotazy.
Konečný kontrolní seznam
- Vybíráme hlavní vysokofrekvenční dotazy, které nastavují téma;
- Hledáme pro ně synonyma pomocí levého a pravého sloupce Wordstatu, webů konkurentů a jejich úryvků;
- Rozbalte přijaté dotazy rozebráním levého sloupce Wordstatu;
- Příprava seznamu zastavovacích slov a jejich aplikace na výsledné fráze;
- Analyzujte tipy pro Yandex a Google;
- Odstraníme základnu a přesnou frekvenci;
- Rozšíření seznamu vylučujících klíčových slov. Čistíme od odpadků a falešných požadavků
- Klastrování provádíme prostřednictvím Majento nebo KeyAssort. U informačních webů v měkkém režimu je prahová hodnota 3-4. Pro komerční internetové zdroje používající metodu Hard s prahovou hodnotou 3.
- Importujeme data do Key Collector a určujeme konkurenci 3-4 frází pro každý cluster s jedinečným záměrem;
- Vybíráme témata a rozhodujeme o vstupních stránkách pro dotazy na základě odhadu celkového počtu přesných zobrazení pro všechny fráze z jednoho klastru (od 300 pro informační lidi) a soutěže o ty nejčastější pro Mutagen (až 12).
- Pro každou vhodnou stránku hledáme další klastry s podobnými potřebami uživatelů. Pokud je můžeme zvážit na jedné stránce, spojíme je. Pokud potřeba není jasná nebo existuje podezření, že by na ni měl odpovědět jiný typ obsahu nebo stránky, zkontrolujeme to vydáním nebo prostřednictvím nástrojů Pixel Tools nebo Just-Magic. U obsahových webů by jádro mělo sestávat z žádosti o informace, z komerčních z transakčních. Přebytek odstraníme.
- Klíče v každé skupině seřadíme podle abecedy a ponecháme ty, které téma popisují z různých úhlů a různými slovy. Všechny ostatní věci jsou stejné, přednost mají ty dotazy, které mají nižší poměr frekvence k přesné frekvenci a vyšší počet přesných zobrazení za měsíc.
Co dělat s jádrem SEO po jeho vytvoření
Udělali seznam klíčů, dali je autorovi a on napsal vynikající článek v plném znění, který odhalil všechny významy. Eh, snil jsem ... Vysvětlující text bude fungovat, pouze pokud copywriter jasně rozumí tomu, co po něm chcete a jak se může ověřit.
Pojďme analyzovat 4 komponenty, které fungovaly dobře a které vám zaručeně zajistí spoustu cíleného provozu k článku:
Pěkná struktura. Analyzujeme požadavky vybrané na vstupní stránce a identifikujeme, jaké potřeby lidé v tomto tématu mají. Dále napíšeme osnovu článku, který jim plně odpovídá. Úkolem je zajistit, aby lidé po vstupu na web obdrželi rozsáhlou a vyčerpávající odpověď na sémantiku, kterou jste sestavili. To poskytne dobré chování a vysokou relevanci záměru. Jakmile vytvoříte plán, podívejte se na stránky svých konkurentů zadáním hlavního vyhledávacího dotazu, který propagujete. Musíte to udělat přesně v tomto pořadí. To znamená, že nejprve to uděláme sami, pak se podíváme na to, co mají ostatní, a v případě potřeby to upřesníme.
Optimalizace pro klíče. Samotný článek je zostřen pod 1–2 nejčastějšími klávesami s konkurencí pro Mutagen až do 12. Další 2–3 středofrekvenční fráze lze použít jako nadpisy, ale ve zředěné podobě, to znamená vložením dalších slov, která nejsou související s tématem, pomocí synonym a slovních tvarů ... Zaměřujeme se na nízkofrekvenční fráze, ze kterých vytahuje jedinečnou část - ocas a rovnoměrně ji vkládá do textu. Vyhledávače si vše najdou a slepí samy.
Synonyma pro základní dotazy. Vypisujeme je odděleně od našeho sémantického jádra a stanovujeme úkol, aby je copywriter používal rovnoměrně v celém textu. To pomůže snížit hustotu našich hlavních slov a zároveň bude text dostatečně optimalizován, aby se dostal nahoru.
Věty určující předmět. LSI samy o sobě stránku nepropagují, ale jejich přítomnost naznačuje, že psaný text s největší pravděpodobností patří do „pera“ odborníka, a to je již plus kvality obsahu. K vyhledávání tematických frází používáme nástroj „Podmínky pro copywritera“ od Pixel Tools.

Alternativní metoda výběru klíčových frází pomocí služeb pro analýzu konkurence
Existuje rychlý přístup k vybudování sémantického jádra, které je použitelné jak pro nováčky, tak pro pokročilé uživatele. Podstata metody spočívá v tom, že zpočátku vybíráme klíče nikoli pro celý web nebo kategorii, ale konkrétně pro článek, vstupní stránku.
Lze jej implementovat dvěma způsoby, které se liší tím, jak vybíráme témata pro stránku a jak hluboce rozšiřujeme klíčové fráze:
- analýzou primárních klíčů;
- na základě analýzy konkurence.
Každý z nich lze implementovat na jednodušší a složitější úrovni. Pojďme se podívat na všechny možnosti.
Bez použití programů
Copywriter nebo webmaster se často nechce zabývat rozhraním velkého počtu programů, ale potřebují pro ně dobrá témata a klíčové fráze.
Tato metoda je jen pro začátečníky a ty, kteří se nechtějí obtěžovat. Všechny akce jsou prováděny bez použití dalšího softwaru, pomocí jednoduchých a srozumitelných služeb.
Co potřebuješ:
- Služba Keys.so pro analýzu konkurence - 1 500 rublů. S propagačním kódem „altblog“ - sleva 15%;
- Mutagen. Kontrola konkurenceschopnosti požadavků - 30 kop, sběr základní a přesné frekvence - 2 kopy za šek;
- Bukvarix - bezplatná verze nebo obchodní účet - 995 rublů. (nyní se slevou 695 rublů)
Možnost 1. Výběr tématu analýzou základních frází:
- Hlavní klíče z tématu vybíráme v širším smyslu pomocí brainstormingu a levého a pravého sloupce Yandex Wordstat;
- Dále pro ně hledáme synonyma, jejichž metody byly zmíněny dříve;
- Do Bukvarix (budete muset zaplatit placený tarif) vyplňujeme všechny přijaté žádosti o označení v rozšířeném režimu „Hledat podle seznamu klíčových slov“;
- Ve filtru zadejte: "! Přesně! Frekvence" od 50, Počet slov od 3;
- Exportujeme celý seznam do Excelu;
- Vybereme všechna klíčová slova a odešleme je ke seskupení do služby „Kulakov Clusterizer“. Pokud je stránka regionální, vybereme si ji požadované město... Ponechte prahovou hodnotu shlukování pro informační weby na 2, pro komerční weby nastavenou na 3;
- Po seskupení vybereme témata pro články a podíváme se na výsledné klastry. Bereme ty, kde je počet frází od 3 a s jedinečným záměrem. Analýza adres URL webů shora ve sloupci „Konkurenti“ (vpravo na servisním štítku Kulakova) pomáhá lépe porozumět potřebám lidí. Nezapomeňte také zkontrolovat soutěž Mutagen. Děláme 2-3 požadavky z klastru. Pokud je všeho více než 12, pak by se téma nemělo brát;
- Rozhodli jsme se pro název budoucí vstupní stránky, zbývá pro ni vybrat klíčové fráze;
- Z pole „Konkurenti“ zkopírujte 3 adresy URL s příslušným typem stránek (pokud je web informativní - použijte odkazy na články, pokud jsou komerční, pak na obchody);
- Postupně je vkládáme do klíčů.so a uvolňujeme pro ně všechny klíčové fráze;
- Kombinujeme je v Excelu a odstraňujeme duplikáty;
- Samotná servisní data nestačí, takže je musíte rozšířit. Pojďme znovu použít Bookvarix;
- Výsledný seznam posíláme ke klastrování do „kulakovského klastrovače“;
- Vybereme skupiny požadavků, které jsou vhodné pro vstupní stránku, se zaměřením na záměr;
- Odstraníme základnu a přesnou frekvenci přes Mutagen v režimu „Hromadné mise“;
- Seznam exportujeme s upřesněnými údaji o počtu zobrazení v Excelu. Odebrat hodnoty null pro oba typy frekvencí;
- Také v aplikaci Excel přidáme vzorec pro poměr základní frekvence k přesnému a ponecháme pouze ty klíče, pro které je tento poměr menší než 100;
- Vymazáváme požadavky jiného typu obsahu;
- Fráze, které odhalují hlavní záměr, ponecháváme co nejúplněji a různými slovy;
- U bodů 8-19 opakujeme všechny stejné kroky pro ostatní témata.
Možnost 2. Výběr tématu pomocí analýzy konkurence:
1. Hledáme špičkové weby v našem tématu, pracujeme s vysokofrekvenčními dotazy a procházíme výsledky pomocí nástroje Arsenkin „Top-10 Analysis“. Stačí najít 1-2 vhodné zdroje.
Pokud propagujeme web v konkrétním městě, označujeme regionálnost;
2. Přejděte do služby keys.so a zadejte adresy URL stránek, které jsme našli, a zjistěte, které stránky konkurentů přinášejí největší provoz.
3. 3-5 nejpřesnějších frekvenčních dotazů z nich kontrolujeme souběžnost. Pokud je u všech frází nad 12, pak je lepší hledat jiné téma, které je méně konkurenceschopné.
4. Pokud potřebujete najít další stránky pro analýzu, otevřete kartu „Konkurenti“ a nastavte parametry: podobnost - 3, tematičnost - 10. Seřaďte data v sestupném pořadí podle návštěvnosti.
5. Poté, co jsme vybrali téma, vložíme jeho název do výsledků vyhledávání a zkopírujeme 3 adresy URL shora.
6. Poté zopakujeme body 10-19 z 1. možnosti.
Pomocí Kei Collector nebo Slovoeba
Tato metoda se bude lišit od předchozí pouze použitím programu Key Collector pro některé operace a hlubším rozšířením klíčů.
Co potřebuješ:
- Program Key Collector - 1800 rublů;
- všechny stejné služby jako v předchozí metodě.
"Pokročilý - 1"
- Analyzujte levý a pravý sloupec Yandex pro celý seznam frází;
- Přes Collector odstraníme přesnou a základní frekvenci;
- Vypočítáme indikátorový klíč 1;
- Smazáme žádosti o nuly a s klíčem 1> 100;
- Pak děláme vše stejným způsobem jako v odstavcích 18-19 možnosti 1.
"Pokročilý - 2"
- Provádíme kroky 1-5, jako v možnosti 2;
- Sbírejte klíče v keys.so pro každou URL;
- Odebírání duplicit v Key Collector;
- Body 1–4 opakujte jako v metodě „Pokročilé -1“.
Nyní porovnáme počet přijatých klíčů a jejich přesnou celkovou frekvenci při shromažďování SN různými metodami:
Jak vidíte z tabulky, nejlepší výsledek ukázal alternativní způsob vytvoření jádra pro stránku - „Pokročilý 1,2“. Bylo možné získat o 34% více cílových klíčů a současně se ukázalo, že celkový provoz přes klastr je o 51% vyšší než v případě klasické metody.
Níže na obrázcích můžete vidět, jak vypadá hotové jádro v každém případě. Vzal jsem fráze s přesným počtem zobrazení od 7 za měsíc, abych mohl vyhodnotit kvalitu klíčových slov. Úplnou sémantiku najdete v tabulce pod odkazem „Zobrazit“.
A) 
B) 
PROTI) 
Nyní víte, že to není vždy nejběžnější způsob, jak to dělají všichni, nejsprávnější a nejsprávnější, ale neměli byste se vzdávat ani jiných metod. Hodně záleží na samotném tématu. Pro komerční weby, kde není tolik klíčů, stačí klasická verze. Na informačních webech můžete také dosáhnout vynikajících výsledků, pokud správně vypracujete technické zadání pro copywritera, vytvoříte dobrou strukturu a seo-optimalizaci. O tom všem si podrobně povíme v následujících článcích.
3 běžné chyby při vytváření sémantického jádra
1. Sbírání frází nahoře. Nestačí analyzovat Wordstat, abyste získali dobrý výsledek!
Více než 70% dotazů, které lidé zadávají zřídka nebo pravidelně, se tam vůbec nedostanou. Ale mezi nimi jsou často klíčové fráze s dobrou konverzí a opravdu nízkou konkurencí. Jak si je nenechat ujít? Nezapomeňte sbírat návrhy pro vyhledávání a kombinovat je s daty z různých zdrojů (počitadla na webech, statistické služby a databáze).
2. Míchání informačních a obchodních požadavků na jedné stránce. Již jsme diskutovali, že klíčové fráze se liší podle typu potřeb. Pokud na váš web přijde návštěvník, který chce provést nákup, ale jako odpověď na jeho požadavek vidí stránku s článkem, myslíte si, že bude spokojen? Ne! Vyhledávače také myslí, když hodnotí stránku, což znamená, že můžete okamžitě zapomenout na špičku frází MF a HF. Pokud tedy máte pochybnosti o určení typu požadavku, podívejte se na výsledky nebo ke stanovení komerční hodnoty použijte nástroje Pixel Tools, Just-Magis.
3. Volba podpory vysoce konkurenčních dotazů. Pozice pro fráze HF VK o 60-70% závisí na faktorech chování, a abyste je získali, musíte se dostat nahoru. Čím více uchazečů, tím delší řada uchazečů a vyšší požadavky na místa. Všechno je jako v životě nebo sportu. Stát se mistrem světa je mnohem obtížnější než získat stejný titul ve vašem městě.
Proto je lepší jít spíše do tichého než přehřátého výklenku.
Dříve bylo dostat se na vrchol ještě obtížnější. Nahoře byli na principu, že kdo měl čas, ten jedl. Vedoucí se dostali na první místa a mohli být vytlačeni pouze hromaděním faktory chování... A jak je získat, když jste na druhé nebo třetí stránce ... Yandex prolomil tento začarovaný kruh v létě 2015 zavedením algoritmu „multi-armable bandit“. Jeho podstatou je právě náhodné zvyšování a snižování polohy webů, aby bylo možné pochopit, zda se nahoře objevily hodnější kandidáti.
Kolik peněz potřebujete na začátek?
Chcete -li odpovědět na tuto otázku, vypočítáme náklady na požadovaný arzenál programů a služeb, abychom mohli připravit a rozdělit klíčové fráze do 100 článků.
Úplně minimum (vhodné pro klasickou verzi):
1. Slovoeb - zdarma
2. Cluster Majento - zdarma
3. Uznání captchas - 30 rublů.
4. Xml limity - 70 rublů.
5. Kontrola konkurence žádosti o mutagen - 10 šeků denně zdarma
6. Pokud nikam nespěcháte a jste připraveni strávit 20–30 hodin rozebráním, obejdete se bez proxy.
—————————
Výsledkem je 100 rublů. Pokud sami zadáte captcha a dostanete limity xml výměnou za ty přenesené z vašeho webu, pak je opravdu možné připravit jádro zdarma. Stačí strávit další den nastavením a ovládáním programů a další 3-4 dny čekáním na výsledky analýzy.
Standardní sada sémantistů (pro pokročilé a klasické metody):
1. Sběratel Kay - 1 900 rublů
2. Klíčový sortiment - 1700 rublů
3. Bukvarix (obchodní účet) - 650 rublů.
4. Služba analýzy klíčů konkurentů. Tedy - 1 500 rublů.
5. 5 proxy - 350 rublů za měsíc
6. Anticaptcha - asi 30 rublů.
7. Limity xml - asi 80 rublů.
8. Kontrola konkurence s Mutagenem (1 šek = 30 kop) - udržíme do 200 rublů.
———————-
Výsledkem je 6410 rublů. Můžete se samozřejmě obejít bez KeyAssortu, nahradit jej Majento pomocí clustereru a místo Key Collector použít Slovoyob. Pak bude stačit 2810 rublů.
Vyplatí se důvěřovat vývoji základního „profíka“ nebo je lepší na to přijít a udělat to sami?
Pokud člověk pravidelně dělá to, co miluje, pumpuje do toho a podle logiky by jeho výsledky měly být rozhodně lepší než výsledky začátečníka v této oblasti. S výběrem klíčových slov ale vše dopadne přesně naopak.
Proč si v 90% případů vede začátečník lépe než profesionál?
Všechno je to o přístupu. Úkolem sémantisty není shromáždit pro vás to nejlepší jádro, ale dokončit svou práci v co nejkratším čase a tak, aby vám vyhovovala její kvalita.
Pokud vše uděláte sami podle výše uvedených algoritmů, bude výsledek řádově vyšší ze dvou důvodů:
- Rozumíte tématu. To znamená, že znáte potřeby svých zákazníků nebo uživatelů webu a můžete v počáteční fázi maximalizovat tokenové dotazy pro analýzu pomocí velkého počtu synonym a konkrétních slov.
- Máme zájem dělat vše efektivně. Majitel firmy nebo zaměstnanec společnosti, ve které pracuje, samozřejmě bude k problému přistupovat zodpovědněji a bude se snažit dělat vše na maximum. Čím úplnější je jádro a čím více málo konkurenčních dotazů v něm bude, tím více cíleného provozu bude shromažďováno, což znamená, že zisk bude vyšší při stejných investicích do obsahu.
Jak zjistíte, že zbývajících 10% tvoří jádro lépe než vy?
Podívejte se na společnosti, ve kterých je výběr klíčových frází klíčovou kompetencí. A okamžitě diskutujte, jaký chcete výsledek, jako všichni ostatní nebo maximum. V druhém případě to bude 2–3krát dražší, ale dlouhodobě se to mnohonásobně vyplatí. Pro ty, kteří si u mě chtějí objednat službu, všechny potřebné informace a podmínky. Garantuji kvalitu!
Proč je tak důležité plně vypracovat sémantiku?
Zde, jako v každém oboru, funguje princip „dobré a špatné volby“. Jaká je jeho podstata?
Každý den stojíme tváří v tvář tomu, co si vybereme:
- setkat se s člověkem, který se zdá být ničím, ale nelpí na něm, nebo, když na to přišel, vybudovat harmonický vztah s někým, kdo je potřebný;
- dělat práci, která se ti nelíbí, nebo najít něco, do čeho tvá duše lže, a učinit z toho svou profesi;
- vhodnou možností je pronajmout si prostor pro obchod na neprocházkovém místě nebo stále čekat, až se uvolní
- nebrat tým nejlepší manažer o prodeji, a ten, kdo se v dnešním rozhovoru ukázal nejlépe.
Zdá se, že je vše jasné. A pokud se na to podíváte z druhé strany, představíte každou volbu jako investici do budoucnosti. Tady začíná zábava!
Ušetřeno na tom. jádro, 3-5 tis. Šťastní jako sloni! K čemu to ale dále vede:
a) pro informační weby:
- Ztráty v provozu nejméně 1,5krát se stejnými investicemi do obsahu. Porovnávání různé metody získávání klíčových frází jsme již empiricky zjistili, že alternativní metoda vám umožňuje nasbírat o 51% více;
- Projekt ve výsledcích vyhledávání klesá rychleji... Pro konkurenty je snadné nás obejít poskytnutím úplnější odpovědi na záměr.
b) u komerčních projektů:
- Méně nebo více potenciálních zákazníků... Pokud máme sémantiku, jako všichni ostatní, přecházíme na stejné dotazy jako naši konkurenti. Velký počet nabídky s konstantní poptávkou snižují podíl každého z nich na trhu;
- Nízká konverze. Konkrétní požadavky lépe převést na tržby. Šetří se na tom. jádro, ztrácíme nejvíce konverzních klíčů;
- Je těžší se dostat dopředu. Existuje mnoho těch, kteří chtějí být na vrcholu - požadavky na každého z kandidátů jsou vyšší.
Přeji vám, abyste to vždy dělali dobrá volba a investujte pouze do plusu!
P.S. Bonus „Jak napsat dobrý článek se špatnou sémantikou“, jakož i další životní hacky za propagaci a vydělávání peněz na internetu, si přečtěte v mé skupině







 Cobra")
























